텍스트 전처리
이 문서에서는 Azure Machine Learning 디자이너의 구성 요소에 대해 설명합니다.
텍스트 전처리 구성 요소를 사용하여 텍스트를 정리하고 단순화할 수 있습니다. 다음과 같은 일반 텍스트 처리 작업을 지원합니다.
- 중지 단어 제거
- 정규식을 사용하여 특정 대상 문자열 검색 및 바꾸기
- 여러 관련 단어를 단일 정규형으로 변환하는 표제어 추출
- 대/소문자 정규화
- 숫자, 특수 문자, 반복되는 문자 시퀀스(예: "aaaa") 등의 특정 클래스 문자 제거
- 이메일과 URL 식별 및 제거
전처리 텍스트 구성 요소는 현재 영어만 지원합니다.
텍스트 전처리 구성
Azure Machine Learning에서 파이프라인에 전처리 텍스트 구성 요소를 추가합니다. 이 구성 요소는 Text Analytics에서 찾을 수 있습니다.
텍스트를 포함하는 열이 하나 이상 있는 데이터 세트를 연결합니다.
언어 드롭다운 목록에서 언어를 선택합니다.
정리할 텍스트 열: 전처리하려는 열을 선택합니다.
중지 단어 제거: 미리 정의된 중지 단어 목록을 텍스트 열에 적용하려면 이 옵션을 선택합니다.
중지 단어 목록은 언어에 따라 다르며 사용자 지정할 수 있습니다.
표제어 추출: 단어를 정규형으로 표시하려면 이 옵션을 선택합니다. 이 옵션은 다른 경우와 유사한 텍스트 토큰의 고유 발생 수를 줄이는 데 유용합니다.
표제어 추출 프로세스는 언어에 따라 달라집니다.
문장 검색: 분석을 수행할 때 구성 요소가 문장 경계 표시를 삽입하도록 하려면 이 옵션을 선택합니다.
이 구성 요소에서는 일련의 세 개 파이프 문자
|||를 사용하여 문장 마침을 표시합니다.정규식을 사용하여 선택적 찾기 및 바꾸기 작업을 수행합니다. 정규식은 다른 모든 기본 제공 옵션보다 먼저 처리됩니다.
- 사용자 지정 정규식: 검색하는 텍스트를 정의합니다.
- 사용자 지정 대체 문자열: 단일 대체 값을 정의합니다.
대/소문자를 소문자로 정규화: ASCII 대문자를 소문자 형식으로 변환하려면 이 옵션을 선택합니다.
문자가 정규화되지 않은 경우 대문자와 소문자로 된 동일한 단어는 두 단어로 간주됩니다.
처리된 출력 텍스트에서 다음과 같은 유형의 문자 또는 문자 시퀀스를 제거할 수도 있습니다.
숫자 제거: 지정된 언어의 모든 숫자 문자를 제거하려면 이 옵션을 선택합니다. ID 번호는 도메인 종속 및 언어에 따라 달라집니다. 숫자 문자가 알려진 단어의 정수 부분이면 숫자가 제거되지 않을 수 있습니다. 기술 참고 사항을 자세히 알아보세요.
특수 문자 제거: 영숫자가 아닌 특수 문자를 모두 제거하려면 이 옵션을 사용합니다.
중복 문자 제거: 두 번 이상 반복되는 시퀀스에서 추가 문자를 제거하려면 이 옵션을 선택합니다. 예를 들어 "aaaaa"와 같은 시퀀스는 "aa"로 줄어듭니다.
이메일 주소 제거:
<string>@<string>형식의 시퀀스를 제거하려면 이 옵션을 선택합니다.URL 제거:
http,https,ftp,wwwURL 접두사가 포함된 시퀀스를 제거하려면 이 옵션을 선택합니다.
축약 동사 확장:이 옵션은 축약 동사를 사용하는 언어에만 적용됩니다. 현재는 영어만 지원됩니다.
예를 들어 이 옵션을 선택하면 "wouldn't stay there" 를 "would not stay there" 로 바꿀 수 있습니다.
백슬래시로 슬래시 정규화:
\\의 모든 인스턴스를/에 매핑하려면 이 옵션을 선택합니다.특수 문자의 토큰 분할:
&,-등과 같은 문자에서 단어를 분할하려면 이 옵션을 선택합니다. 이 옵션은 특수 문자가 두 번 이상 반복될 때 특수 문자를 줄일 수도 있습니다.예를 들어
MS---WORD문자열은MS,-,WORD의 세 가지 토큰으로 분할됩니다.파이프라인을 제출합니다.
기술 정보
스튜디오(클래식) 및 디자이너의 전처리 텍스트 구성 요소는 다양한 언어 모델을 사용합니다. 이 디자이너는 spaCy에서 다중 작업 CNN 학습 모델을 사용합니다. 모델마다 다른 토크나이저 및 품사 태거를 제공하므로 서로 다른 결과를 초래합니다.
다음은 몇 가지 예제입니다.
| 구성 | 출력 결과 |
|---|---|
| 모든 옵션이 선택됨 설명: ‘WC-3 3test 4test’의 ‘3test’와 같은 경우 디자이너는 ‘3test’라는 전체 단어를 제거합니다. 이런 맥락에서 품사 태거는 이 토큰 ‘3test’를 숫자로 지정하므로 품사에 따라 구성 요소는 모듈은 이를 제거합니다. |
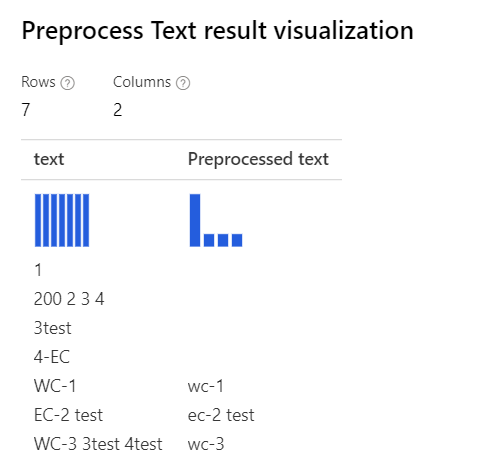
|
Removing number만 선택됨 설명: ‘3test’, ‘4-EC’ 등의 경우, 디자이너 토크나이저는 이를 분할하지 않고 전체 토큰으로 처리합니다. 따라서 이러한 단어에 있는 숫자는 제거되지 않습니다. |

|
정규식을 사용하여 사용자 지정된 결과를 출력할 수도 있습니다.
| 구성 | 출력 결과 |
|---|---|
| 모든 옵션이 선택됨 사용자 지정 정규식: (\s+)*(-|\d+)(\s+)*사용자 지정 대체 문자열: \1 \2 \3 |

|
Removing number만 선택됨 사용자 지정 정규식: (\s+)*(-|\d+)(\s+)*사용자 지정 대체 문자열: \1 \2 \3 |
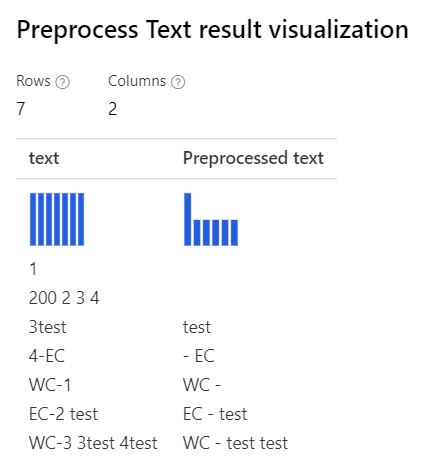
|
다음 단계
Azure Machine Learning에서 사용 가능한 구성 요소 집합을 참조하세요.