기계 학습 파이프라인 문제 해결
적용 대상: Python SDK azureml v1
Python SDK azureml v1
이 문서에서는 Azure Machine Learning SDK 및 Azure Machine Learning 디자이너에서 기계 학습 파이프라인 실행 중 오류가 발생하는 경우 문제를 해결하는 방법에 대해 알아봅니다.
문제 해결 팁
다음 표에는 파이프라인 개발 중에 발생하는 일반적인 문제와 이를 해결할 수 있는 잠재적인 솔루션이 나와 있습니다.
| 문제 | 가능한 솔루션 |
|---|---|
PipelineData 디렉터리로 데이터를 전달할 수 없음 |
파이프라인이 단계 출력 데이터를 예상하는 위치에 해당하는 디렉터리를 스크립트에 만들었는지 확인합니다. 대부분의 경우 입력 인수는 출력 디렉터리를 정의한 다음 디렉터리를 명시적으로 만듭니다. os.makedirs(args.output_dir, exist_ok=True)를 사용하여 출력 디렉터리를 만듭니다. 이 디자인 패턴을 보여 주는 점수 매기기 스크립트 예에 대한 자습서를 참조하세요. |
| 종속성 버그 | 로컬로 테스트할 때 발생하지 않은 종속성 오류가 원격 파이프라인에 표시되는 경우 원격 환경의 종속성 및 버전이 테스트 환경과 일치하는지 확인합니다. 환경 빌드, 캐싱, 재사용을 참조하세요. |
| 컴퓨팅 대상에서 모호한 오류가 발생 | 컴퓨팅 대상을 삭제하고 다시 만들어 보세요. 컴퓨팅 대상을 다시 만드는 과정은 빠르게 수행할 수 있으며 일부 일시적인 문제를 해결할 수 있습니다. |
| 파이프라인이 단계를 다시 사용하지 않음 | 단계 다시 사용은 기본적으로 사용 설정되어 있지만, 파이프라인 단계에서 이를 사용하지 않도록 설정하지 않았는지 확인합니다. 재사용이 사용하지 않도록 설정된 경우 단계의 allow_reuse 매개 변수는 False로 설정됩니다. |
| 파이프라인이 불필요하게 다시 실행됨 | 기본 데이터 또는 스크립트가 변경될 때만 단계가 다시 실행되도록 하려면 각 단계에 대한 소스 코드 디렉터리를 분리합니다. 여러 단계에 동일한 원본 디렉터리를 사용하는 경우 단계가 불필요하게 다시 실행될 수 있습니다. 파이프라인 단계 개체에서 source_directory 매개 변수를 사용하여 해당 단계에 대한 격리된 디렉터리를 가리키고, 여러 단계에 대해 동일한 source_directory 경로를 사용하고 있지 않은지 확인합니다. |
| 학습 epoch 또는 기타 반복 동작에서 단계의 속도가 저하됨 | 로깅을 비롯한 파일 쓰기를 as_mount()에서 as_upload()로 전환해 보세요. 탑재 모드는 원격 가상화된 파일 시스템을 사용하며 파일이 추가될 때마다 전체 파일을 업로드합니다. |
| 컴퓨팅 대상을 시작하는 데 오래 걸림 | 컴퓨팅 대상에 대한 Docker 이미지는 Azure Container Registry(ACR)에서 로드됩니다. 기본적으로 Azure Machine Learning은 기본 서비스 계층을 사용하는 ACR을 만듭니다. 작업 영역에 대한 ACR을 표준 또는 프리미엄 계층으로 변경하면 이미지를 빌드하고 로드하는 데 걸리는 시간을 줄일 수 있습니다. 자세한 내용은 Azure Container Registry 서비스 계층을 참조하세요. |
인증 오류
원격 작업에서 컴퓨팅 대상에 대한 관리 작업을 수행하는 경우 다음 오류 중 하나가 나타납니다.
{"code":"Unauthorized","statusCode":401,"message":"Unauthorized","details":[{"code":"InvalidOrExpiredToken","message":"The request token was either invalid or expired. Please try again with a valid token."}]}
{"error":{"code":"AuthenticationFailed","message":"Authentication failed."}}
예를 들어, 원격 실행을 위해 제출된 ML 파이프라인에서 컴퓨팅 대상을 만들거나 연결하려고 시도하면 오류가 나타납니다.
ParallelRunStep 문제 해결
ParallelRunStep에 대한 스크립트에는 다음 두 함수가 포함되어야 합니다.
init(): 이후 유추를 위해 비용이 많이 드는 준비 또는 일반적인 준비에 이 함수를 사용합니다. 예를 들어 모델을 글로벌 개체에 로드하는 데 사용합니다. 이 함수는 프로세스 시작 시 한 번만 호출됩니다.run(mini_batch): 함수는 각mini_batch인스턴스에 대해 실행됩니다.mini_batch:ParallelRunStep는 run 메서드를 호출하고 목록 또는 PandasDataFrame을 메서드에 대한 인수로 전달합니다. mini_batch의 각 항목은 입력이FileDataset인 경우 파일 경로이고, 입력이TabularDataset인 경우 PandasDataFrame입니다.response: run() 메서드는 PandasDataFrame또는 배열을 반환해야 합니다. append_row output_action의 경우 반환되는 요소가 공통 출력 파일에 추가됩니다. summary_only의 경우 요소의 내용이 무시됩니다. 모든 출력 작업의 경우 반환되는 각 출력 요소는 입력 미니 일괄 처리의 입력 요소에 대한 성공적인 실행 하나를 나타냅니다. 입력을 실행 출력 결과에 매핑하기에 충분한 데이터가 실행 결과에 포함되어 있는지 확인합니다. 실행 출력은 출력 파일에 기록되지만 순서대로 기록된다는 보장은 없으므로, 사용자는 출력의 키를 사용하여 입력에 매핑해야 합니다.
%%writefile digit_identification.py
# Snippets from a sample script.
# Refer to the accompanying digit_identification.py
# (https://github.com/Azure/MachineLearningNotebooks/tree/master/how-to-use-azureml/machine-learning-pipelines/parallel-run)
# for the implementation script.
import os
import numpy as np
import tensorflow as tf
from PIL import Image
from azureml.core import Model
def init():
global g_tf_sess
# Pull down the model from the workspace
model_path = Model.get_model_path("mnist")
# Construct a graph to execute
tf.reset_default_graph()
saver = tf.train.import_meta_graph(os.path.join(model_path, 'mnist-tf.model.meta'))
g_tf_sess = tf.Session()
saver.restore(g_tf_sess, os.path.join(model_path, 'mnist-tf.model'))
def run(mini_batch):
print(f'run method start: {__file__}, run({mini_batch})')
resultList = []
in_tensor = g_tf_sess.graph.get_tensor_by_name("network/X:0")
output = g_tf_sess.graph.get_tensor_by_name("network/output/MatMul:0")
for image in mini_batch:
# Prepare each image
data = Image.open(image)
np_im = np.array(data).reshape((1, 784))
# Perform inference
inference_result = output.eval(feed_dict={in_tensor: np_im}, session=g_tf_sess)
# Find the best probability, and add it to the result list
best_result = np.argmax(inference_result)
resultList.append("{}: {}".format(os.path.basename(image), best_result))
return resultList
다른 파일 또는 폴더가 유추 스크립트와 동일한 디렉터리에 있는 경우 현재 작업 디렉터리를 찾아 참조할 수 있습니다.
script_dir = os.path.realpath(os.path.join(__file__, '..',))
file_path = os.path.join(script_dir, "<file_name>")
ParallelRunConfig에 대한 매개 변수
ParallelRunConfig는 Azure Machine Learning 파이프라인 내에서 ParallelRunStep 인스턴스에 대한 주요 구성입니다. 스크립트를 래핑하고 다음 항목을 포함하여 필요한 매개 변수를 구성하는 데 사용됩니다.
entry_script: 여러 노드에서 병렬로 실행되는 로컬 파일 경로인 사용자 스크립트입니다.source_directory가 있으면 상대 경로를 사용합니다. 없으면 머신에서 액세스할 수 있는 아무 경로를 사용합니다.mini_batch_size: 단일run()호출에 전달된 미니 일괄 처리의 크기입니다. (선택 사항이며 기본값은FileDataset의 경우10파일이고TabularDataset의 경우1MB임)FileDataset의 경우 최솟값이1인 파일 수입니다. 여러 파일을 한 미니 일괄 처리로 결합할 수 있습니다.TabularDataset의 경우 데이터의 크기입니다. 예제 값은1024,1024KB,10MB및1GB입니다. 권장 값은1MB입니다.TabularDataset의 미니 일괄 처리는 파일 경계를 넘지 않습니다. 예를 들어 다양한 크기의 .csv 파일이 있는 경우 가장 작은 파일은 100KB이고 가장 큰 파일은 10MB입니다.mini_batch_size = 1MB를 설정하면 크기가 1MB보다 작은 파일이 하나의 미니 일괄 처리로 처리됩니다. 1MB보다 큰 파일은 여러 개의 미니 일괄 처리로 분할됩니다.
error_threshold: 처리 중에 무시해야 하는FileDataset에 대한TabularDataset및 파일 오류에 대한 레코드 실패 횟수입니다. 전체 입력에 대한 오류 수가 이 값을 초과하면 작업이 중단됩니다. 오류 임계값은run()메서드로 전송되는 개별 미니 일괄 처리가 아닌 전체 입력에 적용됩니다. 범위는[-1, int.max]입니다.-1부분은 처리 중에 발생하는 모든 오류를 무시한다는 뜻입니다.output_action: 다음 값 중 하나는 출력이 구성되는 방식을 나타냅니다.summary_only: 사용자 스크립트가 출력을 저장합니다.ParallelRunStep는 오류 임계값 계산에만 출력을 사용합니다.append_row: 모든 입력에 대해 출력 폴더에 하나의 파일만 만들어져 모든 출력을 줄로 구분하여 추가합니다.
append_row_file_name: append_row output_action의 출력 파일 이름을 사용자 지정하는 방법은 다음과 같습니다(선택 사항이며 기본값은parallel_run_step.txt).source_directory: 컴퓨팅 대상에서 실행할 모든 파일이 포함된 폴더 경로입니다(선택 사항).compute_target:AmlCompute만 지원됩니다.node_count: 사용자 스크립트를 실행하는 데 사용되는 컴퓨팅 노드의 수입니다.process_count_per_node: 노드당 프로세스 수입니다. 모범 사례는 한 노드에 있는 GPU 또는 CPU 수로 설정하는 것입니다(선택 사항이며 기본값은1).environment: Python 환경 정의입니다. 기존 Python 환경을 사용하도록 구성할 수도 있고 임시 환경을 설정하도록 구성할 수도 있습니다. 이 정의는 필요한 애플리케이션 종속성을 설정하는 역할도 담당합니다(선택 사항).logging_level: 로그의 자세한 정도입니다. 값의 자세한 정도는WARNING,INFO,DEBUG순서로 높아집니다. (선택 사항이며 기본값은INFO)run_invocation_timeout:run()메서드 호출 시간 제한(초)입니다. (선택 사항이며 기본값은60)run_max_try: 미니 일괄 처리의 최대run()시도 횟수입니다. 예외가 throw되거나run_invocation_timeout에 도달할 때 아무 것도 반환되지 않으면run()이 실패합니다(선택 사항이며 기본값은3).
mini_batch_size, node_count, process_count_per_node, logging_level, run_invocation_timeout 및 run_max_try를 PipelineParameter로 지정할 수 있습니다. 그러면 파이프라인 실행을 다시 제출할 때 매개 변수 값을 세밀하게 조정할 수 있습니다. 이 예에서는 mini_batch_size 및 Process_count_per_node에 PipelineParameter을(를) 사용하며 나중에 실행을 다시 제출할 때 이 값을 변경할 것입니다.
ParallelRunStep 만들기에 대한 매개 변수
스크립트, 환경 구성 및 매개 변수를 사용하여 ParallelRunStep을 만듭니다. 유추 스크립트의 실행 대상으로 작업 영역에 이미 연결한 컴퓨팅 대상을 지정합니다. ParallelRunStep을 사용하여 다음 매개 변수를 모두 사용하는 일괄 처리 유추 파이프라인 단계를 만듭니다.
name: 단계의 이름이며, 고유한 3-32자 문자와 regex ^[a-z]([-a-z0-9]*[a-z0-9])?$로 구성되어야 한다는 명명 제한이 있습니다.parallel_run_config: 이전에 정의된ParallelRunConfig개체입니다.inputs: 병렬 처리를 위해 분할하려는 하나 이상의 단일 형식 Azure Machine Learning 데이터 세트입니다.side_inputs: 분할할 필요 없이 측면 입력으로 사용되는 하나 이상의 참조 데이터 또는 데이터 세트입니다.output: 출력 디렉터리에 해당하는OutputFileDatasetConfig개체입니다.arguments: 사용자 스크립트에 전달된 인수 목록입니다. 항목 스크립트에서 인수를 검색하려면 unknown_args를 사용합니다(선택 사항).allow_reuse: 동일한 설정/입력으로 실행할 때 이전 결과를 단계에 다시 사용할 것인지 여부를 지정합니다. 이 매개 변수가False이면 파이프라인 실행 중에 이 단계에 대한 새 실행이 생성됩니다. (선택 사항이며 기본값은True)
from azureml.pipeline.steps import ParallelRunStep
parallelrun_step = ParallelRunStep(
name="predict-digits-mnist",
parallel_run_config=parallel_run_config,
inputs=[input_mnist_ds_consumption],
output=output_dir,
allow_reuse=True
)
디버깅 기술
파이프라인 디버깅에는 세 가지 주요 기술이 사용됩니다.
- 로컬 컴퓨터에서 개별 파이프라인 단계 디버그
- 로깅 및 Application Insights를 사용하여 문제의 원인을 격리하고 진단합니다.
- Azure에서 실행 중인 파이프라인에 원격 디버거 연결
로컬에서 스크립트 디버그
파이프라인에서 가장 일반적으로 발생하는 실패 중 하나는 도메인 스크립트가 의도한 대로 실행되지 않거나, 디버그가 어려운 원격 컴퓨팅 컨텍스트에서 런타임 오류를 포함하는 것입니다.
파이프라인 자체는 로컬로 실행할 수 없습니다. 그러나 로컬 컴퓨터에서 별도로 스크립트를 실행하면 컴퓨팅 및 환경 빌드 프로세스를 기다릴 필요가 없으므로 더 빠르게 디버그할 수 있습니다. 이 작업을 수행하려면 몇 가지 개발 작업이 필요합니다.
- 데이터가 클라우드 데이터 저장소에 있는 경우, 데이터를 다운로드하여 스크립트에 사용할 수 있도록 해야 합니다. 적은 양의 데이터 샘플을 사용하면 런타임 시간을 줄이고 스크립트 동작에 대한 피드백을 빠르게 얻을 수 있습니다.
- 중간 파이프라인 단계를 시뮬레이션하려는 경우 특정 스크립트가 이전 단계에서 예상하는 개체 형식을 수동으로 빌드해야 할 수 있습니다.
- 자체 환경을 정의하고 원격 컴퓨팅 환경에 정의된 종속성을 복제해야 합니다.
로컬 환경에서 실행할 스크립트 설정이 있으면 다음과 같은 디버깅 작업을 수행하는 것이 더 쉽습니다.
- 사용자 지정 디버그 구성 연결
- 실행 일시 중지 및 개체 상태 검사
- 런타임 전까지 노출되지 않는 형식 또는 논리 오류 포착
팁
스크립트가 예상대로 실행되는지 확인한 후에는 여러 단계로 이루어진 파이프라인에서 스크립트 실행을 시도하기 전 먼저 단일 단계 파이프라인에서 실행해 보는 것이 좋습니다.
파이프라인 로그 구성, 쓰기, 검토
로컬에서 스크립트를 테스트하는 것은 파이프라인 빌드를 시작하기 전에 주요 코드 조각과 복잡한 논리를 디버그하는 좋은 방법입니다. 어떤 시점에서는 실제 파이프라인 실행 자체 중에 스크립트를 디버깅해야 합니다. 특히 파이프라인 단계 간 상호 작용 중에 발생하는 동작을 진단할 때 더욱 그렇습니다. 이는 JavaScript 코드를 디버그하는 방법과 유사하게, 원격 실행 중에 개체 상태와 예상 값을 볼 수 있도록 단계 스크립트에서 print() 문을 자유롭게 사용하는 것이 좋습니다.
로깅 옵션 및 동작
다음 표에서는 파이프라인의 다양한 디버그 옵션에 대한 정보를 제공합니다. 여기에 나와 있는 Azure Machine Learning, Python, OpenCensus 외에 다른 옵션도 존재하므로 완전한 목록은 아니라는 점을 참조하세요.
| 라이브러리 | Type | 예제 | 대상 | 리소스 |
|---|---|---|---|---|
| Azure Machine Learning SDK | 메트릭 | run.log(name, val) |
Azure Machine Learning 포털 UI | 실험 추적 방법 azureml.core.Run class |
| Python 인쇄/로깅 | 로그 | print(val)logging.info(message) |
드라이버 로그, Azure Machine Learning 디자이너 | 실험 추적 방법 Python 로깅 |
| OpenCensus Python | 로그 | logger.addHandler(AzureLogHandler())logging.log(message) |
Application Insights - 추적 | Application Insights에서 파이프라인 디버깅 OpenCensus Azure Monitor Exporters Python 로깅 Cookbook |
로깅 옵션 예제
import logging
from azureml.core.run import Run
from opencensus.ext.azure.log_exporter import AzureLogHandler
run = Run.get_context()
# Azure Machine Learning Scalar value logging
run.log("scalar_value", 0.95)
# Python print statement
print("I am a python print statement, I will be sent to the driver logs.")
# Initialize Python logger
logger = logging.getLogger(__name__)
logger.setLevel(args.log_level)
# Plain Python logging statements
logger.debug("I am a plain debug statement, I will be sent to the driver logs.")
logger.info("I am a plain info statement, I will be sent to the driver logs.")
handler = AzureLogHandler(connection_string='<connection string>')
logger.addHandler(handler)
# Python logging with OpenCensus AzureLogHandler
logger.warning("I am an OpenCensus warning statement, find me in Application Insights!")
logger.error("I am an OpenCensus error statement with custom dimensions", {'step_id': run.id})
Azure Machine Learning 디자이너
디자이너에서 만든 파이프라인의 경우 제작 페이지나 파이프라인 실행 세부 정보 페이지에서 70_driver_log 파일을 찾을 수 있습니다.
실시간 엔드포인트에 대한 로깅 사용 설정
디자이너에서 실시간 엔드포인트 문제를 해결하고 디버그하려면 SDK를 사용하여 Application Insight 로깅을 사용하도록 설정해야 합니다. 로깅을 통해 모델 배포 및 사용 문제를 해결하고 디버그할 수 있습니다. 자세한 내용은 배포된 모델에 대한 로깅을 참조하세요.
제작 페이지에서 로그 가져오기
파이프라인 실행을 제출하고 제작 페이지에 머무르는 경우 각 구성 요소의 실행이 완료되면 각 구성 요소에 대해 생성되는 로그 파일을 찾을 수 있습니다.
제작 캔버스에서 실행이 완료된 구성 요소를 선택합니다.
구성 요소의 오른쪽 창에서 출력 + 로그 탭으로 이동합니다.
오른쪽 창을 펼치고 70_driver_log.txt를 선택하여 브라우저에서 파일을 봅니다. 로그를 로컬로 다운로드할 수도 있습니다.
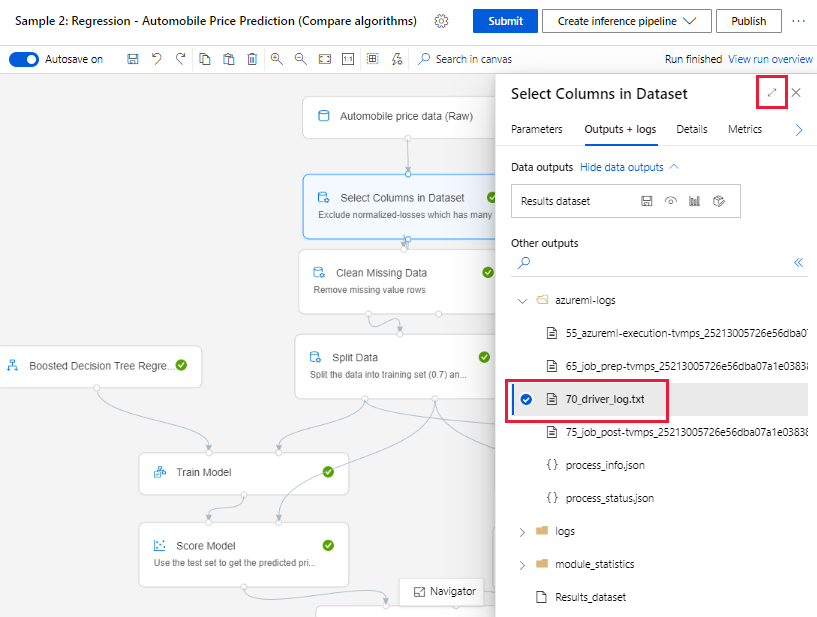
파이프라인 실행에서 로그 가져오기
파이프라인 실행 세부 정보 페이지에서 특정 실행에 대한 로그 파일을 찾을 수도 있습니다. 세부 정보 페이지는 스튜디오의 파이프라인 또는 실험 섹션에 있습니다.
디자이너에서 만든 파이프라인 실행을 선택합니다.
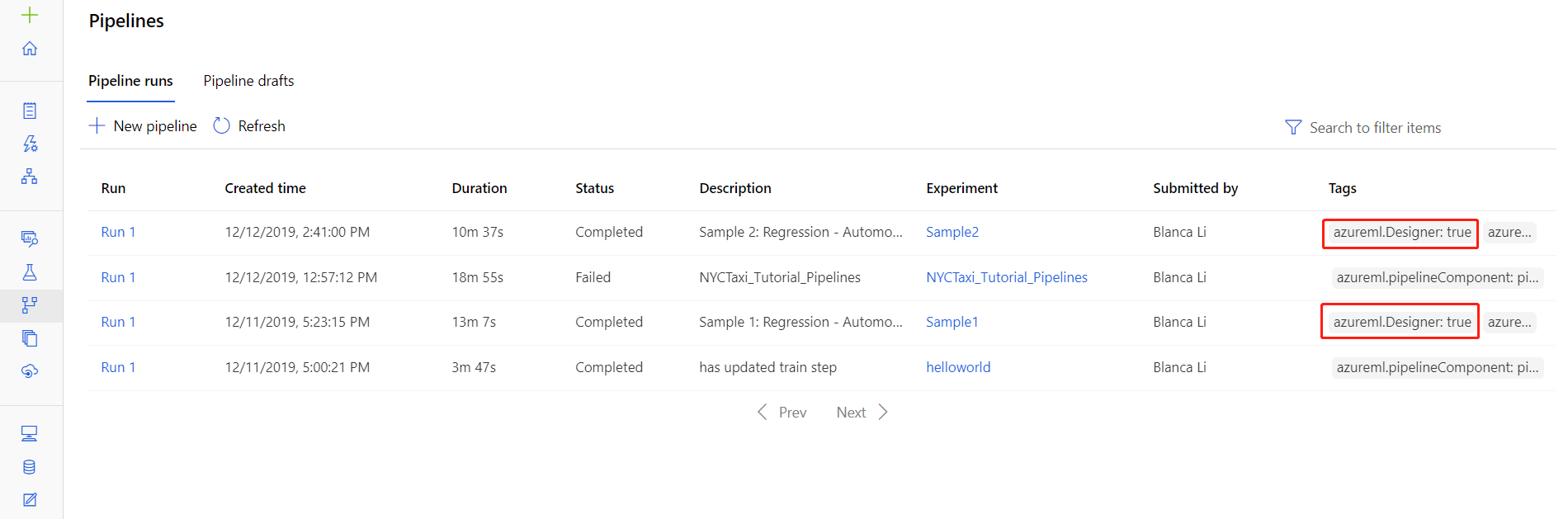
미리 보기 창에서 구성 요소를 선택합니다.
구성 요소의 오른쪽 창에서 출력 + 로그 탭으로 이동합니다.
오른쪽 창을 펼쳐 브라우저에서 std_log.txt 파일을 보거나 해당 파일을 선택하여 로그를 로컬로 다운로드합니다.
Important
파이프라인 실행 세부 정보 페이지에서 파이프라인을 업데이트하려면 파이프라인 실행을 새 파이프라인 초안으로 복제해야 합니다. 파이프라인 실행은 파이프라인의 스냅샷으로 로그 파일과 비슷하며 변경할 수 없습니다.
Application Insights
이와 같은 방식으로 OpenCensus Python 라이브러리를 사용하는 방법에 대한 자세한 내용은 Application Insights에서 기계 학습 파이프라인 디버그 및 문제 해결 가이드를 참조하세요.
Visual Studio Code를 사용한 대화형 디버깅
경우에 따라 ML 파이프라인에 사용된 Python 코드를 대화형으로 디버그해야 할 수도 있습니다. Visual Studio Code(VS Code) 및 debugpy를 사용하여 학습 환경에서 실행되는 코드에 연결할 수 있습니다. 자세한 내용은 VS Code의 대화형 디버깅 가이드를 참조하세요.
네트워크 격리로 HyperdriveStep 및 AutoMLStep 실패
HyperdriveStep 및 AutoMLStep을 사용한 후 모델을 등록하려고 하면 오류가 발생할 수 있습니다.
Azure Machine Learning SDK v1을 사용하고 있습니다.
Azure Machine Learning 작업 영역은 VNet(네트워크 격리)에 대해 구성됩니다.
파이프라인이 이전 단계에서 생성된 모델을 등록하려고 시도합니다. 예를 들어, 다음 예에서
inputs매개 변수는 HyperdriveStep의 save_model입니다.register_model_step = PythonScriptStep(script_name='register_model.py', name="register_model_step01", inputs=[saved_model], compute_target=cpu_cluster, arguments=["--saved-model", saved_model], allow_reuse=True, runconfig=rcfg)
해결 방법
Important
이 동작은 Azure Machine Learning SDK v2를 사용할 때 발생하지 않습니다.
이 오류를 해결하려면 Run 클래스를 사용하여 HyperdriveStep 또는 AutoMLStep에서 만든 모델을 가져옵니다. 다음은 HyperdriveStep에서 출력 모델을 가져오는 예제 스크립트입니다.
%%writefile $script_folder/model_download9.py
import argparse
from azureml.core import Run
from azureml.pipeline.core import PipelineRun
from azureml.core.experiment import Experiment
from azureml.train.hyperdrive import HyperDriveRun
from azureml.pipeline.steps import HyperDriveStepRun
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
'--hd_step_name',
type=str, dest='hd_step_name',
help='The name of the step that runs AutoML training within this pipeline')
args = parser.parse_args()
current_run = Run.get_context()
pipeline_run = PipelineRun(current_run.experiment, current_run.experiment.name)
hd_step_run = HyperDriveStepRun((pipeline_run.find_step_run(args.hd_step_name))[0])
hd_best_run = hd_step_run.get_best_run_by_primary_metric()
print(hd_best_run)
hd_best_run.download_file("outputs/model/saved_model.pb", "saved_model.pb")
print("Successfully downloaded model")
그런 다음 PythonScriptStep에서 파일을 사용할 수 있습니다.
from azureml.pipeline.steps import PythonScriptStep
conda_dep = CondaDependencies()
conda_dep.add_pip_package("azureml-sdk")
conda_dep.add_pip_package("azureml-pipeline")
rcfg = RunConfiguration(conda_dependencies=conda_dep)
model_download_step = PythonScriptStep(
name="Download Model 9",
script_name="model_download9.py",
arguments=["--hd_step_name", hd_step_name],
compute_target=compute_target,
source_directory=script_folder,
allow_reuse=False,
runconfig=rcfg
)
다음 단계
ParallelRunStep을 사용하는 전체 자습서는 자습서: 일괄 처리 점수 매기기를 위한 Azure Machine Learning 파이프라인 빌드를 참조하세요.ML 파이프라인의 자동화된 머신 러닝을 보여 주는 전체 예제는 Python의 Azure Machine Learning 파이프라인에서 자동화된 ML 사용을 참조하세요.
azureml-pipelines-core 패키지 및 azureml-pipelines-steps 패키지에 대한 도움이 필요한 경우 SDK 참조를 확인하세요.
디자이너 예외 및 오류 코드 목록을 참조하세요.