이 자습서에서는 Azure HDInsight에서 Apache HBase 클러스터를 만들고, HBase 테이블을 만들고 Apache Hive를 사용하여 테이블을 쿼리하는 방법을 설명합니다. 일반 HBase 정보는 HDInsight HBase 개요를 참조하세요.
이 자습서에서는 다음을 하는 방법을 알아볼 수 있습니다.
- Apache HBase 클러스터 만들기
- HBase 테이블 만들기 및 데이터 삽입
- Apache Hive를 사용하여 Apache HBase 쿼리
- Curl을 사용하여 HBase REST API 사용
- 클러스터 상태 확인
필수 조건
SSH 클라이언트. 자세한 내용은 SSH를 사용하여 HDInsight(Apache Hadoop)에 연결을 참조하세요.
Bash. 이 문서의 예제에서는 curl 명령에 대한 Windows 10의 Bash 셸을 사용합니다. Windows 10을 위한 Linux용 Windows 하위 시스템 설치 가이드에서 설치 단계를 참조하세요. 다른 Unix 셸도 작동합니다. 약간의 수정을 거치면 curl 예제도 Windows 명령 프롬프트에서 작업할 수 있습니다. 또는 Windows PowerShell cmdlet Invoke-RestMethod를 사용할 수 있습니다.
Apache HBase 클러스터 만들기
다음 절차에서는 Azure Resource Manager 템플릿을 사용하여 HBase 클러스터를 만듭니다. 또한 이 템플릿은 종속된 기본 Azure Storage 계정을 만듭니다. 절차에 사용되는 매개 변수와 다른 클러스터 생성 메서드를 이해하려면 HDInsight에서 Linux 기반 Hadoop 클러스터 만들기를 참조하세요.
Azure Portal에서 템플릿을 열려면 다음 이미지를 선택합니다. 템플릿은 Azure 빠른 시작 템플릿에 있습니다.

사용자 지정 배포 대화 상자에서 다음 값을 입력합니다.
속성 Description Subscription 클러스터를 만드는 데 사용할 Azure 구독을 선택합니다. Resource group Azure 리소스 관리 그룹을 만들거나 기존 그룹을 사용합니다. 위치 리소스 그룹의 위치를 지정합니다. ClusterName HBase 클러스터의 이름을 입력합니다. 클러스터 로그인 이름 및 암호 기본 로그인 이름은 admin입니다.SSH 사용자 이름 및 암호 기본 사용자 이름은 sshuser입니다.다른 매개 변수는 선택 사항입니다.
각 클러스터에는 Azure Storage 계정 종속성이 있습니다. 클러스터를 삭제한 후에는 데이터가 스토리지 계정에 유지됩니다. 클러스터 기본 스토리지 계정 이름은 "스토리지"가 추가된 클러스터 이름이입니다. 템플릿 변수 섹션에 하드 코딩되어 있습니다.
위에 명시된 사용 약관에 동의함을 선택한 다음, 구매를 선택합니다. 클러스터를 만들려면 20분 정도가 걸립니다.
HBase 클러스터가 삭제된 후 동일한 기본 Blob 컨테이너를 사용하여 다른 HBase 클러스터를 만들 수 있습니다. 새 클러스터에서는 원래 클러스터에서 만든 HBase 테이블을 선택합니다. 불일치를 방지하기 위해 클러스터를 삭제하기 전에 HBase 테이블을 사용하지 않도록 설정하는 것이 좋습니다.
테이블 만들기 및 데이터 삽입
SSH를 사용하여 HBase 클러스터를 연결하고 Apache HBase 셸을 사용하여 HBase 테이블을 만들고 데이터 및 쿼리 데이터를 삽입할 수 있습니다.
대부분의 사람들의 경우, 데이터는 테이블 형식으로 나타납니다.

Cloud BigTable의 구현인 HBase에서는 동일한 데이터가 다음과 같이 표시됩니다.

HBase 셸을 사용하려면
ssh명령을 사용하여 HBase 클러스터에 연결합니다. 클러스터 이름으로 바꿔CLUSTERNAME서 다음 명령을 편집한 다음, 명령을 입력합니다.ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.nethbase shell명령을 사용하여 HBase 대화형 셸을 시작합니다. SSH 연결에서 다음 명령을 입력합니다.hbase shell명령을 사용하여
create2열 패밀리가 있는 HBase 테이블을 만듭니다. 테이블 및 열 이름은 대/소문자를 구분합니다. 다음 명령을 입력합니다.create 'Contacts', 'Personal', 'Office'list명령을 사용하여 HBase에 모든 테이블을 나열합니다. 다음 명령을 입력합니다.listput명령을 사용하여 특정 테이블의 지정된 행에서 지정된 열에 값을 삽입합니다. 다음 명령을 입력합니다.put 'Contacts', '1000', 'Personal:Name', 'John Dole' put 'Contacts', '1000', 'Personal:Phone', '1-425-000-0001' put 'Contacts', '1000', 'Office:Phone', '1-425-000-0002' put 'Contacts', '1000', 'Office:Address', '1111 San Gabriel Dr.'scan명령을 사용하여Contacts테이블 데이터를 검사하고 반환합니다. 다음 명령을 입력합니다.scan 'Contacts'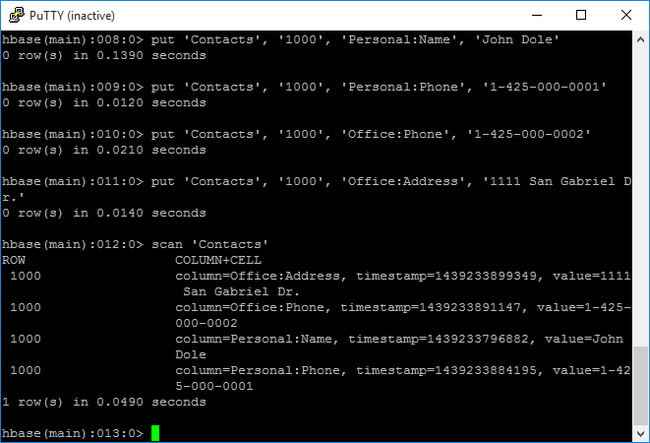
get명령을 사용하여 행의 콘텐츠를 페치합니다. 다음 명령을 입력합니다.get 'Contacts', '1000'행이 하나만 있기 때문에
scan명령을 사용하는 것과 유사한 결과가 표시됩니다.HBase 테이블 스키마에 대한 자세한 내용은 Apache HBase 스키마 디자인 소개를 참조하세요. HBase 명령에 대한 자세한 내용은 Apache HBase 참조 가이드를 참조하세요.
exit명령을 사용하여 HBase 대화형 셸을 중지합니다. 다음 명령을 입력합니다.exit
연락처 HBase 테이블로 대량으로 데이터 로드
HBase는 테이블로 데이터를 로드하는 여러 방법을 포함합니다. 자세한 내용은 대량 로드를 참조하세요.
샘플 데이터 파일은 공용 Blob 컨테이너인 wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt에 있습니다. 데이터 파일 내용은 다음과 같습니다.
8396 Calvin Raji 230-555-0191 230-555-0191 5415 San Gabriel Dr.
16600 Karen Wu 646-555-0113 230-555-0192 9265 La Paz
4324 Karl Xie 508-555-0163 230-555-0193 4912 La Vuelta
16891 Jonn Jackson 674-555-0110 230-555-0194 40 Ellis St.
3273 Miguel Miller 397-555-0155 230-555-0195 6696 Anchor Drive
3588 Osa Agbonile 592-555-0152 230-555-0196 1873 Lion Circle
10272 Julia Lee 870-555-0110 230-555-0197 3148 Rose Street
4868 Jose Hayes 599-555-0171 230-555-0198 793 Crawford Street
4761 Caleb Alexander 670-555-0141 230-555-0199 4775 Kentucky Dr.
16443 Terry Chander 998-555-0171 230-555-0200 771 Northridge Drive
필요에 따라 텍스트 파일을 만들고 고유한 스토리지 계정에 파일을 업로드할 수 있습니다. 지침에 대해서는 HDInsight에서 Apache Hadoop 작업용 데이터 업로드를 참조하세요.
이 절차는 마지막 절차에서 만든 Contacts HBase 테이블을 사용합니다.
ssh 연결 열기에서 데이터 파일을 StoreFiles로 변환하고
Dimporttsv.bulk.output에서 지정된 상대 경로에 저장하려면 다음 명령을 실행합니다.hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Personal:Name,Personal:Phone,Office:Phone,Office:Address" -Dimporttsv.bulk.output="/example/data/storeDataFileOutput" Contacts wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt/example/data/storeDataFileOutput에서 HBase 테이블로 데이터를 업로드하려면 다음 명령을 실행합니다.hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /example/data/storeDataFileOutput ContactsHBase 셸을 열고
scan명령을 사용하여 테이블 콘텐츠를 나열할 수 있습니다.
Apache Hive를 사용하여 Apache HBase 쿼리
Apache Hive를 사용하여 HBase 테이블의 데이터를 쿼리할 수 있습니다. 이 섹션에서는 HBase 테이블에 매핑되는 Hive 테이블을 만들고 이를 사용하여 HBase 테이블의 데이터를 쿼리합니다.
SSH 세션 열기에서 다음 명령을 사용하여 Beeline을 시작합니다.
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -n adminBeeline에 대한 자세한 내용은 Beeline을 사용하여 HDInsight에서 Hadoop과 Hive 사용을 참조하세요.
다음 HiveQL 스크립트를 실행하여 HBase 테이블에 매핑되는 Hive 테이블을 만듭니다. 이 명령문을 실행하기 전에 HBase 셸을 사용하여 이 문서의 앞에서 참조한 샘플 테이블을 만들었는지 확인합니다.
CREATE EXTERNAL TABLE hbasecontacts(rowkey STRING, name STRING, homephone STRING, officephone STRING, officeaddress STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Personal:Name,Personal:Phone,Office:Phone,Office:Address') TBLPROPERTIES ('hbase.table.name' = 'Contacts');HBase 테이블에서 데이터를 쿼리하려면 다음 HiveQL 스크립트를 실행합니다.
SELECT count(rowkey) AS rk_count FROM hbasecontacts;Beeline을 종료하려면
!exit을 사용합니다.ssh 연결을 종료하려면
exit를 사용합니다.
별도의 Hive 및 Hbase 클러스터
HBase 데이터에 액세스하는 Hive 쿼리는 HBase 클러스터에서 실행할 필요가 없습니다. 다음 단계가 완료되면 Hive와 함께 제공되는 클러스터(Spark, Hadoop, HBase 또는 Interactive Query 포함)를 사용하여 HBase 데이터를 쿼리할 수 있습니다.
- 두 클러스터는 모두 동일한 가상 네트워크 및 서브넷에 연결되어야 합니다.
- HBase 클러스터 헤드 노드에서 Hive 클러스터 헤드 노드 및 작업자 노드로 복사
/usr/hdp/$(hdp-select --version)/hbase/conf/hbase-site.xml합니다.
보안 클러스터
HBase 데이터는 ESP 사용 HBase를 사용하여 Hive에서 쿼리할 수도 있습니다.
- 다중 클러스터 패턴을 따르는 경우 두 클러스터에서 모두 ESP를 사용하도록 설정해야 합니다.
- Hive에서 HBase 데이터를 쿼리할 수 있도록 하려면
hive사용자에게 Hbase Apache Ranger 플러그 인을 통해 HBase 데이터에 액세스할 수 있는 권한이 부여되었는지 확인합니다. - 별도의 ESP 지원 클러스터를 사용하는 경우 HBase 클러스터 헤드 노드의
/etc/hosts내용을 Hive 클러스터 헤드 노드 및 작업자 노드에 추가/etc/hosts해야 합니다.
참고 항목
클러스터 중 하나의 크기가 조정되면 /etc/hosts를 다시 추가해야 합니다.
Curl을 통해 HBase REST API 사용
HBase REST API는 기본 인증을 통해 보호됩니다. 자격 증명이 안전하게 서버에 전송되도록 하려면 항상 보안 HTTP(HTTPS)를 사용하여 요청해야 합니다.
HDInsight 클러스터에서 HBase REST API를 사용하도록 설정하려면 다음 사용자 지정 시작 스크립트를 스크립트 동작 섹션에 추가합니다. 시작 스크립트는 클러스터를 만들 때 또는 클러스터를 만든 후에 추가할 수 있습니다. 노드 형식에 대해 영역 서버를 선택하여 스크립트가 HBase 영역 서버에서만 실행되도록 합니다. 스크립트는 지역 서버의 8090 포트에서 HBase REST 프록시를 시작합니다.
#! /bin/bash THIS_MACHINE=`hostname` if [[ $THIS_MACHINE != wn* ]] then printf 'Script to be executed only on worker nodes' exit 0 fi RESULT=`pgrep -f RESTServer` if [[ -z $RESULT ]] then echo "Applying mitigation; starting REST Server" sudo python /usr/lib/python2.7/dist-packages/hdinsight_hbrest/HbaseRestAgent.py else echo "REST server already running" exit 0 fi사용 편의성을 위해 환경 변수를 설정합니다. 클러스터 로그인 암호로 바꿔
MYPASSWORD서 다음 명령을 편집합니다.MYCLUSTERNAME을 HBase 클러스터의 이름으로 바꿉니다. 그런 다음, 명령을 입력합니다.export PASSWORD='MYPASSWORD' export CLUSTER_NAME=MYCLUSTERNAME다음 명령을 사용하여 기존의 HBase 테이블을 나열합니다.
curl -u admin:$PASSWORD \ -G https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/다음 명령을 사용하여 두 열 패밀리가 있는 새 HBase 테이블을 만듭니다.
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/schema" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"@name\":\"Contact1\",\"ColumnSchema\":[{\"name\":\"Personal\"},{\"name\":\"Office\"}]}" \ -v스키마는 JSON 형식으로 제공됩니다.
다음 명령을 사용하여 데이터 일부를 삽입합니다.
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/false-row-key" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"Row\":[{\"key\":\"MTAwMA==\",\"Cell\": [{\"column\":\"UGVyc29uYWw6TmFtZQ==\", \"$\":\"Sm9obiBEb2xl\"}]}]}" \ -v-d 스위치에 지정된 값을 Base64로 인코딩합니다. 예제:
MTAwMA==: 1000
UGVyc29uYWw6TmFtZQ==: Personal: Name
Sm9obiBEb2xl: John Dole
false-row-key를 사용하면 여러 (일괄 처리된) 값을 삽입할 수 있습니다.
다음 명령을 사용하여 행을 가져옵니다.
curl -u admin:$PASSWORD \ GET "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/1000" \ -H "Accept: application/json" \ -v
참고 항목
클러스터 엔드포인트를 통한 검색은 아직 지원되지 않습니다.
HBase Rest에 대한 자세한 내용은 Apache HBase 참조 가이드를 참조하세요.
참고 항목
Thrift는 HDInsight의 HBase에서 지원되지 않습니다.
Curl 또는 WebHCat과 다른 REST 통신을 사용하는 경우 HDInsight 클러스터 관리자의 사용자 이름과 암호를 제공하여 요청을 인증해야 합니다. 또한 클러스터 이름을 서버로 요청을 보내는 데 사용되는 URI(Uniform Resource Identifier)의 일부로 사용해야 합니다.
curl -u <UserName>:<Password> \
-G https://<ClusterName>.azurehdinsight.net/templeton/v1/status
그러면 다음과 유사한 응답이 표시됩니다.
{"status":"ok","version":"v1"}
클러스터 상태 확인
HDInsight에서 HBase는 클러스터 모니터링에 대한 웹 UI와 함께 제공됩니다. 웹 UI를 사용하여 지역에 대한 정보 또는 통계를 요청할 수 있습니다.
HBase Master UI에 액세스하려면
https://CLUSTERNAME.azurehdinsight.net에서 Ambari 웹 UI에 로그인합니다. 여기서CLUSTERNAME은 HBase 클러스터의 이름입니다.왼쪽 메뉴에서 HBase를 선택합니다.
페이지 위쪽에서 빠른 링크를 선택하고 활성 Zookeeper 노드 링크를 가리킨 다음, HBase Master UI를 선택합니다. UI는 다른 브라우저 탭에서 열립니다.
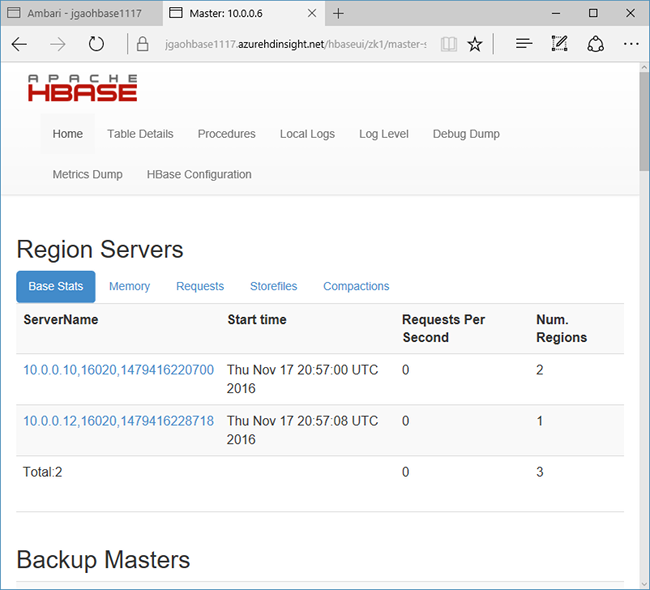
HBase Master UI에는 다음 섹션이 포함되어 있습니다.
- 지역 서버
- 백업 마스터
- 테이블
- 작업
- 소프트웨어 특성
클러스터 재작성
HBase 클러스터가 삭제된 후 동일한 기본 Blob 컨테이너를 사용하여 다른 HBase 클러스터를 만들 수 있습니다. 새 클러스터에서는 원래 클러스터에서 만든 HBase 테이블을 선택합니다. 그러나 불일치를 방지하기 위해 클러스터를 삭제하기 전에 HBase 테이블을 사용하지 않도록 설정하는 것이 좋습니다.
HBase 명령 disable 'Contacts'를 사용할 수 있습니다.
리소스 정리
이 애플리케이션을 계속 사용할 계획이 없으면 다음 단계에 따라 생성된 HBase 클러스터를 삭제합니다.
- Azure Portal에 로그인합니다.
- 맨 위에 있는 검색 상자에 HDInsight를 입력합니다.
- 서비스에서 HDInsight 클러스터를 선택합니다.
- 표시되는 HDInsight 클러스터 목록에서 이 자습서용으로 만든 클러스터 옆에 있는 ...를 클릭합니다.
- 삭제를 클릭합니다. 예를 클릭합니다.
다음 단계
이 자습서에서는 Apache HBase 클러스터를 만드는 방법을 배웠습니다. 그리고 HBase 셸에서 테이블을 만들고 해당 테이블의 데이터를 보는 방법에 대해 설명합니다. HBase 테이블의 데이터에 Hive 쿼리를 사용하는 방법도 배웠습니다. 그리고 HBase C# REST API를 사용하여 HBase 테이블을 만들고 테이블에서 데이터를 검색하는 방법입니다. 자세한 내용은 다음을 참조하세요.