자습서: Azure Machine Learning 및 IoT Edge를 사용하는 엔드투엔드 솔루션
적용 대상: ![]() IoT Edge 1.1
IoT Edge 1.1
Important
IoT Edge 1.1 지원 종료일은 2022년 12월 13일이었습니다. 이 제품, 서비스, 기술 또는 API가 지원되는 방법에 대한 정보는 Microsoft 제품 수명 주기를 확인하세요. 최신 버전의 IoT Edge로 업데이트하는 방법에 대한 자세한 내용은 업데이트 IoT Edge를 참조하세요.
IoT 애플리케이션에 인텔리전트 클라우드와 인텔리전트 에지를 활용하고 싶은 경우가 자주 있습니다. 이 자습서에서는 클라우드의 IoT 디바이스에서 수집한 데이터로 기계 학습 모델을 학습시키고, 그 모델을 IoT Edge에 배포하고, 정기적으로 모델을 유지 관리 및 구체화하는 연습을 합니다.
참고 항목
이 자습서 세트의 개념은 모든 버전의 IoT Edge에 적용되지만 시나리오를 사용해보기 위해 만드는 샘플 디바이스는 IoT Edge 버전 1.1을 실행합니다.
이 자습서의 기본 목적은 기계 학습을 사용하여 IoT 데이터를 처리하는 방법, 특히 에지에서 처리하는 방법을 소개하는 것입니다. 이 자습서에서는 기계 학습을 심층적으로 다루지는 않고 여러 가지 일반적인 기계 학습 워크플로를 다룹니다. 여기서는 사용 사례에 대해 고도로 최적화된 모델을 만들려고 시도하지 않습니다. IoT 데이터 처리를 위해 실행 가능한 모델을 만들고 사용하는 프로세스를 설명하기에 충분합니다.
자습서의 이 섹션에서는 다음에 대해 설명합니다.
- 자습서의 후속 부분을 완료하기 위한 필수 구성 요소입니다.
- 자습서의 대상 사용자입니다.
- 자습서에서 시뮬레이션하는 사용 사례입니다.
- 자습서에서 사용 사례를 충족하기 위해 수행하는 전반적인 프로세스입니다.
Azure를 구독하고 있지 않다면 시작하기 전에 Azure 체험 계정을 만듭니다.
필수 조건
이 자습서를 완료하려면 리소스를 만들 권한이 있는 Azure 구독에 액세스해야 합니다. 이 자습서에서 사용되는 여러 서비스는 Azure 요금이 발생합니다. 아직 Azure 구독이 없는 경우 Azure 체험 계정으로 시작할 수 있습니다.
또한 스크립트를 실행하여 개발 머신으로 사용할 Azure Virtual Machine을 설정할 수 있도록 PowerShell이 설치된 머신이 필요합니다.
이 문서에서는 다음과 같은 도구를 사용합니다.
데이터 캡처용 Azure IoT Hub
데이터 준비 및 기계 학습 실험에 기본 프런트 엔드로 사용할 Azure Notebooks. 샘플 데이터 하위 집합을 사용하는 Notebook에서 Python 코드를 실행하는 것은 데이터를 준비하는 동안 반복되는 대화형 소요 시간을 줄이는 매우 좋은 방법입니다. Jupyter Notebook을 사용하여 컴퓨팅 백 엔드에서 대규모로 실행할 스크립트를 준비할 수도 있습니다.
대규모 기계 학습 및 기계 학습 이미지 생성 시 백 엔드로 사용할 Azure Machine Learning. Jupyter Notebook에서 준비하고 테스트한 스크립트를 사용하여 Azure Machine Learning 백 엔드를 실행할 것입니다.
기계 학습 이미지의 비 클라우드 애플리케이션에 사용할 Azure IoT Edge
물론 다른 옵션도 사용할 수 있습니다. 특정 시나리오, 예를 들어 IoT Central을 코드 없는 대안으로 사용하여 IoT 디바이스에서 초기 학습 데이터를 캡처할 수 있습니다.
대상 그룹 및 역할 지정
이 문서 세트는 IoT 개발 또는 기계 학습 경험이 없는 개발자를 위해 작성되었습니다. 에지에 기계 학습을 배포하려면 다양한 기술을 연결하는 방법을 알아야 합니다. 따라서 이 자습서에서는 여러 기술을 연결하여 IoT 솔루션을 구현하는 한 가지 방법을 보여주는 완전한 엔드투엔드 시나리오를 다룹니다. 실제 환경에서는 전공이 다른 여러 사람들에게 이러한 작업을 분배하기도 합니다. 예를 들어 개발자는 디바이스 또는 클라우드 코드에 집중하고, 데이터 과학자는 분석 모델을 설계합니다. 개별 개발자가 이 자습서를 성공적으로 완료할 수 있도록, 어떤 일을 무슨 이유로 수행하는지 자세히 설명하는 인사이트와 링크가 포함된 보충 지침을 제공해 드렸습니다.
다른 역할이 할당된 동료들과 팀을 구성하여 함께 자습서를 진행하고, 여러분이 갖고 있는 전문 지식을 총동원하고, 각 요소가 어떻게 서로 맞물려 작동하는지 팀 단위로 알아볼 수도 있습니다.
어떤 경우에도 독자들을 올바른 방향으로 안내할 수 있도록 이 자습서의 각 문서에서는 사용자의 역할을 알려줍니다. 다음과 같은 역할이 있습니다.
- 클라우드 개발(DevOps 분야에서 일하는 클라우드 개발자 포함)
- 데이터 분석
사용 사례: 예측 유지 관리
이 시나리오는 2008년 Conference on Prognostics and Health Management(PHM08)에서 발표된 사용 사례를 기반으로 합니다. 목표는 터보팬 항공기 엔진 세트의 RUL(잔여 수명)을 예측하는 것입니다. 이 데이터는 MAPSS(Modular Aero-Propulsion System Simulation) 소프트웨어의 상업용 버전인 C-MAPSS를 사용하여 생성되었습니다. 이 소프트웨어는 상태, 제어 및 엔진 매개 변수를 간편하게 시뮬레이션할 수 있는 유연한 터보팬 엔진 시뮬레이션 환경을 제공합니다.
이 자습서에 사용되는 데이터는 터보팬 엔진 성능 저하 시뮬레이션 데이터 세트에서 가져온 것입니다.
추가 정보 파일에 포함된 내용:
실험 시나리오
데이터 세트는 여러 다변량 시계열로 구성됩니다. 각 데이터 세트는 학습 및 테스트 하위 집합으로 나뉩니다. 각 시계열은 다른 엔진에서 온 것입니다. 즉, 데이터는 동일한 유형의 엔진에서 온 것으로 간주될 수 있습니다. 각 엔진은 사용자가 알 수 없는 다양한 정도의 초기 마모 및 제조 편차로 시작됩니다. 이 마모 및 변형은 정상으로 간주됩니다. 즉, 오류 조건으로 간주되지 않습니다. 엔진 성능에 상당한 영향을 주는 세 가지 작동 설정이 있습니다. 이러한 설정은 데이터에도 포함되어 있습니다. 데이터가 센서 노이즈로 오염되었습니다.
각 시계열이 시작할 때는 엔진이 정상적으로 작동하다가 시계열 중간의 특정 시점에 오류가 발생합니다. 학습 세트에서, 시스템이 고장 날 때까지 오류가 점점 많이 발생합니다. 테스트 세트에서는 시스템이 고장 나기 전 특정 시점에 시계열이 종료됩니다. 경쟁의 목적은 테스트 세트에서 오류가 발생하기 전까지 정상 작동하는 주기의 수, 즉, 엔진이 계속 작동하게 될 마지막 주기 후의 정상 작동하는 주기 수를 예측하는 것입니다. 테스트 데이터에 대한 실제 RUL(잔여 수명) 값의 벡터도 제공해 드렸습니다.
경쟁을 위해 데이터를 게시했기 때문에, 기계 학습 모델을 파생하는 여러 가지 방법이 독립적으로 게시되었습니다. 예제를 연구하면 특정 기계 학습 모델 만들기와 관련된 프로세스와 추론을 이해하는 데 도움이 됩니다. 예를 들어 다음 방법을 살펴보세요.
GitHub 사용자 jancervenka의 항공기 엔진 고장 예측 모델
GitHub 사용자 hankroark의 터보팬 엔진 성능 저하
Process
아래 그림은 이 자습서에서 수행할 단계를 간략하게 보여줍니다.
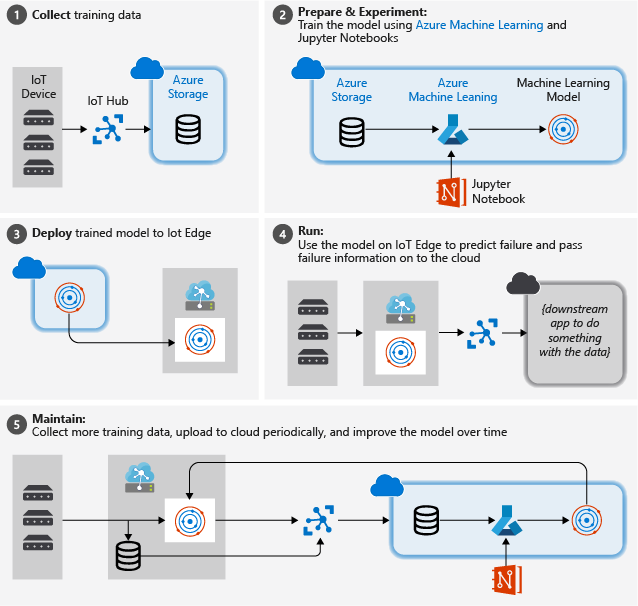
학습 데이터 수집: 프로세스는 학습 데이터를 수집하는 것부터 시작합니다. 데이터가 이미 수집되어 있고 데이터베이스에서 또는 데이터 파일의 형태로 사용할 수 있는 경우도 있고, IoT 시나리오처럼 IoT 디바이스 및 센서에서 데이터를 수집하고 클라우드에 저장해야 하는 경우도 있습니다.
여기서는 터보팬 엔진이 없다고 가정하므로, 프로젝트 파일에는 NASA 디바이스 데이터를 클라우드로 전송하는 간단한 디바이스 시뮬레이터가 포함되어 있습니다.
‘데이터 준비’ 대부분의 경우 디바이스 및 센서에서 수집된 원시 데이터를 기계 학습에 사용할 수 있도록 준비해야 합니다. 이 단계에는 데이터 정리, 데이터 서식 다시 지정 또는 기계 학습에서 사용할 수 있는 추가 정보를 삽입하는 전처리 과정에 포함될 수 있습니다.
항공기 엔진 기계 데이터의 경우 데이터의 실제 관찰 결과를 기반으로 샘플의 모든 데이터 포인트에 대한 명시적 고장 시간을 계산하는 과정이 데이터 준비에 포함됩니다. 이 정보를 통해 기계 학습 알고리즘이 실제 센서 데이터 패턴과 엔진의 예상 잔여 수명 간의 상관 관계를 찾을 수 있습니다. 이 단계는 도메인과 깊은 관계가 있습니다.
기계 학습 모델 빌드. 준비된 데이터에 따라, 이제 다양한 기계 학습 알고리즘과 매개 변수화를 실험하여 모델을 학습시키고 결과를 서로 비교할 수 있습니다.
여기서는 테스트를 위해 모델이 컴퓨팅한 결과를 엔진 세트에서 관측된 실제 결과와 비교합니다. Azure Machine Learning에서는 모델 레지스트리에 만드는 여러 모델 반복을 관리할 수 있습니다.
‘모델 배포’ 성공 조건을 충족하는 모델이 완성되면 배포를 진행할 수 있습니다. 여기에는 모델을 REST 호출을 사용하여 데이터를 제공하고 분석 결과를 반환할 수 있는 웹 서비스 앱으로 래핑하는 과정이 포함됩니다. 그 후 웹 서비스 앱을 docker 컨테이너에 패키징하여 클라우드에 또는 IoT Edge 모듈로 배포할 수 있습니다. 이 예제에서는 IoT Edge에 배포하는 방법에 집중하겠습니다.
모델 유지 관리 및 구체화. 모델을 배포한 후에도 할 일이 남아 있습니다. 대부분의 경우 앞으로도 계속 데이터를 수집하여 주기적으로 클라우드에 업로드합니다. 이 데이터를 사용하여 모델을 다시 학습시키고 구체화한 다음, IoT Edge에 다시 배포할 수 있습니다.
리소스 정리
이 자습서는 각 문서가 이전 작업에서 수행된 작업을 기반으로 하는 집합의 일부입니다. 최종 자습서를 완료할 때까지 기다렸다가 리소스를 정리하세요.
다음 단계
이 자습서는 다음과 같은 섹션으로 나뉩니다.
- 개발 머신 및 Azure 서비스를 설정합니다.
- 기계 학습 모듈에 사용할 학습 데이터를 생성합니다.
- 기계 학습 모델을 학습시키고 배포합니다.
- 투명 게이트웨이로 작동할 IoT Edge 디바이스를 구성합니다.
- IoT Edge 모듈을 만들어서 배포합니다.
- IoT Edge 디바이스에 데이터를 보냅니다.
다음 문서를 계속 진행하여 개발 머신을 설정하고 Azure 리소스를 프로비저닝하세요.