이 문서에서는 Azure Machine Learning 디자이너의 구성 요소에 대해 설명합니다.
이 구성 요소를 사용하여 분류 또는 회귀 모델을 학습할 수 있습니다. 학습은 모델을 정의하고 해당 매개 변수를 설정한 후에 수행되며 태그가 지정된 데이터가 필요합니다. 모델 학습을 사용하여 새 데이터로 기존 모델을 다시 학습할 수도 있습니다.
학습 프로세스 작동 방식
Azure Machine Learning에서 기계 학습 모델을 만들고 사용하는 것은 일반적으로 3단계 프로세스입니다.
특정 유형의 알고리즘을 선택하고 해당 매개 변수 또는 하이퍼 매개 변수를 정의하여 모델을 구성합니다. 다음 모델 유형 중 하나를 선택합니다.
- 신경망, 의사 결정 트리 및 의사 결정 포리스트 및 기타 알고리즘을 기반으로 하는 분류 모델입니다.
- 표준 선형 회귀를 포함할 수 있거나, 신경망 및 베이지언 회귀를 비롯한 다른 알고리즘을 사용하는 회귀 모델.
레이블이 지정되고 알고리즘과 호환되는 데이터가 있는 데이터 세트를 제공합니다. 데이터와 모델을 모두 학습 모델에 연결합니다.
학습에서 생성하는 것은 데이터에서 학습된 통계 패턴을 캡슐화하는 특정 이진 형식인 iLearner입니다. 이 형식을 직접 수정하거나 읽을 수 없습니다. 그러나 다른 구성 요소에서 이 학습된 모델을 사용할 수 있습니다.
모델의 속성을 볼 수도 있습니다. 자세한 내용은 결과 섹션을 참조하세요.
학습을 완료한 후 채점 구성 요소 중 하나와 학습된 모델을 사용하여 새 데이터에 대한 예측을 만듭니다.
모델 학습을 사용하는 방법
파이프라인에 모델 학습 구성 요소를 추가합니다. 이 구성 요소는 Machine Learning 범주 아래에서 찾을 수 있습니다. 학습을 확장하고 모델 학습 구성 요소를 파이프라인으로 끌어서 놓습니다.
왼쪽 입력에서 학습되지 않은 모드를 연결합니다. 학습 데이터 세트를 학습 모델의 오른쪽 입력에 연결합니다.
학습 데이터 세트에는 레이블 열이 포함되어야 합니다. 레이블이 없는 행은 무시됩니다.
레이블 열의 경우, 구성 요소의 오른쪽 패널에서 열 편집을 클릭하고 모델이 학습에 사용할 수 있는 결과가 포함된 단일 열을 선택합니다.
분류 문제의 경우 레이블 열에 범주 값 또는 불연속 값이 포함되어야 합니다. 일부 예는 예/아니요 등급, 질병 분류 코드 또는 이름 또는 소득 그룹일 수 있습니다. 비범주형 열을 선택하면 학습 중에 구성 요소에서 오류를 반환합니다.
회귀 문제의 경우 레이블 열에 응답 변수를 나타내는 숫자 데이터가 포함되어야 합니다. 이상적으로 숫자 데이터는 연속 배율을 나타냅니다.
예를 들어 신용 위험 점수, 하드 드라이브의 예상 고장 시간 또는 지정된 요일이나 시간에 콜 센터에서 받을 예상 통화 수 등입니다. 숫자 열을 선택하지 않으면 오류가 발생할 수 있습니다.
- 사용할 레이블 열을 지정하지 않으면 Azure Machine Learning은 데이터 세트의 메타데이터를 사용하여 적절한 레이블 열이 무엇인지 유추하려고 합니다. 잘못된 열을 선택하는 경우 열 선택기를 사용하여 수정합니다.
팁
열 선택기를 사용하는 데 문제가 있는 경우 팁은 데이터 세트에서 열 선택 문서를 참조하세요. WITH RULES 및 BY NAME 옵션을 사용하기 위한 몇 가지 일반적인 시나리오와 팁을 설명합니다.
파이프라인을 제출합니다. 많은 데이터가 있는 경우 시간이 걸릴 수 있습니다.
중요합니다
각 행의 ID인 ID 열 또는 고유 값 이 너무 많은 텍스트 열이 있는 경우 모델 학습은 "열의 고유 값 수: "{column_name}"이 허용보다 큽니다.
열이 고유 값의 임계값에 도달하여 메모리 부족이 발생할 수 있기 때문입니다. 메타데이터 편집을 사용하여 해당 열을 명확한 기능으로 표시하면 학습에 사용되지 않습니다. 또는 텍스트 열을 전처리하기 위해 텍스트 구성 요소에서 N-Gram 기능을 추출하여 텍스트 열을 전처리합니다. 자세한 오류 정보는 디자이너 오류 코드를 참조하세요.
모델 해석력
모델 해석성은 ML 모델을 이해하고 인간이 이해할 수 있는 방식으로 의사 결정을 위한 기본 기반을 제시할 수 있는 가능성을 제공합니다.
현재 모델 학습 구성 요소는 해석력 패키지를 사용하여 ML 모델을 설명하도록 지원합니다. 지원되는 기본 제공 알고리즘은 다음과 같습니다.
- 선형 회귀
- 신경망 회귀
- 향상된 의사 결정 트리 회귀
- 의사 결정 포리스트 회귀
- 포아송 회귀
- 2클래스 로지스틱 회귀
- 2클래스 지원 벡터 컴퓨터
- 이중 클래스 부스팅된 의사 결정 트리
- 2클래스 의사 결정 포리스트
- 다중 클래스 의사 결정 포리스트
- 다중 클래스 로지스틱 회귀
- 다중 클래스 신경망
모델 설명을 생성하려면 모델 학습 구성 요소의 모델 설명 드롭다운 목록에서 True를 선택합니다. 모델 학습 구성 요소에서는 기본적으로 False로 설정되어 있습니다. 설명을 생성하려면 추가 컴퓨팅 비용이 필요합니다.
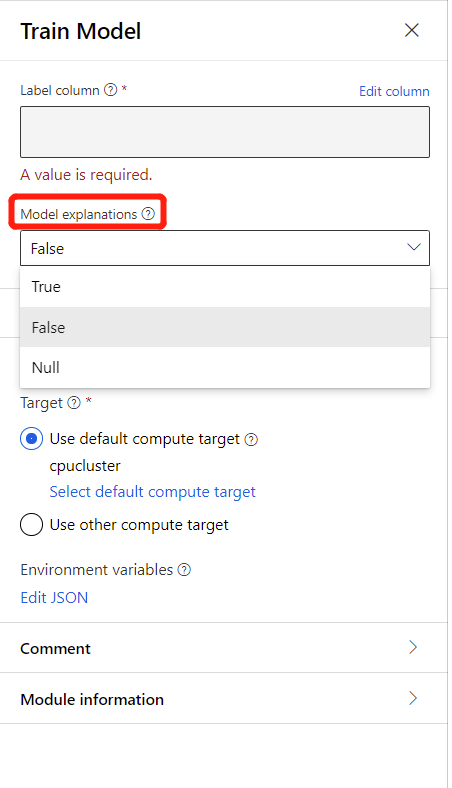
파이프라인 실행이 완료되면 모델 학습 구성 요소의 오른쪽 창에 있는 설명 탭으로 이동하여 모델 성능, 데이터 세트 및 기능 중요도를 살펴볼 수 있습니다.
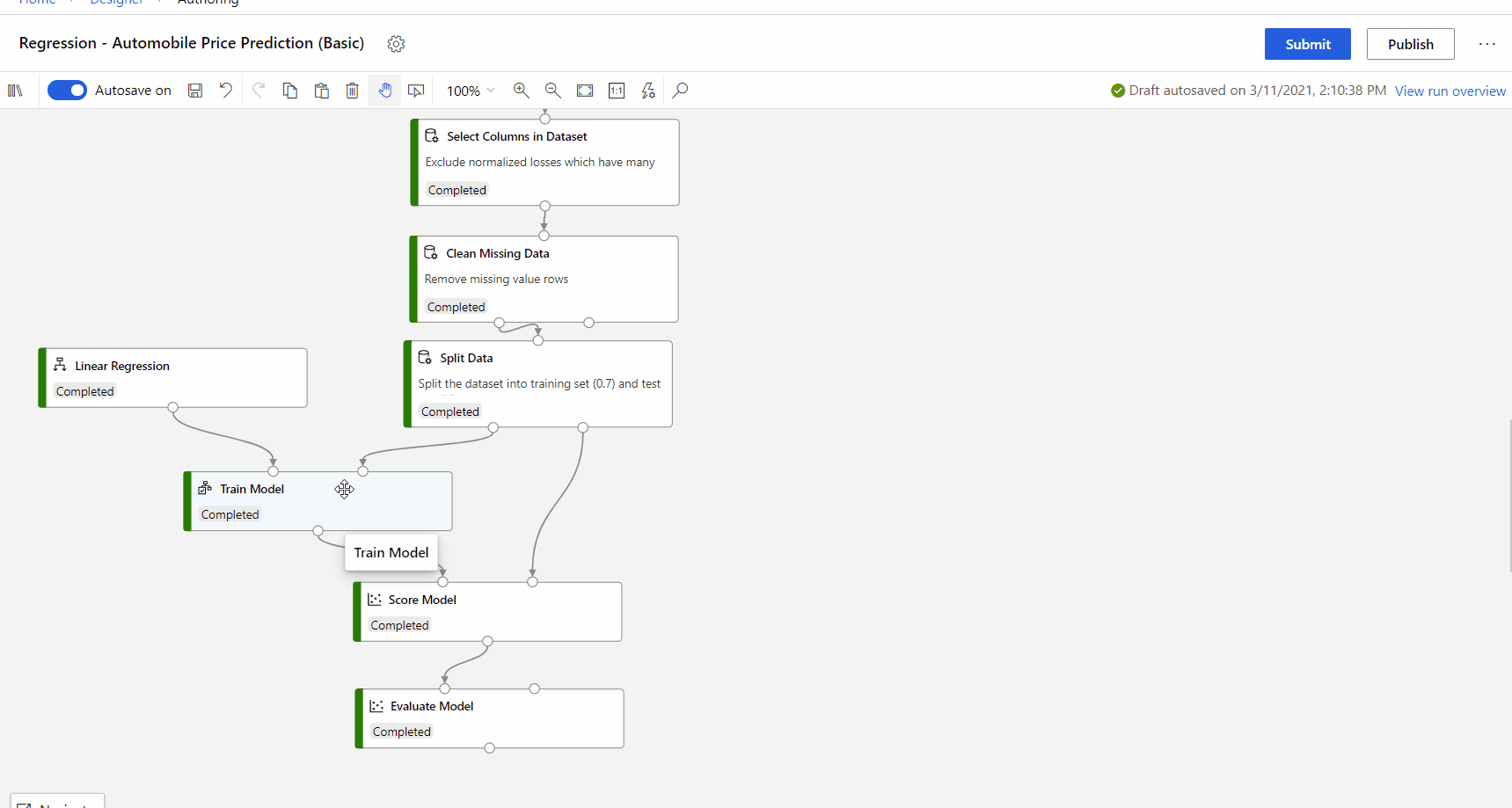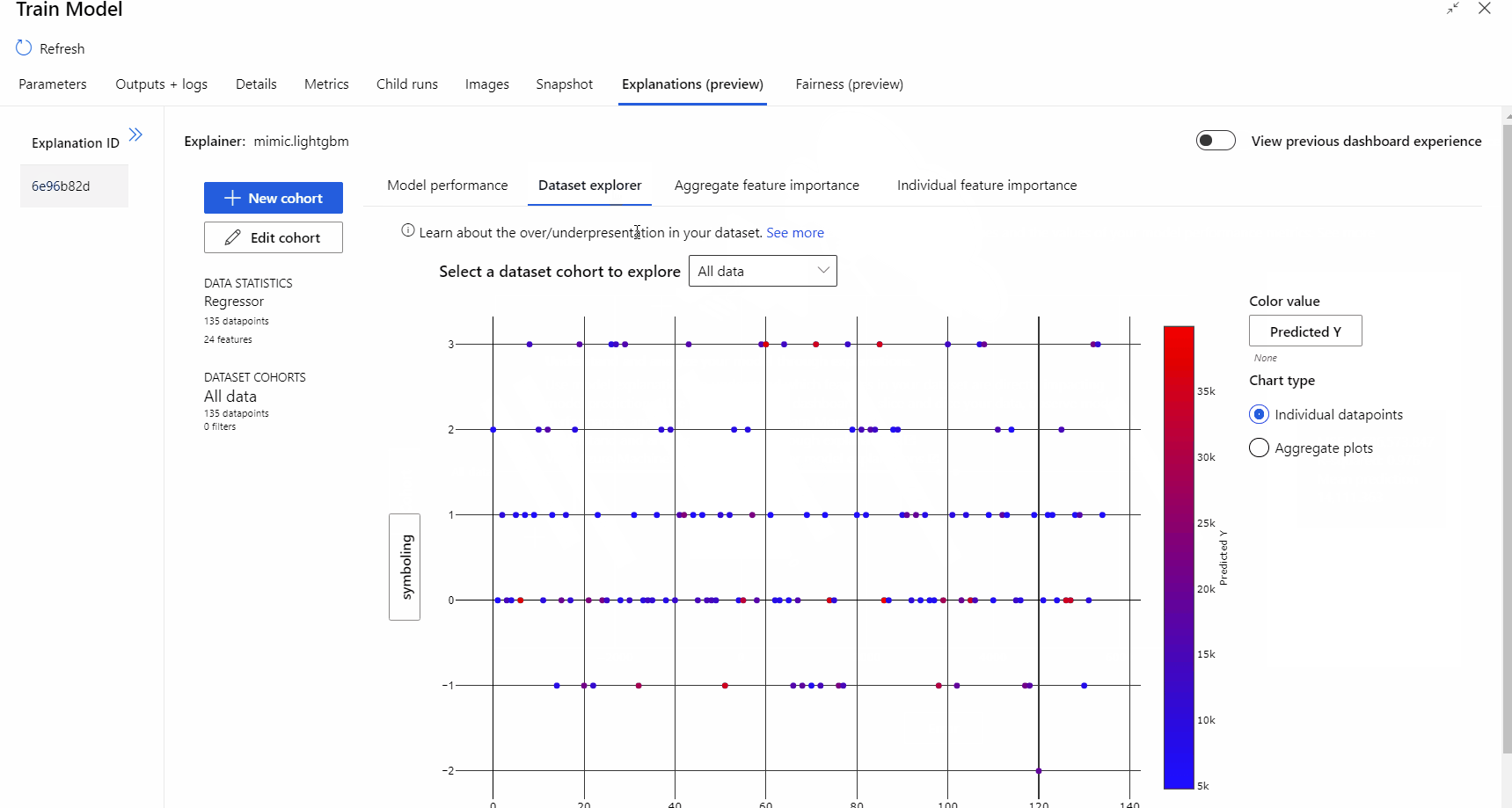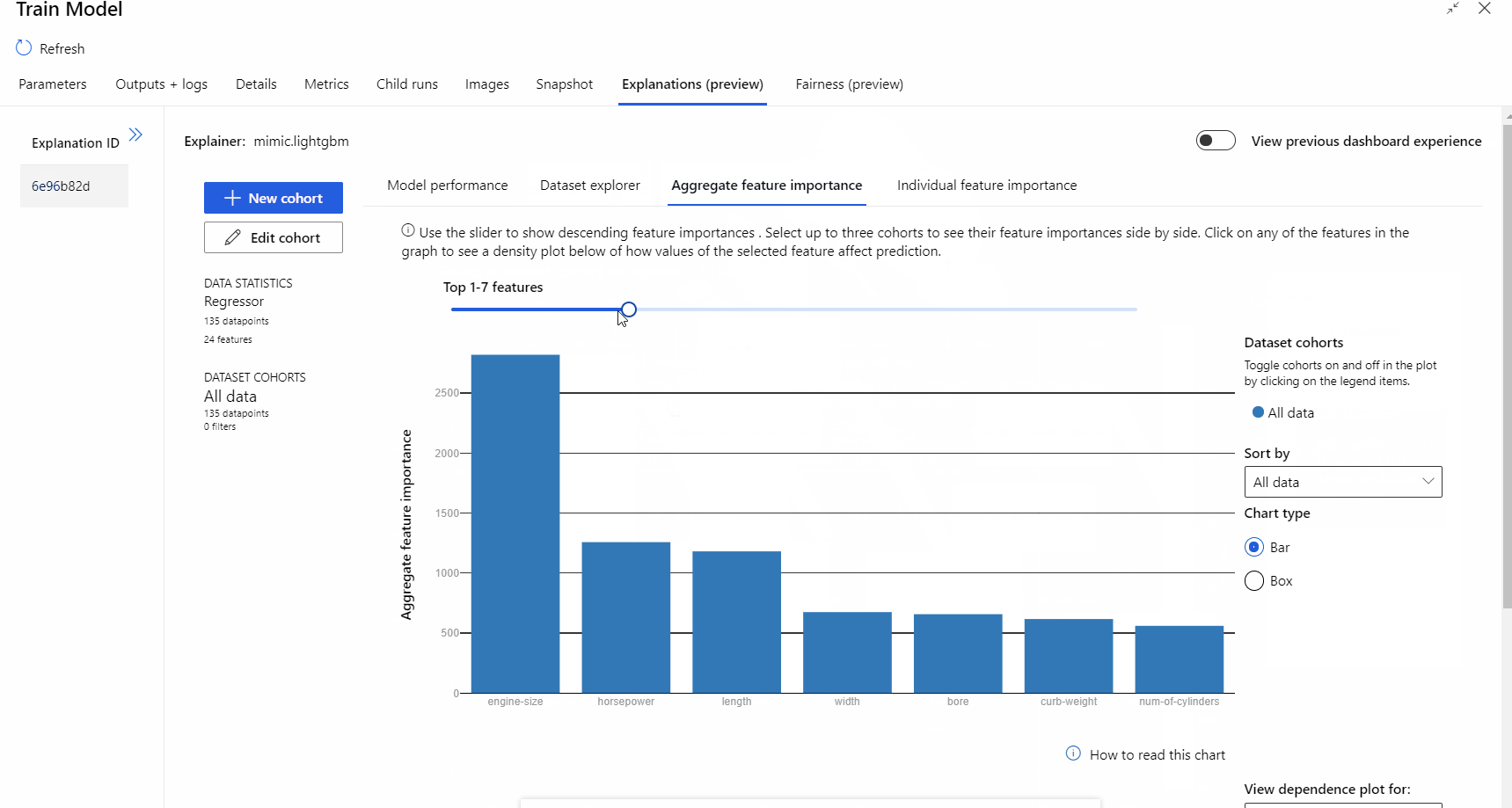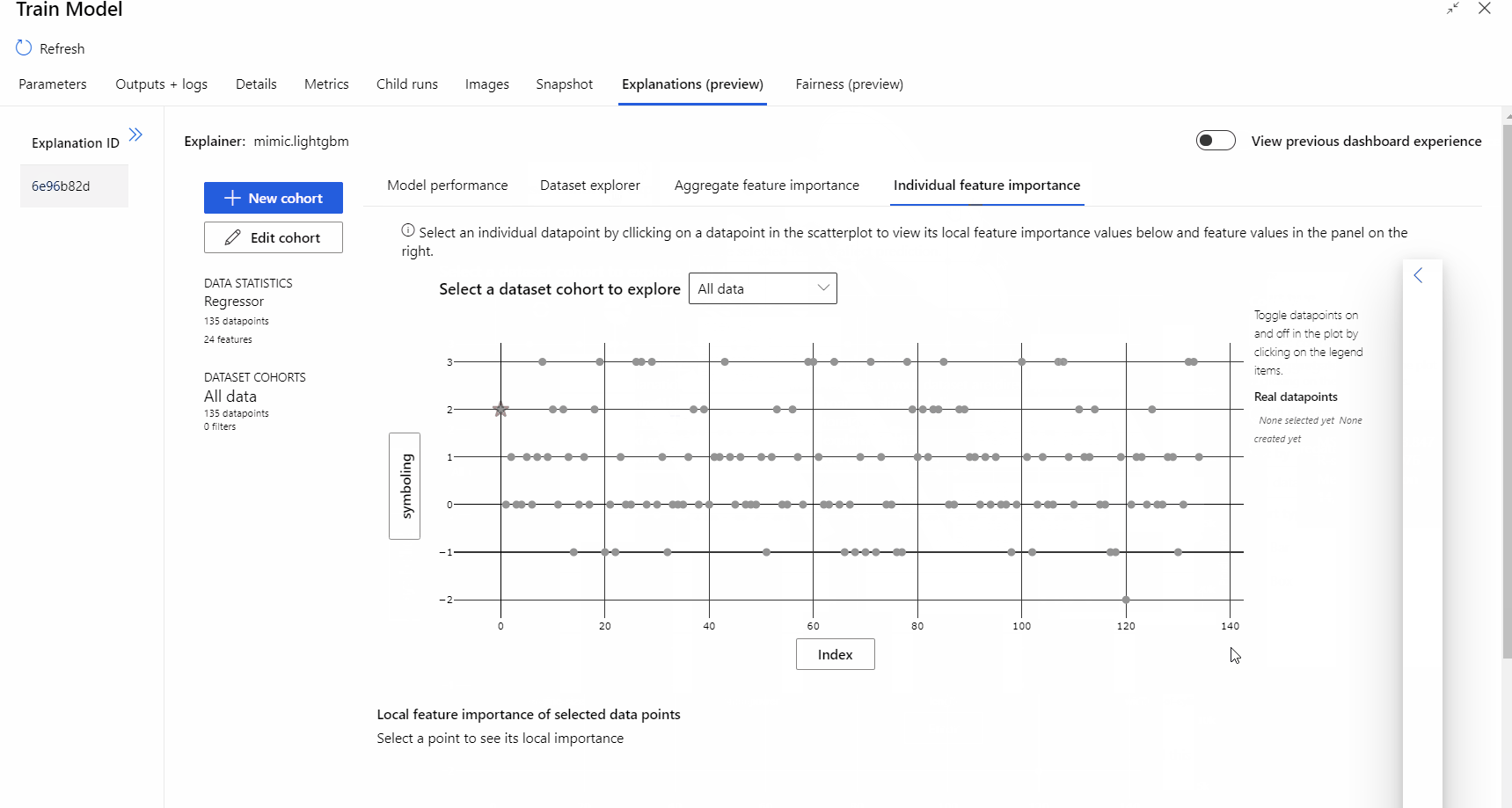
Azure Machine Learning에서 모델 설명을 사용하는 방법에 대한 자세한 내용은 ML 모델 해석에 대한 방법 문서를 참조하세요.
결과
모델을 학습한 후:
다른 파이프라인에서 모델을 사용하려면 구성 요소를 선택하고 오른쪽 패널의 출력 탭 아래에서 데이터 세트 등록 아이콘을 선택합니다. 데이터 세트의 구성 요소 팔레트에 저장된 모델에 액세스할 수 있습니다.
새 값을 예측하는 데 모델을 사용하려면 모델 채점 구성 요소에 새 입력 데이터와 함께 모델을 연결합니다.
다음 단계
Azure Machine Learning에서 사용 가능한 구성 요소 집합을 참조하세요.