MirrorMaker를 사용하여 HDInsight에서 Kafka와 함께 Apache Kafka 토픽 복제
Apache Kafka의 미러링 기능을 사용하여 토픽을 보조 클러스터로 복제하는 방법에 대해 알아봅니다. 미러링을 연속 프로세스로 또는 간헐적으로 실행하여 한 클러스터의 데이터를 다른 클러스터로 마이그레이션할 수 있습니다.
이 예제에서 미러링은 두 HDInsight 클러스터 간에 항목을 복제하는 데 사용됩니다. 두 클러스터는 서로 다른 데이터 센터의 다양한 가상 네트워크에 있습니다.
Warning
내결함성을 달성하기 위한 수단으로 미러링을 사용하지 마세요. 토픽 내 항목에 대한 오프셋은 주 클러스터와 보조 클러스터 간에 차이가 있으므로 클라이언트에서 이 두 가지를 서로 교환해서 사용할 수 없습니다. 내결함성이 염려되는 경우 클러스터 내의 토픽에 대한 복제를 설정해야 합니다. 자세한 내용은 HDInsight에서 Apache Kafka 시작을 참조하세요.
Apache Kafka 미러링 작동 방식
미러링은 Apache Kafka의 일부인 MirrorMaker 도구를 사용하여 작동합니다. MirrorMaker는 기본 클러스터의 토픽에서 레코드를 사용한 후 보조 클러스터에 로컬 복사본을 만듭니다. MirrorMaker는 기본 클러스터에서 불러온 한 개 이상의 소비자와 로컬 보조 클러스터에 작성하는 프로듀서를 사용합니다.
재해 복구에 가장 유용한 미러링 설정은 다양한 Azure 지역에서 Kafka 클러스터를 사용하는 것입니다. 이를 위해 클러스터가 있는 가상 네트워크는 함께 피어링됩니다.
다음 다이어그램에서는 미러링 프로세스와 클러스터 간 통신 흐름을 보여줍니다.
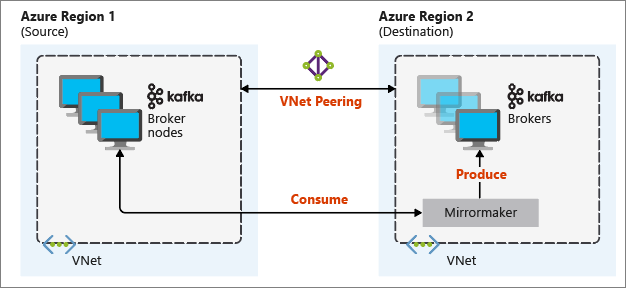
기본 및 보조 클러스터는 노드와 파티션 수에 따라 다를 수 있으며 토픽 내의 오프셋도 다릅니다. 미러링은 분할에 사용되는 키 값을 유지하므로 레코드 순서는 키 기준으로 유지됩니다.
네트워크 경계를 넘은 미러링
다른 네트워크의 Kafka 클러스터 간에 미러링해야 하는 경우 다음과 같은 추가 고려 사항이 있습니다.
게이트웨이: 네트워크는 TCP/IP 수준에서 통신할 수 있어야 합니다.
서버 주소 지정: IP 주소 또는 정규화된 도메인 이름을 사용하여 클러스터 노드를 처리하도록 선택할 수 있습니다.
IP 주소: IP 주소 광고를 사용하도록 Kafka 클러스터를 구성한 경우 broker 노드의 및 ZooKeeper 노드의 IP 주소를 사용하여 미러링 설정을 진행할 수 있습니다.
도메인 이름: IP 주소 광고에 대해 Kafka 클러스터를 구성하지 않은 경우 FQDN(정규화된 도메인 이름)을 사용하여 클러스터를 서로 연결할 수 있어야 합니다. 이렇게 하려면 요청을 다른 네트워크로 전달하도록 구성된 DNS(Domain Name System) 서버가 각 네트워크에 필요할 수 있습니다. Azure 가상 네트워크를 만들 때 네트워크와 함께 제공되는 자동 DNS를 사용하는 대신, 서버에 대한 사용자 지정 DNS 서버와 IP 주소를 지정해야 합니다. 가상 네트워크를 만든 후 해당 IP 주소를 사용하는 Azure 가상 머신을 만들어야 합니다. 그런 다음 DNS 소프트웨어를 설치하고 구성합니다.
Important
HDInsight를 가상 네트워크에 설치하기 전에 사용자 지정 DNS 서버를 만들고 구성합니다. HDInsight에서 가상 네트워크에 구성된 DNS 서버를 사용하기 위해 추가로 구성할 필요는 없습니다.
두 Azure 가상 네트워크 연결에 대한 자세한 내용은 연결 구성을 참조하세요.
미러링 아키텍처
이 아키텍처는 서로 다른 리소스 그룹과 가상 네트워크에 있는 두 개의 클러스터, 즉 주 클러스터와 보조 클러스터를 제공합니다.
생성 단계
두 리소스 그룹 생성:
Resource group 위치 kafka-primary-rg 미국 중부 kafka-secondary-rg 미국 중북부 kafka-primary-rg에서 새 가상 네트워크 kafka-primary-vnet을 만듭니다. 기본 설정을 그대로 둡니다.
kafka-secondary-rg에 새 가상 네트워크 kafka-secondary-vnet을 만들고, 역시 기본 설정대로 둡니다.
두 개의 새 Kafka 클러스터 생성:
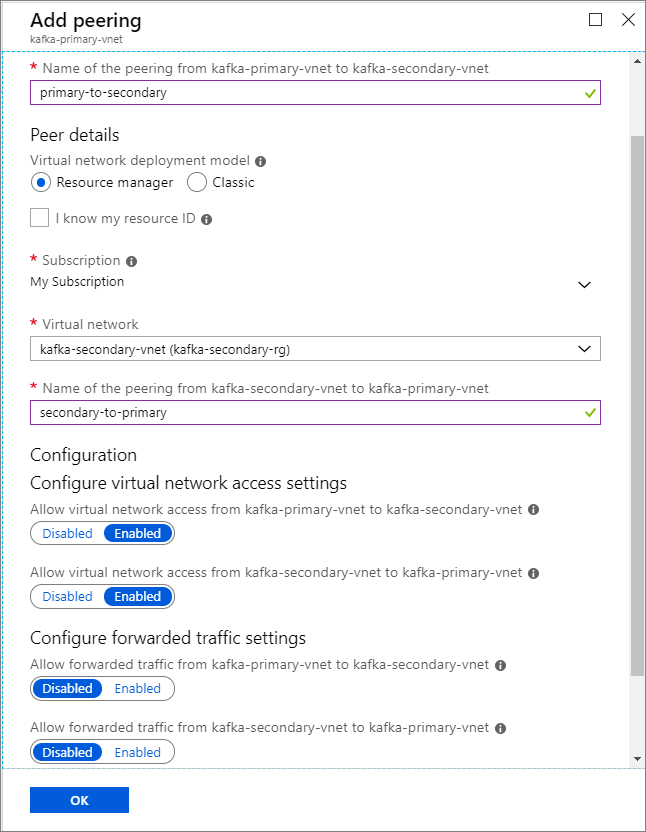
클러스터 이름 Resource group 가상 네트워크 스토리지 계정 kafka-primary-cluster kafka-primary-rg kafka-primary-vnet kafkaprimarystorage kafka-secondary-cluster kafka-secondary-rg kafka-secondary-vnet kafkasecondarystorage Virtual Network 피어링 생성. 이 단계에서는 kafka-primary-vnet에서 kafka-secondary-vnet으로, kafka-secondary-vnet에서 다시 kafka-primary-vnet으로 하나씩 연결되는 두 개의 피어링을 만듭니다.
kafka-primary-vnet 가상 네트워크를 선택합니다.
설정에서 피어링을 선택합니다.
추가를 선택합니다.
피어링 추가 화면에서 다음 스크린샷에 표시된 대로 세부 정보를 입력합니다.
IP 보급 구성
도메인 이름 대신 브로커 IP 주소를 사용하여 클라이언트에서 연결할 수 있도록 IP 광고를 구성합니다.
기본 클러스터에 대한 Ambari 대시보드로 이동합니다:
https://PRIMARYCLUSTERNAME.azurehdinsight.net.서비스>kafka를 선택합니다. Configs 탭을 선택합니다.
아래쪽 kafka-env template 섹션에 다음 구성 줄을 추가합니다. 저장을 선택합니다.
# Configure Kafka to advertise IP addresses instead of FQDN IP_ADDRESS=$(hostname -i) echo advertised.listeners=$IP_ADDRESS sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.properties구성 저장 화면에 메모를 입력하고 저장을 선택합니다.
구성 경고가 표시되면 계속 진행을 선택합니다.
구성 변경 내용 저장에서 확인을 선택합니다.
다시 시작 필요 알림에서 다시 시작>영향을 받는 모든 서비스 다시 시작을 선택합니다. 그런 다음 모두 다시 시작 확인을 선택합니다.
모든 네트워크 인터페이스에서 수신 대기하도록 Kafka 구성
- 서비스>kafka에서 Configs탭을 그대로 유지합니다. Kafka Broker 섹션에서 수신기 속성을
PLAINTEXT://0.0.0.0:9092로 설정합니다. - 저장을 선택합니다.
- 다시 시작>모두 다시 시작 확인을 선택합니다.
주 클러스터에 대한 broker IP 주소 및 ZooKeeper 주소 기록
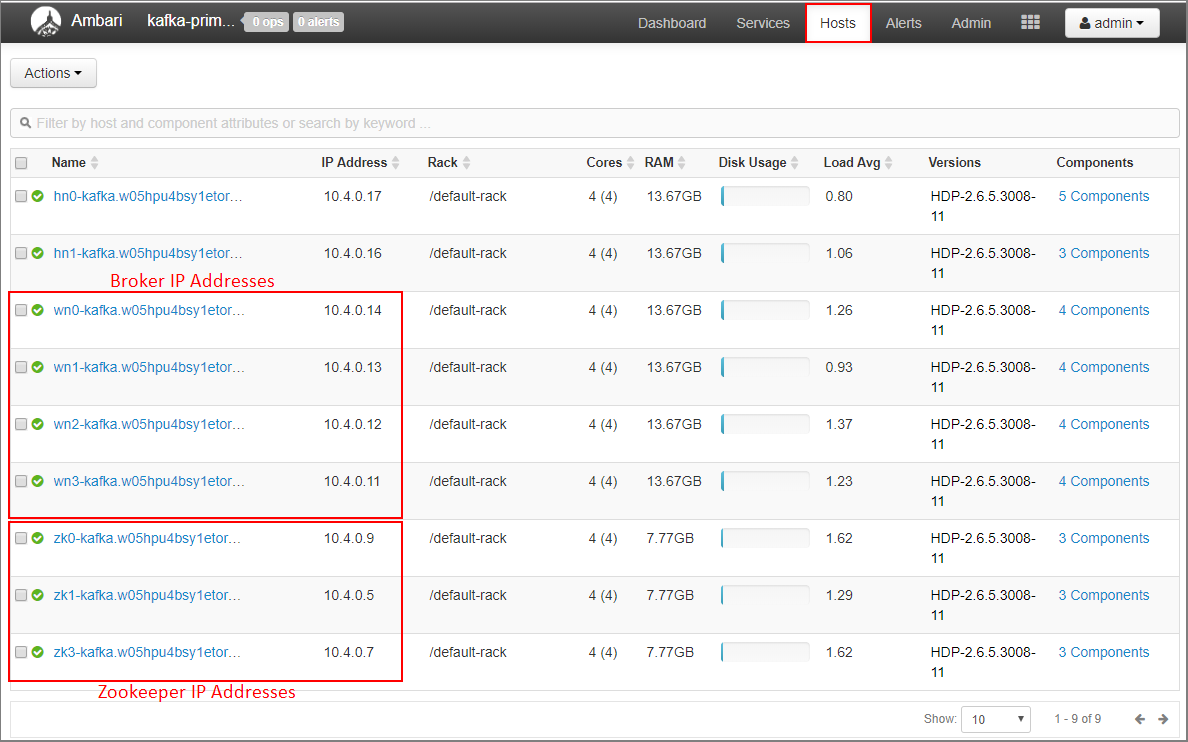
Ambari 대시보드에서 호스트를 선택합니다.
broker 및 ZooKeeper의 IP 주소를 기록해 둡니다. broker 노드에는 호스트 이름의 처음 두 문자로 wn, ZooKeeper 노드에는 호스트 이름의 처음 두 문자로 zk 가 있습니다.
두 번째 클러스터 kafka-secondary-cluster에서 앞의 세 단계를 반복합니다. 즉 IP 광고를 구성하고, 수신기를 설정하며, broker 및 ZooKeeper IP 주소를 기록합니다.
항목 만들기
SSH를 사용하여 주 클러스터에 연결합니다.
ssh sshuser@PRIMARYCLUSTER-ssh.azurehdinsight.net클러스터를 만들 때 사용한 SSH 사용자 이름으로
sshuser를 바꿉니다. 클러스터를 만들 때 사용한 기본 이름으로PRIMARYCLUSTER를 바꿉니다.자세한 내용은 HDInsight와 함께 SSH 사용을 참조하세요.
다음 명령을 사용하여 주 클러스터에 대한 Apache ZooKeeper 호스트 및 broker 호스트가 있는 두 개의 환경 변수를 만듭니다.
ZOOKEEPER_IP_ADDRESS1같은 문자열은 이전에 기록된 실제 IP 주소(10.23.0.11,10.23.0.7등)로 바꾸어야 합니다.BROKER_IP_ADDRESS1에 대해서도 마찬가지입니다. 사용자 지정 DNS 서버에서 FQDN 해결을 사용하는 경우, 다음 단계에 따라 broker 및 ZooKeeper 이름을 가져옵니다.# get the ZooKeeper hosts for the primary cluster export PRIMARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181, ZOOKEEPER_IP_ADDRESS2:2181, ZOOKEEPER_IP_ADDRESS3:2181' # get the broker hosts for the primary cluster export PRIMARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'testtopic이라는 토픽을 만들려면 다음 명령을 사용합니다./usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $PRIMARY_ZKHOSTS다음 명령을 사용하여 토픽이 만들어졌는지 확인합니다.
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $PRIMARY_ZKHOSTS응답에
testtopic이 있습니다.다음을 사용하여 이(기본) 클러스터에 대한 broker 호스트 정보를 봅니다.
echo $PRIMARY_BROKERHOSTS이 명령은 다음 텍스트와 비슷한 정보를 반환합니다.
10.23.0.11:9092,10.23.0.7:9092,10.23.0.9:9092이 정보를 저장합니다. 해당 정보는 다음 섹션에서 사용됩니다.
미러링 구성
다른 SSH 세션을 사용하여 보조 클러스터에 연결합니다.
ssh sshuser@SECONDARYCLUSTER-ssh.azurehdinsight.net클러스터를 만들 때 사용한 SSH 사용자 이름으로
sshuser를 바꿉니다. 클러스터를 만들 때 사용한 이름으로SECONDARYCLUSTER를 바꿉니다.자세한 내용은 HDInsight와 함께 SSH 사용을 참조하세요.
consumer.properties파일을 사용하여 주 클러스터와의 통신을 구성합니다. 파일을 만들려면 다음 명령을 사용합니다.nano consumer.propertiesconsumer.properties파일의 내용으로 다음 텍스트를 사용합니다.bootstrap.servers=PRIMARY_BROKERHOSTS group.id=mirrorgroup주 클러스터의 브로커 호스트 IP 주소로
PRIMARY_BROKERHOSTS를 바꿉니다.이 파일은 기본 Kafka 클러스터에서 읽을 때 사용할 소비자 정보를 설명합니다. 자세한 내용은
kafka.apache.org에서 소비자 구성을 참조하세요.파일을 저장하려면 Ctrl+X를 누른 다음 Y 키와 Enter 키를 차례로 누릅니다.
보조 클러스터와 통신하는 프로듀서를 구성하기 전에 보조 클러스터의 broker IP 주소에 대한 변수를 설정합니다. 다음 명령을 사용하여 이러한 변수를 만듭니다:
export SECONDARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'명령은 다음 텍스트와 비슷한 정보를 반환해야 합니다.
10.23.0.14:9092,10.23.0.4:9092,10.23.0.12:9092producer.properties파일을 사용하여 보조 클러스터와 통신합니다. 파일을 만들려면 다음 명령을 사용합니다.nano producer.propertiesproducer.properties파일의 내용으로 다음 텍스트를 사용합니다.bootstrap.servers=SECONDARY_BROKERHOSTS compression.type=noneSECONDARY_BROKERHOSTS를 이전 단계에서 사용된 broker IP 주소로 바꿉니다.자세한 내용은
kafka.apache.org에서 프로듀서 구성을 참조하세요.다음 명령을 사용하여 보조 클러스터용 ZooKeeper 호스트의 IP 주소로 환경 변수를 만듭니다.
# get the ZooKeeper hosts for the secondary cluster export SECONDARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181,ZOOKEEPER_IP_ADDRESS2:2181,ZOOKEEPER_IP_ADDRESS3:2181'HDInsight의 Kafka에 대한 기본 구성이 토픽의 자동 생성을 허용하지 않습니다. 미러링 프로세스를 시작하기 전에 다음 옵션 중 하나를 사용해야 합니다.
보조 클러스터에 토픽 생성하기: 이 옵션을 사용하면 파티션 및 복제 요소의 수를 설정할 수 있습니다.
다음 명령을 사용하여 사전에 토픽을 만들 수 있습니다.
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $SECONDARY_ZKHOSTStesttopic을 만들려는 토픽의 이름으로 바꿉니다.자동 토픽을 만들기 위한 클러스터 구성: 이 옵션을 사용하면 MirrorMaker에서 토픽을 자동으로 만들 수 있습니다. 주 항목과 다른 수의 파티션 또는 다른 복제 요소를 사용하여 만들 수 있습니다.
자동으로 토픽을 생성하도록 보조 클러스터를 구성하려면 이러한 단계를 수행합니다.
- 보조 클러스터에 대한 Ambari 대시보드로 이동합니다:
https://SECONDARYCLUSTERNAME.azurehdinsight.net. - 서비스>kafka를 선택합니다. 그런 다음 구성 탭을 선택합니다.
- 필터 필드에
auto.create값을 입력합니다. 이렇게 하면 속성 목록이 필터링되고auto.create.topics.enable설정이 표시됩니다. auto.create.topics.enable값을true로 변경하고 저장을 선택합니다. 메모를 추가하고 저장을 다시 선택합니다.- Kafka 서비스를 선택하고 다시 시작을 선택한 후 영향을 받는 모든 서비스 다시 시작을 선택합니다. 메시지가 나타나면 모두 다시 시작 확인을 선택합니다.
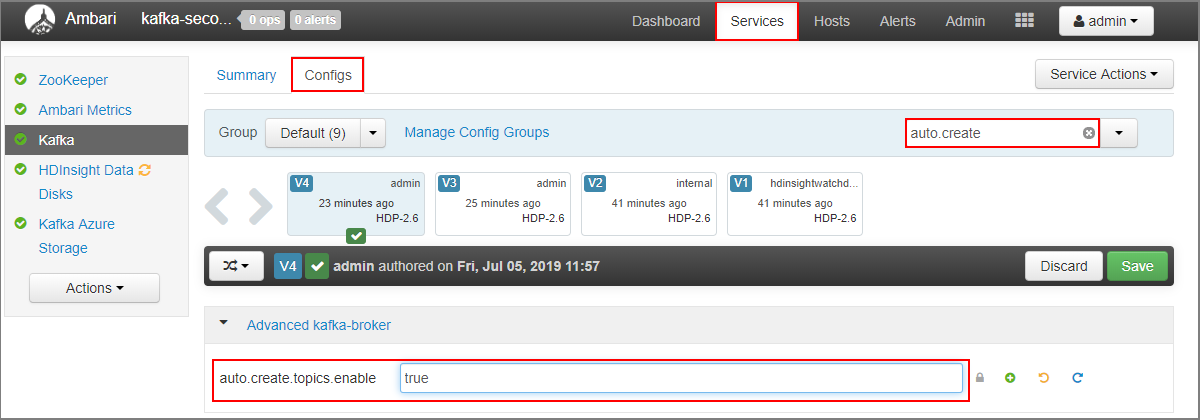
- 보조 클러스터에 대한 Ambari 대시보드로 이동합니다:
MirrorMaker 시작
참고 항목
이 문서에는 Microsoft에서 더 이상 사용하지 않는 용어에 대한 참조가 포함되어 있습니다. 소프트웨어에서 용어가 제거되면 이 문서에서 해당 용어가 제거됩니다.
보조 클러스터에 대한 SSH 연결에서 다음 명령을 사용하여 MirrorMaker 프로세스를 시작합니다.
/usr/hdp/current/kafka-broker/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer.properties --producer.config producer.properties --whitelist testtopic --num.streams 4이 예제에 사용된 매개 변수는 다음과 같습니다.
매개 변수 설명 --consumer.config소비자 속성이 포함된 파일을 지정합니다. 이러한 속성은 기본 Kafka 클러스터에서 읽는 소비자를 만드는 데 사용됩니다. --producer.config생산자 속성이 포함된 파일을 지정합니다. 이러한 속성은 보조 Kafka 클러스터에 쓰는 프로듀서를 만드는 데 사용됩니다. --whitelistMirrorMaker로 기본 클러스터에서 보조 클러스터로 복제하는 토픽의 목록. --num.streams생성할 소비자 스레드 수입니다. 보조 노드의 소비자는 이제 메시지 수신을 대기하고 있습니다.
SSH 연결부터 기본 클러스터까지 다음 명령을 사용하여 생산자를 시작하고 토픽에 메시지를 전송합니다.
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $PRIMARY_BROKERHOSTS --topic testtopic커서로 빈 라인에 도달하면 몇 개의 텍스트 메시지를 입력합니다. 메시지는 기본 클러스터의 토픽으로 보내집니다. 완료되면 Ctrl+C를 눌러 프로듀서 프로세스를 종료합니다.
보조 클러스터에 대한 SSH 연결에서 Ctrl+C를 눌러 MirrorMaker 프로세스를 종료합니다. 해당 프로세스를 종료하는 데 몇 초 정도 걸릴 수 있습니다. 메시지가 보조에 복제되었는지 확인하려면 다음 명령을 사용합니다.
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $SECONDARY_BROKERHOSTS --topic testtopic --from-beginning이제 토픽 목록에 MirrorMaster가 기본 클러스터에서 보조로 토픽을 미러링할 때 만들어진
testtopic이(가) 포함됩니다. 이 항목에서 검색한 메시지는 기본 클러스터에 입력한 것과 동일합니다.
클러스터 삭제
Warning
HDInsight 클러스터에 대한 청구는 사용 여부에 관계없이 분 단위로 비례 배분됩니다. 클러스터는 사용한 후에 삭제해야 합니다. HDInsight 클러스터를 삭제하는 방법을 참조하세요.
이 문서의 단계에서는 다른 Azure 리소스 그룹에 클러스터를 만들었습니다. 만든 리소스를 모두 삭제하려면, kafka-primary-rg 및 kafka-secondary-rg의 만든 두 리소스 그룹을 삭제하면 됩니다. 리소스 그룹을 삭제하면 클러스터, 가상 네트워크, 스토리지 계정 등 이 문서를 따라 만든 리소스가 모두 제거됩니다.
다음 단계
이 문서에서는 MirrorMaker를 사용하여 Apache Kafka 클러스터의 복제본을 만드는 방법을 알아보았습니다. Kafka를 사용하는 다른 방법을 찾으려면 다음 링크를 사용하세요.