메트릭 및 로그 파일 v1 로그 및 보기
적용 대상: Python SDK azureml v1
Python SDK azureml v1
기본 Python 로깅 패키지와 Azure Machine Learning Python SDK 관련 기능을 사용하여 실시간 정보를 로그할 수 있습니다. 로컬로 로그인하고 로그를 포털의 작업 영역에 보낼 수 있습니다.
로그는 오류 및 경고를 진단하거나 매개 변수 및 모델 성능과 같은 성능 메트릭을 추적하는 데 도움이 됩니다. 이 문서에서는 다음 시나리오에서 로깅을 사용하도록 설정하는 방법에 대해 알아봅니다.
- 실행 메트릭 로그
- 대화형 학습 세션
- ScriptRunConfig를 사용하여 학습 작업 제출
- Python 네이티브
logging설정 - 추가 원본에서 로깅
팁
이 문서에서는 모델 학습 프로세스를 모니터링하는 방법을 보여 줍니다. 할당량, 완료된 학습 실행 또는 완료된 모델 배포와 같이 Azure Machine Learning의 리소스 사용량 및 이벤트를 모니터링하는 데 관심이 있는 경우 Azure Machine Learning 모니터링을 참조하세요.
데이터 형식
스칼라 값, 목록, 테이블, 이미지, 디렉터리 등을 포함한 여러 데이터 형식을 기록할 수 있습니다. 다양한 데이터 형식에 대한 자세한 내용과 Python 코드 예제는 Run 클래스 참조 페이지를 참조하세요.
실행 메트릭 로그
로깅 API에서 다음 메서드를 사용하여 메트릭 시각화에 영향을 줄 수 있습니다. 로그된 메트릭의 서비스 한도에 유의하세요.
| 기록된 값 | 예제 코드 | 포털의 형식 |
|---|---|---|
| 숫자 값의 배열 기록 | run.log_list(name='Fibonacci', value=[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]) |
단일 변수 꺾은선형 차트 |
| 반복적으로 사용되는 동일한 메트릭 이름(for 루프 내에서와 같이)을 사용하여 단일 숫자 값 기록 | for i in tqdm(range(-10, 10)): run.log(name='Sigmoid', value=1 / (1 + np.exp(-i))) angle = i / 2.0 |
단일 변수 꺾은선형 차트 |
| 2개의 숫자 열을 반복적으로 사용하여 행 기록 | run.log_row(name='Cosine Wave', angle=angle, cos=np.cos(angle)) sines['angle'].append(angle) sines['sine'].append(np.sin(angle)) |
두 개의 변수 꺽은선형 차트 |
| 두 개의 숫자 열을 사용하여 테이블 기록 | run.log_table(name='Sine Wave', value=sines) |
두 개의 변수 꺽은선형 차트 |
| 이미지 로그 | run.log_image(name='food', path='./breadpudding.jpg', plot=None, description='desert') |
이 메서드는 이미지 파일이나 matplotlib 플롯을 실행에 로그하는 데 사용합니다. 실행 기록에서 해당 이미지를 표시하고 비교할 수 있습니다. |
MLflow를 사용하여 로그
MLflow는 오픈 소스이며 클라우드 이식성에 대한 로컬 모드를 지원하기 때문에 MLflow를 사용하여 모델, 메트릭 및 아티팩트를 로깅하는 것이 좋습니다. 다음 표 및 코드 예제에서는 MLflow를 사용하여 학습 실행에서 메트릭 및 아티팩트를 로그하는 방법을 보여 줍니다. MLflow의 로깅 메서드 및 디자인 패턴에 대해 자세히 알아봅니다.
mlflow 및 azureml-mlflow pip 패키지를 작업 영역에 설치해야 합니다.
pip install mlflow
pip install azureml-mlflow
MLflow 추적 URI가 Azure Machine Learning 백 엔드를 가리키도록 설정하여 메트릭 및 아티팩트가 작업 영역에 로그되도록 합니다.
from azureml.core import Workspace
import mlflow
from mlflow.tracking import MlflowClient
ws = Workspace.from_config()
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.create_experiment("mlflow-experiment")
mlflow.set_experiment("mlflow-experiment")
mlflow_run = mlflow.start_run()
| 기록된 값 | 예제 코드 | 주의 |
|---|---|---|
| 숫자 값 로그(int 또는 float) | mlflow.log_metric('my_metric', 1) |
|
| 부울 값 로그 | mlflow.log_metric('my_metric', 0) |
0 = True, 1 = False |
| 문자열 로그 | mlflow.log_text('foo', 'my_string') |
아티팩트로 로그됨 |
| numpy 메트릭 또는 PIL 이미지 개체 로그 | mlflow.log_image(img, 'figure.png') |
|
| matlotlib 플롯 또는 이미지 파일 로그 | mlflow.log_figure(fig, "figure.png") |
SDK를 통해 실행 메트릭 보기
run.get_metrics()를 사용하여 학습된 모델의 메트릭을 볼 수 있습니다.
from azureml.core import Run
run = Run.get_context()
run.log('metric-name', metric_value)
metrics = run.get_metrics()
# metrics is of type Dict[str, List[float]] mapping metric names
# to a list of the values for that metric in the given run.
metrics.get('metric-name')
# list of metrics in the order they were recorded
실행 개체의 데이터 및 정보 속성을 통해 MLflow를 사용하여 실행 정보에 액세스할 수도 있습니다. 자세한 내용은 MLflow.entities.Run object 설명서를 참조하세요.
실행이 완료되면 MlFlowClient()를 사용하여 검색할 수 있습니다.
from mlflow.tracking import MlflowClient
# Use MlFlow to retrieve the run that was just completed
client = MlflowClient()
finished_mlflow_run = MlflowClient().get_run(mlflow_run.info.run_id)
실행 개체의 데이터 필드에서 실행에 대한 메트릭, 매개 변수 및 태그를 볼 수 있습니다.
metrics = finished_mlflow_run.data.metrics
tags = finished_mlflow_run.data.tags
params = finished_mlflow_run.data.params
참고 항목
mlflow.entities.Run.data.metrics 아래의 메트릭 사전은 지정된 메트릭 이름에 대해 가장 최근에 로그된 값만 반환합니다. 예를 들어 순서대로 1, 2, 3, 4를 sample_metric이라는 메트릭에 로드하는 경우 sample_metric의 메트릭 사전에는 4만 있습니다.
특정 메트릭 이름에 대해 로그된 모든 메트릭을 얻으려면 MlFlowClient.get_metric_history()를 사용할 수 있습니다.
스튜디오 UI에서 실행 메트릭 보기
Azure Machine Learning 스튜디오에서 로그된 메트릭을 비롯한 완료된 실행 기록을 찾아볼 수 있습니다.
실험 탭으로 이동합니다. 실험에서 작업 영역의 모든 실행을 보려면 모두 실행 탭을 선택합니다. 위쪽 메뉴 모음에서 실험 필터를 적용하여 특정 실험에 대한 실행을 드릴다운할 수 있습니다.
개별 실험 보기에 대해 모든 실험 탭을 선택합니다. 실험 실행 대시보드에서 각 실행에 대한 추적된 메트릭 및 로그를 볼 수 있습니다.
실행 목록 테이블을 편집하여 여러 실행을 선택하고 실행에 대해 로그된 마지막 값, 최솟값, 최댓값을 표시할 수도 있습니다. 여러 실행의 로그된 메트릭 값과 집계를 비교하려면 차트를 사용자 지정합니다. 차트의 y-축에 여러 메트릭을 그리고 x-축을 사용자 지정하여 로그된 메트릭을 그릴 수 있습니다.
실행에 대한 로그 파일 보기 및 다운로드
로그 파일은 Azure Machine Learning 워크로드를 디버그하는 데 필수적인 리소스입니다. 학습 작업을 제출한 후 특정 실행으로 드릴다운하여 해당 로그 및 출력을 봅니다.
- 실험 탭으로 이동합니다.
- 특정 실행에 대한 runID를 선택합니다.
- 페이지 맨 위에서 출력 및 로그를 선택합니다.
- 모두 다운로드를 선택하여 모든 로그를 zip 폴더로 다운로드합니다.
- 개별 로그 파일, 다운로드를 차례로 선택하여 개별 로그 파일을 다운로드할 수도 있습니다.
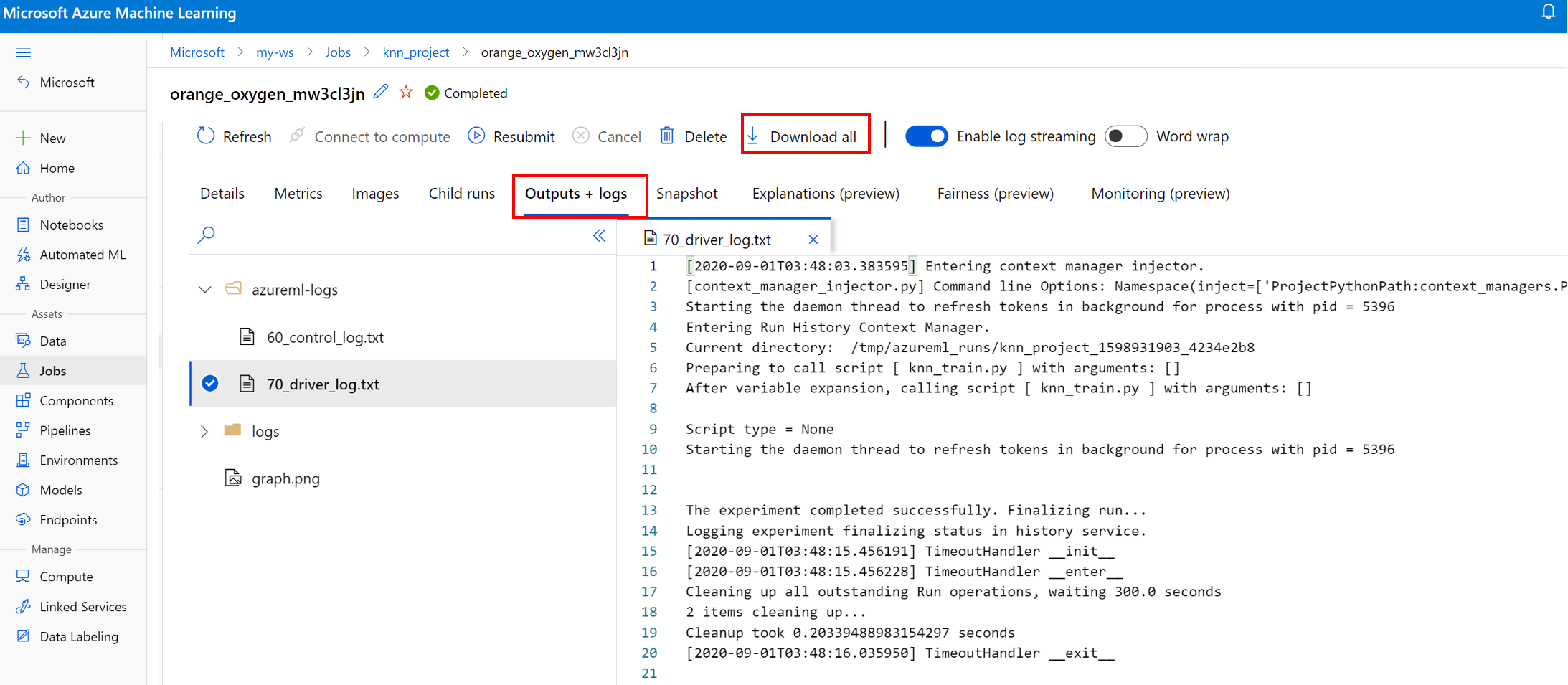
user_logs 폴더
이 폴더에는 사용자가 생성한 로그에 대한 정보가 포함되어 있습니다. 이 폴더는 기본적으로 열려 있으며 std_log.txt 로그가 선택됩니다. std_log.txt는 코드의 로그(예: print 문)가 표시되는 위치입니다. 이 파일에는 컨트롤 스크립트 및 학습 스크립트의 stdout 로그와 stderr 로그가 프로세스당 하나씩 포함됩니다. 대부분의 경우 여기에서 로그를 모니터링합니다.
system_logs 폴더
이 폴더에는 Azure Machine Learning에서 생성한 로그가 포함되며 기본적으로 닫힙니다. 시스템에서 생성된 로그는 런타임의 작업 단계에 따라 다른 폴더로 그룹화됩니다.
기타 폴더
다중 컴퓨팅 클러스터에서 학습하는 작업의 경우 노드 IP마다 로그가 있습니다. 각 노드의 구조는 단일 노드 작업과 동일합니다. 전체 실행, stderr, stdout 로그에 대한 로그 폴더가 하나 더 있습니다.
Azure Machine Learning은 학습 작업을 실행하는 AutoML이나 Docker 컨테이너와 같이 학습 중에 다양한 원본의 정보를 기록합니다. 해당 로그는 대부분 문서화되지 않습니다. 문제가 발생하여 Microsoft 지원에 문의하는 경우 이러한 로그를 사용하여 문제를 해결할 수 있습니다.
대화형 로깅 세션
대화형 로깅 세션은 일반적으로 Notebook 환경에서 사용됩니다. Experiment.start_logging() 메서드는 대화형 로깅 세션을 시작합니다. 세션 중에 기록된 모든 메트릭은 실험의 실행 기록에 추가됩니다. run.complete() 메서드는 세션을 종료하고 실행을 완료됨으로 표시합니다.
ScriptRun 로그
이 섹션에서는 ScriptRunConfig로 구성할 때 생성된 실행 내부에 로깅 코드를 추가하는 방법을 알아봅니다. ScriptRunConfig 클래스를 사용하여 반복 가능한 실행에 대한 스크립트 및 환경을 캡슐화할 수 있습니다. 또한 이 옵션을 사용하여 모니터링을 위한 시각적 Jupyter Notebook 위젯을 표시할 수 있습니다.
다음 예제에서는 run.log() 메서드를 사용하여 알파 값에 대한 매개 변수 스윕을 수행하고 결과를 캡처합니다.
로깅 논리가 포함된 학습 스크립트(
train.py)를 만듭니다.# Copyright (c) Microsoft. All rights reserved. # Licensed under the MIT license. from sklearn.datasets import load_diabetes from sklearn.linear_model import Ridge from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split from azureml.core.run import Run import os import numpy as np import mylib # sklearn.externals.joblib is removed in 0.23 try: from sklearn.externals import joblib except ImportError: import joblib os.makedirs('./outputs', exist_ok=True) X, y = load_diabetes(return_X_y=True) run = Run.get_context() X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) data = {"train": {"X": X_train, "y": y_train}, "test": {"X": X_test, "y": y_test}} # list of numbers from 0.0 to 1.0 with a 0.05 interval alphas = mylib.get_alphas() for alpha in alphas: # Use Ridge algorithm to create a regression model reg = Ridge(alpha=alpha) reg.fit(data["train"]["X"], data["train"]["y"]) preds = reg.predict(data["test"]["X"]) mse = mean_squared_error(preds, data["test"]["y"]) run.log('alpha', alpha) run.log('mse', mse) model_file_name = 'ridge_{0:.2f}.pkl'.format(alpha) # save model in the outputs folder so it automatically get uploaded with open(model_file_name, "wb") as file: joblib.dump(value=reg, filename=os.path.join('./outputs/', model_file_name)) print('alpha is {0:.2f}, and mse is {1:0.2f}'.format(alpha, mse))사용자 관리 환경에서 실행되도록
train.py스크립트를 제출합니다. 학습을 위해 전체 스크립트 폴더가 제출됩니다.from azureml.core import ScriptRunConfig src = ScriptRunConfig(source_directory='./scripts', script='train.py', environment=user_managed_env)run = exp.submit(src)show_output매개 변수는 자세한 정보 로깅을 설정합니다. 그러면 학습 프로세스의 세부 정보와 원격 리소스 또는 컴퓨팅 대상에 대한 정보를 확인할 수 있습니다. 실험을 제출할 때 자세한 정보 로깅을 설정하려면 다음 코드를 사용합니다.run = exp.submit(src, show_output=True)결과 실행의
wait_for_completion함수에서도 동일한 매개 변수를 사용할 수 있습니다.run.wait_for_completion(show_output=True)
네이티브 Python 로깅
SDK의 일부 로그에는 로깅 수준을 DEBUG로 설정하도록 지시하는 오류가 포함될 수 있습니다. 로깅 수준을 설정하려면 스크립트에 다음 코드를 추가합니다.
import logging
logging.basicConfig(level=logging.DEBUG)
기타 로깅 원본
Azure Machine Learning은 학습 중에 자동화된 Machine Learning 실행 또는 작업을 실행하는 Docker 컨테이너와 같은 다른 원본의 정보를 기록할 수도 있습니다. 이러한 로그는 문서화되어 있지 않지만 문제가 발생하여 Microsoft 지원에 문의하는 경우 문제 해결 중에 이러한 로그를 사용할 수 있습니다.
Azure Machine Learning 디자이너의 메트릭 로깅에 대한 자세한 내용은 디자이너에서 메트릭을 기록하는 방법을 참조하세요.
예제 Notebook
이 문서의 개념을 보여 주는 노트북은 다음과 같습니다.
- how-to-use-azureml/training/train-on-local
- how-to-use-azureml/track-and-monitor-experiments/logging-api
Jupyter 노트북을 사용하여 이 서비스 검색 문서를 따라 노트북을 실행하는 방법을 알아봅니다.
다음 단계
Azure Machine Learning을 사용하는 방법에 대한 자세한 내용은 다음 문서를 참조하세요.
- 최상의 모델을 등록하고 배포하는 방법에 대한 예제는 Azure Machine Learning으로 이미지 분류 모델 학습 자습서를 참조하세요.