Apache Spark 설정 구성
HDInsight Spark 클러스터에는 Apache Spark 라이브러리 설치가 포함되어 있습니다. 각 HDInsight 클러스터에는 Spark를 비롯하여 설치된 모든 서비스에 대한 기본 구성 매개 변수가 포함되어 있습니다. HDInsight Apache Hadoop 클러스터 관리의 핵심은 Spark 작업을 비롯한 작업을 모니터링하는 것입니다. Spark 작업을 가장 잘 실행하려면 클러스터의 논리적 구성을 결정할 때 실제 클러스터 구성을 고려해야 합니다.
기본 HDInsight Apache Spark 클러스터에는 3개의 Apache ZooKeeper 노드, 2개의 헤드 노드 및 하나 이상의 작업자 노드가 포함되어 있습니다.
HDInsight 클러스터 노드의 VM 수 및 VM 크기는 Spark 구성에 영향을 미칠 수 있습니다. 기본이 아닌 HDInsight 구성 값을 사용하려면 종종 기본이 아닌 Spark 구성 값이 필요합니다. HDInsight Spark 클러스터를 만드는 경우 각 구성 요소에 대한 제안된 VM 크기가 표시됩니다. 현재, Azure에 대한 메모리 최적화 Linux VM 크기는 D12 v2 이상입니다.
Apache Spark 버전
클러스터에 최적의 Spark 버전을 사용합니다. HDInsight 서비스에는 여러 버전의 Spark 및 HDInsight가 포함되어 있습니다. Spark의 각 버전에는 기본 클러스터 설정 집합이 포함됩니다.
새 클러스터를 만들 때 여러 Spark 버전 중에서 선택할 수 있습니다. 전체 목록을 보려면 HDInsight 구성 요소 및 버전을 참조하세요.
참고 항목
HDInsight 서비스에서 Apache Spark의 기본 버전은 예고 없이 변경될 수 있습니다. 버전 종속성이 있는 경우 .NET SDK/Azure PowerShell 및 Azure 클래식 CLI를 사용하여 클러스터를 만들 때 특정 버전을 지정하는 것이 좋습니다.
Apache Spark에는 다음과 같은 3가지 시스템 구성 위치가 있습니다.
- Spark 속성은 대부분의 애플리케이션 매개 변수를 제어하며,
SparkConf개체 또는 Java 시스템 속성을 통해 설정할 수 있습니다. - 각 노드의
conf/spark-env.sh스크립트를 통해, IP 주소와 같은 컴퓨터별 설정을 지정하는 데 환경 변수를 사용할 수 있습니다. - 로깅은
log4j.properties를 통해 구성할 수 있습니다.
특정 Spark 버전을 선택하면 클러스터에 기본 구성 설정이 포함됩니다. 사용자 지정 Spark 구성 파일을 사용하여 기본 Spark 구성 값을 변경할 수 있습니다. 아래에 예제가 나와 있습니다.
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
위에 표시된 예제는 5개의 Spark 구성 매개 변수에 대한 몇 가지 기본값을 재정의합니다. 이러한 값은 Apache Hadoop MapReduce 분할 최소 크기 및 parquet 블록 크기의 압축 코덱입니다. 또한 Spark SQL 파티션 및 열려 있는 파일 크기 기본값이 여기에 해당합니다. 이러한 구성 변경은 관련 데이터 및 작업(이 예제에서는 게놈 데이터)이 특정 특성을 갖기 때문에 선택되었습니다. 이러한 특성은 사용자 지정 구성 설정을 사용할 때 더 좋습니다.
클러스터 구성 설정 보기
클러스터에서 성능 최적화를 수행하기 전에, 현재 HDInsight 클러스터 구성 설정을 확인합니다. Spark 클러스터 창에서 대시보드 링크를 클릭하여 Azure Portal에서 HDInsight 대시보드를 시작합니다. 클러스터 관리자의 사용자 이름 및 암호로 로그인합니다.
핵심 클러스터 리소스 사용 현황 메트릭의 대시보드를 포함하는 Apache Ambari 웹 UI가 표시됩니다. Ambari 대시보드에는 Apache Spark 구성 및 설치한 다른 서비스가 표시됩니다. 대시보드에는 Spark를 포함하여 설치된 서비스에 대한 정보를 볼 수 있는 구성 기록 탭이 포함되어 있습니다.
Apache Spark에 대한 구성 값을 표시하려면 구성 기록을 선택한 후 Spark2를 선택합니다. 구성 탭을 선택하고 서비스 목록에서 Spark(또는 사용 중인 버전에 따라 Spark2) 링크를 선택합니다. 클러스터에 대한 구성 값 목록을 확인합니다.
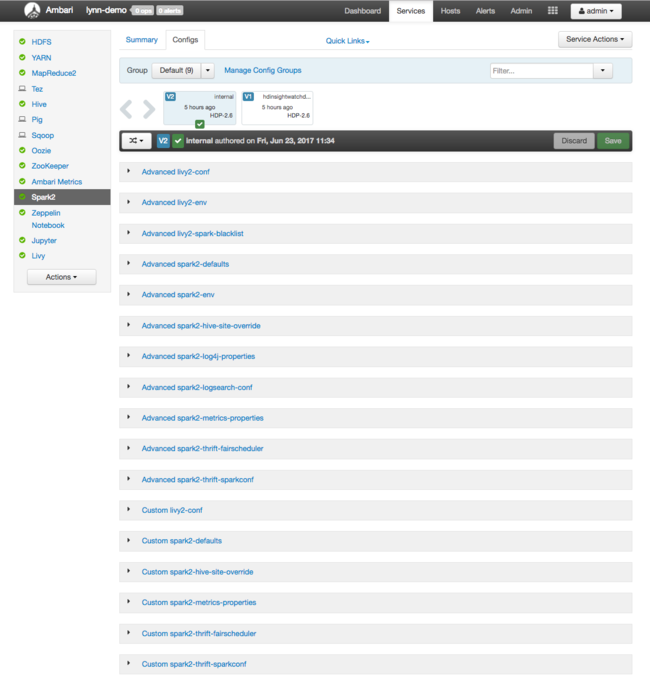
개별 Spark 구성 값을 보거나 변경하려면 제목에서 "spark"가 있는 링크를 선택합니다. Spark에 대한 구성에는 다음 범주의 사용자 지정 및 고급 구성 값이 모두 포함됩니다.
- 사용자 지정 Spark2-defaults
- 사용자 지정 Spark2-metrics-properties
- 고급 Spark2-defaults
- 고급 Spark2-env
- 고급 spark2-hive-site-override
기본이 아닌 구성 값 집합을 만드는 경우 업데이트 기록이 표시됩니다. 이 구성 기록은 기본이 아닌 구성 중에서 최적 성능을 나타내는 구성을 확인하는 데도 유용할 수 있습니다.
참고 항목
일반적인 Spark 클러스터 구성 설정을 변경하지는 않고 보기만 하려면 최상위 Spark 작업 UI 인터페이스에서 환경 탭을 선택합니다.
Spark 실행기 구성
다음 다이어그램은 핵심 Spark 개체에 해당하는 드라이버 프로그램과 해당 관련 Spark 컨텍스트, 클러스터 관리자 및 해당 n 작업자 노드를 나타냅니다. 각 작업자 노드에는 실행기, 캐시 및 n 태스크 인스턴스가 포함됩니다.
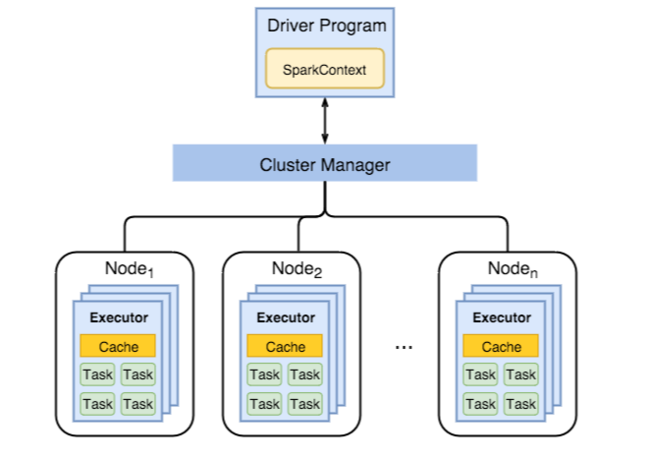
Spark 작업은 작업자 리소스, 특히 메모리를 사용하므로, 작업자 노드 실행기에 대한 Spark 구성 값을 조정하는 것이 일반적입니다.
애플리케이션 요구 사항을 개선하기 위해 Spark 구성 조정을 위해 수정되는 3가지 핵심 매개 변수는 spark.executor.instances, spark.executor.cores 및 spark.executor.memory입니다. 실행자는 Spark 애플리케이션을 위해 시작된 프로세스입니다. 실행기는 작업자 노드에서 실행되며 애플리케이션에 대한 작업을 담당합니다. 작업자 노드 및 작업자 노드 크기의 개수에 따라 실행기 개수와 실행기 크기가 결정됩니다. 값은 클러스터 헤드 노드의 spark-defaults.conf 에 저장됩니다. Ambari Web UI에서 사용자 지정 spark-defaults를 선택하여 실행 중인 클러스터에서 이러한 값을 편집할 수 있습니다. 변경한 후에는 UI에 영향 받은 모든 서비스를 다시 시작하라는 메시지가 표시됩니다.
참고 항목
이러한 세 가지 구성 매개 변수는 (클러스터에서 실행된는 모든 애플리케이션의 경우) 클러스터 수준에서 구성될 수도 있고, 각 개별 애플리케이션에 대해 지정될 수도 있습니다.
Spark 실행기에서 사용되는 리소스에 대한 또 다른 정보원은 Spark 애플리케이션 UI입니다. UI에서 실행기에는 구성과 사용된 리소스의 Device 요약 보기 및 자세히 보기가 표시됩니다. 전체 클러스터와 특정 작업 실행에 대한 실행기 값 중 어떤 것을 변경할지 결정합니다.
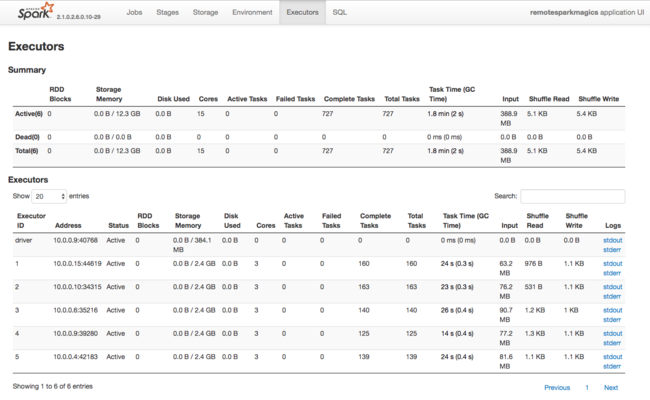
또는 Ambari REST API를 사용하여 HDInsight 및 Spark 클러스터 구성 설정을 프로그래매틱 방식으로 확인할 수 있습니다. 자세한 내용은 GitHub의 Apache Ambari API 참조를 참조하세요.
Spark 워크로드에 따라 기본이 아닌 Spark 구성을 사용하여 보다 최적화된 Spark 작업 실행이 제공되는지 확인할 수 있습니다. 샘플 워크로드로 벤치마크 테스트를 수행하여 기본이 아닌 클러스터 구성의 유효성을 검사합니다. 조정을 고려할 수 있는 몇 가지 일반적인 매개 변수는 다음과 같습니다.
| 매개 변수 | 설명 |
|---|---|
| --num-executors | 실행기 수를 설정합니다. |
| --executor-cores | 각 실행기의 코어 수를 설정합니다. 다른 프로세스도 사용 가능한 메모리 중 일부를 소비하기 때문에 중간 규모의 실행기를 사용하는 것이 좋습니다. |
| --executor-memory | Apache Hadoop YARN에서 각 실행기의 메모리 크기(힙 크기)를 제어하며, 실행 오버헤드를 위해 일부 메모리를 남겨 두어야 합니다. |
다음은 다른 구성 값을 갖는 두 개의 작업자 노드 예제입니다.

다음 목록에서는 핵심 Spark 실행기 메모리 매개 변수를 보여 줍니다.
| 매개 변수 | 설명 |
|---|---|
| spark.executor.memory | 실행기에 사용할 수 있는 총 메모리 크기를 정의합니다. |
| spark.storage.memoryFraction | (기본 ~60%)는 지속된 RDD를 저장하는 데 사용할 수 있는 메모리 양을 정의합니다. |
| spark.shuffle.memoryFraction | (기본 ~20%)는 무작위 재생용으로 예약된 메모리 양을 정의합니다. |
| spark.storage.unrollFraction 및 spark.storage.safetyFraction | (총 메모리의 ~30%) - 이러한 값은 Spark에서 내부적으로 사용되므로 변경하지 않아야 합니다. |
YARN은 각 Spark 노드의 컨테이너에서 사용되는 메모리의 최대 합계를 제어합니다. 다음 다이어그램은 YARN 구성 개체와 Spark 개체 사이의 노드별 관계를 보여 줍니다.
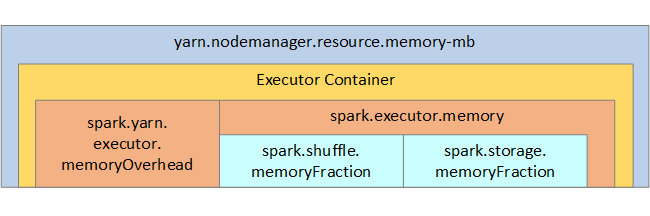
Jupyter Notebook에서 실행 중인 애플리케이션에 대한 매개 변수 변경
기본적으로 HDInsight의 Spark 클러스터에는 다양한 구성 요소가 포함되어 있습니다. 이러한 각 구성 요소에는 필요에 따라 재정의될 수 있는 기본 구성 값이 포함되어 있습니다.
| 구성 요소 | 설명 |
|---|---|
| Spark Core | Spark Core, Spark SQL, Spark Streaming API, GraphX, 및 Apache Spark MLlib. |
| Anaconda | Python 패키지 관리자. |
| Apache Livy | HDInsight Spark 클러스터에 원격 작업 제출하는 데 사용되는 Apache Spark REST API. |
| Jupyter Notebooks 및 Apache Zeppelin Notebooks | Spark 클러스터와의 상호 작용을 위한 브라우저 기반 대화형 UI. |
| ODBC 드라이버 | HDInsight의 Spark 클러스터를 Microsoft Power BI 및 Tableau와 같은 BI(비즈니스 인텔리전스) 도구에 연결합니다. |
Jupyter Notebook에서 실행되는 애플리케이션의 경우 %%configure 명령을 사용하여 노트 자체에서 구성을 변경합니다. 이러한 구성 변경 내용은 노트 인스턴스에서 실행되는 Spark 작업에 적용됩니다. 첫 번째 코드 셀을 실행하기 전에 애플리케이션의 시작 부분에 이를 변경합니다. 변경된 구성은 생성된 Livy 세션에 적용됩니다.
참고 항목
애플리케이션의 이후 단계에서 구성을 변경하려면 -f(force) 매개 변수를 사용합니다. 그러나 애플리케이션의 모든 진행 상태는 손실됩니다.
다음 코드는 Jupyter Notebook에서 실행 중인 애플리케이션에 대한 구성을 변경하는 방법을 보여 줍니다.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
결론
Spark 작업이 뛰어난 성능으로 예측 가능한 방식으로 실행되도록 하기 위해 핵심 구성 설정을 모니터링합니다. 이러한 설정은 특정 워크로드에 대해 최상의 Spark 클러스터 구성을 결정하도록 도와줍니다. 또한 장기 실행 및/또는 리소스 소모형 Spark 작업의 실행을 모니터링해야 합니다. 가장 일반적인 문제는 크기가 잘못된 실행기와 같이 잘못된 구성에서 발생하는 메모리 압력과 관련되어 있습니다. 또한 장기 실행 작업 및 작업으로 인해 카티전 작업이 발생하기도 합니다.