이 문서에서는 Azure Machine Learning 디자이너의 구성 요소에 대해 설명합니다.
이 구성 요소를 사용하여 정규화를 통해 데이터 세트를 변환합니다.
정규화는 기계 학습을 위한 데이터 준비의 일부로 적용되는 기술입니다. 정규화의 목표는 값 범위 차이의 왜곡이나 정보 손실 없이 공통 스케일을 사용하도록 데이터 세트의 숫자 열 값을 변경하는 것입니다. 데이터를 올바르게 모델링하려면 일부 알고리즘에도 정규화가 필요합니다.
예를 들어 입력 데이터 세트에 값이 0에서 1 사이인 열과 값이 10,000에서 100,000 사이인 다른 열이 있다고 가정합니다. 숫자의 크기가 크게 달라지면 모델링하는 동안 값을 기능으로 결합하려고 할 때 문제가 발생할 수 있습니다.
정규화 는 모델에서 사용되는 모든 숫자 열에 적용된 배율 내에 값을 유지하면서 원본 데이터의 일반 분포 및 비율을 유지하는 새 값을 만들어 이러한 문제를 방지합니다.
이 구성 요소는 숫자 데이터를 변환하기 위한 몇 가지 옵션을 제공합니다.
- 모든 값을 0~1 스케일로 변경하거나 절대값 대신 백분위수 순위로 표시하여 값을 변환할 수 있습니다.
- 단일 열 또는 동일한 데이터 세트의 여러 열에 정규화를 적용할 수 있습니다.
- 파이프라인을 반복하거나 동일한 정규화 단계를 다른 데이터에 적용해야 하는 경우 단계를 정규화 변환으로 저장하고 스키마가 동일한 다른 데이터 세트에 적용할 수 있습니다.
경고
일부 알고리즘에서는 모델을 학습하기 전에 데이터를 정규화해야 합니다. 다른 알고리즘은 자체 데이터 크기 조정 또는 정규화를 수행합니다. 따라서 예측 모델을 빌드하는 데 사용할 기계 학습 알고리즘을 선택하는 경우 학습 데이터에 정규화를 적용하기 전에 알고리즘의 데이터 요구 사항을 검토해야 합니다.
데이터 정규화 구성
이 구성 요소를 사용하여 한 번에 하나의 정규화 방법만 적용할 수 있습니다. 따라서 선택한 모든 열에 동일한 정규화 메서드가 적용됩니다. 다른 정규화 방법을 사용하려면 두 번째 데이터 정규화 인스턴스를 사용합니다.
파이프라인에 데이터 정규화 구성 요소를 추가합니다. 이 구성 요소는 Azure Machine Learning의 데이터 변환 아래에 있는 스케일링 및 축소 범주에서 찾을 수 있습니다.
모두 숫자로 이루어진 열이 하나 이상 포함된 데이터 세트를 연결합니다.
열 선택기를 사용하여 정규화할 숫자 열을 선택합니다. 개별 열을 선택하지 않으면 기본적으로 입력의 모든 숫자 형식 열이 포함되고 선택한 모든 열에 동일한 정규화 프로세스가 적용됩니다.
정규화하면 안 되는 숫자 열을 포함하는 경우 이상한 결과가 발생할 수 있습니다. 항상 열을 신중하게 확인합니다.
숫자 열이 검색되지 않으면 열 메타데이터를 확인하여 열의 데이터 형식이 지원되는 숫자 형식인지 확인합니다.
팁
특정 형식의 열이 입력으로 제공되도록 하려면 데이터를 정규화하기 전에 데이터 세트에서 열 선택 구성 요소를 사용합니다.
선택 시 상수 열에 0 사용: 임의의 숫자 열에 변경되지 않는 단일 값이 포함된 경우 이 옵션을 선택합니다. 이렇게 하면 이러한 열이 정규화 작업에 사용되지 않습니다.
변환 메서드 드롭다운 목록에서 선택한 모든 열에 적용할 단일 수학 함수를 선택합니다.
Zscore: 모든 값을 z 점수로 변환합니다.
열의 값은 다음 수식을 사용하여 변환됩니다.
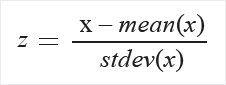
평균 및 표준 편차는 각 열에 대해 개별적으로 계산됩니다. 모집단 표준 편차가 사용됩니다.
MinMax: min-max normalizer는 모든 기능을 [0,1] 간격으로 선형으로 다시 크기 조정합니다.
[0,1] 간격으로 다시 크기 조정은 최소값이 0이 되도록 각 기능의 값을 이동한 다음 새 최대값(원래 최대값과 최소값 간의 차이)으로 나누어 수행됩니다.
열의 값은 다음 수식을 사용하여 변환됩니다.

로지스틱: 열의 값은 다음 수식을 사용하여 변환됩니다.

LogNormal: 이 옵션은 모든 값을 로그 크기 조정으로 변환합니다.
열의 값은 다음 수식을 사용하여 변환됩니다.

여기에서 μ 및 σ 각 열에 대해 데이터에서 경험적으로 계산되는 분포의 매개 변수입니다.
TanH: 모든 값은 쌍곡 탄젠트로 변환됩니다.
열의 값은 다음 수식을 사용하여 변환됩니다.

파이프라인을 제출하거나 데이터 정규화 구성 요소를 두 번 클릭하고 선택한 항목 실행을 선택합니다.
결과
데이터 정규화 구성 요소는 다음 두 개의 출력을 생성합니다.
변환된 값을 보려면 구성 요소를 마우스 오른쪽 단추로 클릭하고 시각화를 선택합니다.
기본적으로 값은 현재 위치에서 변환됩니다. 변환된 값을 원래 값과 비교하려는 경우 열 추가 구성 요소를 사용하여 데이터 세트를 다시 결합하고 열을 나란히 표시합니다.
동일한 정규화 방법을 다른 데이터 세트에 적용할 수 있도록 변환을 저장하려면 구성 요소를 선택한 다음, 오른쪽 패널의 출력 탭에서 데이터 세트 등록을 선택합니다.
그런 다음, 왼쪽 창의 변환 그룹에서 저장된 변환 을 로드하고 변환 적용을 사용하여 동일한 스키마가 있는 데이터 세트에 적용할 수 있습니다.
다음 단계
Azure Machine Learning에서 사용 가능한 구성 요소 집합을 참조하세요.