Azure Monitor Logs를 쿼리하여 HDInsight 클러스터 모니터링
Azure HDInsight 클러스터에서 Azure Monitor 로그를 사용하는 방법에 대한 몇 가지 기본적인 시나리오를 살펴봅니다.
참고 항목
이 문서는 Log Analytics 대신 Azure Monitor 로그라는 용어를 사용하도록 최근에 업데이트되었습니다. 로그 데이터는 여전히 Log Analytics 작업 영역에 저장되며 동일한 Log Analytics 서비스에 의해 계속 수집 및 분석됩니다. Azure Monitor에서 로그의 역할을 보다 잘 반영하기 위해 용어를 업데이트하고 있습니다. 자세한 내용은 Azure Monitor 용어 변경을 참조하세요.
필수 조건
Azure Monitor 로그를 사용하도록 HDInsight 클러스터를 구성해야 하고, HDInsight 클러스터와 관련된 Azure Monitor 로그 모니터링 솔루션이 작업 영역에 추가되어 있어야 합니다. 지침은 HDInsight 클러스터에서 Azure Monitor 로그 사용을 참조하세요.
HDInsight 클러스터 메트릭 분석
HDInsight 클러스터에 대한 특정 메트릭을 조회하는 방법을 알아봅니다.
Azure Portal에서 HDInsight 클러스터에 연결된 Log Analytics 작업 영역을 엽니다.
일반에서 로그를 선택합니다.
Azure Monitor 로그를 사용하도록 구성된 모든 HDInsight 클러스터에 대해 모든 사용 가능한 메트릭을 검색하려면 검색 상자에 다음 쿼리를 입력한 다음, 실행을 선택합니다. 결과를 검토합니다.
search *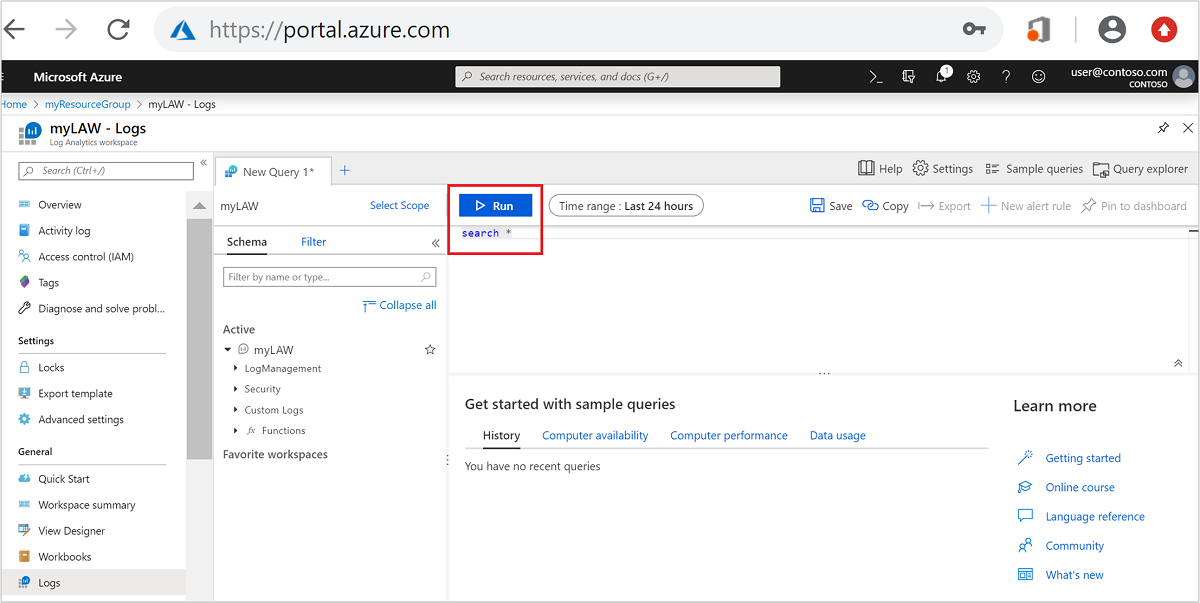
왼쪽 메뉴에서 필터 탭을 선택합니다.
형식 아래에서 하트비트를 선택합니다. 그런 다음, 적용 및 실행을 선택합니다.
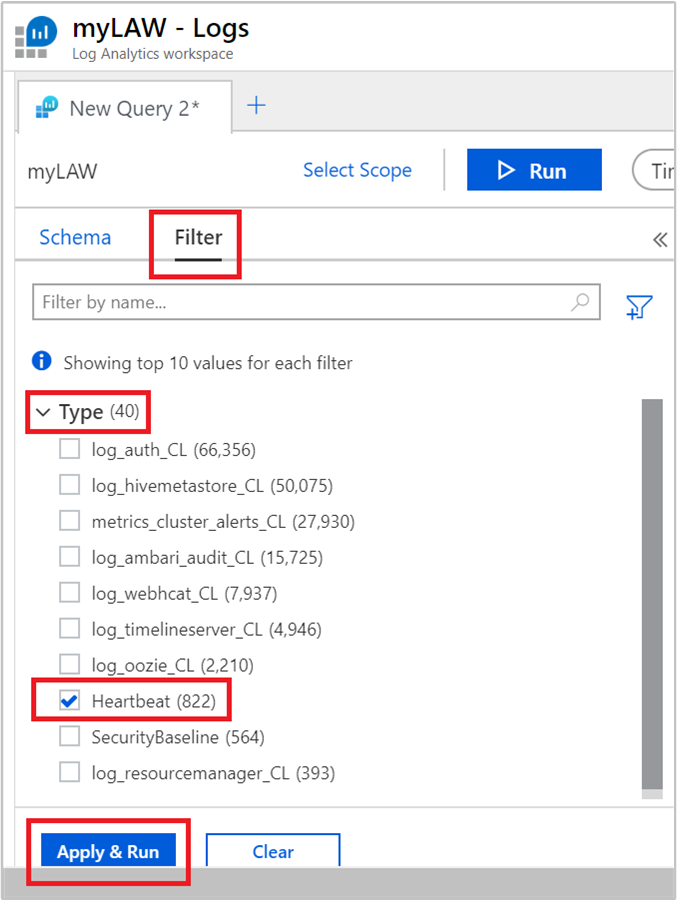
텍스트 상자의 쿼리가 다음과 같이 변경됩니다.
search * | where Type == "Heartbeat"왼쪽 메뉴에 제공되는 옵션을 사용하여 더 자세히 알아볼 수 있습니다. 예시:
특정 노드에서 로그를 보려면 다음을 수행합니다.
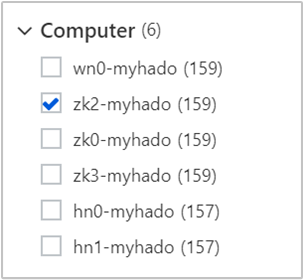
특정 시간에 로그를 보려면 다음을 수행합니다.
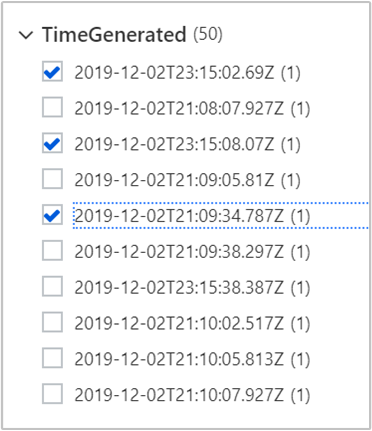
적용 및 실행을 선택하고 결과를 검토합니다. 또한 쿼리는 다음과 같이 업데이트되었습니다.
search * | where Type == "Heartbeat" | where (Computer == "zk2-myhado") and (TimeGenerated == "2019-12-02T23:15:02.69Z" or TimeGenerated == "2019-12-02T23:15:08.07Z" or TimeGenerated == "2019-12-02T21:09:34.787Z")
추가 샘플 쿼리
클러스터 이름별로 분류된 10분 간격으로 사용되는 평균 리소스를 기반으로 한 샘플 쿼리:
search in (metrics_resourcemanager_queue_root_default_CL) *
| summarize AggregatedValue = avg(UsedAMResourceMB_d) by ClusterName_s, bin(TimeGenerated, 10m)
사용된 리소스의 평균에 따라 구체화하는 대신 다음 쿼리를 사용하여 10분 간격으로 최대 리소스가 사용된 시점(90번째 및 95번째 백분위수)에 따라 결과를 구체화할 수 있습니다.
search in (metrics_resourcemanager_queue_root_default_CL) *
| summarize ["max(UsedAMResourceMB_d)"] = max(UsedAMResourceMB_d), ["pct95(UsedAMResourceMB_d)"] = percentile(UsedAMResourceMB_d, 95), ["pct90(UsedAMResourceMB_d)"] = percentile(UsedAMResourceMB_d, 90) by ClusterName_s, bin(TimeGenerated, 10m)
추적 이벤트에 대한 경고 만들기
경고를 만드는 첫 번째 단계는 경고를 트리거하는 쿼리에 도달하는 것입니다. 경고를 만들려는 모든 쿼리를 사용할 수 있습니다.
Azure Portal에서 HDInsight 클러스터에 연결된 Log Analytics 작업 영역을 엽니다.
일반에서 로그를 선택합니다.
경고를 만들려는 항목에 대해 다음 쿼리를 실행한 다음, 실행을 선택합니다.
metrics_resourcemanager_queue_root_default_CL | where AppsFailed_d > 0쿼리는 HDInsight 클러스터에서 실행되는 실패한 애플리케이션의 목록을 제공합니다.
페이지 맨 위에서 새 경고 규칙을 선택합니다.
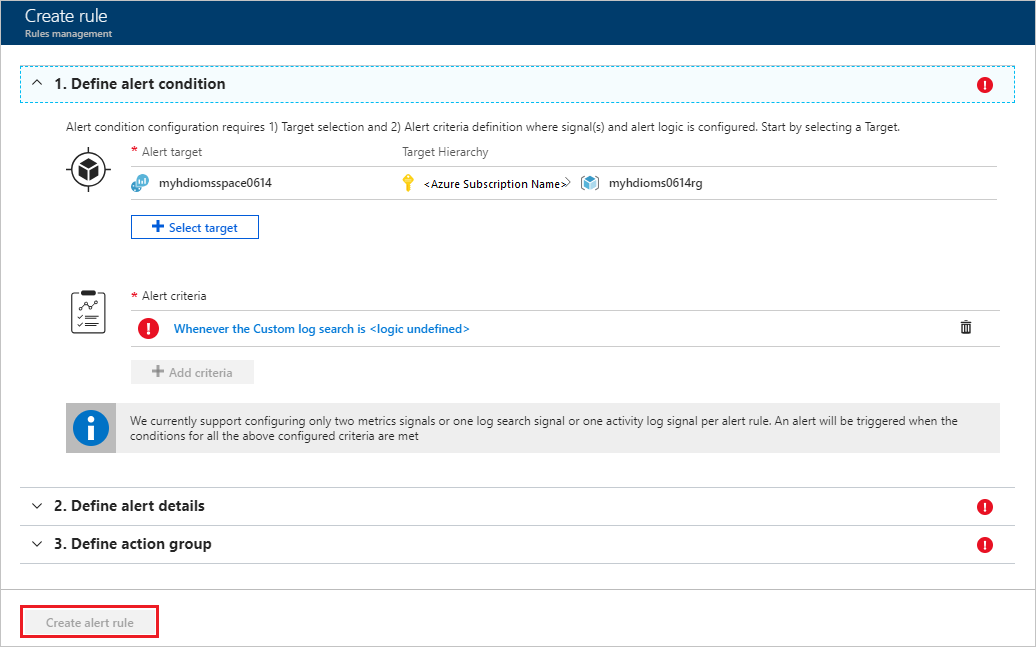
규칙 만들기 창에서 쿼리 및 기타 세부 정보를 입력하여 경고를 만든 다음, 경고 규칙 만들기를 선택합니다.
기존 경고를 편집 또는 삭제
Azure Portal에서 Log Analytics 작업 영역을 엽니다.
왼쪽 메뉴의 모니터링에서 메트릭을 선택합니다.
위쪽에서 경고 규칙 관리를 선택합니다.
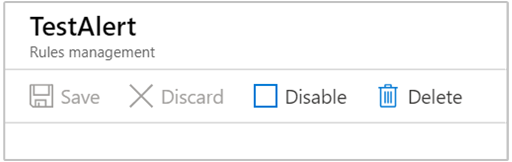
편집하거나 삭제하려는 경고를 선택합니다.
저장, 취소, 사용 안 함 및 삭제와 같은 옵션이 있습니다.
자세한 내용은 Azure Monitor를 사용하여 메트릭 경고 만들기, 보기 및 관리를 참조하세요.