이 빠른 시작에서는 ARM 템플릿(Azure Resource Manager 템플릿)을 사용하여 Azure HDInsight에서 Apache Spark 클러스터를 만듭니다. 그런 다음, Jupyter Notebook 파일을 만들고 이를 사용하여 Apache Hive 테이블에 대해 Spark SQL 쿼리를 실행합니다. Azure HDInsight는 엔터프라이즈를 위한 관리형의 전체 스펙트럼 오픈 소스 분석 서비스입니다. HDInsight용 Apache Spark 프레임워크를 통해 메모리 내 처리 기능을 사용하여 데이터 분석 및 클러스터 컴퓨팅을 신속하게 처리합니다. Jupyter Notebook을 사용하면 데이터와 상호 작용하고, 코드를 markdown 텍스트와 결합하고, 간단한 시각화를 수행할 수 있습니다.
여러 클러스터를 함께 사용하는 경우 가상 네트워크를 만들고, Spark 클러스터를 사용하는 경우 Hive Warehouse Connector도 사용하는 것이 좋습니다. 자세한 내용은 Azure HDInsight에 대한 가상 네트워크 계획 및 Hive Warehouse Connector를 사용하여 Apache Spark 및 Apache Hive 통합을 참조하세요.
Azure Resource Manager 템플릿은 프로젝트에 대한 인프라 및 구성을 정의하는 JSON(JavaScript Object Notation) 파일입니다. 이 템플릿은 선언적 구문을 사용합니다. 배포를 만들기 위한 프로그래밍 명령의 시퀀스를 작성하지 않고 의도하는 배포를 설명합니다.
환경이 필수 구성 요소를 충족하고 ARM 템플릿 사용에 익숙한 경우 Azure에 배포 단추를 선택합니다. 그러면 Azure Portal에서 템플릿이 열립니다.

필수 조건
Azure 구독이 없는 경우, 시작하기 전에 무료 계정을 만드십시오.
템플릿 검토
이 빠른 시작에서 사용되는 템플릿은 Azure 빠른 시작 템플릿에서 나온 것입니다.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"metadata": {
"_generator": {
"name": "bicep",
"version": "0.5.6.12127",
"templateHash": "4742950082151195489"
}
},
"parameters": {
"clusterName": {
"type": "string",
"metadata": {
"description": "The name of the HDInsight cluster to create."
}
},
"clusterLoginUserName": {
"type": "string",
"maxLength": 20,
"minLength": 2,
"metadata": {
"description": "These credentials can be used to submit jobs to the cluster and to log into cluster dashboards. The username must consist of digits, upper or lowercase letters, and/or the following special characters: (!#$%&'()-^_`{}~)."
}
},
"clusterLoginPassword": {
"type": "secureString",
"minLength": 10,
"metadata": {
"description": "The password must be at least 10 characters in length and must contain at least one digit, one upper case letter, one lower case letter, and one non-alphanumeric character except (single-quote, double-quote, backslash, right-bracket, full-stop). Also, the password must not contain 3 consecutive characters from the cluster username or SSH username."
}
},
"sshUserName": {
"type": "string",
"minLength": 2,
"metadata": {
"description": "These credentials can be used to remotely access the cluster. The sshUserName can only consit of digits, upper or lowercase letters, and/or the following special characters (%&'^_`{}~). Also, it cannot be the same as the cluster login username or a reserved word"
}
},
"sshPassword": {
"type": "secureString",
"maxLength": 72,
"minLength": 6,
"metadata": {
"description": "SSH password must be 6-72 characters long and must contain at least one digit, one upper case letter, and one lower case letter. It must not contain any 3 consecutive characters from the cluster login name"
}
},
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]",
"metadata": {
"description": "Location for all resources."
}
},
"headNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the headnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"workerNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the workernode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
}
},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2021-08-01",
"name": "[format('storage{0}', uniqueString(resourceGroup().id))]",
"location": "[parameters('location')]",
"sku": {
"name": "Standard_LRS"
},
"kind": "StorageV2"
},
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('clusterName')]",
"location": "[parameters('location')]",
"properties": {
"clusterVersion": "4.0",
"osType": "Linux",
"tier": "Standard",
"clusterDefinition": {
"kind": "spark",
"configurations": {
"gateway": {
"restAuthCredential.isEnabled": true,
"restAuthCredential.username": "[parameters('clusterLoginUserName')]",
"restAuthCredential.password": "[parameters('clusterLoginPassword')]"
}
}
},
"storageProfile": {
"storageaccounts": [
{
"name": "[replace(replace(reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))).primaryEndpoints.blob, 'https://', ''), '/', '')]",
"isDefault": true,
"container": "[parameters('clusterName')]",
"key": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))), '2021-08-01').keys[0].value]"
}
]
},
"computeProfile": {
"roles": [
{
"name": "headnode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('headNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "workernode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('workerNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
}
]
}
},
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))]"
]
}
],
"outputs": {
"storage": {
"type": "object",
"value": "[reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))))]"
},
"cluster": {
"type": "object",
"value": "[reference(resourceId('Microsoft.HDInsight/clusters', parameters('clusterName')))]"
}
}
}
템플릿에는 두 개의 Azure 리소스가 정의되어 있습니다.
- Microsoft.Storage/storageAccounts: Azure Storage 계정을 만듭니다.
- Microsoft.HDInsight/cluster: HDInsight 클러스터를 만듭니다.
템플릿 배포
아래 Azure에 배포 단추를 선택하여 Azure에 로그인하고 ARM 템플릿을 엽니다.
다음 값을 입력하거나 선택합니다.
속성 Description Subscription 드롭다운 목록에서 클러스터에 사용할 Azure 구독을 선택합니다. 리소스 그룹 드롭다운 목록에서 기존 리소스 그룹을 선택하거나 새로 만들기를 선택합니다. 위치 이 값은 리소스 그룹에 사용되는 위치로 자동 입력됩니다. 클러스터 이름 글로벌로 고유한 이름을 입력합니다. 이 템플릿의 경우 소문자와 숫자만 사용합니다. 클러스터 로그인 사용자 이름 사용자 이름을 입력합니다. 기본값은 admin입니다.클러스터 로그인 암호 암호를 입력합니다. 암호는 10자 이상이어야 하며, 숫자, 대문자, 소문자 및 영숫자가 아닌 문자( ' ` "문자 제외)를 각각 하나 이상 포함해야 합니다.SSH 사용자 이름 사용자 이름을 입력합니다. 기본값은 sshuser입니다.SSH 암호 암호를 입력합니다. 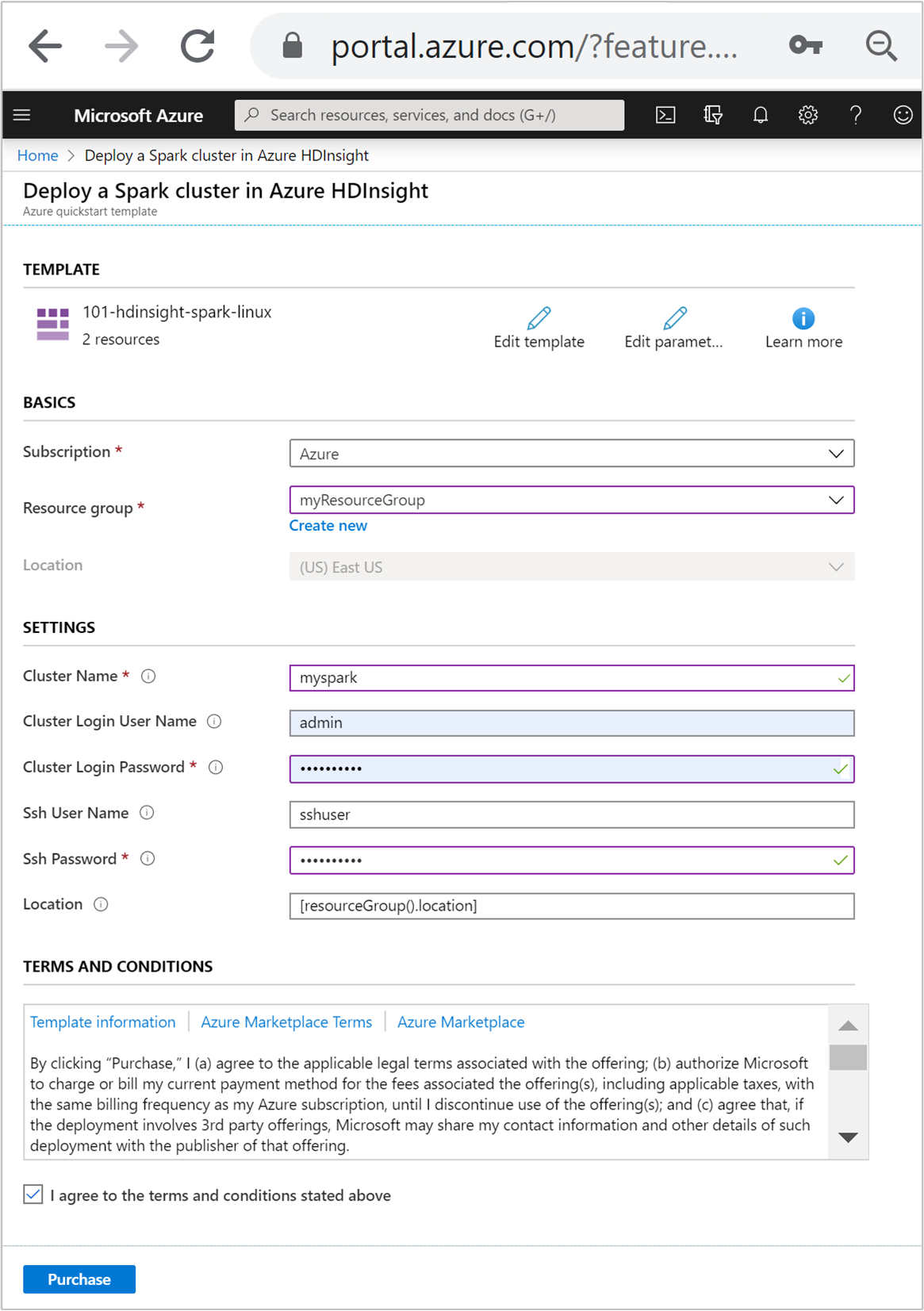
사용 약관을 검토합니다. 그런 다음, 위에 명시된 사용 약관에 동의함을 선택한 다음, 구매를 선택합니다. 배포가 진행 중이라는 알림이 표시됩니다. 클러스터를 만들려면 20분 정도가 걸립니다.
HDInsight 클러스터를 만드는 데 문제가 발생하는 경우 이를 수행하기 위한 적절한 사용 권한이 없을 수 있습니다. 자세한 내용은 액세스 제어 요구 사항을 참조하세요.
배포된 리소스 검토
클러스터가 만들어지면 리소스로 이동 링크가 포함된 배포 성공 알림이 표시됩니다. 리소스 그룹 페이지에 새 HDInsight 클러스터와 해당 클러스터에 연결된 기본 스토리지가 나열됩니다. 각 클러스터에는 Azure Storage 또는 Azure Data Lake Storage Gen2 종속성이 있습니다. 이 스토리지 계정을 기본 스토리지 계정이라고 합니다. HDInsight 클러스터와 해당 기본 스토리지 계정은 같은 Azure 지역에 있어야 합니다. 클러스터를 삭제해도 스토리지 계정 종속성은 삭제되지 않습니다. 이 스토리지 계정을 기본 스토리지 계정이라고 합니다. HDInsight 클러스터와 해당 기본 스토리지 계정은 같은 Azure 지역에 있어야 합니다. 클러스터를 삭제하더라도 스토리지 계정은 삭제되지 않습니다.
Jupyter Notebook 파일 만들기
Jupyter Notebook은 다양한 프로그래밍 언어를 지원하는 대화형 Notebook 환경입니다. Jupyter Notebook 파일을 사용하여 데이터와 상호 작용하고, 코드를 markdown 텍스트와 결합하고, 간단한 시각화를 수행할 수 있습니다.
Azure Portal을 엽니다.
HDInsight 클러스터를 선택한 다음, 만든 클러스터를 선택합니다.
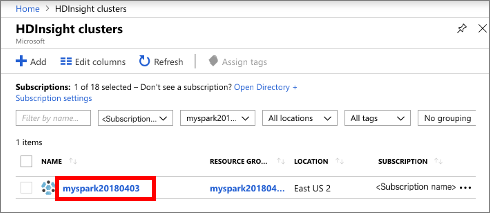
포털의 클러스터 대시보드 섹션에서 Jupyter Notebook을 선택합니다. 메시지가 표시되면 클러스터에 대한 클러스터 로그인 자격 증명을 입력합니다.
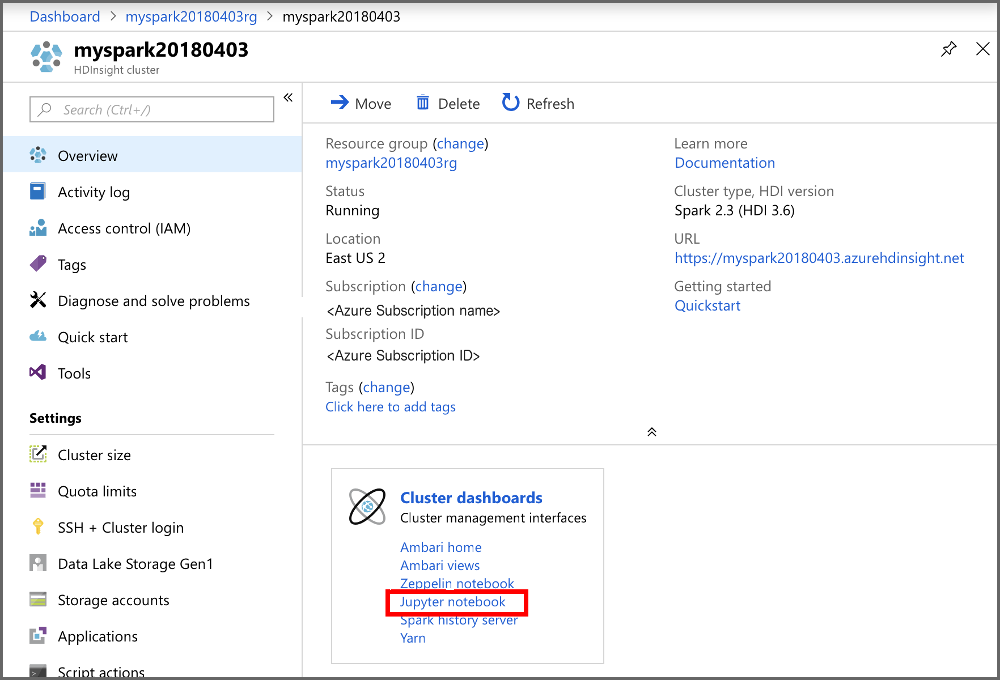
새로 만들기>PySpark를 선택하여 Notebook을 만듭니다.
새 Notebook이 만들어지고 Untitled(Untitled.pynb) 이름으로 열립니다.
Apache Spark SQL 문 실행
SQL(구조적 쿼리 언어)은 데이터 쿼리 및 변환에 가장 일반적이며 널리 사용되는 언어입니다. Spark SQL은 익숙한 SQL 구문을 사용하여 구조화된 데이터를 처리하기 위한 Apache Spark에 대한 확장으로 작동합니다.
커널이 준비되었는지 확인합니다. Notebook의 커널 이름 옆에 속이 빈 원이 보이면 커널이 준비된 것입니다. 속이 찬 원은 커널이 사용 중이라는 뜻입니다.
 alt-text="Kernel status." border="true":::
alt-text="Kernel status." border="true":::Notebook을 처음으로 시작하면 커널이 백그라운드에서 몇 가지 작업을 수행합니다. 커널이 준비될 때까지 기다립니다.
빈 셀에 다음 코드를 붙여 넣은 다음, SHIFT + ENTER를 눌러 코드를 실행합니다. 이 명령은 클러스터의 Hive 테이블을 나열합니다.
%%sql SHOW TABLESJupyter Notebook 파일을 HDInsight 클러스터와 함께 사용하는 경우 Spark SQL을 사용하여 Hive 쿼리를 실행하는 데 사용할 수 있는 미리 설정된
spark세션이 제공됩니다.%%sql은 Jupyter Notebook에 미리 설정된spark세션을 사용하여 Hive 쿼리를 실행하도록 지시합니다. 쿼리는 기본적으로 모든 HDInsight 클러스터와 함께 제공되는 Hive 테이블(hivesampletable)에서 상위 10개의 행을 검색합니다. 처음으로 쿼리를 제출할 때 Jupyter는 Notebook에 대한 Spark 애플리케이션을 만듭니다. 완료하는 데 약 30초가 걸립니다. Spark 애플리케이션이 준비되면 약 1초 후 쿼리가 실행되어 결과를 생성합니다. 출력은 다음과 같습니다.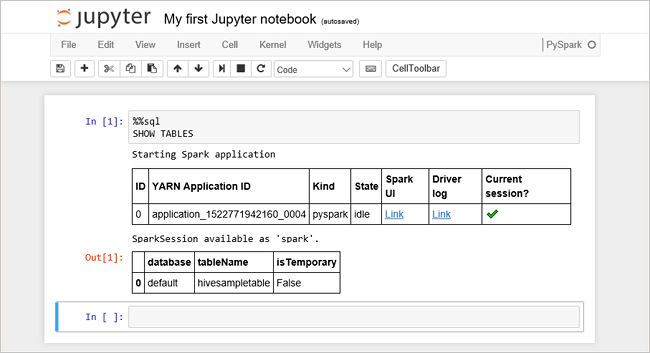 y in HDInsight" border="true":::
y in HDInsight" border="true":::Jupyter에서 쿼리를 실행할 때마다, 웹 브라우저 창 제목에 Notebook 제목과 함께 (사용 중) 상태가 표시됩니다. 또한 오른쪽 위 모서리에 있는 PySpark 텍스트 옆에 단색 원이 표시됩니다.
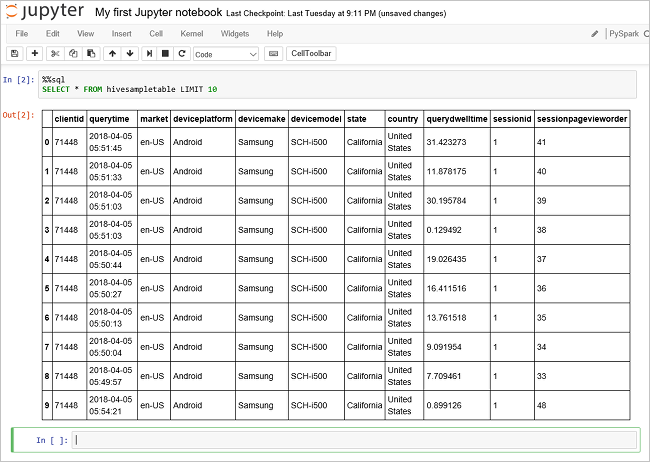
또 다른 쿼리를 실행하여
hivesampletable의 데이터를 봅니다.%%sql SELECT * FROM hivesampletable LIMIT 10쿼리 출력이 표시되도록 화면이 새로 고쳐집니다.
 Insight" border="true":::
Insight" border="true":::Notebook의 파일 메뉴에서 닫기 및 중지를 선택합니다. Notebook을 종료하면 Spark 애플리케이션을 비롯한 클러스터 리소스가 릴리스됩니다.
리소스 정리
빠른 시작을 완료한 후 클러스터를 삭제하는 것이 좋습니다. HDInsight를 사용하면 데이터가 Azure Storage에 저장되기 때문에 클러스터를 사용하지 않을 때 안전하게 삭제할 수 있습니다. HDInsight 클러스터를 사용하지 않는 기간에도 요금이 청구됩니다. 클러스터에 대한 요금이 스토리지에 대한 요금보다 몇 배 더 많기 때문에, 클러스터를 사용하지 않을 때는 삭제하는 것이 경제적인 면에서 더 합리적입니다.
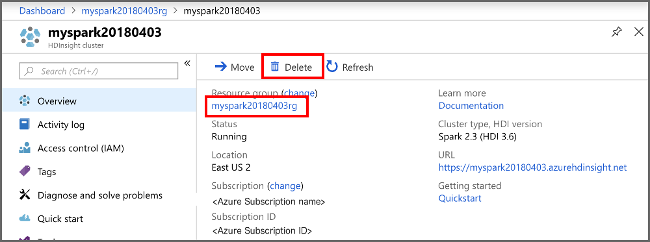
Azure Portal에서 클러스터로 이동하여 삭제를 선택합니다.
 sight cluster" border="true":::
sight cluster" border="true":::
또한 리소스 그룹 이름을 선택하여 리소스 그룹 페이지를 연 다음, 리소스 그룹 삭제를 선택할 수도 있습니다. 리소스 그룹을 삭제하여 HDInsight 클러스터와 기본 스토리지 계정을 삭제합니다.
다음 단계
이 빠른 시작에서는 HDInsight에서 Apache Spark 클러스터를 만들고 기본 Spark SQL 쿼리를 실행하는 방법을 알아보았습니다. 다음 자습서를 진행하여 샘플 데이터에서 대화형 쿼리를 실행하는 데 HDInsight 클러스터를 사용하는 방법에 대해 알아보세요.