Python으로 Computer Vision 모델을 학습시키도록 AutoML 설정(v1)
적용 대상: Python SDK azureml v1
Python SDK azureml v1
Important
이 문서의 일부 Azure CLI 명령에서는 azure-cli-ml 또는 v1(Azure Machine Learning용 확장)을 사용합니다. v1 확장에 대한 지원은 2025년 9월 30일에 종료됩니다. v1 확장은 이 날짜까지 설치하고 사용할 수 있습니다.
2025년 9월 30일 이전에 ml 또는 v2 확장으로 전환하는 것이 좋습니다. v2 확장에 대한 자세한 내용은 Azure ML CLI 확장 및 Python SDK v2를 참조하세요.
Important
이 기능은 현재 공개 미리 보기로 제공됩니다. 이 미리 보기 버전은 서비스 수준 계약 없이 제공됩니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
이 문서에서는 Azure Machine Learning Python SDK에서 자동화된 ML을 사용하여 이미지 데이터에 대한 Computer Vision 모델을 학습시키는 방법을 알아봅니다.
자동화된 ML은 이미지 분류, 개체 감지 및 인스턴스 분할과 같은 Computer Vision 작업에 대한 모델 학습을 지원합니다. Computer Vision 작업을 위한 AutoML 모델 작성은 현재 Azure Machine Learning Python SDK를 통해 지원됩니다. 결과 실험 실행, 모델 및 출력은 Azure Machine Learning 스튜디오 UI에서 액세스할 수 있습니다. 이미지 데이터에 대한 Computer Vision 작업을 위한 자동화된 ML에 대해 자세히 알아보기.
참고 항목
Computer Vision 작업을 위한 자동화된 ML은 Azure Machine Learning Python SDK를 통해서만 사용할 수 있습니다.
필수 조건
Azure Machine Learning 작업 영역 작업 영역을 만들려면 작업 영역 리소스 만들기를 참조하세요.
설치된 Azure Machine Learning Python SDK. SDK를 설치하려면 다음 중 하나를 수행할 수 있습니다.
SDK를 자동으로 설치하고 ML 워크플로에 대해 미리 구성된 컴퓨팅 인스턴스를 만듭니다. 자세한 내용은 Azure Machine Learning 컴퓨팅 인스턴스 만들기 및 관리를 참조하세요.
automl패키지를 직접 설치합니다. 여기에는 SDK의 기본 설치가 포함됩니다.
참고 항목
Python 3.7 및 3.8만 Computer Vision 작업에 대한 자동화된 ML 지원과 호환됩니다.
작업 종류 선택
이미지용 자동화된 ML은 다음 작업 종류를 지원합니다.
| 작업 유형 | AutoMLImage 구성 구문 |
|---|---|
| 이미지 분류 | ImageTask.IMAGE_CLASSIFICATION |
| 이미지 분류 다중 레이블 | ImageTask.IMAGE_CLASSIFICATION_MULTILABEL |
| 이미지 개체 감지 | ImageTask.IMAGE_OBJECT_DETECTION |
| 이미지 인스턴스 분할 | ImageTask.IMAGE_INSTANCE_SEGMENTATION |
이 작업 종류는 필수 매개 변수이며 AutoMLImageConfig에서 task 매개 변수를 사용하여 전달됩니다.
예시:
from azureml.train.automl import AutoMLImageConfig
from azureml.automl.core.shared.constants import ImageTask
automl_image_config = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION)
학습 및 유효성 검사 데이터
Computer Vision 모델을 생성하려면 레이블이 지정된 이미지 데이터를 Azure Machine Learning TabularDataset 형식으로 모델 학습을 위한 입력으로 가져와야 합니다. 데이터 레이블 지정 프로젝트에서 내보낸TabularDataset를 사용하거나 레이블이 지정된 학습 데이터로 새 TabularDataset를 만들 수 있습니다.
학습 데이터가 다른 형식(예: 파스칼 VOC 또는 COCO)인 경우 샘플 Notebooks에 포함된 도우미 스크립트를 적용하여 데이터를 JSONL로 변환할 수 있습니다. 자동화된 ML로 Computer Vision 작업을 위한 데이터를 준비하는 방법에 대해 자세히 알아봅니다.
Warning
이 기능의 경우 SDK를 사용하여 JSONL 형식의 데이터에서 TabularDatasets를 만드는 것만 지원됩니다. 현재 UI를 통한 데이터 세트 만들기는 지원되지 않습니다. 현재 UI는 JSONL 형식의 이미지 URL에 사용되는 데이터 형식인 StreamInfo 데이터 형식을 인식하지 못합니다.
참고 항목
AutoML 실행을 제출하려면 학습 데이터 세트에 10개 이상의 이미지가 있어야 합니다.
JSONL 스키마 샘플
TabularDataset의 구조는 현재 작업에 따라 다릅니다. Computer Vision 작업 종류의 경우 다음 필드로 구성됩니다.
| 필드 | 설명 |
|---|---|
image_url |
StreamInfo 개체로 파일 경로를 포함합니다. |
image_details |
이미지 메타데이터 정보는 높이, 너비, 형식으로 구성됩니다. 이 필드는 선택 사항이므로 존재할 수도 있고 없을 수도 있습니다. |
label |
작업 종류를 기반으로 하는 이미지 레이블의 json 표현입니다. |
다음은 이미지 분류를 위한 샘플 JSONL 파일입니다.
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "AmlDatastore://image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
다음 코드는 개체 감지를 위한 샘플 JSONL 파일입니다.
{
"image_url": "AmlDatastore://image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "AmlDatastore://image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
데이터 사용
데이터가 JSONL 형식이면 다음 코드를 사용하여 TabularDataset를 만들 수 있습니다.
ws = Workspace.from_config()
ds = ws.get_default_datastore()
from azureml.core import Dataset
training_dataset = Dataset.Tabular.from_json_lines_files(
path=ds.path('odFridgeObjects/odFridgeObjects.jsonl'),
set_column_types={'image_url': DataType.to_stream(ds.workspace)})
training_dataset = training_dataset.register(workspace=ws, name=training_dataset_name)
자동화된 ML은 Computer Vision 작업에 대한 학습 또는 유효성 검사 데이터 크기에 제약을 가하지 않습니다. 최대 데이터 세트 크기는 데이터 세트 뒤의 스토리지 계층(예: Blob 스토리지)에 의해서만 제한됩니다. 이미지나 레이블의 최소 개수는 없습니다. 그러나 출력 모델이 충분히 학습되도록 레이블당 최소 10-15개의 샘플로 시작하는 것이 좋습니다. 레이블/클래스의 총 수가 많을수록 레이블당 더 많은 샘플이 필요합니다.
학습 데이터는 필수이며 training_data 매개 변수를 사용하여 전달됩니다. AutoMLImageConfig의 validation_data 매개 변수를 사용하여 모델에 사용할 유효성 검사 데이터 세트로 다른 TabularDataset를 선택적으로 지정할 수 있습니다. 유효성 검사 데이터 세트가 지정되지 않은 경우 다른 값으로 validation_size 인수를 전달하지 않는 한 기본적으로 학습 데이터의 20%가 유효성 검사에 사용됩니다.
예시:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(training_data=training_dataset)
실험 실행 컴퓨팅
모델 학습을 수행하기 위해 자동화된 ML에 대한 컴퓨팅 대상을 제공합니다. Computer Vision 작업을 위한 자동화된 ML 모델에는 GPU SKU가 필요하고 NC 및 ND 제품군을 지원합니다. 더 빠른 학습을 위해 NCsv3 시리즈(v100 GPU 포함)를 권장합니다. 다중 GPU VM SKU가 있는 컴퓨팅 대상은 다중 GPU를 활용하여 학습 속도도 높입니다. 또한 여러 노드가 있는 컴퓨팅 대상을 설정하면 모델의 하이퍼 매개 변수를 튜닝할 때 병렬 처리를 통해 더 빠른 모델 학습을 수행할 수 있습니다.
참고 항목
컴퓨팅 인스턴스를 컴퓨팅 대상으로 사용하는 경우에는 여러 AutoML 작업이 동시에 실행되지 않는지 확인하세요. 또한 실험 리소스에서 max_concurrent_iterations이 1로 설정되어 있는지 확인하세요.
컴퓨팅 대상은 필수 매개 변수이며 AutoMLImageConfig의 compute_target 매개 변수를 사용하여 전달됩니다. 예시:
from azureml.train.automl import AutoMLImageConfig
automl_image_config = AutoMLImageConfig(compute_target=compute_target)
모델 알고리즘 및 하이퍼 매개 변수 구성
Computer Vision 작업을 지원하여 모델 알고리즘을 제어하고 하이퍼 매개 변수를 스윕할 수 있습니다. 이러한 모델 알고리즘과 하이퍼 매개 변수는 스윕을 위한 매개 변수 공간으로 전달됩니다.
모델 알고리즘은 필수이며 model_name 매개 변수를 통해 전달됩니다. 단일 model_name을 지정하거나 여러 개 중에서 선택할 수 있습니다.
지원되는 모델 알고리즘
다음 표에는 각 Computer Vision 작업에 대해 지원되는 모델이 요약되어 있습니다.
| 작업 | 모델 알고리즘 | 문자열 리터럴 구문default_model*은 *로 표시됨 |
|---|---|---|
| 이미지 분류 (다중 클래스 및 다중 레이블) |
MobileNet: 모바일 애플리케이션용 경량 모델 ResNet: Residual Network ResNeSt: Split Attention Network SE-ResNeXt50: Squeeze-and-Excitation Network ViT: 비전 변환기 네트워크 |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224(소형) vitb16r224*(기본) vitl16r224(대형) |
| 개체 감지 | YOLOv5: 1단계 개체 감지 모델 더 빠른 RCNN ResNet FPN: 2단계 개체 감지 모델 RetinaNet ResNet FPN: 초점 손실로 클래스 불균형 해결 참고: YOLOv5 모델 크기는 model_size하이퍼 매개 변수를 참조하세요. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| 인스턴스 구분 | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn maskrcnn_resnet50_fpn |
모델 알고리즘을 제어하는 것 외에도 모델 학습에 사용되는 하이퍼 매개 변수를 조정할 수도 있습니다. 노출된 많은 하이퍼 매개 변수가 모델에 구애받지 않지만 하이퍼 매개 변수가 작업별 또는 모델별인 경우가 있습니다. 이러한 인스턴스에 사용할 수 있는 하이퍼 매개 변수에 대해 자세히 알아봅니다.
데이터 증강
일반적으로 딥 러닝 모델 성능은 데이터가 많을수록 개선될 수 있습니다. 데이터 증강은 데이터 크기와 데이터 세트의 가변성을 증폭하는 실용적인 기술로, 과적합을 방지하고 보이지 않는 데이터에 대한 모델 일반화 기능을 개선시키는 데 도움이 됩니다. 자동화된 ML은 입력 이미지를 모델에 제공하기 전에 Computer Vision 작업을 기반으로 다양한 데이터 증강 기술을 적용합니다. 현재 데이터 증강을 제어하기 위해 노출된 하이퍼 매개 변수가 없습니다.
| 작업 | 영향을 받는 데이터 세트 | 데이터 증강 기법 적용 |
|---|---|---|
| 이미지 분류(다중 클래스 및 다중 레이블) | 교육 유효성 검사 및 테스트 |
임의 크기 조정 및 자르기, 수평 뒤집기, 색상 지터(밝기, 대비, 채도 및 색조), 채널별 ImageNet 평균 및 표준 편차를 사용한 정규화 크기 조정, 중앙 자르기, 정규화 |
| 개체 감지, 인스턴스 분할 | 교육 유효성 검사 및 테스트 |
경계 상자 주변의 임의 자르기, 확장, 수평 뒤집기, 정규화, 크기 조정 정규화, 크기 조정 |
| yolov5를 사용한 개체 감지 | 교육 유효성 검사 및 테스트 |
모자이크, 임의 아핀(회전, 이동, 스케일링, 전단), 수평 뒤집기 레터박스 크기 조정 |
실험 설정 구성
최적의 모델 및 하이퍼 매개 변수를 검색하기 위해 대규모 스윕을 수행하기 전에 첫 번째 기준선을 얻는 데 기본값을 시도하는 것이 좋습니다. 다음으로, 여러 모델과 해당 매개 변수를 스윕하기 전에 동일한 모델에 대한 여러 하이퍼 매개 변수를 탐색할 수 있습니다. 이렇게 하면 여러 모델과 각각에 대해 여러 하이퍼 매개 변수를 사용하면 검색 공간이 기하급수적으로 늘어나고 최적의 구성을 찾기 위해 더 많은 반복이 필요하기 때문에 보다 반복적인 접근 방식을 사용할 수 있습니다.
지정된 알고리즘(예: yolov5)에 대한 기본 하이퍼 매개 변수 값을 사용하려는 경우 다음과 같이 AutoML 이미지 실행에 대한 구성을 지정할 수 있습니다.
from azureml.train.automl import AutoMLImageConfig
from azureml.train.hyperdrive import GridParameterSampling, choice
from azureml.automl.core.shared.constants import ImageTask
automl_image_config_yolov5 = AutoMLImageConfig(task=ImageTask.IMAGE_OBJECT_DETECTION,
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
hyperparameter_sampling=GridParameterSampling({'model_name': choice('yolov5')}),
iterations=1)
기준 모델을 구축한 후에는 모델 알고리즘과 하이퍼 매개 변수 공간을 스윕하기 위해 모델 성능을 최적화할 수 있습니다. 다음 샘플 구성을 사용하여 각 알고리즘의 하이퍼 매개 변수를 스윕하고 learning_rate, optimizer, lr_scheduler 등의 값 범위에서 선택하여 최적의 기본 메트릭이 있는 모델을 생성할 수 있습니다. 하이퍼 매개 변수 값을 지정하지 않으면 지정된 알고리즘에 기본값이 사용됩니다.
기본 메트릭
모델 최적화 및 하이퍼 매개 변수 튜닝에 사용되는 기본 메트릭은 작업 종류에 따라 다릅니다. 다른 기본 메트릭 값을 사용하는 것은 현재 지원되지 않습니다.
accuracyIMAGE_CLASSIFICATION의 경우iouIMAGE_CLASSIFICATION_MULTILABEL의 경우mean_average_precisionIMAGE_OBJECT_DETECTION의 경우mean_average_precisionIMAGE_INSTANCE_SEGMENTATION의 경우
실험 예산
experiment_timeout_hours를 사용하여 AutoML Vision 실험의 최대 시간 예산을 선택적으로 지정할 수 있습니다. 이는 실험이 종료되기까지의 시간입니다. 지정되지 않은 경우 기본 실험 시간 제한은 7일(최대 60일)입니다.
모델의 하이퍼 매개 변수 스위핑
Computer Vision 모델을 학습할 때 모델 성능은 선택한 하이퍼 매개 변수 값에 크게 의존합니다. 종종 최적의 성능을 얻기 위해 하이퍼 매개 변수를 조정해야 할 수 있습니다. 자동화된 ML에서 Computer Vision 작업을 지원하므로 하이퍼 매개 변수를 스윕하여 모델에 대한 최적의 설정을 찾을 수 있습니다. 이 기능은 Azure Machine Learning의 하이퍼 매개 변수 튜닝 기능을 적용합니다. 하이퍼 매개 변수를 조정하는 방법 알아보기.
매개 변수 검색 공간 정의
모델 알고리즘과 하이퍼 매개 변수를 정의하여 매개 변수 공간에서 스윕할 수 있습니다.
- 각 작업 종류에 대해 지원되는 모델 알고리즘 목록은 모델 알고리즘 및 하이퍼 매개 변수 구성을 참조하세요.
- 각 컴퓨터 비전 작업 유형에 대해 컴퓨터 비전 작업에 대한 하이퍼 매개 변수 하이퍼 매개 변수를 참조하세요.
- 이산 및 연속 하이퍼 매개 변수에 대해 지원되는 분포에 대한 세부 정보를 참조하세요.
스윕을 위한 샘플링 방법
하이퍼 매개 변수를 스윕할 때 정의된 매개 변수 공간을 비우는 데 사용할 샘플링 방법을 지정해야 합니다. 현재 다음 샘플링 방법이 hyperparameter_sampling 매개 변수와 함께 지원됩니다.
참고 항목
현재 임의 및 그리드 샘플링만 조건부 하이퍼 매개 변수 공간을 지원합니다.
조기 종료 정책
조기 종료 정책을 사용하여 성능이 좋지 않은 실행을 자동으로 종료할 수 있습니다. 조기 종료는 컴퓨팅 효율성을 개선시켜 덜 유망한 구성에 소비되었을 컴퓨팅 리소스를 절약합니다. 이미지용 자동화된 ML은 early_termination_policy 매개 변수를 사용하여 다음과 같은 조기 종료 정책을 지원합니다. 종료 정책을 지정하지 않으면 모든 구성이 완료될 때까지 실행됩니다.
하이퍼 매개 변수 스윕에 대한 조기 종료 정책을 구성하는 방법에 대해 자세히 알아봅니다.
스윕을 위한 리소스
스윕에 대해 iterations 및 max_concurrent_iterations를 지정하여 하이퍼 매개 변수 스윕에 사용된 리소스를 제어할 수 있습니다.
| 매개 변수 | 세부 정보 |
|---|---|
iterations |
스윕할 최대 구성 수에 대한 필수 매개 변수입니다. 1~1000 사이의 정수여야 합니다. 주어진 모델 알고리즘에 대한 기본 하이퍼 매개 변수만 탐색할 때 이 매개 변수를 1로 설정합니다. |
max_concurrent_iterations |
동시에 실행할 수 있는 최대 실행 수입니다. 지정하지 않으면 모든 실행이 병렬로 시작됩니다. 지정한 경우 1~100 사이의 정수여야 합니다. 참고:동시 실행 수는 지정된 컴퓨팅 대상에서 사용할 수 있는 리소스에서 제어됩니다. 원하는 동시성에 사용할 수 있는 리소스가 컴퓨팅 대상에 있는지 확인합니다. |
참고 항목
전체 스윕 구성 샘플은 이 자습서를 참조하세요.
인수
매개 변수 공간 스윕 동안 변경되지 않는 고정 설정 또는 매개 변수를 인수로 전달할 수 있습니다. 인수는 이름-값 쌍으로 전달되며 이름 앞에 이중 대시가 있어야 합니다.
from azureml.train.automl import AutoMLImageConfig
arguments = ["--early_stopping", 1, "--evaluation_frequency", 2]
automl_image_config = AutoMLImageConfig(arguments=arguments)
증분 학습(선택 사항)
학습 실행이 완료되면 학습된 모델 검사점을 로드하여 모델을 추가로 학습시키는 옵션이 있습니다. 증분 학습에 동일한 데이터 세트 또는 다른 데이터 세트를 사용할 수 있습니다.
증분 학습에 사용할 수 있는 두 가지 옵션이 있습니다. 기능:
- 검사점을 로드할 실행 ID를 전달합니다.
- FileDataset를 통해 검사점을 전달합니다.
실행 ID를 통해 검사점 전달
원하는 모델에서 실행 ID를 찾으려면 다음 코드를 사용할 수 있습니다.
# find a run id to get a model checkpoint from
target_checkpoint_run = automl_image_run.get_best_child()
실행 ID를 통해 검사점을 전달하려면 checkpoint_run_id 매개 변수를 사용해야 합니다.
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_run_id= target_checkpoint_run.id,
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
FileDataset를 통해 검사점 전달
FileDataset를 통해 검사점을 전달하려면 checkpoint_dataset_id 및 checkpoint_filename 매개 변수를 사용해야 합니다.
# download the checkpoint from the previous run
model_name = "outputs/model.pt"
model_local = "checkpoints/model_yolo.pt"
target_checkpoint_run.download_file(name=model_name, output_file_path=model_local)
# upload the checkpoint to the blob store
ds.upload(src_dir="checkpoints", target_path='checkpoints')
# create a FileDatset for the checkpoint and register it with your workspace
ds_path = ds.path('checkpoints/model_yolo.pt')
checkpoint_yolo = Dataset.File.from_files(path=ds_path)
checkpoint_yolo = checkpoint_yolo.register(workspace=ws, name='yolo_checkpoint')
automl_image_config = AutoMLImageConfig(task='image-object-detection',
compute_target=compute_target,
training_data=training_dataset,
validation_data=validation_dataset,
checkpoint_dataset_id= checkpoint_yolo.id,
checkpoint_filename='model_yolo.pt',
primary_metric='mean_average_precision',
**tuning_settings)
automl_image_run = experiment.submit(automl_image_config)
automl_image_run.wait_for_completion(wait_post_processing=True)
실행 제출
AutoMLImageConfig 개체가 준비되면 실험을 제출할 수 있습니다.
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-image-object-detection")
automl_image_run = experiment.submit(automl_image_config)
출력 및 평가 메트릭
자동화된 ML 학습 실행은 하위 실행의 출력, 로그 및 메트릭 탭에서 볼 수 있는 채점 파일 및 환경 파일과 같은 출력 모델 파일, 평가 메트릭, 로그 및 배포 아티팩트를 생성합니다.
팁
실행 결과 보기 섹션에서 작업 결과로 이동하는 방법을 확인합니다.
각 실행에 대해 제공되는 성능 차트 및 메트릭의 정의와 예는 자동화된 Machine Learning 실험 결과 평가를 참조하세요.
모델 등록 및 배포
실행이 완료되면 최상의 실행에서 만들어진 모델을 등록할 수 있습니다(최상의 기본 메트릭이 만들어진 구성).
best_child_run = automl_image_run.get_best_child()
model_name = best_child_run.properties['model_name']
model = best_child_run.register_model(model_name = model_name, model_path='outputs/model.pt')
사용하려는 모델을 등록한 후 ACI(Azure Container Instances) 또는 AKS(Azure Kubernetes Service)에 웹 서비스로 배포할 수 있습니다. ACI는 배포를 테스트하는 데 가장 적합한 옵션이지만, AKS는 대규모 프로덕션 사용에 더 적합합니다.
이 예에서는 모델을 AKS에서 웹 서비스로 배포합니다. AKS에 배포하려면 먼저 AKS 컴퓨팅 클러스터를 만들거나 기존 AKS 클러스터를 사용합니다. 배포 클러스터에 GPU 또는 CPU VM SKU를 사용할 수 있습니다.
from azureml.core.compute import ComputeTarget, AksCompute
from azureml.exceptions import ComputeTargetException
# Choose a name for your cluster
aks_name = "cluster-aks-gpu"
# Check to see if the cluster already exists
try:
aks_target = ComputeTarget(workspace=ws, name=aks_name)
print('Found existing compute target')
except ComputeTargetException:
print('Creating a new compute target...')
# Provision AKS cluster with GPU machine
prov_config = AksCompute.provisioning_configuration(vm_size="STANDARD_NC6",
location="eastus2")
# Create the cluster
aks_target = ComputeTarget.create(workspace=ws,
name=aks_name,
provisioning_configuration=prov_config)
aks_target.wait_for_completion(show_output=True)
다음으로, 모델을 포함하는 웹 서비스를 설정하는 방법을 설명하는 유추 구성을 정의할 수 있습니다. 유추 구성에서 실행되는 학습의 채점 스크립트와 환경을 사용할 수 있습니다.
from azureml.core.model import InferenceConfig
best_child_run.download_file('outputs/scoring_file_v_1_0_0.py', output_file_path='score.py')
environment = best_child_run.get_environment()
inference_config = InferenceConfig(entry_script='score.py', environment=environment)
그런 다음, 모델을 AKS 웹 서비스로 배포할 수 있습니다.
# Deploy the model from the best run as an AKS web service
from azureml.core.webservice import AksWebservice
from azureml.core.webservice import Webservice
from azureml.core.model import Model
from azureml.core.environment import Environment
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
cpu_cores=1,
memory_gb=50,
enable_app_insights=True)
aks_service = Model.deploy(ws,
models=[model],
inference_config=inference_config,
deployment_config=aks_config,
deployment_target=aks_target,
name='automl-image-test',
overwrite=True)
aks_service.wait_for_deployment(show_output=True)
print(aks_service.state)
또는 Azure Machine Learning 스튜디오 UI에서 모델을 배포할 수 있습니다. 자동화된 ML 실행의 모델 탭에서 배포하려는 모델로 이동하고 배포를 선택합니다.
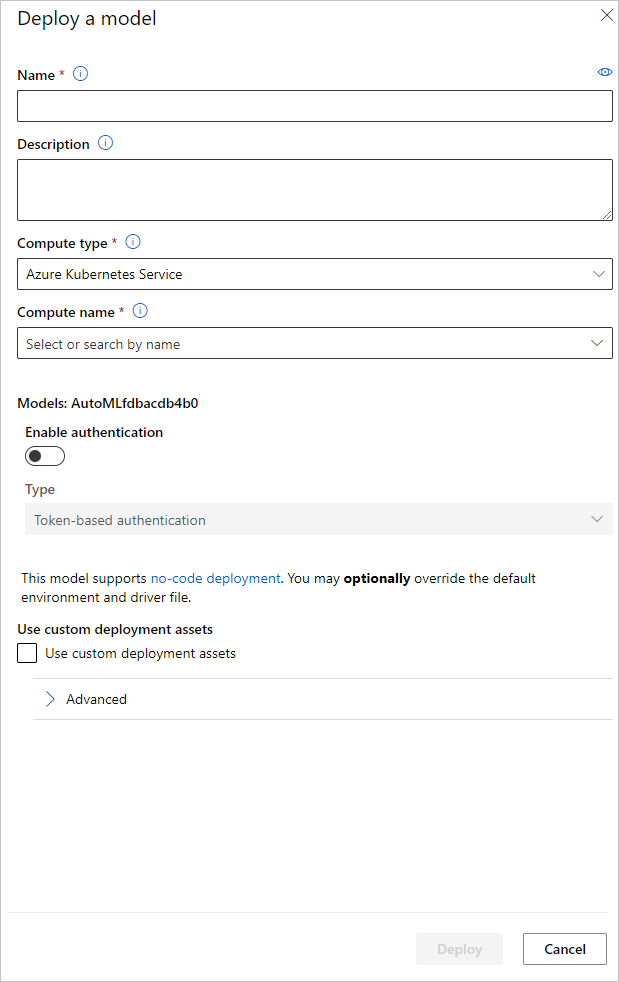
모델 배포 창에서 모델 배포에 사용할 모델 배포 엔드포인트 이름과 유추 클러스터를 구성할 수 있습니다.
유추 구성 업데이트
이전 단계에서 Microsoft는 최상의 모델에서 로컬 score.py 파일로 채점 파일 outputs/scoring_file_v_1_0_0.py를 다운로드하고 이를 사용하여 InferenceConfig 개체를 만들었습니다. 이 스크립트는 다운로드 후 InferenceConfig를 만들기 전에 필요한 경우 모델별 유추 설정을 변경하도록 수정할 수 있습니다. 예를 들어, 다음은 채점 파일에서 모델을 초기화하는 코드 섹션입니다.
...
def init():
...
try:
logger.info("Loading model from path: {}.".format(model_path))
model_settings = {...}
model = load_model(TASK_TYPE, model_path, **model_settings)
logger.info("Loading successful.")
except Exception as e:
logging_utilities.log_traceback(e, logger)
raise
...
각 작업(및 일부 모델)에는 model_settings 사전에 매개 변수 세트가 있습니다. 기본적으로 학습 및 유효성 검사 중에 사용된 매개 변수에 대해 동일한 값을 사용합니다. 유추를 위해 모델을 사용할 때 필요한 동작에 따라 이러한 매개 변수를 변경할 수 있습니다. 아래에서 각 작업 종류 및 모델에 대한 매개 변수 목록을 찾을 수 있습니다.
| 작업 | 매개 변수 이름 | 기본값 |
|---|---|---|
| 이미지 분류(다중 클래스 및 다중 레이블) | valid_resize_sizevalid_crop_size |
256 224 |
| 개체 감지 | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0.3 0.5 100 |
yolov5를 사용한 개체 감지 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 보통 0.1 0.5 |
| 인스턴스 구분 | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0.3 0.5 100 0.5 100 False JPG |
작업별 하이퍼 매개 변수에 대한 자세한 설명은 자동화된 Machine Learning의 컴퓨터 비전 작업에 대한 하이퍼 매개 변수를 참조하세요.
타일링을 사용하고 타일링 동작을 제어하려는 경우 tile_grid_size, tile_overlap_ratio 및 tile_predictions_nms_thresh 매개 변수를 사용할 수 있습니다. 이러한 매개 변수에 대한 자세한 내용은 AutoML을 사용하여 작은 개체 감지 모델 학습을 참조하세요.
예제 Notebook
자동화된 기계 학습 샘플에 대한 GitHub Notebook 리포지토리에서 자세한 코드 예제 및 사용 사례를 검토합니다. 컴퓨터 비전 모델 빌드와 관련된 샘플은 'image-' 접두사가 있는 폴더를 확인하세요.