Azure Machine Learning을 활용하면 로컬 컴퓨터의 파일이나 폴더, 클라우드 스토리지, Azure Machine Learning 데이터 자산, Git 리포지토리, SQL 데이터베이스 등 다양한 소스에서 벡터 인덱스를 생성할 수 있습니다. Azure Machine Learning은 다양한 문서, 코드 및 프레젠테이션 파일 형식을 처리할 수 있습니다. 전체 목록은 지원되는 파일 형식을 참조하세요. 새로운 인덱스를 생성할 필요 없이, 기존에 사용하던 Azure AI 검색(이전 명칭 Cognitive Search) 인덱스를 그대로 활용하는 것도 가능합니다.
벡터 인덱스를 생성하면 Azure Machine Learning이 데이터를 자동으로 분할하고 임베딩을 추출한 뒤, 이를 Faiss 또는 Azure AI 검색 인덱스에 저장합니다. 또한, Azure Machine Learning은 다음과 같은 결과물을 생성합니다.
원본 데이터에 대한 테스트를 수행합니다.
생성된 벡터 인덱스를 활용한 샘플 프롬프트 실행 흐름입니다. 이 샘플 프롬프트 흐름은 다음과 같은 기능들을 제공합니다.
- 이것은 자동 생성된 프롬프트의 변형 버전입니다.
- 각 프롬프트 변형의 성능은 생성된 테스트 데이터를 활용하여 평가됩니다.
- 각 프롬프트 변형에 대한 메트릭을 통해 실행하기에 가장 적합한 변형을 선택할 수 있습니다.
이 샘플을 기반으로 프롬프트 개발을 진행할 수 있습니다.
중요합니다
이 기능은 현재 공개 미리 보기로 제공됩니다. 이 미리 보기 버전은 서비스 수준 계약 없이 제공되며, 프로덕션 워크로드에는 권장되지 않습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다.
자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
사전 준비 사항
Azure 구독 Azure 구독이 아직 없는 경우 체험 계정을 생성합니다.
Microsoft Foundry 모델에서 Azure OpenAI에 액세스합니다.
이제 Azure Machine Learning 작업 영역에서 프롬프트 흐름 기능을 자유롭게 활용하실 수 있습니다. 프롬프트 흐름을 사용하려면 미리 보기 기능 관리 패널에서 프롬프트 흐름으로 AI 솔루션 빌드 옵션을 활성화하면 됩니다.
Machine Learning 스튜디오를 활용한 벡터 인덱스 생성
왼쪽 메뉴에서 프롬프트 흐름 을 선택하세요.
벡터 인덱스 탭을 선택합니다.
만들기를 실행합니다.
벡터 인덱스 생성 대화창이 나타나면 벡터 인덱스의 이름을 입력하세요.
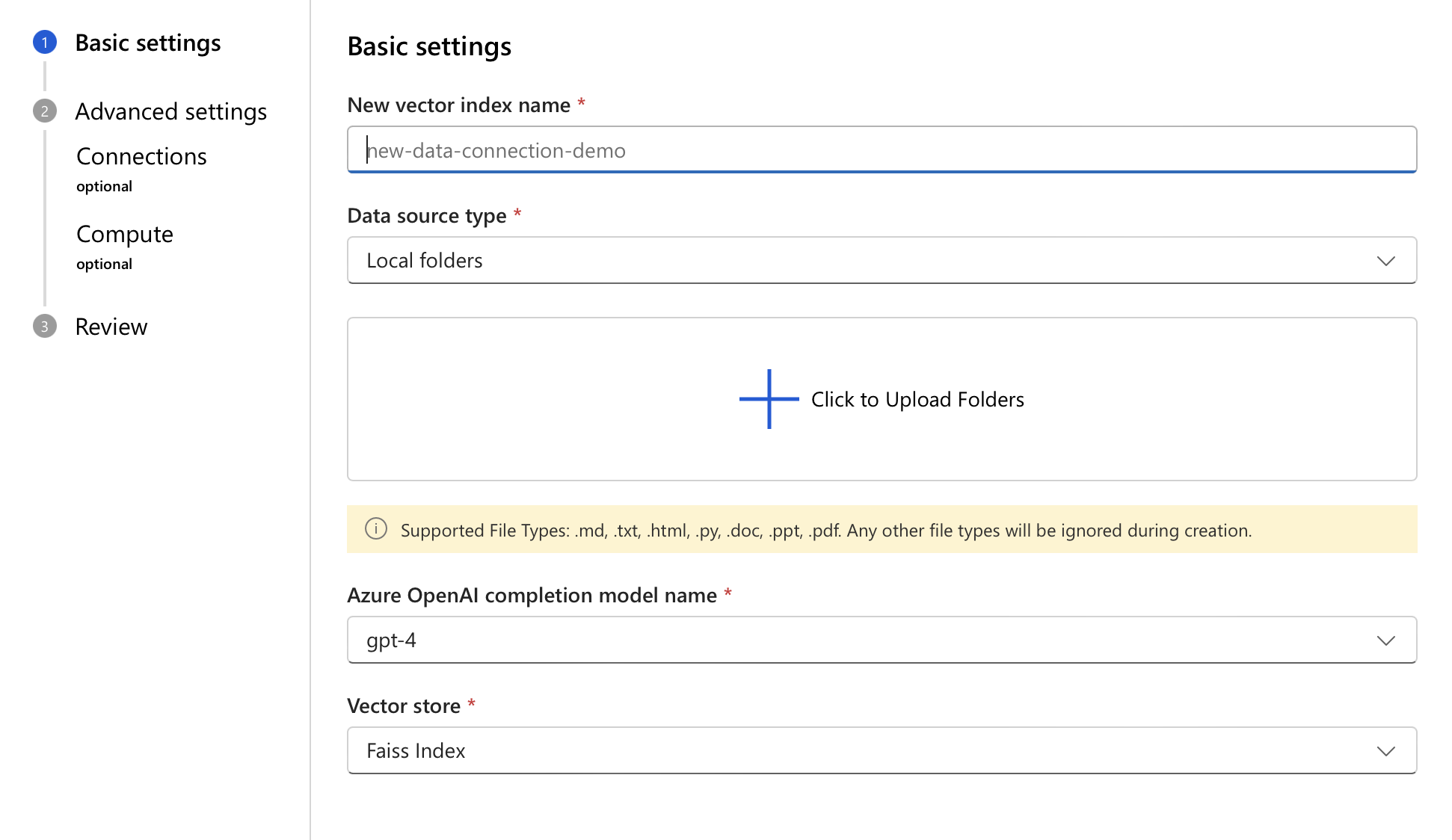
중요합니다
Azure AI 검색에 인덱스를 저장하는 경우 인덱스 이름은 Azure AI 검색 명명 규칙(2~128자, 소문자, 숫자, 하이픈() 및 밑줄(
-_)만 준수해야 합니다. 첫 번째 문자는 문자 또는 숫자여야 하며 연속 하이픈이나 밑줄은 없어야 합니다. 이러한 규칙을 위반하는 이름은 최종 인덱싱 단계에서 작업이 실패하게 하며, 이는 긴 처리 실행 후에 발생할 수 있습니다.데이터 원본 유형을 선택합니다.
선택된 형식에 맞춰 원본의 위치 정보를 자세히 제공합니다. 그다음에 다음을 선택합니다.
벡터 인덱스의 세부 정보를 확인한 후 만들기 버튼을 클릭합니다.
표시되는 개요 페이지에서 벡터 인덱스 생성의 진행 상태를 추적하고 확인할 수 있습니다. 데이터 크기가 클수록 처리 시간이 더 오래 소요될 수 있습니다.
프롬프트 흐름에 벡터 인덱스 추가
벡터 인덱스를 생성한 후 프롬프트 흐름 캔버스에서 이를 프롬프트 흐름에 통합할 수 있습니다.
기존 프롬프트 흐름을 엽니다.
프롬프트 플로우 디자이너 상단 메뉴의 도구 더 보기를 클릭한 후, 목록에서 인덱스 조회항목을 선택해 주세요.
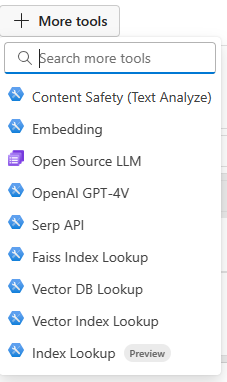
캔버스에 인덱스 조회 도구가 추가됩니다. 도구가 보이지 않으면 캔버스 하단으로 스크롤하세요.
벡터 인덱스의 이름을 지정하세요.
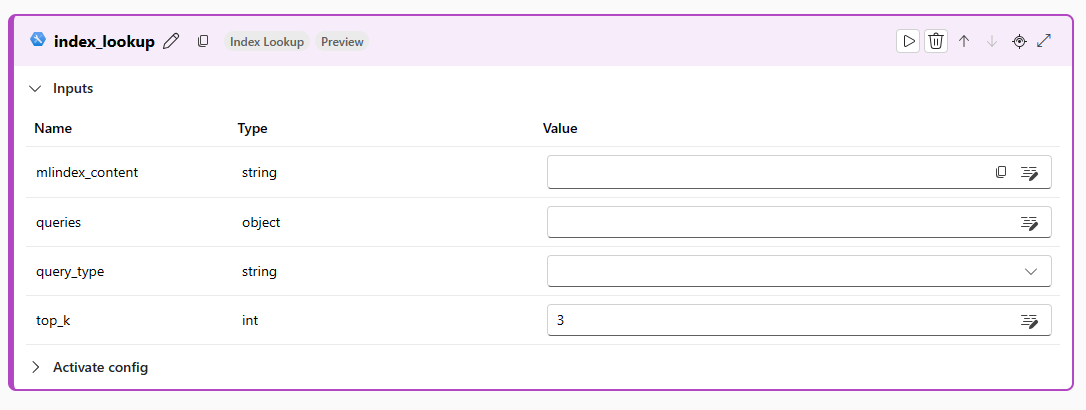
mlindex_content 값 상자를 선택하고 인덱스를 선택합니다. 이 도구는 튜토리얼의 ‘벡터 인덱스 생성’ 섹션에서 구축한 인덱스를 참조하여 검색을 수행해야 합니다. 필요한 모든 정보를 입력한 후 저장을 클릭하면 서랍 생성이 닫힙니다.
쿼리와 인덱스에 대해 실행할 query_types를 지정합니다.
해당 항목에 입력 가능한 일반 문자열의 예시로는
How to use SDK V2?'. Here is an example of an embedding as an input:${embed_the_question.output}`을 들 수 있습니다. 일반 문자열을 전달하는 방식은 벡터 인덱스를 생성한 동일한 작업 영역에서만 해당 벡터 인덱스를 사용할 때 작동합니다.
지원되는 파일 형식
벡터 인덱싱을 위해 지원하는 파일 형식: .txt, .md, .html, .htm, .py, .pdf, .ppt, .pptx, .doc, .docx, .xls, .xlsx. 다른 파일 형식은 만드는 동안 무시됩니다.
다음 단계
- 프롬프트 흐름 샘플(미리 보기)을 사용하여 RAG 시작 - 코드 없는 구성 요소를 사용하여 RAG 파이프라인을 빌드합니다.
- Azure Machine Learning(미리 보기)에서 벡터 저장소 사용 - 벡터 저장소 옵션으로 Azure AI 검색 및 Faiss에 대해 알아봅니다.