데이터 수집 파이프라인에 대한 DevOps
대부분의 시나리오에서 데이터 수집 솔루션은 스크립트, 서비스 호출 및 모든 활동을 오케스트레이션하는 파이프라인으로 구성됩니다. 이 문서에서는 기계 학습 모델을 학습시키는 데 사용할 데이터를 준비하는 일반적인 데이터 수집 파이프라인의 개발 수명 주기에 DevOps 사례를 적용하는 방법을 알아봅니다. 파이프라인은 다음과 같은 Azure 서비스를 사용하여 빌드됩니다.
- Azure Data Factory:: 원시 데이터를 읽고 데이터 준비를 오케스트레이션합니다.
- Azure Databricks: 데이터를 변환하는 Python Notebook을 실행합니다.
- Azure Pipelines: 연속 통합 및 개발 프로세스를 자동화합니다.
데이터 수집 파이프라인 워크플로
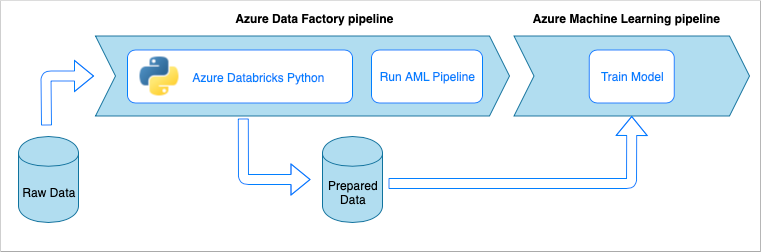
데이터 수집 파이프라인은 다음과 같은 워크플로를 구현합니다.
- 원시 데이터를 ADF(Azure Data Factory) 파이프라인으로 읽어 들입니다.
- ADF 파이프라인에서 데이터를 Azure Databricks 클러스터로 보내고, 이 클러스터는 Python Notebook을 실행하여 데이터를 변환합니다.
- 데이터가 Blob 컨테이너에 저장되고, Azure Machine Learning은 이 데이터를 모델 학습에 사용할 수 있습니다.
연속 통합 및 지속적인 업데이트 개요
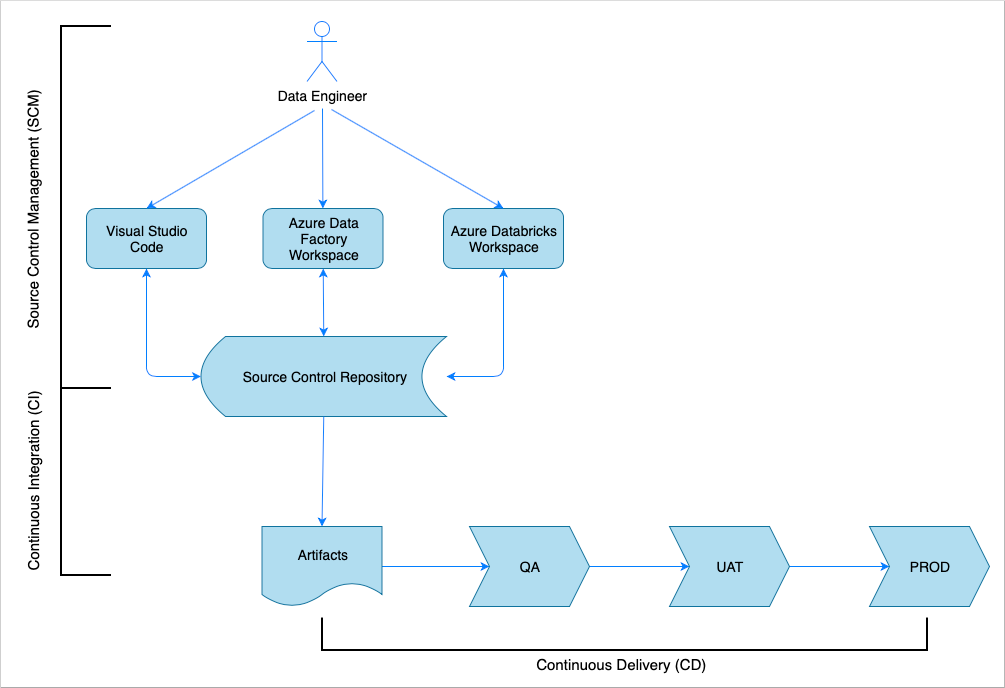
많은 소프트웨어 솔루션이 그렇듯이, 솔루션을 작업하는 팀(예: 데이터 엔지니어)이 있습니다. 이들은 Azure Data Factory, Azure Databricks, Azure Storage 계정 등의 동일한 Azure 리소스를 협업하고 공유합니다. 이러한 리소스가 모인 것이 개발 환경입니다. 데이터 엔지니어들은 동일한 소스 코드 베이스에 기여합니다.
연속 통합 및 지속적인 업데이트 시스템은 솔루션을 빌드, 테스트 및 제공(배포)하는 프로세스를 자동화합니다. CI(연속 통합) 프로세스에서는 다음과 같은 작업이 수행됩니다.
- 코드 어셈블
- 코드 품질 테스트
- 단위 테스트
- 테스트를 거친 코드 및 Azure Resource Manager 템플릿과 같은 아티팩트 생성
CD(지속적인 업데이트) 프로세스에서는 아티팩트를 다운스트림 환경에 배포합니다.
이 문서에서는 Azure Pipelines를 사용하여 CI 및 CD 프로세스를 자동화하는 방법을 보여줍니다.
소스 제어 관리
소스 제어 관리는 변경 내용을 추적하고 팀원 간 협업을 지원하는 데 필요합니다. 예를 들어 코드는 Azure DevOps, GitHub 또는 GitLab 리포지토리에 저장됩니다. 협업 워크플로는 분기 모델을 기반으로 합니다.
Python Notebook 소스 코드
데이터 엔지니어는 IDE(예: Visual Studio Code)에서 로컬로 또는 Databricks 작업 영역에서 직접 Python Notebook 소스 코드를 작업합니다. 변경이 완료된 코드는 분기 정책을 따라 리포지토리에 병합됩니다.
팁
.ipynb Jupyter Notebook 형식이 아닌 .py 파일에 코드를 저장하는 것이 좋습니다. 이렇게 하면 코드 가독성이 향상되고 CI 프로세스에서 코드 품질 검사가 자동화됩니다.
Azure Data Factory 소스 코드
Azure Data Factory 파이프라인의 소스 코드는 Azure Data Factory 작업 영역에서 생성되는 JSON 파일의 컬렉션입니다. 일반적으로 데이터 엔지니어는 소스 코드 파일을 직접 작업하는 대신 Azure Data Factory 작업 영역에서 비주얼 디자이너로 작업합니다.
소스 제어 리포지토리를 사용하도록 작업 영역을 구성하려면 Azure Repos Git 통합을 통한 작성을 참조하세요.
CI(연속 통합)
연속 통합 프로세스의 궁극적인 목표는 소스 코드에서 공동 팀 작업을 수집하고 다운스트림 환경에 배포할 수 있도록 준비하는 것입니다. 소스 코드 관리와 마찬가지로 이 프로세스는 Python Notebook 파이프라인과 Azure Data Factory 파이프라인에서 서로 다릅니다.
Python Notebook CI
Python Notebook의 CI 프로세스는 협업 분기(예: master 또는 develop)에서 코드를 가져오며 다음 작업을 수행합니다.
- 코드 린팅
- 단위 테스트
- 코드를 아티팩트로 저장
다음 코드 조각은 Azure DevOps yaml 파이프라인에서 이러한 단계를 구현하는 방법을 보여줍니다.
steps:
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
- publish: $(Build.SourcesDirectory)
artifact: di-notebooks
이 파이프라인에서는 Python 코드 린팅에 flake8을 사용합니다. 소스 코드에 정의된 단위 테스트를 실행하고 Azure Pipelines 실행 화면에서 사용할 수 있도록 린팅 및 테스트 결과를 게시합니다.
린팅 및 단위 테스트가 성공하면 파이프라인에서는 후속 배포 단계에 사용할 수 있도록 소스 코드를 아티팩트 리포지토리에 복사합니다.
Azure Data Factory CI
Azure Data Factory 파이프라인의 CI 프로세스는 데이터 수집 파이프라인에는 병목 상태입니다. 연속 통합은 없습니다. Azure Data Factory에 대한 배포 가능한 아티팩트는 Azure Resource Manager 템플릿의 컬렉션입니다. 이러한 템플릿을 생성하는 유일한 방법은 Azure Data Factory 작업 영역에서 게시 단추를 클릭하는 것입니다.
- 데이터 엔지니어가 기능 분기의 소스 코드를 협업 분기에 병합합니다(예: master 또는 develop).
- 권한이 부여된 사용자가 게시 단추를 클릭하여 소스 코드의 Azure Resource Manager 템플릿을 협업 분기에 생성합니다.
- 작업 영역에서 파이프라인의 유효성을 검사(린팅 및 단위 테스트)하고, Azure Resource Manager 템플릿을 생성(빌드)하고, 생성된 템플릿을 동일한 코드 리포지토리의 기술 분기 adf_publish에 저장(아티팩트 게시)합니다. 이 분기는 Azure Data Factory 작업 영역에서 자동으로 생성합니다.
이 프로세스에 대한 자세한 내용은 Azure Data Factory의 연속 통합 및 지속적인 업데이트를 참조하세요.
생성된 Azure Resource Manager 템플릿이 환경의 제약을 받지 않아야 합니다. 즉, 환경에 따라 달라질 수 있는 모든 값이 매개 변수화됩니다. Azure Data Factory는 이러한 값을 대부분 매개 변수로 노출합니다. 예를 들어 다음 템플릿에서는 Azure Machine Learning 작업 영역에 대한 연결 속성이 매개 변수로 노출됩니다.
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
"AzureMLService_servicePrincipalKey": {
"value": ""
},
"AzureMLService_properties_typeProperties_subscriptionId": {
"value": "0fe1c235-5cfa-4152-17d7-5dff45a8d4ba"
},
"AzureMLService_properties_typeProperties_resourceGroupName": {
"value": "devops-ds-rg"
},
"AzureMLService_properties_typeProperties_servicePrincipalId": {
"value": "6e35e589-3b22-4edb-89d0-2ab7fc08d488"
},
"AzureMLService_properties_typeProperties_tenant": {
"value": "72f988bf-86f1-41af-912b-2d7cd611db47"
}
}
}
그러나 기본적으로 Azure Data Factory 작업 영역에서 처리하지 않는 사용자 지정 속성을 노출하려는 경우가 있습니다. 이 문서의 시나리오에서 Azure Data Factory 파이프라인은 데이터를 처리하는 Python Notebook을 호출합니다. Notebook은 입력 데이터 파일의 이름을 사용하는 매개 변수를 허용합니다.
import pandas as pd
import numpy as np
data_file_name = getArgument("data_file_name")
data = pd.read_csv(data_file_name)
labels = np.array(data['target'])
...
이 이름은 Dev, QA, UAT 및 PROD 환경에서 서로 다릅니다. 여러 작업이 있는 복잡한 파이프라인에는 여러 사용자 지정 속성이 있을 수 있습니다. 다음과 같이 모든 값을 한 장소에 모으고 파이프라인 변수로 정의하는 것이 좋습니다.
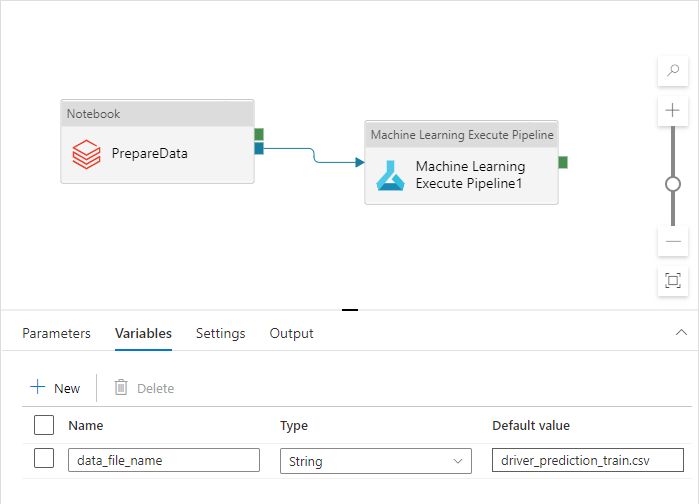
파이프라인 변수를 실제로 사용하는 동안 파이프라인 활동은 파이프라인 변수를 참조할 수 있습니다.
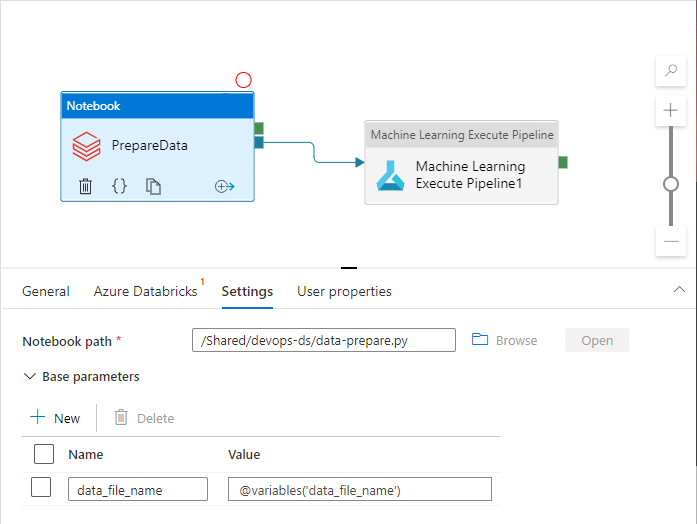
Azure Data Factory 작업 영역은 기본적으로 파이프라인 변수를 Azure Resource Manager 템플릿 매개 변수로 노출하지 않습니다. 작업 영역에서는 기본 매개 변수화 템플릿을 사용하여 Azure Resource Manager 템플릿 매개 변수로 노출해야 하는 파이프라인 속성을 지시합니다. 목록에 파이프라인 변수를 추가하려면 기본 매개 변수화 템플릿의 "Microsoft.DataFactory/factories/pipelines" 섹션을 다음 코드 조각으로 업데이트하고 그 결과로 얻은 json 파일을 원본 폴더의 루트에 배치합니다.
"Microsoft.DataFactory/factories/pipelines": {
"properties": {
"variables": {
"*": {
"defaultValue": "="
}
}
}
}
이렇게 하면 게시 단추를 클릭할 때 Azure Data Factory 작업 영역이 매개 변수 목록에 변수를 추가하게 됩니다.
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
...
"data-ingestion-pipeline_properties_variables_data_file_name_defaultValue": {
"value": "driver_prediction_train.csv"
}
}
}
JSON 파일의 값은 파이프라인 정의에 구성된 기본값입니다. 이러한 값은 Azure Resource Manager 템플릿이 배포될 때 대상 환경 값으로 재정의되어야 합니다.
CD(지속적인 업데이트)
지속적인 업데이트 프로세스는 아티팩트를 가져와서 첫 번째 대상 환경에 배포합니다. 테스트를 실행하여 솔루션이 작동하는지 확인합니다. 테스트가 성공하면 다음 환경을 계속 진행합니다.
CD Azure Pipelines는 환경을 나타내는 여러 스테이지로 구성됩니다. 각 스테이지에는 다음 단계를 수행하는 배포 및 작업이 포함됩니다.
- Azure Databricks 작업 영역에 Python Notebook 배포
- Azure Data Factory 파이프라인 배포
- 파이프라인 실행
- 데이터 수집 결과 확인
파이프라인 스테이지는 환경 체인을 거치면서 배포 프로세스가 진화하는 방식에 대한 추가 제어를 제공하는 승인 및 게이트를 통해 구성할 수 있습니다.
Python Notebook 배포
다음 코드 조각은 Python Notebook을 Databricks 클러스터에 복사하는 Azure Pipeline 배포를 정의합니다.
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
CI에서 생성된 아티팩트는 배포 에이전트에 자동으로 복사되며 $(Pipeline.Workspace) 폴더에 있습니다. 이 경우 배포 작업은 Python Notebook을 포함하고 있는 di-notebooks 아티팩트를 참조합니다. 이 배포에서는 Databricks Azure DevOps 확장을 사용하여 Notebook 파일을 Databricks 작업 영역에 복사합니다.
Deploy_to_QA 스테이지에는 Azure DevOps 프로젝트에 정의된 변수 그룹 devops-ds-qa-vg에 대한 참조가 포함됩니다. 이 스테이지의 단계는 이 변수 그룹의 변수(예: $(DATABRICKS_URL) 및 $(DATABRICKS_TOKEN))를 참조합니다. 다음 스테이지(예: Deploy_to_UAT)가 자체 UAT 범위 변수 그룹에 정의된 동일한 변수 이름을 사용하여 작동하기 때문입니다.
Azure Data Factory 파이프라인 배포
Azure Data Factory에 대한 배포 가능한 아티팩트는 Azure Resource Manager 템플릿입니다. 이 아티팩트는 다음 코드 조각에 나와 있는 것처럼 Azure 리소스 그룹 배포 작업을 통해 배포될 예정입니다.
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
데이터 파일 이름 매개 변수 값은 QA 스테이지 변수 그룹에 정의된 $(DATA_FILE_NAME) 변수에서 가져옵니다. 마찬가지로 ARMTemplateForFactory.json에 정의된 모든 매개 변수를 재정의할 수 있습니다. 이러한 값이 없으면 기본값이 사용됩니다.
파이프라인을 실행하고 데이터 수집 결과 확인
다음 단계는 배포된 솔루션이 작동하는지 확인하는 것입니다. 다음 작업 정의는 PowerShell 스크립트를 사용하여 Azure Data Factory 파이프라인을 실행하고 Azure Databricks 클러스터에서 Python Notebook을 실행합니다. Notebook은 데이터가 올바르게 수집되었는지 확인하고 이름이 $(bin_FILE_NAME)인 결과 데이터 파일의 유효성을 검사합니다.
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'
작업의 최종 태스크에서는 Notebook 실행 결과를 확인합니다. 오류를 반환하는 경우 파이프라인 실행 상태를 실패로 설정합니다.
종합
전체 CI/CD Azure 파이프라인은 다음 스테이지로 구성됩니다.
- CI
- QA에 배포
- Databricks에 배포 + ADF에 배포
- 통합 테스트
보유하고 있는 대상 환경의 수와 동일한 수의 배포 스테이지가 포함됩니다. 각 배포 스테이지에는 동시에 실행되는 배포 2개와 환경에서 솔루션을 테스트하기 위해 배포 후에 실행되는 작업 하나가 포함됩니다.
파이프라인 구현 샘플은 다음 yaml 코드 조각에서 어셈블됩니다.
variables:
- group: devops-ds-vg
stages:
- stage: 'CI'
displayName: 'CI'
jobs:
- job: "CI_Job"
displayName: "CI Job"
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- script: pip install --upgrade flake8 flake8_formatter_junit_xml
displayName: 'Install flake8'
- checkout: self
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
# The CI stage produces two artifacts (notebooks and ADF pipelines).
# The pipelines Azure Resource Manager templates are stored in a technical branch "adf_publish"
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/code/dataingestion
artifact: di-notebooks
- checkout: git://${{variables['System.TeamProject']}}@adf_publish
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/devops-ds-adf
artifact: adf-pipelines
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'