일괄 처리 엔드포인트에 대한 권한 부여
일괄 처리 엔드포인트는 Microsoft Entra 인증 또는 aad_token을 지원합니다. 즉, 일괄 처리 엔드포인트를 호출하려면 사용자가 유효한 Microsoft Entra 인증 토큰을 일괄 처리 엔드포인트 URI에 제공해야 합니다. 권한 부여는 엔드포인트 수준에서 적용됩니다. 다음 문서에서는 일괄 처리 엔드포인트와 올바르게 상호 작용하는 방법 및 이에 대한 보안 요구 사항을 설명합니다.
권한 부여 작동 원리
일괄 처리 엔드포인트를 호출하려면 사용자가 보안 주체를 나타내는 유효한 Microsoft Entra 토큰을 제시해야 합니다. 이 주체는 사용자 주체 또는 서비스 주체일 수 있습니다. 어쨌든 엔드포인트가 호출되면 토큰과 연결된 ID 아래에 일괄 처리 배포 작업이 만들어집니다. 작업을 성공적으로 만들려면 ID에 다음 권한이 필요합니다.
- 일괄 처리 엔드포인트/배포를 읽습니다.
- 일괄 처리 유추 엔드포인트/배포에서 작업을 만듭니다.
- 실험/실행을 만듭니다.
- 데이터 저장소에서 읽고 씁니다.
- 데이터 저장소 비밀을 나열합니다.
RBAC 권한의 자세한 목록은 일괄 처리 엔드포인트 호출에 대한 RBAC 구성을 참조하세요.
Important
일괄 처리 엔드포인트를 호출하는 데 사용되는 ID는 데이터 저장소가 구성된 방식에 따라 기본 데이터를 읽는 데 사용되지 않을 수 있습니다. 자세한 내용은 데이터 액세스에 대한 컴퓨팅 클러스터 구성을 참조하세요.
다양한 형식의 자격 증명을 사용하여 작업을 실행하는 방법
다음 예에서는 다양한 형식의 자격 증명을 사용하여 일괄 처리 배포 작업을 시작하는 다양한 방법을 보여 줍니다.
Important
프라이빗 링크 사용 작업 영역에서 작업할 때 Azure Machine Learning 스튜디오의 UI에서 일괄 처리 엔드포인트를 호출할 수 없습니다. 대신 작업 만들기를 위해 Azure Machine Learning CLI v2를 사용하세요.
필수 조건
- 이 예제에서는 모델이 일괄 처리 엔드포인트로 올바르게 배포되었다고 가정합니다. 특히 일괄 처리 배포에서 MLflow 모델 사용 자습서에서 만든 심장 질환 분류자를 사용하고 있습니다.
사용자 자격 증명을 사용하여 작업 실행
이 경우 현재 로그인한 사용자의 ID를 사용하여 일괄 처리 엔드포인트를 실행하려고 합니다. 다음 단계를 수행합니다.
Azure CLI를 사용하여 대화형 또는 디바이스 코드 인증을 사용하여 로그인합니다.
az login인증되면 다음 명령을 사용하여 일괄 처리 배포 작업을 실행합니다.
az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci
서비스 주체를 사용하여 작업 실행
이 경우 Microsoft Entra ID에 이미 만들어진 서비스 주체를 사용하여 일괄 처리 엔드포인트를 실행하려고 합니다. 인증을 완료하려면 인증을 수행할 비밀을 만들어야 합니다. 다음 단계를 수행합니다.
옵션 3: 새 클라이언트 암호 만들기에 설명된 대로 인증에 사용할 비밀을 만듭니다.
서비스 주체를 사용하여 인증하려면 다음 명령을 사용합니다. 자세한 내용은 Azure CLI로 로그인을 참조하세요.
az login --service-principal \ --tenant <tenant> \ -u <app-id> \ -p <password-or-cert>인증되면 다음 명령을 사용하여 일괄 처리 배포 작업을 실행합니다.
az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/
관리 ID를 사용하여 작업 실행
관리 ID를 사용하여 일괄 처리 엔드포인트 및 배포를 호출할 수 있습니다. 이 관리 ID는 일괄 처리 엔드포인트에 속하지 않지만 엔드포인트를 실행하여 일괄 작업을 만드는 데 사용되는 ID입니다. 이 시나리오에서는 사용자 할당 ID와 시스템 할당 ID를 모두 사용할 수 있습니다.
Azure 리소스에 대한 관리 ID로 구성된 리소스에서 관리 ID를 사용하여 로그인할 수 있습니다. 리소스의 ID로 로그인하는 것은 --identity 플래그를 통해 이루어집니다. 자세한 내용은 Azure CLI로 로그인을 참조하세요.
az login --identity
인증되면 다음 명령을 사용하여 일괄 처리 배포 작업을 실행합니다.
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci
Batch 엔드포인트 호출에 대한 RBAC 구성
Batch 엔드포인트는 소비자가 작업을 생성하는 데 사용할 수 있는 지속성 API를 노출합니다. 호출자는 해당 작업을 생성할 수 있도록 적절한 권한을 요청합니다. 기본 제공 보안 역할 중 하나를 사용하거나 목적을 위해 사용자 지정 역할을 만들 수 있습니다.
일괄 처리 엔드포인트를 성공적으로 호출하려면 엔드포인트를 호출하는 데 사용되는 ID에 부여된 다음 명시적 작업이 필요합니다. 할당 방법은 Azure 역할 할당 단계를 참조하세요.
"actions": [
"Microsoft.MachineLearningServices/workspaces/read",
"Microsoft.MachineLearningServices/workspaces/data/versions/write",
"Microsoft.MachineLearningServices/workspaces/datasets/registered/read",
"Microsoft.MachineLearningServices/workspaces/datasets/registered/write",
"Microsoft.MachineLearningServices/workspaces/datasets/unregistered/read",
"Microsoft.MachineLearningServices/workspaces/datasets/unregistered/write",
"Microsoft.MachineLearningServices/workspaces/datastores/read",
"Microsoft.MachineLearningServices/workspaces/datastores/write",
"Microsoft.MachineLearningServices/workspaces/datastores/listsecrets/action",
"Microsoft.MachineLearningServices/workspaces/listStorageAccountKeys/action",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/read",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/read",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/deployments/jobs/write",
"Microsoft.MachineLearningServices/workspaces/batchEndpoints/jobs/write",
"Microsoft.MachineLearningServices/workspaces/computes/read",
"Microsoft.MachineLearningServices/workspaces/computes/listKeys/action",
"Microsoft.MachineLearningServices/workspaces/metadata/secrets/read",
"Microsoft.MachineLearningServices/workspaces/metadata/snapshots/read",
"Microsoft.MachineLearningServices/workspaces/metadata/artifacts/read",
"Microsoft.MachineLearningServices/workspaces/metadata/artifacts/write",
"Microsoft.MachineLearningServices/workspaces/experiments/read",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/submit/action",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/read",
"Microsoft.MachineLearningServices/workspaces/experiments/runs/write",
"Microsoft.MachineLearningServices/workspaces/metrics/resource/write",
"Microsoft.MachineLearningServices/workspaces/modules/read",
"Microsoft.MachineLearningServices/workspaces/models/read",
"Microsoft.MachineLearningServices/workspaces/endpoints/pipelines/read",
"Microsoft.MachineLearningServices/workspaces/endpoints/pipelines/write",
"Microsoft.MachineLearningServices/workspaces/environments/read",
"Microsoft.MachineLearningServices/workspaces/environments/write",
"Microsoft.MachineLearningServices/workspaces/environments/build/action",
"Microsoft.MachineLearningServices/workspaces/environments/readSecrets/action"
]
데이터 액세스를 위한 컴퓨팅 클러스터 구성
일괄 처리 엔드포인트는 권한 있는 사용자만 일괄 처리 배포를 호출하고 작업을 생성할 수 있도록 합니다. 그러나 입력 데이터를 구성하는 방법에 따라 다른 자격 증명을 사용하여 기본 데이터를 읽을 수 있습니다. 다음 표를 사용하여 어떤 자격 증명이 사용되는지 이해합니다.
| 데이터 입력 형식 | 저장소의 자격 증명 | 사용된 자격 증명 | 액세스 권한 부여자 |
|---|---|---|---|
| 데이터 저장소 | 예 | 작업 영역의 데이터 저장소 자격 증명 | 액세스 키 또는 SAS |
| 데이터 자산 | 예 | 작업 영역의 데이터 저장소 자격 증명 | 액세스 키 또는 SAS |
| 데이터 저장소 | 아니요 | 컴퓨팅 클러스터의 작업 ID + 관리 ID | RBAC |
| 데이터 자산 | 아니요 | 컴퓨팅 클러스터의 작업 ID + 관리 ID | RBAC |
| Azure Blob Storage | 적용되지 않음 | 컴퓨팅 클러스터의 작업 ID + 관리 ID | RBAC |
| Azure Data Lake Storage Gen1 | 적용되지 않음 | 컴퓨팅 클러스터의 작업 ID + 관리 ID | POSIX |
| Azure Data Lake Storage Gen2 | 적용되지 않음 | 컴퓨팅 클러스터의 작업 ID + 관리 ID | POSIX 및 RBAC |
컴퓨팅 클러스터의 작업 ID + 관리 ID가 표시되는 테이블의 항목에 대해 컴퓨팅 클러스터의 관리 ID는 스토리지 계정을 탑재하고 구성하는 데 사용됩니다. 그러나 작업의 ID는 여전히 기본 데이터를 읽는 데 사용되어 세분화된 액세스 제어를 달성할 수 있도록 합니다. 즉, 스토리지에서 데이터를 성공적으로 읽으려면 배포가 실행되는 컴퓨팅 클러스터의 관리 ID에 스토리지 계정에 대한 Storage Blob 데이터 읽기 권한자 이상의 액세스 권한이 있어야 합니다.
데이터 액세스를 위해 컴퓨팅 클러스터를 구성하려면 다음 단계를 수행합니다.
Azure Machine Learning 스튜디오로 이동합니다.
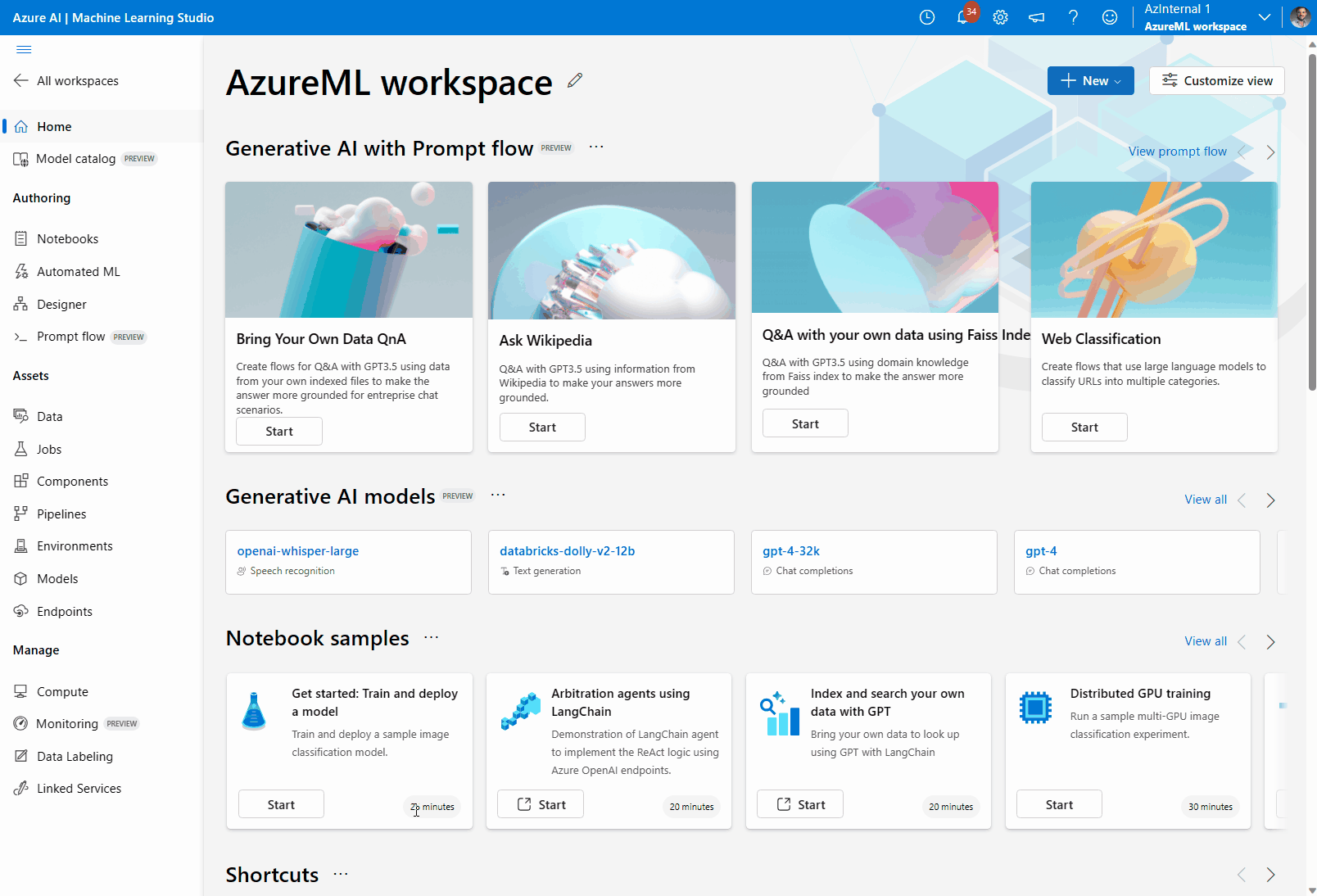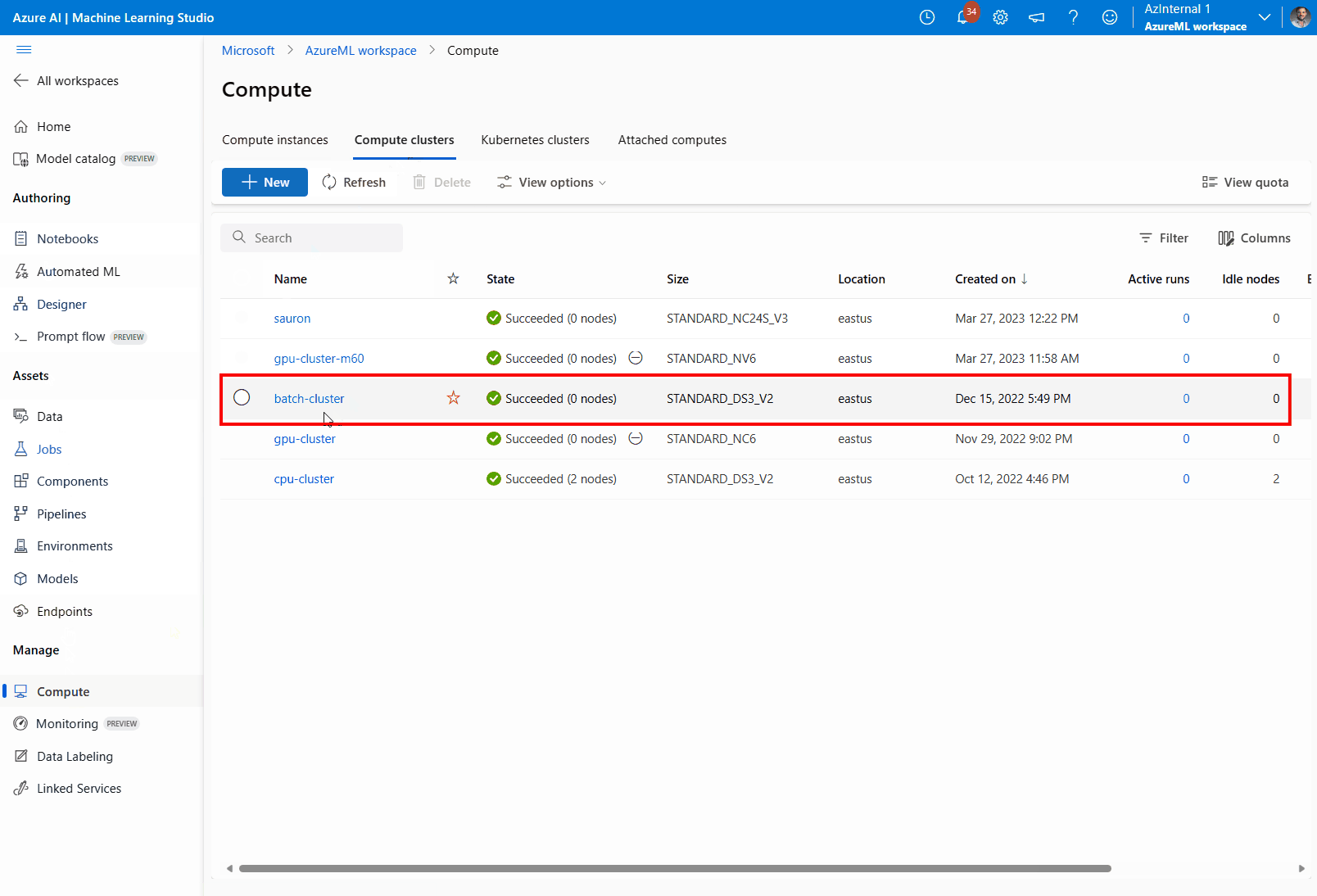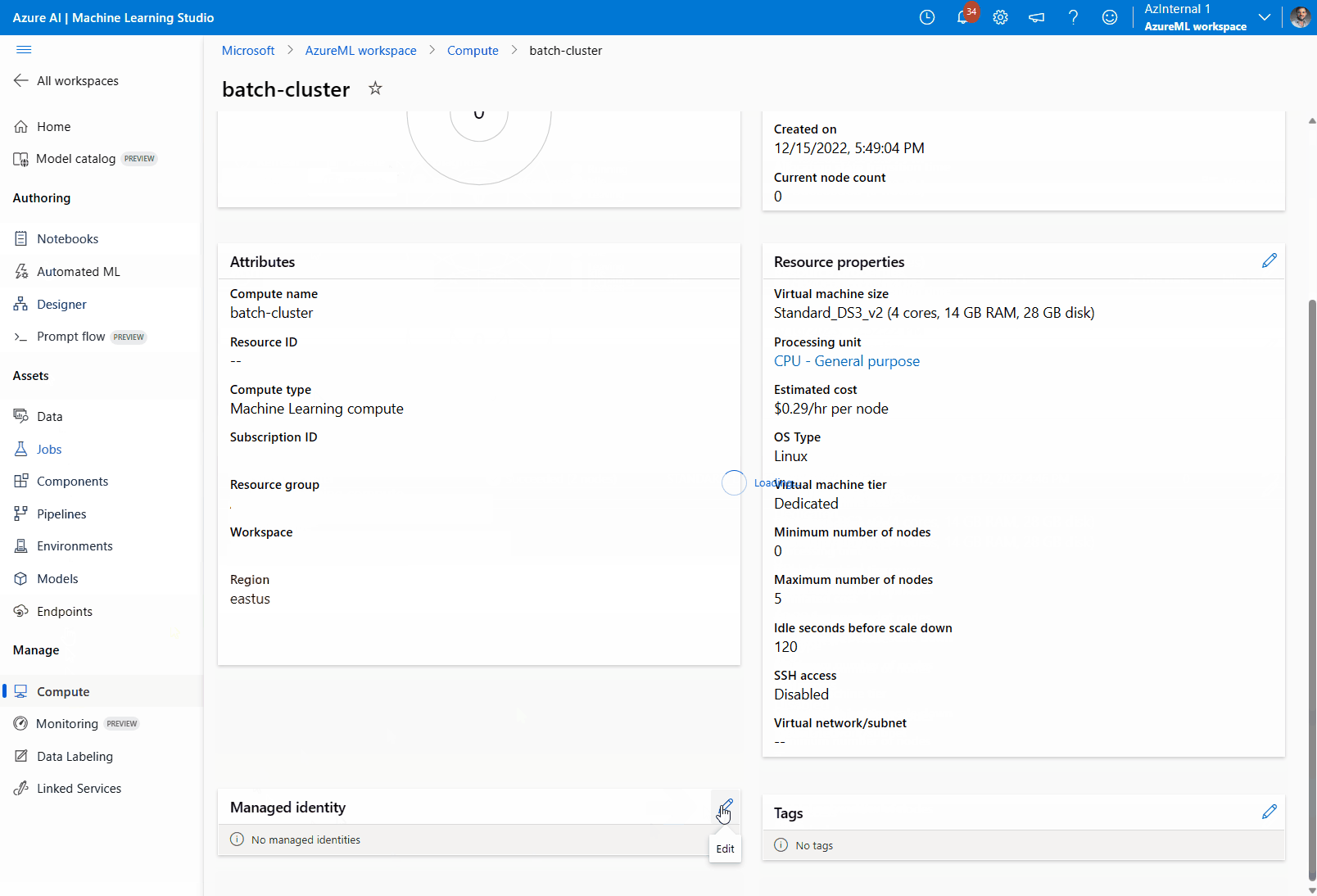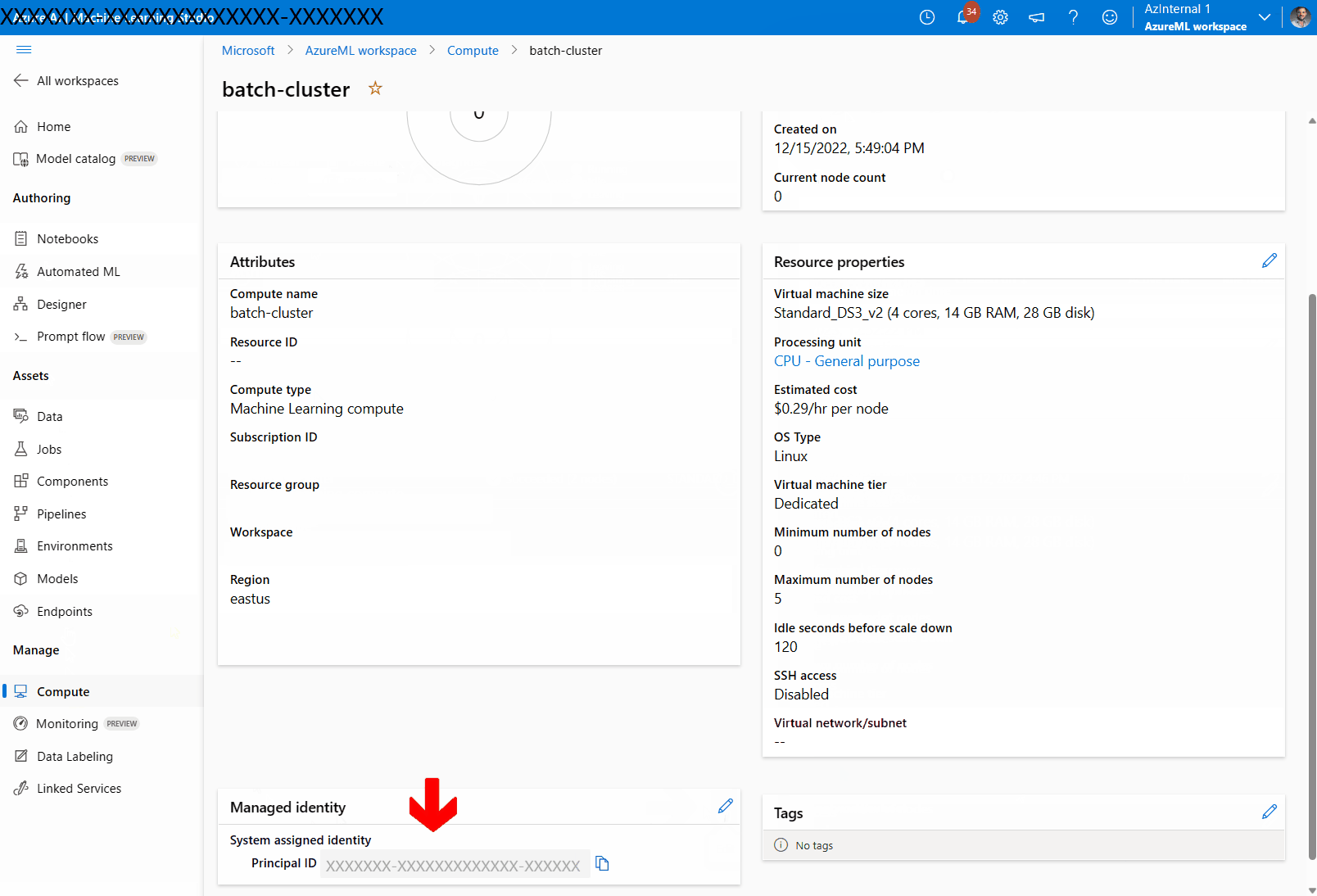
컴퓨팅으로 이동한 다음, 컴퓨팅 클러스터로 이동하고 배포에서 사용 중인 컴퓨팅 클러스터를 선택합니다.
컴퓨팅 클러스터에 관리 ID 할당:
관리 ID 섹션에서 컴퓨팅에 할당된 관리 ID가 있는지 확인합니다. 그렇지 않은 경우 편집 옵션을 선택합니다.
관리 ID 할당을 선택하고 필요에 따라 구성합니다. 시스템 할당 관리 ID 또는 사용자 할당 관리 ID를 사용할 수 있습니다. 시스템 할당 관리 ID를 사용하는 경우 "[작업 영역 이름]/computes/[컴퓨팅 클러스터 이름]"으로 이름이 지정됩니다.
변경 내용을 저장합니다.
Azure Portal로 이동하여 데이터가 있는 연결된 스토리지 계정으로 이동합니다. 데이터 입력이 데이터 자산 또는 데이터 저장소인 경우 해당 자산이 배치되는 스토리지 계정을 찾습니다.
스토리지 계정에서 Storage Blob 데이터 판독기 액세스 수준을 할당합니다.
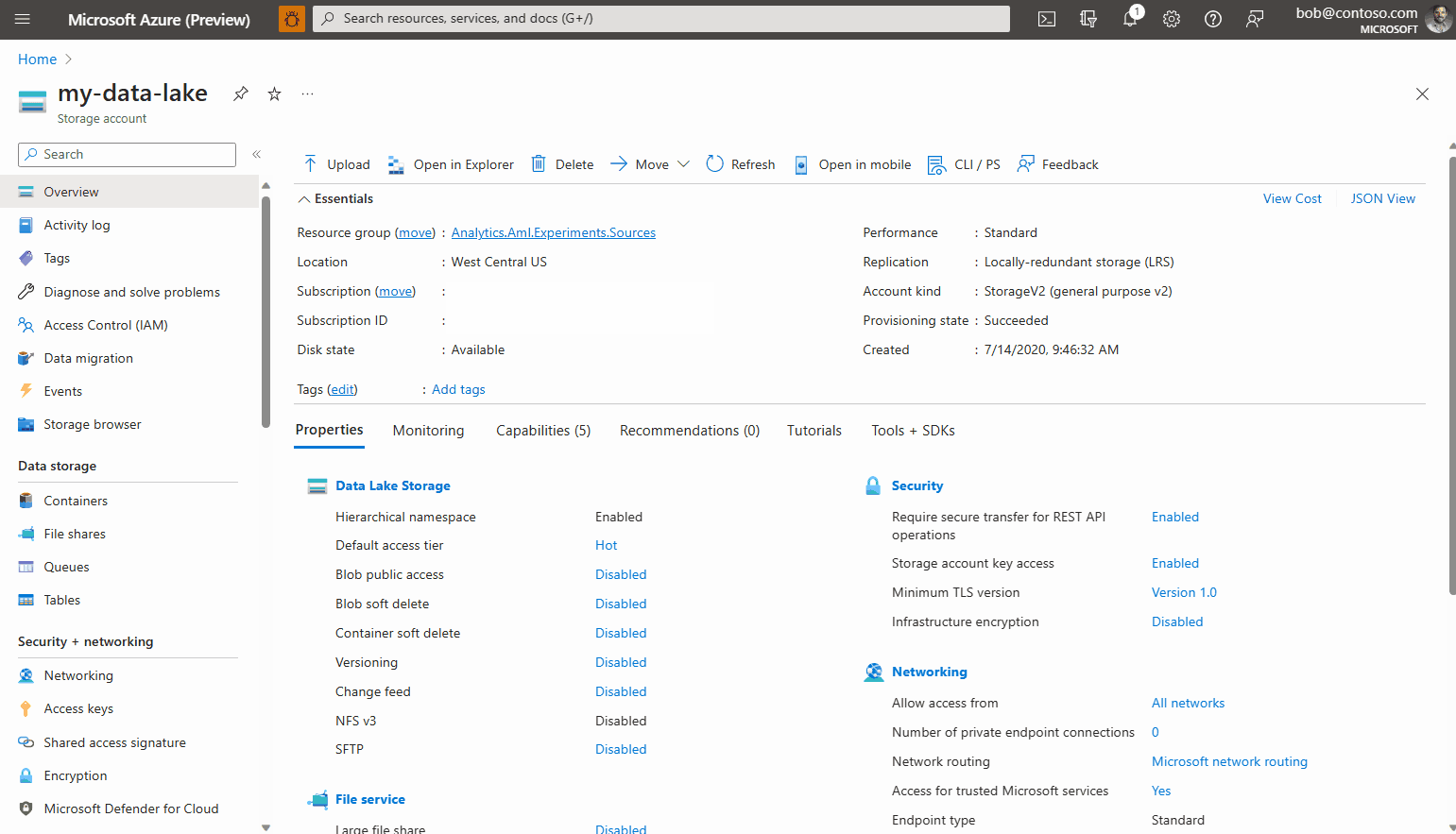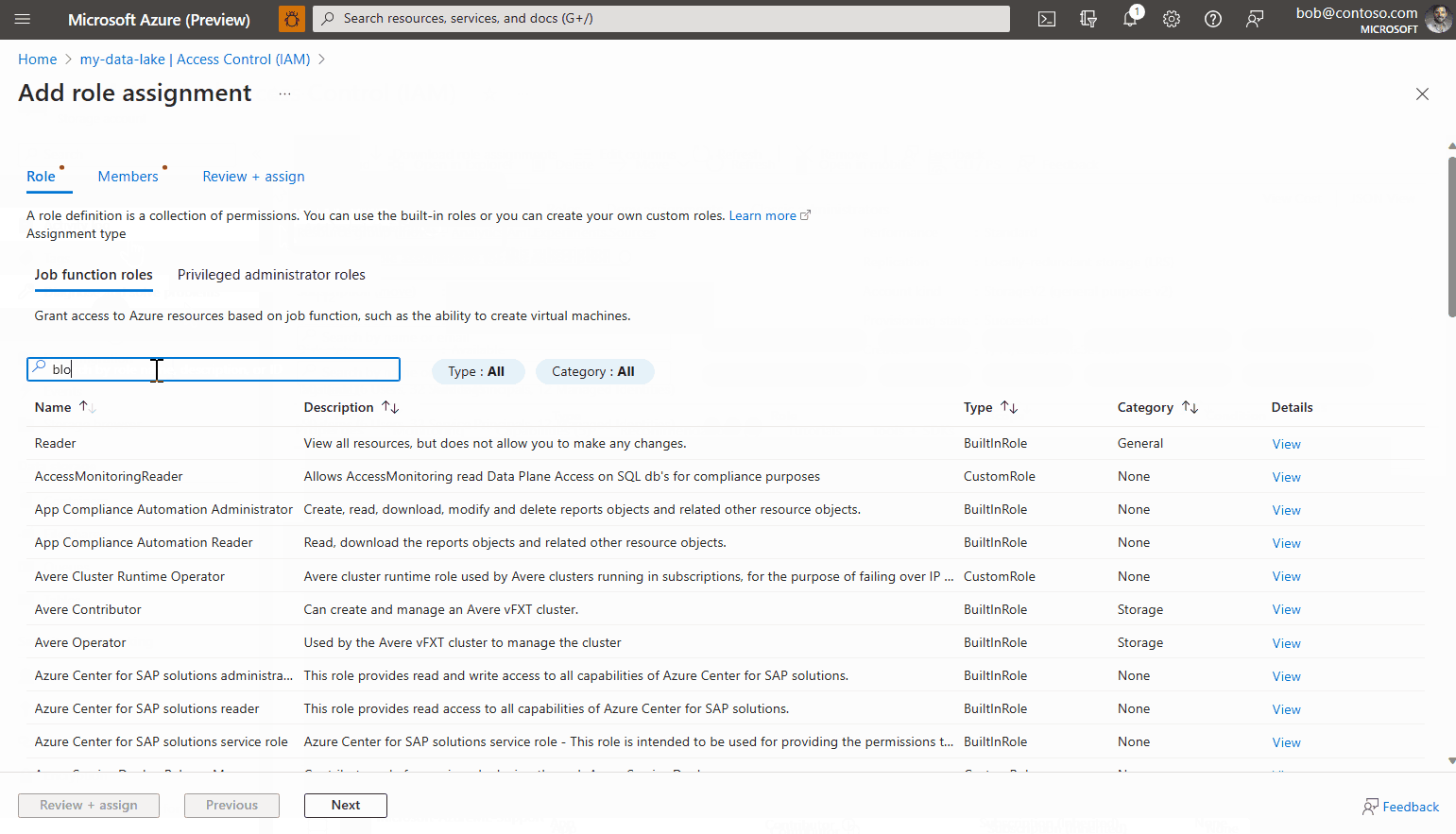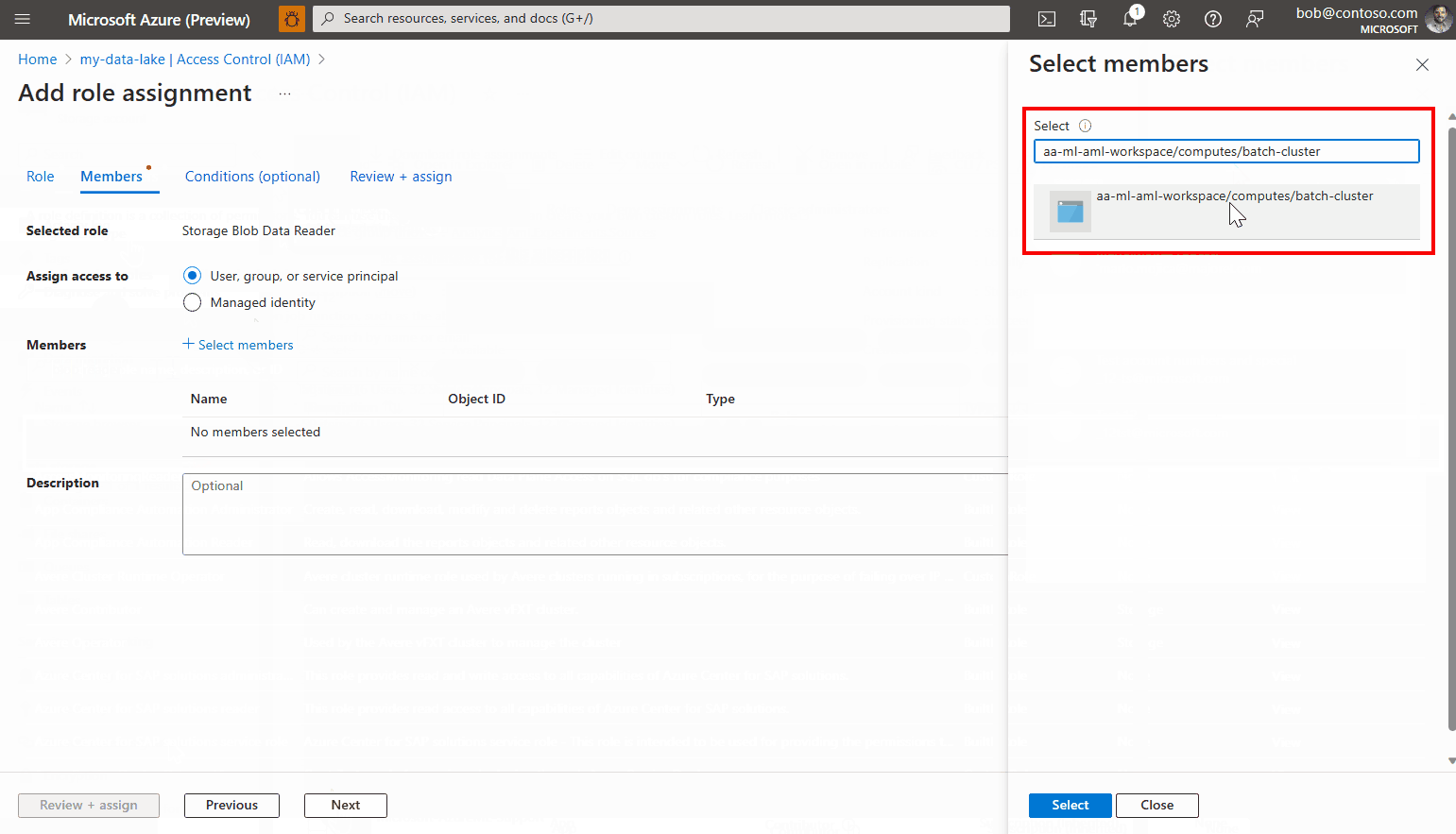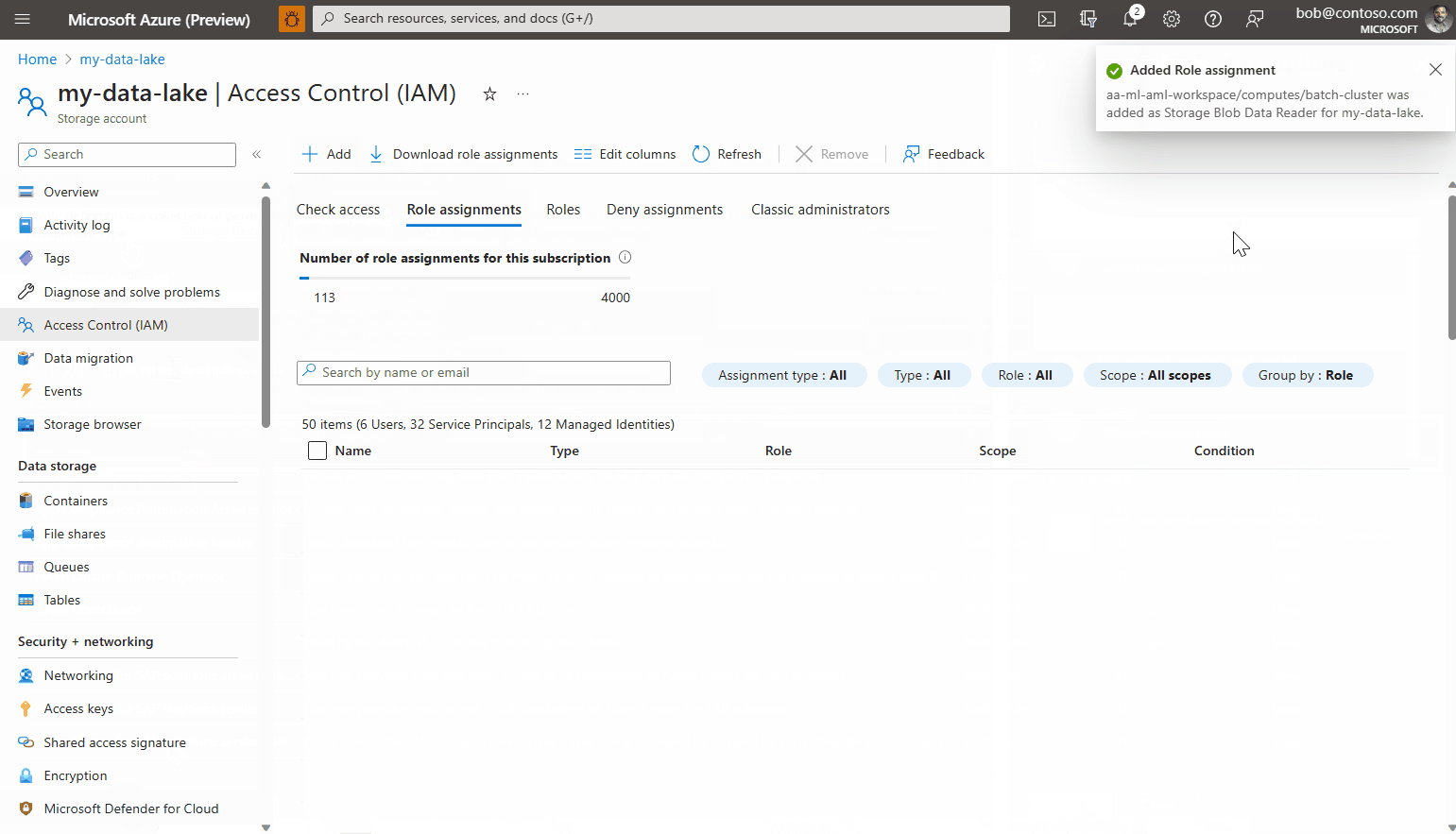
IAM(Access Control) 섹션으로 이동합니다.
역할 할당 탭을 선택한 다음 추가>역할 할당을 클릭합니다.
Storage Blob 데이터 판독기라는 역할을 찾아 선택하고 다음을 클릭합니다.
멤버 선택을 클릭합니다.
만든 관리 ID를 찾습니다. 시스템 할당 관리 ID를 사용하는 경우 "[작업 영역 이름]/computes/[컴퓨팅 클러스터 이름]"으로 이름이 지정됩니다.
계정을 추가하고 마법사를 완료합니다.
엔드포인트는 선택한 스토리지 계정에서 작업 및 입력 데이터를 받을 준비가 된 것입니다.