Python으로 시계열 예측 모델을 학습시키도록 AutoML 설정(SDKv1)
적용 대상:  Python SDK azureml v1
Python SDK azureml v1
이 문서에서는 Azure Machine Learning Python SDK에서 Azure Machine Learning 자동화 ML을 사용하여 시계열 예측 모델에 AutoML 학습을 설정하는 방법을 알아봅니다.
이렇게 하려면 다음을 수행합니다.
- 시계열 모델링에 대한 데이터를 준비합니다.
AutoMLConfig개체에서 특정 시계열 매개 변수를 구성합니다.- 시계열 데이터를 사용하여 예측을 실행합니다.
하위 코드 환경의 경우 Azure Machine Learning Studio에서 자동화된 ML을 사용하는 시계열 예측 예제를 알아보려면 자습서: 자동화된 Machine Learning으로 수요 예측을 참조하세요.
고전적인 시계열 방법과 달리, 자동화된 ML에서는 이전 시계열 값이 "피벗"되어 다른 예측 변수와 함께 회귀 변수의 추가 차원이 됩니다. 이 방법은 학습 중에 여러 컨텍스트 변수와 각 변수 간 관계를 통합합니다. 여러 요인이 예측에 영향을 줄 수 있으므로 이 방법은 실제 예측 시나리오에 적합합니다. 예를 들어 판매를 예측하는 경우 판매 결과에 과거 기록 추세의 상호 작용, 환율 및 가격이 모두 함께 영향을 미칩니다.
필수 조건
이 문서의 내용을 진행하려면 다음 항목이 필요합니다.
Azure Machine Learning 작업 영역 작업 영역을 만들려면 작업 영역 리소스 만들기를 참조하세요.
이 문서에서는 자동화된 Machine Learning 실험 설정에 어느 정도 익숙한 것으로 가정합니다. 방법에 따라 기본적인 자동화된 Machine Learning 실험 디자인 패턴을 확인합니다.
Important
이 문서의 Python 명령을 실행하려면 최신
azureml-train-automl패키지 버전이 필요합니다.- 로컬 환경에 최신
azureml-train-automl패키지를 설치합니다. - 최신
azureml-train-automl패키지에 대한 자세한 내용은 릴리스 정보를 참조하세요.
- 로컬 환경에 최신
학습 및 유효성 검사 데이터
자동화된 ML에서 예측 회귀 작업 유형과 회귀 작업 유형 간의 가장 중요한 차이점은 유효한 시계열을 나타내는 기능을 학습 데이터에 포함하는 것입니다. 정규 시계열에는 잘 정의되고 일관된 빈도가 있으며 연속 시간 범위의 모든 샘플 요소에 값이 있습니다.
Important
미래 가치를 예측하기 위해 모델을 학습하는 경우 학습에 사용된 모든 기능을 의도한 구간에 대해 예측을 실행할 때도 사용할 수 있는지 확인합니다. 예를 들어, 수요 예측을 만들 때 현재 주가에 대한 기능을 포함하면 학습 정확도가 크게 높아질 수 있습니다. 그러나 장기 구간을 사용하여 예측하려는 경우 미래 시계열 요소에 해당하는 선물 주가를 정확하게 예측할 수 없으며 모델 정확성이 떨어질 수 있습니다.
별도의 학습 데이터 및 유효성 검사 데이터를 AutoMLConfig 개체에서 직접 지정할 수 있습니다. AutoMLConfig에 대해 자세히 알아보세요.
시계열 예측의 경우 기본적으로 ROCV(이동 원본 교차 유효성 검사)만 유효성 검사에 사용됩니다. ROCV는 원본 시간 요소를 사용하여 계열을 학습 및 유효성 검사 데이터로 나눕니다. 원본을 시간에 따라 슬라이딩하여 교차 유효성 검사 겹을 생성합니다. 이 전략은 시계열 데이터의 무결성을 유지하고 데이터 누출의 위험을 제거합니다.
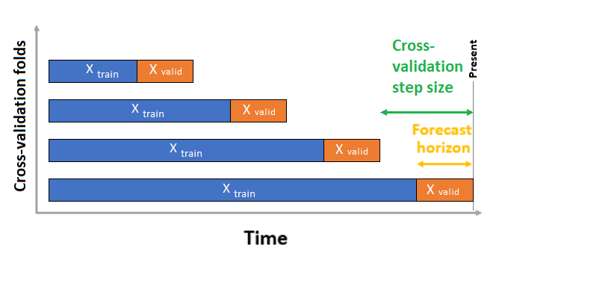
학습 및 유효성 검사 데이터를 하나의 데이터 세트로 매개 변수 training_data에 전달합니다. 매개 변수 n_cross_validations를 사용하여 교차 유효성 검사 폴드 수를 설정하고 cv_step_size를 사용하여 두 개의 연속 교차 유효성 검사 폴딩 사이의 기간 수를 설정합니다. 또는 두 매개 변수를 모두 비워 둘 수도 있으며 이 경우 AutoML에서 자동으로 설정됩니다.
적용 대상: Python SDK azureml v1
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
자체 유효성 검사 데이터를 가져올 수 있으며 AutoML에서 데이터 분할 및 교차 유효성 검사 구성에서 자세히 알아볼 수 있습니다.
AutoML이 교차 유효성 검사를 적용하여 과잉 맞춤 모델을 방지하는 방법에 대해 자세히 알아봅니다.
실험 구성
AutoMLConfig 개체는 자동화된 기계 학습 태스크에 필요한 설정 및 데이터를 정의합니다. 예측 모델의 구성은 표준 회귀 모델의 설정과 유사하지만 특히 시계열 데이터에 대해서는 특정 모델, 구성 옵션 및 기능화 단계가 존재합니다.
지원되는 모델
자동화된 Machine Learning은 모델 생성 및 튜닝 프로세스의 일부로 다른 모델 및 알고리즘을 자동으로 시도합니다. 사용자는 알고리즘을 지정할 필요가 없습니다. 예측 실험의 경우 원시 시계열 및 딥 러닝 모델은 모두 권장 시스템의 일부입니다.
팁
기존 회귀 모델도 예측 실험을 위한 권장 시스템의 일부로 테스트됩니다. SDK 참조 설명서에서 지원되는 모델의 전체 목록을 참조하세요.
구성 설정
회귀 문제와 마찬가지로 태스크 유형, 반복 횟수, 학습 데이터 및 교차 유효성 검사 수와 같은 표준 학습 매개 변수를 정의합니다. 예측 작업에는 실험을 구성하기 위해 time_column_name 및 forecast_horizon 매개 변수가 필요합니다. 데이터에 여러 매장의 판매 데이터 또는 여러 상태의 에너지 데이터와 같은 여러 시계열이 포함된 경우 자동화된 ML에서 자동으로 이를 감지하고 time_series_id_column_names 매개 변수(미리 보기)를 설정합니다. 실행을 더 잘 구성하기 위해 추가 매개 변수를 포함할 수도 있습니다. 포함할 수 있는 항목에 대한 자세한 내용은 선택적 구성 섹션을 참조하세요.
Important
자동 시계열 식별은 현재 공개 미리 보기로 제공됩니다. 이 미리 보기 버전은 서비스 수준 계약 없이 제공됩니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
| 매개 변수 이름 | 설명 |
|---|---|
time_column_name |
시계열을 작성하고 해당 빈도를 유추하는 데 사용되는 날짜/시간 열을 입력 데이터에 지정하는 데 사용됩니다. |
forecast_horizon |
앞으로 어느 정도의 기간에 대해 예측할 것인지 정의합니다. 구간은 시계열 빈도의 단위입니다. 단위는 예측자가 예측해야 하는 학습 데이터의 시간 간격(예: 매월, 매주)을 기준으로 합니다. |
코드는 다음과 같습니다.
ForecastingParameters클래스를 사용하여 실험 학습에 대한 예측 매개 변수를 정의합니다.time_column_name을 데이터 세트의day_datetime필드에 설정합니다.- 전체 테스트 세트를 예측하려면
forecast_horizon을 50으로 설정합니다.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
다음으로 이들 forecasting_parameters가 표준 AutoMLConfig 개체로 전달되고 forecasting 작업 유형, 기본 메트릭, 종료 조건 및 학습 데이터도 함께 전달됩니다.
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
자동화된 ML을 사용하여 예측 모델을 학습시키는 데 필요한 데이터 양은 AutoMLConfig를 구성할 때 지정된 forecast_horizon, n_cross_validations 및 target_lags 또는 target_rolling_window_size 값의 영향을 받습니다.
다음 수식은 시계열 기능을 구성하는 데 필요한 기록 데이터의 양을 계산합니다.
필요한 최소 기록 데이터: (2x forecast_horizon) + #n_cross_validations + max(max(target_lags ), target_rolling_window_size)
지정된 관련 설정에 필요한 기록 데이터 양을 충족하지 않는 데이터 세트의 계열에 대해서는 Error exception이 발생합니다.
기능화 단계
모든 자동화된 Machine Learning 실험에서 자동 크기 조정 및 정규화 기술이 기본적으로 데이터에 적용됩니다. 이러한 기술은 기능화 유형으로서 다양한 규모에서의 기능에 민감한 특정 알고리즘을 지원합니다. AutoML의 기능화에서 기본 기능화 단계에 대해 자세히 알아봅니다.
그러나 다음 단계는 forecasting 작업 유형에 대해서만 수행됩니다.
- 시계열 샘플 빈도(예: 매시간, 매일, 매주)를 검색하고 없는 시간 요소의 새 레코드를 만들어 계열이 연속되도록 합니다.
- 누락된 값을 대상(전방 채우기를 통해) 및 기능 열(중앙값 열 값 사용)에 귀속
- 시계열 식별자를 기반으로 기능을 만들어 여러 계열에서 고정 효과를 사용할 수 있도록 설정
- 계절적 패턴을 학습하는 데 도움이 되는 시간 기반 기능 만들기
- 범주 변수를 숫자 수량으로 인코딩
- 고정되지 않은 시계열을 감지하고 자동으로 구분하여 단위 루트의 영향을 완화합니다.
시계열 데이터에서 생성된 가능한 엔지니어링된 기능의 전체 목록을 보려면 TimeIndexFeaturizer 클래스를 참조하세요.
참고 항목
자동화된 Machine Learning 기능화 단계(기능 정규화, 누락된 데이터 처리, 텍스트를 숫자로 변환 등)는 기본 모델의 일부가 됩니다. 예측에 모델을 사용하는 경우 학습 중에 적용되는 동일한 기능화 단계가 입력 데이터에 자동으로 적용됩니다.
기능화 사용자 지정
또한 ML 모델을 학습시키는 데 사용되는 데이터와 기능이 관련 있는 예측 결과를 내도록 기능화 설정을 사용자 지정하는 옵션도 있습니다.
forecasting 작업에 대해 지원되는 사용자 지정은 다음과 같습니다.
| 사용자 지정 | 정의 |
|---|---|
| 열 용도 업데이트 | 지정된 열에 대해 자동 감지된 기능 유형을 재정의합니다. |
| 변환기 매개 변수 업데이트 | 지정된 변환기의 매개 변수를 업데이트합니다. 현재 Imputer(fill_value 및 median)를 지원합니다. |
| 열 삭제 | 기능화에서 삭제할 열을 지정합니다. |
SDK를 사용하여 기능화를 사용자 지정하려면 "featurization": FeaturizationConfig를 AutoMLConfig 개체에 지정합니다. 사용자 지정 기능화에 대해 자세히 알아봅니다.
참고 항목
열 삭제 기능은 SDK 버전 1.19부터 더 이상 사용되지 않습니다. 자동화된 ML 실험에서 사용하기 전에 데이터 정리의 일부로 데이터 세트에서 열을 삭제합니다.
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
실험에 Azure Machine Learning 스튜디오를 사용하는 경우 스튜디오에서 기능화를 사용자 지정하는 방법을 참조하세요.
선택적 구성
딥 러닝을 사용하도록 설정하고 대상 롤링 기간 집계를 지정하는 등의 예측 작업에 더 많은 옵션 구성을 사용할 수 있습니다. 더 많은 매개 변수의 전체 목록은 ForecastingParameters SDK 참조 설명서에서 확인할 수 있습니다.
빈도 및 대상 데이터 집계
빈도, freq, 매개 변수를 사용하여 불규칙한 데이터로 인한 오류를 방지합니다. 불규칙한 데이터에는 시간별 또는 일별 데이터와 같이 설정된 주기를 따르지 않는 데이터가 포함됩니다.
매우 불규칙한 데이터 또는 변화하는 비즈니스 요구에 대해 사용자는 원하는 예측 빈도인 freq를 선택적으로 설정하고 target_aggregation_function을 지정하여 시계열의 대상 열을 집계할 수 있습니다. AutoMLConfig 개체에서 이 두 가지 설정을 사용하면 데이터 준비 시간을 절약할 수 있습니다.
대상 열 값에 대해 지원되는 집계 작업은 다음과 같습니다.
| 함수 | 설명 |
|---|---|
sum |
대상 값의 합계 |
mean |
대상 값의 평균 또는 산술평균 |
min |
대상의 최솟값 |
max |
대상의 최댓값 |
딥 러닝 사용
참고 항목
자동화된 Machine Learning의 예측에 대한 DNN 지원은 미리 보기로 제공되며, 로컬 실행 또는 Databricks에서 시작된 실행에는 지원되지 않습니다.
심층 신경망, 즉 DNN을 사용한 딥 러닝을 적용하여 모델의 점수를 개선할 수도 있습니다. 자동화된 ML의 딥 러닝을 사용하여 단변량 및 다변량 시계열 데이터를 예측할 수 있습니다.
딥 러닝 모델에는 다음과 같은 세 가지 기능이 내장되어 있습니다.
- 입력에서 출력으로의 임의 매핑에서 학습할 수 있습니다.
- 여러 입력 및 출력을 지원합니다.
- 긴 시퀀스에 걸쳐 있는 입력 데이터의 패턴을 자동으로 추출할 수 있습니다.
딥 러닝을 사용하도록 설정하려면 AutoMLConfig 개체에서 enable_dnn=True를 설정합니다.
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
Warning
SDK로 만든 실험에 DNN을 사용하도록 설정하면 최상의 모델 설명이 사용하지 않도록 설정됩니다.
Azure Machine Learning 스튜디오에서 만든 AutoML 실험에 DNN을 사용하도록 설정하려면 스튜디오 UI에서 작업 유형 설정 방법을 참조하세요.
대상 이동 기간 집계
예측자의 가장 좋은 정보는 대상의 최근 값인 경우가 많습니다. 대상 이동 기간 집계를 사용하면 데이터 값의 이동 집계를 기능으로 추가할 수 있습니다. 이러한 기능을 추가적인 상황별 데이터로 생성하여 사용하면 학습 모델의 정확도에 도움이 됩니다.
예를 들어 에너지 수요를 예측하고자 한다고 가정해 봅니다. 가열된 공간의 열 변화를 설명하기 위해 이동 기간 기능에 3일을 추가하고자 할 수 있습니다. 이 예에서는 AutoMLConfig 생성자에서 target_rolling_window_size= 3을 설정하여 이 기간을 만듭니다.
이 표는 기간 집계가 적용될 때 발생하는 기능 엔지니어링 결과를 보여 줍니다. 최소, 최대 및 합계 열은 정의된 설정을 기반으로 3개의 슬라이딩 윈도우에서 생성됩니다. 각 행에는 새로 계산된 기능이 있는데 2017년 9월 8일 오전 4시 타임스탬프의 경우 최대, 최소 및 합계 값은 2017년 9월 8일 오전 1시 - 오전 3시의 수요 값을 사용하여 계산됩니다. 이 3개의 기간은 함께 이동하면서 나머지 행의 데이터를 채웁니다.

대상 이동 기간 집계 기능을 적용하는 Python 코드 예제를 확인합니다.
짧은 계열 처리
자동화된 ML은 모델 개발의 학습 및 유효성 검사 단계를 수행하기에 충분한 데이터 요소가 없으면 시계열을 짧은 계열로 간주합니다. 데이터 포인트의 수는 각 실험마다 다르며, max_horizon, 교차 유효성 검사 분할 수, 시계열 기능을 생성하는 데 필요한 기록의 최댓값인 모델 Lookback의 길이에 따라 달라집니다.
자동화된 ML은 short_series_handling_configuration 매개 변수를 사용하여 ForecastingParameters 개체에서 기본적으로 짧은 계열 처리를 제공합니다.
짧은 계열 처리를 사용하도록 설정하려면 freq 매개 변수도 정의해야 합니다. 시간별 빈도를 정의하기 위해 freq='H'를 설정합니다. pandas 시계열 페이지 DataOffset 개체 섹션을 방문하여 빈도 문자열 옵션을 봅니다. short_series_handling_configuration = 'auto'인 기본 동작을 변경하려면 short_series_handling_configuration 매개 변수를 ForecastingParameter 개체에서 업데이트합니다.
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
다음 표에는 short_series_handling_config에 사용할 수 있는 설정이 요약되어 있습니다.
| 설정 | 설명 |
|---|---|
auto |
짧은 계열 처리의 기본값입니다. - 모든 계열이 짧은 경우 데이터를 패딩합니다. - 모든 계열이 짧은 것은 아닌 경우 짧은 계열을 삭제합니다. |
pad |
short_series_handling_config = pad인 경우 자동화된 ML은 찾아낸 각 짧은 계열에 임의 값을 추가합니다. 다음 목록에는 열 유형과 채워지는 항목이 나와 있습니다. - NaN으로 채워지는 개체 열 - 0으로 채워지는 숫자 열 - False로 채워지는 부울/논리 열 - 대상 열은 평균이 0이고 표준 편차가 1인 임의 값으로 채워집니다. |
drop |
short_series_handling_config = drop인 경우 자동화된 ML이 짧은 계열을 삭제하여 학습 또는 예측에 사용되지 않습니다. 이러한 계열에 대한 예측은 NAN을 반환합니다. |
None |
채워지거나 삭제된 계열이 없음 |
Warning
채우기는 모델 결과의 정확도에 영향을 줄 수 있는데 이는 이전 학습을 오류 없이 가져오려고 인공 데이터를 도입하고 있기 때문입니다. 많은 계열이 짧은 경우 설명 가능성 결과에 어느 정도 영향이 있을 수 있습니다.
비고정 시계열 검색 및 처리
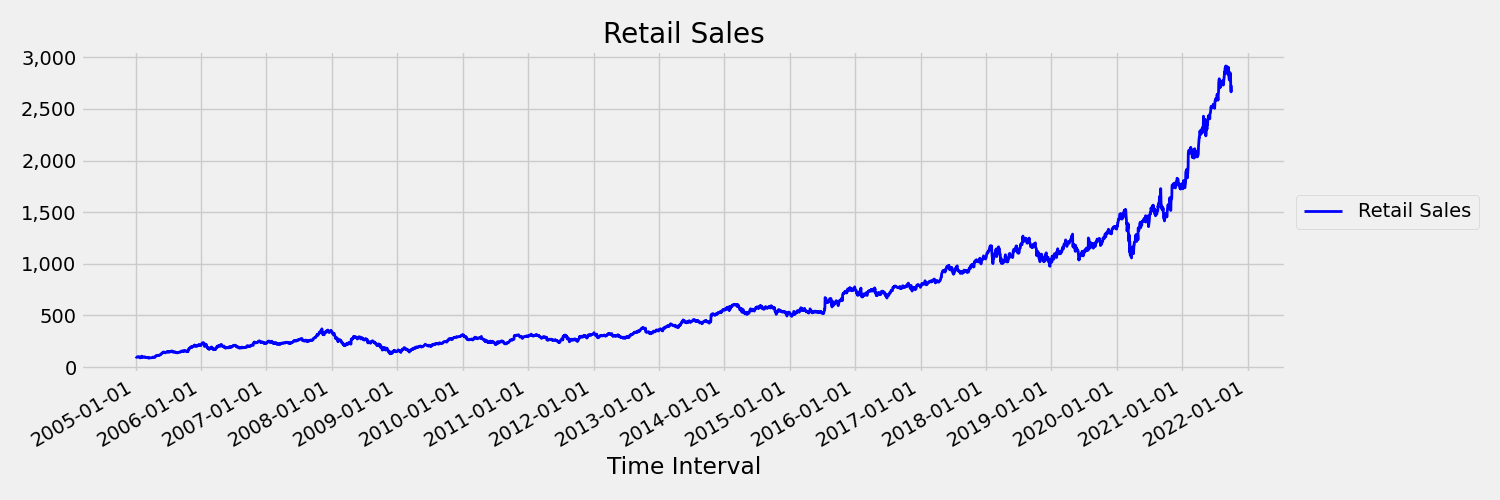
모멘트(평균과 분산)가 시간 경과에 따라 변하는 시계열을 비고정이라고 합니다. 예를 들어, 확률적 추세를 나타내는 시계열은 본질적으로 비고정입니다. 이를 시각화하기 위해 아래 이미지는 일반적으로 상승 추세를 보이는 계열을 그립니다. 이제 계열의 첫 번째와 두 번째 절반에 대한 평균(average) 값을 계산하고 비교합니다. 두 팀이 똑같나요? 여기서 플롯의 전반부에 있는 계열의 평균은 후반부보다 작습니다. 시계열의 평균이 보고 있는 시간 간격에 따라 달라진다는 사실은 시변 모멘트의 예입니다. 여기서 계열의 평균은 첫 번째 모멘트입니다.
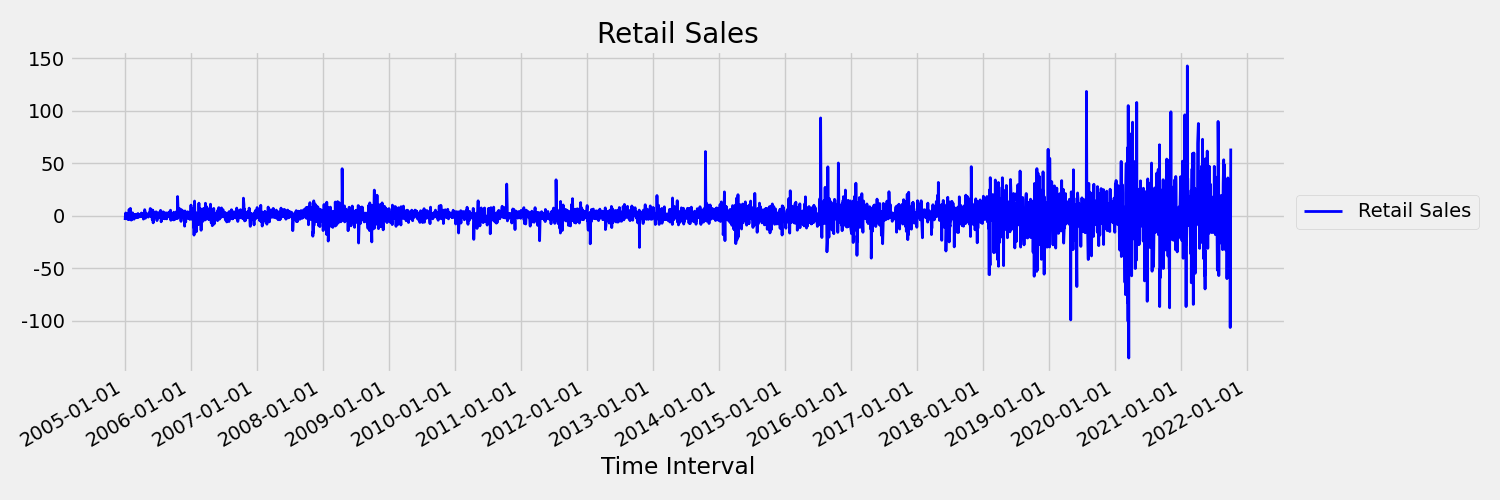
다음으로, 첫 번째 차이점으로 원래 시리즈를 그리는 이미지를 살펴보겠습니다. $x_t = y_t - y_{t-1}$, 여기서 $x_t$는 소매 판매의 변화이며 $y_t$ 및 $y_{t-1}$는 각각 원래 계열과 첫 번째 지연을 나타냅니다. 계열의 평균은 보고 있는 시간 프레임에 관계없이 거의 일정합니다. 이는 1차 고정 시계열의 예입니다. 첫 번째 순서 용어를 추가한 이유는 첫 번째 모멘트(평균)가 시간 간격에 따라 변경되지 않고 두 번째 모멘트인 분산에 대해서도 동일한 것을 알 수 없기 때문입니다.
AutoML 기계 학습 모델은 본질적으로 확률적 추세 또는 비고정 시계열과 관련된 기타 잘 알려진 문제를 처리할 수 없습니다. 결과적으로 이러한 추세가 존재하는 경우 샘플 외 예측 정확도가 "나쁨"이 됩니다.
AutoML은 시계열 데이터 세트를 자동으로 분석하여 고정 여부와 관계없이 검사합니다. 고정되지 않은 시계열이 검색되면 AutoML은 비정착 시계열의 효과를 완화하기 위해 자동으로 차이점 변형을 적용합니다.
실험 실행
AutoMLConfig 개체가 준비되면 실험을 제출할 수 있습니다. 모델이 완료된 후 최상의 실행 반복을 검색합니다.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
최적 모델로 예측
최상의 모델 반복을 사용하여 모델 학습에 사용되지 않은 데이터의 값을 예측합니다.
롤링 예측을 사용하여 모델 정확도 평가
모델을 프로덕션 환경에 배치하기 전에 학습 데이터에서 유지된 테스트 집합에서 정확도를 평가해야 합니다. 모범 사례 절차는 테스트 집합에 대해 학습된 예측을 시간에 따라 롤포워드하는 롤링 평가로, 선택한 일부 메트릭 집합에 대해 통계적으로 강력한 추정치를 얻기 위해 여러 예측 기간에 대한 오류 메트릭의 평균을 산정합니다. 이상적으로 평가에 대한 테스트 집합은 모델의 예측 기간에 비해 깁니다. 예측 오류의 예측값은 통계적으로 노이즈할 수 있으므로 신뢰성이 떨어집니다.
예를 들어 모델에 일일 판매량을 학습시켜 향후 최대 2주(14일)의 수요를 예측한다고 가정합니다. 사용 가능한 기록 데이터가 충분한 경우 테스트 집합에 대해 최종 몇 개월의 데이터부터 1년의 데이터까지 예약할 수 있습니다. 롤링 평가는 테스트 집합의 처음 2주 동안 14일 전 예측을 생성하는 것으로 시작됩니다. 그런 다음, 테스트 집합에 대해 며칠 동안의 예측이 진행되며 새 위치부터 또 다른 14일 전 예측을 생성합니다. 테스트 집합 끝에 도달할 때까지 이 프로세스가 계속됩니다.
롤링 평가를 수행하려면 fitted_model의 rolling_forecast 메서드를 호출한 다음, 결과에 대해 원하는 메트릭을 계산합니다. 예를 들어 test_features_df라는 pandas DataFrame에 테스트 집합 기능이 있고 test_target라는 numpy 배열에 대상의 테스트 집합 실제 값이 있다고 가정합니다. 평균 제곱 오차를 사용한 롤링 평가는 다음 코드 샘플에 나와 있습니다.
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
이 샘플에서 롤링 예측의 단계 크기는 1로 설정되어 있습니다. 즉, 각 반복에서 예측자가 한 기간 또는 수요 예측 예에서 하루 앞으로 나아갑니다. 따라서 rolling_forecast에서 반환되는 총 예측 수는 테스트 집합의 길이와 이 단계 크기에 따라 달라집니다. 자세한 내용 및 예제는 rolling_forecast() 설명서 및 학습 데이터에서 벗어나는 예측 Notebook을 참조하세요.
미래 예측
forecast_quantiles() 함수는 일반적으로 분류 및 회귀 작업에 사용되는 predict() 메서드와 달리 예측이 시작되어야 하는 시기를 지정할 수 있습니다. 기본적으로 forecast_quantiles() 메서드는 요소 예측 또는 평균/중앙값 예측을 생성하며, 이 예측에서는 시간이 지나며 불확실성이 점차 감소하는 현상(Cone of Uncertainty)이 나타나지 않습니다. 학습 데이터 Notebook에서 벗어나는 예측에 대해 자세히 알아보세요.
다음 예제에서는 먼저 y_pred의 모든 값을 NaN으로 바꿉니다. 이 경우에는 예측 원점이 학습 데이터의 끝에 오게 됩니다. 그러나 y_pred의 두 번째 절반을 NaN으로 바꾸면 이 함수는 처음 절반의 숫자 값을 수정하지 않은 상태로 유지하지만 두 번째 절반의 NaN 값을 예측합니다. 이 함수는 예측된 값과 정렬된 기능을 모두 반환합니다.
forecast_quantiles() 함수에서 forecast_destination 매개 변수를 사용하여 지정된 날짜까지의 값을 예측할 수도 있습니다.
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
종종 고객은 분포의 특정 분위수에서 예측을 이해하려고 합니다. 예를 들어 식료품 품목 또는 클라우드 서비스용 가상 머신과 같은 인벤토리를 제어하는 데 예측을 사용하는 경우가 있습니다. 이 경우 제어점은 일반적으로 “품목이 재고가 있고 99%가 소진되지 않기를 원합니다”와 같은 것입니다. 다음은 50번째 백분위수 또는 95번째 백분위수와 같이 예측을 위해 보고 싶은 분위수를 지정하는 방법을 보여 줍니다. 앞서 언급한 코드 예제와 같이 분위수를 지정하지 않으면 50번째 백분위수 예측만 생성됩니다.
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
모델 성능을 예측하는 데 도움이 되는 RMSE(제곱 평균 오차) 또는 MAPE(절대 평균 백분율 오차)와 같은 모델 메트릭을 계산할 수 있습니다. 예제는 자전거 공유 수요 Notebook의 평가 섹션을 참조하세요.
전체적인 모델 정확도를 확인한 후에 가장 현실적인 다음 단계는 모델을 사용하여 알 수 없는 미래 가치를 예측하는 것입니다.
테스트 세트 test_dataset와 형식은 같지만 날짜/시간이 미래인 데이터 세트를 제공하면 결과 예측 세트는 각 시계열 단계에 대해 예측된 값입니다. 데이터 세트의 마지막 시계열 레코드가 2018년 12월 31일에 대한 것이라고 가정합니다. 다음 날(또는 <= forecast_horizon을 예측해야 하는 기간)의 수요를 예측하려면 2019년 1월 1일의 각 매장에 대한 단일 시계열 레코드를 만듭니다.
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
필요한 단계를 반복하여 이 미래 데이터를 데이터 프레임에 로드하고 best_run.forecast_quantiles(test_dataset)를 실행하여 미래 가치를 예측합니다.
참고 항목
target_lags 및/또는 target_rolling_window_size를 사용하도록 설정한 경우 자동화된 ML을 사용한 예측에서 샘플 내 예측은 지원되지 않습니다.
대규모 예측
단일 기계 학습 모델로는 충분하지 않아 여러 기계 학습 모델이 필요한 시나리오가 있습니다. 예를 들어 특정 브랜드의 각 개별 매장에서 판매를 예측하거나 개별 사용자에 맞게 경험을 조정하는 것입니다. 각 인스턴스에 대한 모델을 빌드하면 많은 기계 학습 문제에서 결과가 향상될 수 있습니다.
그룹화는 그룹별로 개별 모델을 학습하기 위해 결합할 수 있는 시계열 예측의 한 개념입니다. 이 방법은 그룹에 다른 엔터티의 기록 또는 추세를 활용할 수 있는 스무딩, 채우기 또는 엔터티가 필요한 시간 계열이 있는 경우에 특히 유용할 수 있습니다. 많은 모델 및 계층적 시계열 예측은 이러한 대규모 예측 시나리오에 대한 자동화된 기계 학습을 통해 구동되는 솔루션입니다.
여러 모델
자동화된 기계 학습이 포함된 Azure Machine Learning 많은 모델 솔루션을 통해 사용자는 수백만 개의 모델을 병렬로 학습하고 관리할 수 있습니다. 많은 모델 솔루션 가속기는 Azure Machine Learning 파이프라인을 사용하여 모델을 학습시킵니다. 특히 파이프라인 개체 및 ParalleRunStep이 사용되며 ParallelRunConfig를 통해 설정된 특정 구성 매개 변수가 필요합니다.
다음 다이어그램에서는 많은 모델 솔루션의 워크플로를 보여줍니다.

다음 코드에서는 사용자가 많은 모델 실행을 설정하는 데 필요한 주요 매개 변수를 보여줍니다. 많은 모델 예측 예제는 많은 모델 - 자동화된 ML Notebook을 참조하세요.
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
계층적 시계열 예측
대부분의 애플리케이션에서 고객은 비즈니스의 거시적 및 미시적 수준에서 예측을 이해해야 합니다. 예측은 서로 다른 지리적 위치에서 제품의 판매를 예측하거나 회사의 여러 조직에 대한 예상 인력 수요를 이해하는 것일 수 있습니다. 계층 데이터에서 지능적으로 예측하도록 기계 학습 모델을 학습시키는 기능은 필수적입니다.
계층적 시계열은 각 고유 계열이 지리 또는 제품 유형과 같은 차원 기반 계층 구조로 정렬되는 구조입니다. 다음 예제에서는 계층 구조를 형성하는 고유한 특성이 있는 데이터를 보여줍니다. 여기서 계층 구조는 헤드폰 또는 태블릿과 같은 제품 유형, 제품 유형을 액세서리 및 디바이스로 구분하는 제품 범주, 제품이 판매되는 지역으로 정의됩니다.

이를 추가로 시각화하기 위해 계층의 리프 수준에는 특성 값이 고유하게 조합된 모든 시계열이 포함됩니다. 계층 구조의 각 상위 수준은 시계열을 정의하기 위해 더 작은 차원 하나를 고려하고 하위 수준의 각 자식 노드 집합을 부모 노드로 집계합니다.

계층적 시계열 솔루션은 다대다 모델 솔루션을 기반으로 하며 비슷한 구성 설정을 공유합니다.
다음 코드에서는 계층적 시계열 예측 실행을 설정하기 위한 주요 매개 변수를 보여줍니다. 엔드투엔드 예제는 계층적 시계열 - 자동화된 ML Notebook을 참조하세요.
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
예제 Notebook
다음을 포함하는 고급 예측 구성의 자세한 코드 예제는 예측 샘플 Notebook을 참조하세요.
다음 단계
- AutoML 모델을 온라인 엔드포인트에 배포하는 방법에 대해 자세히 알아봅니다.
- 해석력: 자동화된 Machine Learning의 모델 설명(미리 보기)에 대해 알아봅니다.
- AutoML이 예측 모델을 빌드하는 방법에 대해 알아봅니다.