작업의 데이터에 액세스
적용 대상: Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
이 문서에서는 다음에 대해 알아봅니다.
- Azure Machine Learning 작업에서 Azure Storage의 데이터를 읽는 방법입니다.
- Azure Machine Learning 작업의 데이터를 Azure Storage에 쓰는 방법입니다.
- 탑재 모드와 다운로드 모드의 차이점
- 사용자 ID 및 관리 ID를 사용하여 데이터에 액세스하는 방법입니다.
- 작업에서 탑재 설정을 사용할 수 있습니다.
- 일반적인 시나리오에 대한 최적의 탑재 설정입니다.
- V1 데이터 자산에 액세스하는 방법
필수 구성 요소
Azure 구독 Azure 구독이 아직 없는 경우 시작하기 전에 체험 계정을 만듭니다. Azure Machine Learning 평가판 또는 유료 버전을 사용해 보세요.
Azure Machine Learning 작업 영역
빠른 시작
데이터에 액세스할 때 사용할 수 있는 세부 옵션을 살펴보기 전에 먼저 데이터 액세스에 대한 관련 코드 조각을 설명합니다.
Azure Machine Learning 작업의 Azure Storage에서 데이터 읽기
이 예에서는 공용 Blob Storage 계정의 데이터에 액세스하는 Azure Machine Learning 작업을 제출합니다. 그러나 프라이빗 Azure Storage 계정의 자체 데이터에 액세스하도록 코드 조각을 조정할 수 있습니다. 여기에 설명된 대로 경로를 업데이트합니다. Azure Machine Learning은 Microsoft Entra 통과를 통해 클라우드 스토리지에 대한 인증을 원활하게 처리합니다. 작업을 제출할 때 다음을 선택할 수 있습니다.
- 사용자 ID: Microsoft Entra ID를 통과하여 데이터에 액세스합니다.
- 관리 ID: 컴퓨팅 대상의 관리 ID를 사용하여 데이터에 액세스합니다.
- 없음: 데이터에 액세스하기 위해 ID를 지정하지 않습니다. 자격 증명 기반(키/SAS 토큰) 데이터 저장소를 사용하거나 공용 데이터에 액세스할 때는 없음을 사용합니다.
팁
키나 SAS 토큰을 사용하여 인증하는 경우 런타임이 키/토큰을 노출하지 않고 자동으로 스토리지에 연결하므로 Azure Machine Learning 데이터 저장소를 만드는 것이 좋습니다.
from azure.ai.ml import command, Input, MLClient, UserIdentityConfiguration, ManagedIdentityConfiguration
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data. Supported paths include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# We set the path to a file on a public blob container
# ==============================================================
path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
# ==============================================================
# What type of data does the path point to? Options include:
# data_type = AssetTypes.URI_FILE # a specific file
# data_type = AssetTypes.URI_FOLDER # a folder
# data_type = AssetTypes.MLTABLE # an mltable
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the mode. The popular modes include:
# mode = InputOutputModes.RO_MOUNT # Read-only mount on the compute target
# mode = InputOutputModes.DOWNLOAD # Download the data to the compute target
# ==============================================================
mode = InputOutputModes.RO_MOUNT
# ==============================================================
# You can set the identity you want to use in a job to access the data. Options include:
# identity = UserIdentityConfiguration() # Use the user's identity
# identity = ManagedIdentityConfiguration() # Use the compute target managed identity
# ==============================================================
# This example accesses public data, so we don't need an identity.
# You also set identity to None if you use a credential-based datastore
identity = None
# Set the input for the job:
inputs = {
"input_data": Input(type=data_type, path=path, mode=mode)
}
# This command job uses the head Linux command to print the first 10 lines of the file
job = command(
command="head ${{inputs.input_data}}",
inputs=inputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
identity=identity,
)
# Submit the command
ml_client.jobs.create_or_update(job)
Azure Machine Learning 작업의 데이터를 Azure Storage에 씁니다.
이 예에서는 기본 Azure Machine Learning 데이터 저장소에 데이터를 쓰는 Azure Machine Learning 작업을 제출합니다. 선택적으로 데이터 자산의 name 값을 설정하여 출력에 데이터 자산을 만들 수 있습니다.
from azure.ai.ml import command, Input, Output, MLClient
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the input and output URI paths for the data. Supported paths include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# As an example, we set the input path to a file on a public blob container
# As an example, we set the output path to a folder in the default datastore
# ==============================================================
input_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
output_path = "azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv"
# ==============================================================
# What type of data are you pointing to?
# AssetTypes.URI_FILE (a specific file)
# AssetTypes.URI_FOLDER (a folder)
# AssetTypes.MLTABLE (a table)
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the input mode. The most commonly-used modes:
# InputOutputModes.RO_MOUNT
# InputOutputModes.DOWNLOAD
# Set the mode to Read Only (RO) to mount the data
# ==============================================================
input_mode = InputOutputModes.RO_MOUNT
# ==============================================================
# Set the output mode. The most commonly-used modes:
# InputOutputModes.RW_MOUNT
# InputOutputModes.UPLOAD
# Set the mode to Read Write (RW) to mount the data
# ==============================================================
output_mode = InputOutputModes.RW_MOUNT
# Set the input and output for the job:
inputs = {
"input_data": Input(type=data_type, path=input_path, mode=input_mode)
}
outputs = {
"output_data": Output(type=data_type,
path=output_path,
mode=output_mode,
# optional: if you want to create a data asset from the output,
# then uncomment name (name can be set without setting version)
# name = "<name_of_data_asset>",
# version = "<version>",
)
}
# This command job copies the data to your default Datastore
job = command(
command="cp ${{inputs.input_data}} ${{outputs.output_data}}",
inputs=inputs,
outputs=outputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
)
# Submit the command
ml_client.jobs.create_or_update(job)
Azure Machine Learning 데이터 런타임
작업을 제출하면 Azure Machine Learning 데이터 런타임은 스토리지 위치에서 컴퓨팅 대상까지의 데이터 로드를 제어합니다. Azure Machine Learning 데이터 런타임은 기계 학습 작업의 속도와 효율성을 위해 최적화되었습니다. 주요 이점은 다음과 같습니다.
- 데이터 로드는 빠른 속도와 높은 메모리 효율성으로 알려진 언어인 Rust 언어로 작성됩니다. 동시 데이터 다운로드의 경우 Rust는 Python GIL(Global Interpreter Lock) 문제를 방지합니다.
- 경량; Rust는 다른 기술(예: JVM)에 대한 종속성이 없습니다. 결과적으로 런타임은 빠르게 설치되며 컴퓨팅 대상에서 추가 리소스(CPU, 메모리)를 드레이닝하지 않습니다.
- 다중 프로세스(병렬) 데이터 로드
- 딥 러닝을 수행할 때 GPU를 더 잘 활용할 수 있도록 CPU에서 백그라운드 작업으로 데이터를 프리페치합니다.
- 클라우드 스토리지에 대한 원활한 인증 처리
- 데이터를 탑재(스트림)하거나 모든 데이터를 다운로드하는 옵션을 제공합니다. 자세한 내용은 탑재(스트리밍) 및 다운로드 섹션을 참조하세요.
- 로컬, 원격 및 포함 파일 시스템과 바이트 스토리지에 대한 통합 Python 인터페이스인 fsspec과의 원활한 통합입니다.
팁
학습(클라이언트) 코드에서 자체 탑재/다운로드 기능을 만드는 대신 Azure Machine Learning 데이터 런타임을 활용하는 것이 좋습니다. GIL(Global Interpreter Lock) 문제로 인해 클라이언트 코드가 Python을 사용하여 스토리지에서 데이터를 다운로드할 때 스토리지 처리량 제약 조건이 관찰되었습니다.
경로
작업에 데이터 입력/출력을 제공하는 경우 데이터 위치를 가리키는 path 매개 변수를 지정해야 합니다. 이 표에서는 Azure Machine Learning이 지원하는 다양한 데이터 위치를 보여 주고 path 매개 변수 예도 보여 줍니다.
| 위치 | 예제 |
|---|---|
| 로컬 컴퓨터의 경로 | ./home/username/data/my_data |
| 퍼블릭 http(s) 서버의 경로 | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Azure Storage의 경로 | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| Azure Machine Learning 데이터 저장소 경로 | azureml://datastores/<data_store_name>/paths/<path> |
| 데이터 자산 경로 | azureml:<my_data>:<version> |
모드
데이터 입/출력이 포함된 작업을 실행할 때 다음 모드 옵션 중에서 선택할 수 있습니다.
ro_mount: 로컬 디스크(SSD) 컴퓨팅 대상에 읽기 전용으로 스토리지 위치를 탑재합니다.rw_mount: 로컬 디스크(SSD) 컴퓨팅 대상에 읽기-쓰기로 스토리지 위치를 탑재합니다.download: 스토리지 위치에서 로컬 디스크(SSD) 컴퓨팅 대상으로 데이터를 다운로드합니다.upload: 컴퓨팅 대상에서 스토리지 위치로 데이터를 업로드합니다.eval_mount/eval_download:이러한 모드는 MLTable에 고유합니다. 일부 시나리오에서는 MLTable이 MLTable 파일을 호스트하는 스토리지 계정과 다른 스토리지 계정에 있을 수 있는 파일을 생성할 수 있습니다. 또는 MLTable은 스토리지 리소스에 있는 데이터를 하위 집합으로 나누거나 섞을 수 있습니다. 하위 집합/순서 섞기의 해당 보기는 Azure Machine Learning 데이터 런타임이 실제로 MLTable 파일을 평가하는 경우에만 표시됩니다. 예를 들어, 이 다이어그램에서는eval_mount또는eval_download와 함께 사용되는 MLTable이 두 개의 다른 스토리지 컨테이너와 다른 스토리지 계정에 있는 주석 파일에서 이미지를 가져온 다음 원격 컴퓨팅 대상의 파일 시스템에 탑재/다운로드할 수 있는 방법을 보여 줍니다.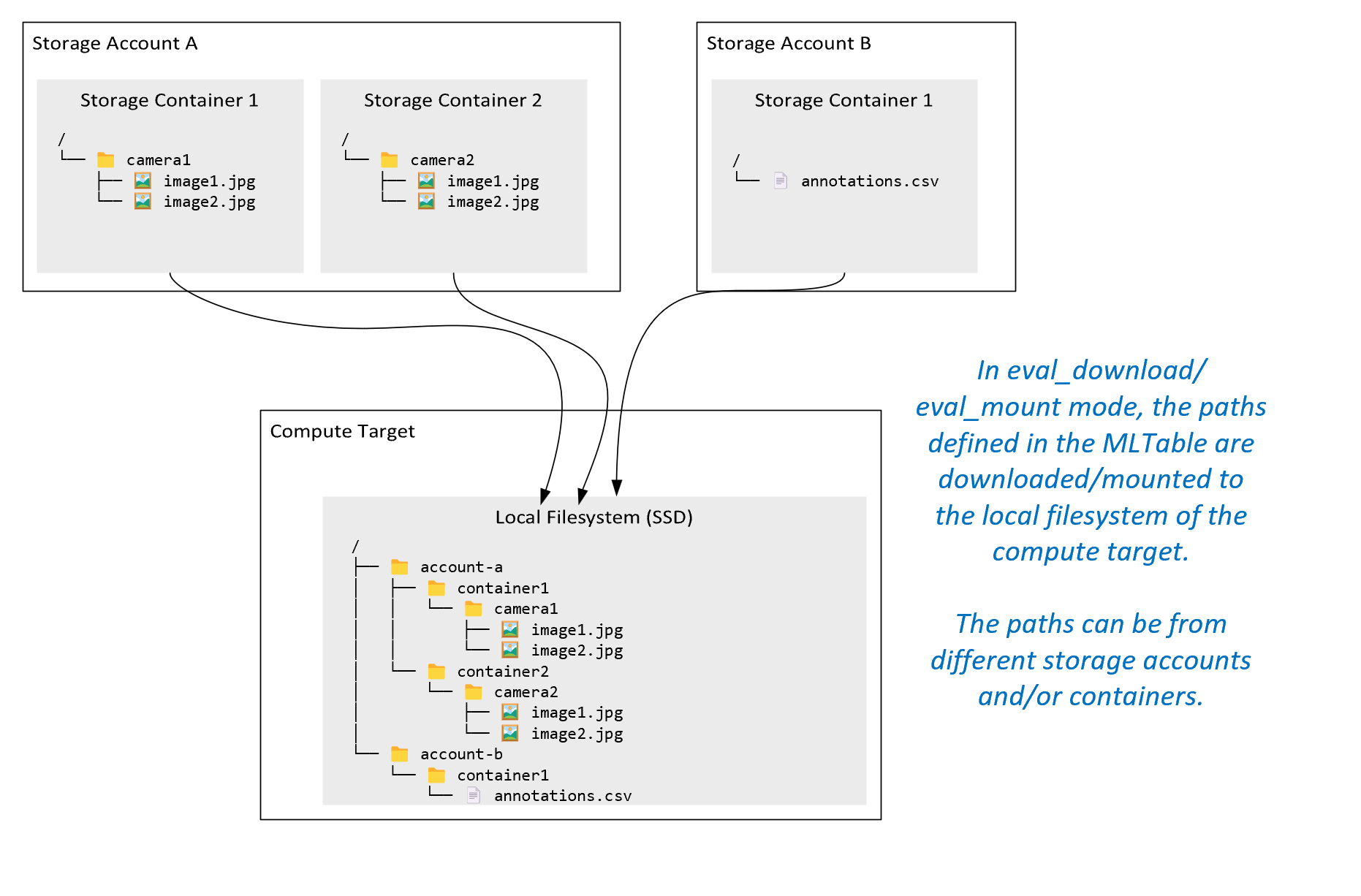
그러면 폴더 구조의 컴퓨팅 대상 파일 시스템에서
camera1폴더,camera2폴더 및annotations.csv파일에 액세스할 수 있습니다./INPUT_DATA ├── account-a │ ├── container1 │ │ └── camera1 │ │ ├── image1.jpg │ │ └── image2.jpg │ └── container2 │ └── camera2 │ ├── image1.jpg │ └── image2.jpg └── account-b └── container1 └── annotations.csvdirect: Azure Machine Learning 데이터 런타임을 통하지 않고 다른 API를 통해 URI에서 직접 데이터를 읽을 수 있습니다. 예를 들어, boto s3 클라이언트를 사용하여 s3 버킷(가상 호스팅 스타일 또는 경로 스타일httpsURL 사용)의 데이터에 액세스할 수 있습니다.direct모드를 사용하면 입력의 URI를 문자열로 가져올 수 있습니다.spark.read_*()메서드가 URI를 처리하는 방법을 알고 있으므로 Spark 작업에서 직접 모드를 사용하는 것을 볼 수 있습니다. Spark가 아닌 작업의 경우 액세스 자격 증명을 관리하는 것은 사용자의 책임입니다. 예를 들어, 컴퓨팅 MSI를 명시적으로 활용하거나 브로커 액세스를 사용해야 합니다.

이 표에서는 다양한 형식/모드/입력/출력 조합에 사용할 수 있는 모드를 보여 줍니다.
| Type | 입/출력 | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
입력 | ✓ | ✓ | ✓ | ||||
uri_file |
입력 | ✓ | ✓ | ✓ | ||||
mltable |
입력 | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
출력 | ✓ | ✓ | |||||
uri_file |
출력 | ✓ | ✓ | |||||
mltable |
출력 | ✓ | ✓ | ✓ |
다운로드
다운로드 모드에서는 모든 입력 데이터가 컴퓨팅 대상의 로컬 디스크(SSD)에 복사됩니다. 모든 데이터가 복사되면 Azure Machine Learning 데이터 런타임은 사용자 학습 스크립트를 시작합니다. 사용자 스크립트가 시작되면 다른 파일과 마찬가지로 로컬 디스크에서 데이터를 읽습니다. 작업이 완료되면 컴퓨팅 대상의 디스크에서 데이터가 제거됩니다.
| 장점 | 단점 |
|---|---|
| 학습이 시작되면 학습 스크립트에 대해 컴퓨팅 대상의 로컬 디스크(SSD)에서 모든 데이터를 사용할 수 있습니다. Azure Storage/네트워크 상호 작용이 필요하지 않습니다. | 데이터 세트는 컴퓨팅 대상 디스크에 완전히 맞아야 합니다. |
| 사용자 스크립트가 시작된 후에는 스토리지/네트워크 안정성에 대한 종속성이 없습니다. | 전체 데이터 세트가 다운로드됩니다(학습에서 데이터의 작은 부분만 임의로 선택해야 하는 경우 다운로드의 대부분이 낭비됨). |
| Azure Machine Learning 데이터 런타임은 다운로드(많은 작은 파일의 상당한 차이) 및 최대 네트워크/스토리지 처리량을 병렬화할 수 있습니다. | 작업은 모든 데이터가 컴퓨팅 대상의 로컬 디스크에 다운로드될 때까지 기다립니다. 제출된 딥 러닝 작업의 경우 데이터가 준비될 때까지 GPU가 유휴 상태가 됩니다. |
| FUSE 계층에 의해 추가되는 불가피한 오버헤드 없음(왕복: 사용자 스크립트에서 사용자 공간 호출 → 커널 → 사용자 공간 퓨즈 디먼 → 커널 → 사용자 공간에서 사용자 스크립트에 대한 응답) | 다운로드가 완료된 후에는 스토리지 변경 내용이 데이터에 반영되지 않습니다. |
다운로드를 사용하는 경우
- 데이터는 다른 학습을 방해하지 않고 컴퓨팅 대상의 디스크에 들어갈 만큼 작습니다.
- 학습에서는 데이터 세트의 대부분 또는 전부를 사용합니다.
- 학습은 데이터 세트에서 파일을 두 번 이상 읽습니다.
- 학습은 대용량 파일의 임의 위치로 이동해야 합니다.
- 학습이 시작되기 전에 모든 데이터가 다운로드될 때까지 기다려도 괜찮습니다.
사용 가능한 다운로드 설정
작업에서 다음 환경 변수를 사용하여 다운로드 설정을 조정할 수 있습니다.
| 환경 변수 이름 | Type | 기본값 | 설명 |
|---|---|---|---|
RSLEX_DOWNLOADER_THREADS |
u64 | NUMBER_OF_CPU_CORES * 4 |
다운로드에서 사용할 수 있는 동시 스레드 수 |
AZUREML_DATASET_HTTP_RETRY_COUNT |
u64 | 7 | 개별 스토리지의 다시 시도 횟수 / 일시적인 오류 복구를 위한 http 요청입니다. |
작업에서 환경 변수를 설정하여 위의 기본값을 변경할 수 있습니다. 예를 들면 다음과 같습니다.
간결성을 위해 작업에서 환경 변수를 정의하는 방법만 보여 줍니다.
from azure.ai.ml import command
env_var = {
"RSLEX_DOWNLOADER_THREADS": 64,
"AZUREML_DATASET_HTTP_RETRY_COUNT": 10
}
job = command(
environment_variables=env_var
)
성능 메트릭 다운로드
컴퓨팅 대상의 VM 크기는 데이터 다운로드 시간에 영향을 미칩니다. 특별한 사항
- 코어 수. 사용 가능한 코어가 많을수록 동시성이 높아져 다운로드 속도가 빨라집니다.
- 예상 네트워크 대역폭. Azure의 각 VM에는 NIC(네트워크 인터페이스 카드)의 최대 처리량이 있습니다.
참고 항목
A100 GPU VM의 경우 Azure Machine Learning 데이터 런타임은 컴퓨팅 대상에 데이터를 다운로드할 때 NIC(네트워크 인터페이스 카드)를 포화시킬 수 있습니다(~24Gbit/s). 가능한 이론적 최대 처리량.
이 표는 Azure Machine Learning 데이터 런타임이 Standard_D15_v2 VM의 100GB 파일에 대해 처리할 수 있는 다운로드 성능을 보여 줍니다(20코어, 25Gbit/s 네트워크 처리량).
| 데이터 구조 | 다운로드 전용(초) | MD5(초) 다운로드 및 계산 | 달성된 처리량(Gbit/s) |
|---|---|---|---|
| 10 x 10GB 파일 | 55.74 | 260.97 | 14.35Gbit/s |
| 100 x 1GB 파일 | 58.09 | 259.47 | 13.77Gbit/s |
| 1 x 100GB 파일 | 96.13 | 300.61 | 8.32Gbit/s |
더 작은 파일로 분할된 더 큰 파일이 병렬 처리로 인해 다운로드 성능을 개선시킬 수 있음을 알 수 있습니다. 페이로드를 다운로드하는 데 소요되는 시간에 비해 스토리지 요청 제출에 필요한 시간이 늘어나므로 파일이 너무 작아지는(4MB 미만) 것은 피하는 것이 좋습니다. 자세한 내용은 작은 파일이 많은 문제를 참조하세요.
탑재(스트리밍)
탑재 모드에서 Azure Machine Learning 데이터 기능은 FUSE(사용자 공간의 파일 시스템) Linux 기능을 사용하여 에뮬레이트된 파일 시스템을 만듭니다. 모든 데이터를 컴퓨팅 대상의 로컬 디스크(SSD)에 다운로드하는 대신 런타임은 사용자의 스크립트 작업에 실시간으로 반응할 수 있습니다. 예를 들어, "파일 열기", "X 위치에서 2KB 청크 읽기", "디렉터리 콘텐츠 나열"입니다.
| 장점 | 단점 |
|---|---|
| 컴퓨팅 대상 로컬 디스크 용량을 초과하는 데이터를 사용할 수 있습니다(컴퓨팅 하드웨어에 따라 제한되지 않음). | Linux FUSE 모듈의 오버헤드가 추가되었습니다. |
| 학습 시작 시 지연이 없습니다(다운로드 모드와 다름). | 사용자의 코드 동작에 대한 종속성(단일 스레드 탑재에서 작은 파일을 순차적으로 읽는 학습 코드도 스토리지에서 데이터를 요청하는 경우 네트워크 또는 스토리지 처리량을 최대화하지 못할 수 있음). |
| 사용 시나리오에 맞게 조정할 수 있는 추가 설정. | 창을 지원하지 않습니다. |
| 학습에 필요한 데이터만 스토리지에서 읽습니다. |
탑재를 사용하는 경우
- 데이터가 커서 컴퓨팅 대상 로컬 디스크에 맞지 않습니다.
- 클러스터의 각 개별 컴퓨팅 노드는 전체 데이터 세트(임의 파일 또는 csv 파일 선택의 행 등)를 읽을 필요가 없습니다.
- 학습이 시작되기 전에 모든 데이터가 다운로드될 때까지 기다리는 지연은 문제가 될 수 있습니다(유휴 GPU 시간).
사용 가능한 탑재 설정
작업에서 다음 환경 변수를 사용하여 탑재 설정을 조정할 수 있습니다.
| 환경 변수 이름 | Type | 기본값 | 설명 |
|---|---|---|---|
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL |
u64 | 설정되지 않음(캐시는 만료되지 않음) | getattr 호출 결과를 캐시에 보관하고 스토리지에서 이 정보에 대한 후속 요청을 다시 방지하는 데 필요한 시간(밀리초)입니다. |
DATASET_RESERVED_FREE_DISK_SPACE |
u64 | 150MB | 컴퓨팅을 정상 상태로 유지하기 위한 시스템 구성을 위한 것입니다. 다른 설정값에 관계없이 Azure Machine Learning 데이터 런타임은 디스크 공간의 마지막 RESERVED_FREE_DISK_SPACE 바이트를 사용하지 않습니다. |
DATASET_MOUNT_CACHE_SIZE |
usize | 제한 없음 | 탑재에서 사용할 수 있는 디스크 공간의 양을 제어합니다. 양수 값은 절대값을 바이트 단위로 설정합니다. 음수 값은 여유 공간으로 남겨둘 디스크 공간의 양을 설정합니다. 이 표에서는 더 많은 디스크 캐시 옵션을 제공합니다. 편의를 위해 KB, MB 및 GB 한정자를 지원합니다. |
DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD |
f64 | 1.0 | 캐시가 AVAILABLE_CACHE_SIZE * DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD까지 채워지면 볼륨 탑재가 캐시 정리를 시작합니다. 0과 1 사이여야 합니다. < 1로 설정하면 백그라운드 캐시 정리가 더 일찍 트리거됩니다. |
DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET |
f64 | 0.7 | 캐시 정리는 적어도(1-DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET) 캐시 공간을 확보하려고 시도합니다. |
DATASET_MOUNT_READ_BLOCK_SIZE |
usize | 2MB | 스트리밍 읽기 블록 크기. 파일이 충분히 크면 퓨즈 요청 읽기 작업이 더 적은 경우에도 스토리지 및 캐시에서 최소 DATASET_MOUNT_READ_BLOCK_SIZE의 데이터를 요청합니다. |
DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT |
usize | 32 | 프리페치 블록 수(블록 k를 읽으면 블록 k+1, ..., k.+DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT의 백그라운드 프리페치가 트리거됨) |
DATASET_MOUNT_READ_THREADS |
usize | NUMBER_OF_CORES * 4 |
백그라운드 프리페치 스레드 수입니다. |
DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED |
bool | false | 블록 기반 캐싱을 사용하도록 설정합니다. |
DATASET_MOUNT_MEMORY_CACHE_SIZE |
usize | 128MB | 블록 기반 캐싱에만 적용됩니다. 사용할 수 있는 RAM 블록 기반 캐싱의 크기입니다. 값이 0이면 메모리 캐싱이 완전히 사용하지 않도록 설정됩니다. |
DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED |
bool | true | 블록 기반 캐싱에만 적용됩니다. true로 설정하면 블록 기반 캐싱이 로컬 하드 드라이브를 사용하여 블록을 캐시합니다. |
DATASET_MOUNT_BLOCK_FILE_CACHE_MAX_QUEUE_SIZE |
usize | 512MB | 블록 기반 캐싱에만 적용됩니다. 블록 기반 캐싱은 캐시된 블록을 백그라운드에서 로컬 디스크에 씁니다. 이 설정은 로컬 디스크 캐시로 플러시되기를 기다리는 블록을 저장하는 데 사용할 수 있는 메모리 탑재 양을 제어합니다. |
DATASET_MOUNT_BLOCK_FILE_CACHE_WRITE_THREADS |
usize | NUMBER_OF_CORES * 2 |
블록 기반 캐싱에만 적용됩니다. 블록 기반 캐싱이 컴퓨팅 대상의 로컬 디스크에 다운로드한 블록을 쓰는 데 사용하는 백그라운드 스레드 수입니다. |
DATASET_UNMOUNT_TIMEOUT_SECONDS |
u64 | 30 | 탑재 메시지 루프를 강제로 종료하기 전에 unmount가 보류 중인 모든 작업(예: 플러시 호출)을(정상적으로) 완료하는 데 걸리는 시간(초)입니다. |
작업에서 환경 변수를 설정하여 위의 기본값을 변경할 수 있습니다. 예를 들면 다음과 같습니다.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": True
}
job = command(
environment_variables=env_var
)
블록 기반 오픈 모드
블록 기반 열기 모드는 각 파일을 미리 정의된 크기의 블록으로 분할합니다(마지막 블록 제외). 지정된 위치의 읽기 요청은 스토리지에서 해당 블록을 요청하고, 요청한 데이터를 즉시 반환합니다. 또한 읽기는 여러 스레드(순차 읽기에 최적화됨)를 사용하여 N개의 다음 블록에 대한 백그라운드 프리페치를 트리거합니다. 다운로드된 블록은 2계층 캐시(RAM 및 로컬 디스크)에 캐시됩니다.
| 장점 | 단점 |
|---|---|
| 학습 스크립트에 대한 빠른 데이터 배달(아직 요청되지 않은 청크에 대한 차단 감소) | 임의 읽기는 앞으로 프리페치된 블록을 낭비할 수 있습니다. |
| 더 많은 작업이 백그라운드 스레드로 오프로드됩니다(프리페치/캐싱). 그런 다음 학습을 진행할 수 있습니다. | 로컬 디스크 캐시의 파일에서 직접 읽기(예: 전체 파일 캐시 모드)와 비교하여 캐시 간을 탐색하기 위한 오버헤드가 추가되었습니다. |
| 요청된 데이터(프리페칭 포함)만 스토리지에서 읽혀집니다. | |
| 충분히 작은 데이터의 경우 빠른 RAM 기반 캐시가 사용됩니다. |
블록 기반 오픈 모드를 사용하는 경우
임의의 파일 위치에서 빠른 읽기가 필요한 경우를 제외하는 대부분의 시나리오에 권장됩니다. 이러한 경우에는 전체 파일 캐시 열기 모드를 사용합니다.
전체 파일 캐시 오픈 모드
탑재 폴더 아래의 파일(예: f = open(path, args))을 전체 파일 모드로 열면 전체 파일이 디스크의 컴퓨팅 대상 캐시 폴더에 다운로드될 때까지 호출이 차단됩니다. 이후의 모든 읽기 호출은 캐시된 파일로 리디렉션되므로 스토리지 상호 작용이 필요하지 않습니다. 캐시에 현재 파일을 넣을 만큼 사용 가능한 공간이 충분하지 않으면 mount는 캐시에서 가장 최근에 사용된 파일을 삭제하여 정리를 시도합니다. 파일이 디스크에 맞지 않는 경우(캐시 설정과 관련하여) 데이터 런타임은 스트리밍 모드로 대체됩니다.
| 장점 | 단점 |
|---|---|
| 파일을 연 후에는 스토리지 안정성/처리량 종속성이 없습니다. | 파일 전체가 다운로드될 때까지 공개통화가 차단됩니다. |
| 빠른 임의 읽기(파일의 임의 위치에서 청크 읽기) | 파일의 일부가 필요하지 않은 경우에도 스토리지에서 전체 파일을 읽습니다. |
사용 시기
128MB를 초과하는 상대적으로 큰 파일에 대해 임의 읽기가 필요한 경우.
사용
작업에서 환경 변수 DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED를 false로 설정합니다.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False
}
job = command(
environment_variables=env_var
)
탑재: 파일 나열
수백만 개의 파일을 작업할 때 재귀 목록(예: ls -R /mnt/dataset/folder/)을 방지합니다. 재귀 목록은 부모 디렉터리의 디렉터리 콘텐츠를 나열하기 위해 많은 호출을 트리거합니다. 그런 다음 모든 자식 수준에서 내부의 각 디렉터리에 대해 별도의 재귀 호출이 필요합니다. 일반적으로 Azure Storage에서는 단일 목록 요청당 5000개의 요소만 반환되도록 허용합니다. 결과적으로 각각 10개의 파일이 포함된 100만 개의 폴더를 재귀적으로 나열하려면 스토리지에 대한 1,000,000 / 5000 + 1,000,000 = 1,000,200 요청이 필요합니다. 이에 비해 10,000개의 파일이 있는 1,000개의 폴더에는 재귀 목록을 저장하기 위해 1001개의 요청만 필요합니다.
Azure Machine Learning 탑재는 지연 방식으로 목록을 처리합니다. 따라서 많은 작은 파일을 나열하려면 전체 목록을 반환하는 클라이언트 라이브러리 호출(예: Python의 os.listdir()) 대신 반복 클라이언트 라이브러리 호출(예: Python의 os.scandir())을 사용하는 것이 좋습니다. 반복적인 클라이언트 라이브러리 호출은 생성기를 반환합니다. 즉, 전체 목록이 로드될 때까지 기다릴 필요가 없습니다. 그러면 더 빠르게 진행될 수 있습니다.
다음 표에서는 Python os.scandir() 및 os.listdir() 함수가 플랫 구조로 ~4M 파일이 포함된 폴더를 나열하는 데 필요한 시간을 비교합니다.
| 메트릭 | os.scandir() |
os.listdir() |
|---|---|---|
| 첫 번째 항목을 가져오는 데 걸리는 시간(초) | 0.67 | 553.79 |
| 처음 50,000개 항목을 가져오는 데 걸리는 시간(초) | 9.56 | 562.73 |
| 모든 항목을 가져오는 데 걸리는 시간(초) | 558.35 | 582.14 |
일반적인 시나리오에 대한 최적의 탑재 설정
특정 일반적인 시나리오의 경우 Azure Machine Learning 작업에서 설정해야 하는 최적의 탑재 설정을 보여 줍니다.
대용량 파일을 순차적으로 한 번 읽기(csv 파일의 라인 처리)
Azure Machine Learning 작업의 environment_variables 섹션에 다음 탑재 설정을 포함합니다.
참고 항목
서버리스 컴퓨팅을 사용하려면 이 코드에서 compute="cpu-cluster",를 삭제합니다.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
# Increase the number of blocks used for prefetch. This leads to use of more RAM (2 MB * #value set).
# Can adjust up and down for fine-tuning, depending on the actual data processing pattern.
# An optimal setting based on our test ~= the number of prefetching threads (#CPU_CORES * 4 by default)
"DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT": 80,
}
job = command(
environment_variables=env_var
)
여러 스레드에서 대용량 파일을 한 번 읽기(여러 스레드에서 분할된 csv 파일 처리)
Azure Machine Learning 작업의 environment_variables 섹션에 다음 탑재 설정을 포함합니다.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
여러 스레드에서 수백만 개의 작은 파일(이미지)을 한 번에 읽기(이미지에 대한 단일 epoch 학습)
Azure Machine Learning 작업의 environment_variables 섹션에 다음 탑재 설정을 포함합니다.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
여러 스레드에서 수백만 개의 작은 파일(이미지)을 여러 번 읽기(이미지에 대한 여러 epoch 학습)
Azure Machine Learning 작업의 environment_variables 섹션에 다음 탑재 설정을 포함합니다.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
}
job = command(
environment_variables=env_var
)
임의 검색으로 대용량 파일 읽기(예: 탑재된 폴더에서 파일 데이터베이스 제공)
Azure Machine Learning 작업의 environment_variables 섹션에 다음 탑재 설정을 포함합니다.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False, # Disable block-based caching
}
job = command(
environment_variables=env_var
)
데이터 로딩 병목 현상 진단 및 해결
Azure Machine Learning 작업이 데이터와 함께 실행되면 입력의 mode에 따라 스토리지에서 바이트를 읽고 컴퓨팅 대상 로컬 SSD 디스크에 캐시하는 방법이 결정됩니다. 다운로드 모드의 경우 사용자 코드가 실행을 시작하기 전에 모든 데이터가 디스크에 캐시됩니다. 따라서 병렬 스레드 수,
- 파일 수 등의 요소가
- 최대 다운로드
- 파일 크기
속도에 영향을 미칩니다. 탑재의 경우 데이터가 캐시되기 전에 사용자 코드가 파일을 열기 시작해야 합니다. 탑재 설정이 다르면 읽기 및 캐싱 동작이 달라집니다. 다양한 요인이 스토리지에서 데이터를 로드하는 속도에 영향을 미칩니다.
- 계산할 데이터 지역성: 스토리지와 컴퓨팅 대상 위치가 동일해야 합니다. 스토리지와 컴퓨팅 대상이 서로 다른 지역에 있으면 데이터가 지역 간에 전송되어야 하기 때문에 성능이 저하됩니다. 데이터가 컴퓨팅과 공동 배치되도록 하는 방법에 대한 자세한 내용은 데이터를 컴퓨팅과 공동 배치를 참조하세요.
- 컴퓨팅 대상 크기: 소규모 컴퓨팅은 더 큰 컴퓨팅 크기에 비해 코어 수가 적고(병렬 처리가 적음) 예상 네트워크 대역폭도 더 작습니다. 두 요소 모두 데이터 로딩 성능에 영향을 미칩니다.
- 예를 들어,
Standard_D2_v2(2개 코어, 1500Mbps NIC)과 같은 작은 VM 크기를 사용하고 50,000MB(50GB)의 데이터를 로드하려고 시도하는 경우 달성 가능한 최상의 데이터 로드 시간은 ~270초입니다.(NIC가 187.5MB/s 처리량으로 포화되었다고 가정). 반면,Standard_D5_v2(16개 코어, 12,000Mbps)은 동일한 데이터를 33초 안에 로드합니다(NIC가 1500MB/s 처리량으로 포화된다고 가정).
- 예를 들어,
- 스토리지 계층: LLM(대규모 언어 모델)을 포함한 대부분의 시나리오에서 표준 스토리지는 최고의 비용/성능 프로필을 제공합니다. 그러나 작은 파일이 많이 있는 경우에는 프리미엄 스토리지가 더 나은 비용 대비 성능 프로필을 제공합니다. 자세한 내용은 Azure Storage 옵션을 참조하세요.
- 스토리지 부하: 스토리지 계정의 부하가 높은 경우(예: 데이터를 요청하는 클러스터의 많은 GPU 노드) 스토리지의 송신 용량에 도달할 위험이 있습니다. 자세한 내용은 스토리지 부하를 참조하세요. 병렬로 액세스해야 하는 작은 파일이 많은 경우 스토리지 요청 제한에 도달할 수 있습니다. 표준 스토리지 계정의 대상 크기 조정에서 송신 용량 및 스토리지 요청 제한에 대한 최신 정보를 참조하세요.
- 사용자 코드의 데이터 액세스 패턴: 탑재 모드를 사용하면 코드의 열기/읽기 작업을 기반으로 데이터를 가져옵니다. 예를 들어, 대용량 파일의 임의 섹션을 읽을 때 탑재의 기본 데이터 프리페치 설정으로 인해 읽히지 않는 블록이 다운로드될 수 있습니다. 최대 처리량에 도달하려면 일부 설정을 조정해야 할 수도 있습니다. 자세한 내용은 일반적인 시나리오에 대한 최적의 탑재 설정을 참조하세요.
로그를 사용하여 문제 진단
작업에서 데이터 런타임 로그에 액세스하려면 다음 안내를 따릅니다.
- 작업 페이지에서 출력+로그 탭을 선택합니다.
- system_logs 폴더와 data_capability 폴더를 차례로 선택합니다.
- 두 개의 로그 파일이 표시됨:
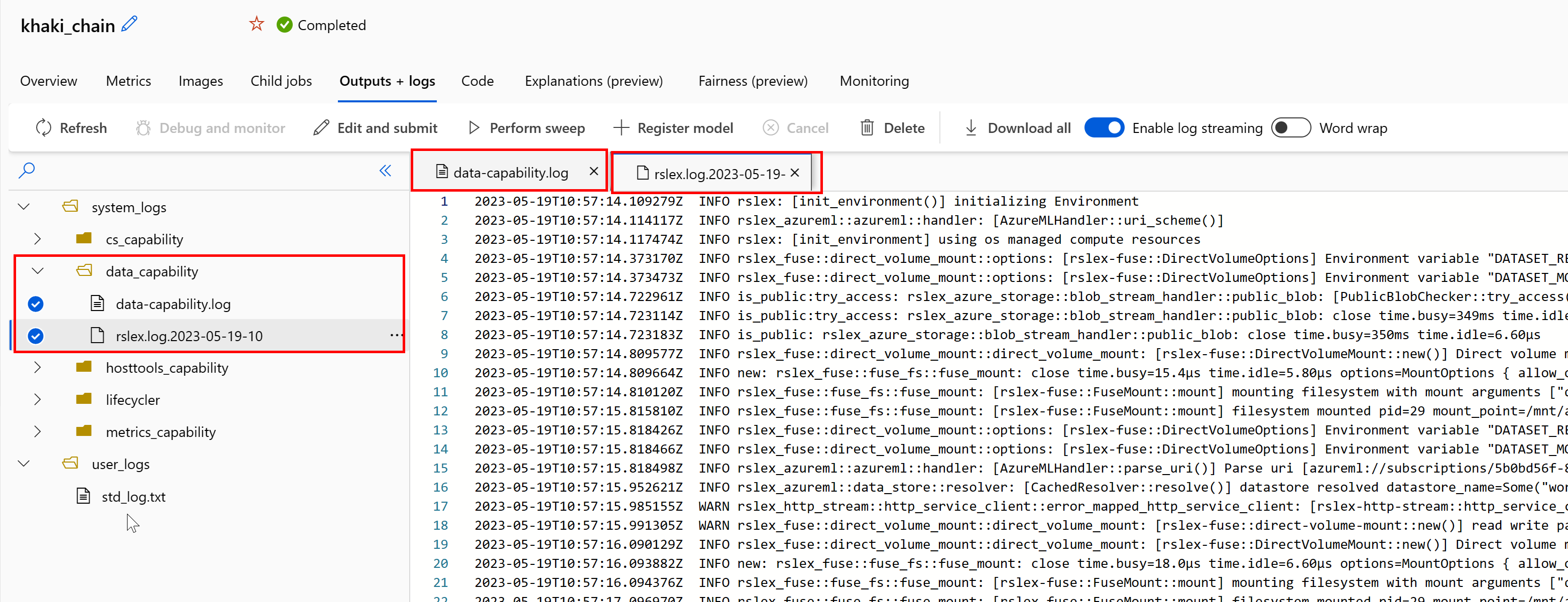

로그 파일 data-capability.log는 주요 데이터 로드 작업에 소요된 시간에 대한 상위 수준 정보를 표시합니다. 예를 들어, 데이터를 다운로드하면 런타임은 다운로드 작업 시작 및 종료 시간을 기록합니다.
INFO 2023-05-18 17:14:47,790 sdk_logger.py:44 [28] - ActivityStarted, download
INFO 2023-05-18 17:14:50,295 sdk_logger.py:44 [28] - ActivityCompleted: Activity=download, HowEnded=Success, Duration=2504.39 [ms]
다운로드 처리량이 VM 크기에 대해 예상되는 네트워크 대역폭의 일부인 경우 로그 파일 rslex.log.<TIMESTAMP>를 검사할 수 있습니다. 이 파일에는 Rust 기반 런타임의 모든 세분화된 로깅이 포함되어 있습니다. 예를 들어 병렬 처리 로깅은 다음과 같습니다.
2023-05-18T14:08:25.388670Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce:get_iter: rslex::prefetching: close time.busy=23.2µs time.idle=1.90µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0 index=0
2023-05-18T14:08:25.388731Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce: rslex::dataset_crossbeam: close time.busy=90.9µs time.idle=9.10µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0
2023-05-18T14:08:25.388762Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:combine: rslex::dataset_crossbeam: close time.busy=1.22ms time.idle=9.50µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4
rslex.log 파일은 탑재 또는 다운로드 모드 선택 여부에 관계없이 모든 파일 복사에 대한 세부 정보를 제공합니다. 또한 사용되는 설정(환경 변수)에 대해서도 설명합니다. 디버깅을 시작하려면 일반적인 시나리오에 대한 최적의 탑재 설정을 지정했는지 확인합니다.
Azure Storage 모니터링
Azure Portal에서 스토리지 계정을 선택한 다음 메트릭을 선택하여 스토리지 메트릭을 확인할 수 있습니다.

그런 다음 SuccessServerLatency를 사용하여 SuccessE2ELatency를 표시합니다. 메트릭이 높은 SuccessE2ELatency와 낮은 SuccessServerLatency를 표시하는 경우 사용 가능한 스레드가 제한되어 있거나 CPU, 메모리 또는 네트워크 대역폭과 같은 리소스가 부족한 경우 다음을 수행해야 합니다.
- Azure Machine Learning 스튜디오의 모니터링 보기를 사용하여 작업의 CPU 및 메모리 사용률을 확인합니다. CPU와 메모리가 부족한 경우 컴퓨팅 대상 VM 크기를 늘리는 것이 좋습니다.
- 다운로드 중이고 CPU와 메모리를 활용하지 않는 경우
RSLEX_DOWNLOADER_THREADS를 늘리는 것이 좋습니다. 탑재를 사용하는 경우 더 많은 프리페치를 수행하려면DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT를 늘려야 하고, 더 많은 읽기 스레드를 위해서는DATASET_MOUNT_READ_THREADS를 늘려야 합니다.
메트릭에 낮은 SuccessE2ELatency 및 낮은 SuccessServerLatency가 표시되지만 클라이언트 대기 시간이 긴 경우 서비스에 도달하는 스토리지 요청이 지연된 것입니다. 다음 사항을 확인해야 합니다.
- 탑재/다운로드에 사용되는 스레드 수(
DATASET_MOUNT_READ_THREADS/RSLEX_DOWNLOADER_THREADS)가 컴퓨팅 대상에서 사용 가능한 코어 수에 비해 너무 낮게 설정되었는지 여부. 설정이 너무 낮으면 스레드 수를 늘립니다. - 다운로드 다시 시도 횟수(
AZUREML_DATASET_HTTP_RETRY_COUNT)가 너무 높게 설정되었는지 여부. 그렇다면 다시 시도 횟수를 줄입니다.
작업 중 디스크 사용량 모니터링
Azure Machine Learning 스튜디오에서 작업 실행 중에 컴퓨팅 대상 디스크 IO 및 사용량을 모니터링할 수도 있습니다. 작업으로 이동하여 모니터링 탭을 선택합니다. 이 탭에서는 30일 단위로 작업 리소스에 대한 인사이트를 제공합니다. 예시:

참고 항목
작업 모니터링은 Azure Machine Learning이 관리하는 컴퓨팅 리소스만 지원합니다. 런타임이 5분 미만인 작업은 데이터가 부족하여 이 보기를 채울 수 없습니다.
Azure Machine Learning 데이터 런타임은 컴퓨팅을 정상 상태로 유지하기 위해 디스크 공간의 마지막 RESERVED_FREE_DISK_SPACE바이트를 사용하지 않습니다(기본값은 150MB). 디스크가 가득 찬 경우 코드는 파일을 출력으로 선언하지 않고 디스크에 파일을 쓰고 있습니다. 따라서 코드를 확인하여 데이터가 임시 디스크에 잘못 기록되지 않았는지 확인합니다. 임시 디스크에 파일을 써야 하는데 해당 리소스가 꽉 차는 경우 다음을 고려합니다.
- 임시 디스크가 더 큰 VM 크기로 VM 크기를 늘립니다.
- 캐시된 데이터에 TTL(
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL)을 설정하여 디스크에서 데이터를 제거합니다.
컴퓨팅을 통해 데이터를 같은 위치에 배치
주의
스토리지와 컴퓨팅이 서로 다른 지역에 있으면 데이터가 지역 간에 전송되어야 하기 때문에 성능이 저하됩니다. 이로 인해 비용이 증가합니다. 스토리지 계정과 컴퓨팅 리소스가 동일한 지역에 있는지 확인합니다.
데이터와 Azure Machine Learning 작업 영역이 서로 다른 지역에 저장되어 있는 경우 azcopy 유틸리티를 사용하여 동일한 지역의 스토리지 계정에 데이터를 복사하는 것이 좋습니다. AzCopy는 서버 간 API를 사용하므로 스토리지 서버 간에 데이터가 직접 복사됩니다. 이 복사 작업은 컴퓨터의 네트워크 대역폭을 사용하지 않습니다. AZCOPY_CONCURRENCY_VALUE 환경 변수를 사용하여 이러한 작업의 처리량을 늘릴 수 있습니다. 자세히 알아보려면 동시성 향상을 참조하세요.
저장 부하
단일 스토리지 계정은 다음과 같은 경우 부하가 높을 때 제한될 수 있습니다.
- 작업에서 많은 GPU 노드를 사용합니다.
- 스토리지 계정에 작업을 실행할 때 데이터에 액세스하는 동시 사용자/앱이 많이 있습니다.
이 섹션에서는 제한이 워크로드에 문제가 될 수 있는지 확인하기 위한 계산과 제한 감소에 접근하는 방법을 보여 줍니다.
대역폭 제한 계산
Azure Storage 계정의 기본 송신 한도는 120Gbit/s입니다. Azure VM에는 서로 다른 네트워크 대역폭이 있으며 이는 스토리지의 최대 기본 송신 용량에 도달하는 데 필요한 이론적인 컴퓨팅 노드 수에 영향을 미칩니다.
| 크기 | GPU 카드 | vCPU | 메모리: GiB | 임시 스토리지(SSD) GiB | GPU 카드 수 | GPU 메모리: GiB | 예상 네트워크 대역폭(Gbit/s) | 스토리지 계정 송신 기본 최댓값(Gbit/s)* | 기본 송신 용량에 도달하는 노드 수 |
|---|---|---|---|---|---|---|---|---|---|
| Standard_ND96asr_v4 | A100 | 96 | 900 | 6000 | 8 | 40 | 24 | 120 | 5 |
| Standard_ND96amsr_A100_v4 | A100 | 96 | 1900 | 6400 | 8 | 80 | 24 | 120 | 5 |
| Standard_NC6s_v3 | V100 | 6 | 112 | 736 | 1 | 16 | 24 | 120 | 5 |
| Standard_NC12s_v3 | V100 | 12 | 224 | 1474 | 2 | 32 | 24 | 120 | 5 |
| Standard_NC24s_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC24rs_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC4as_T4_v3 | T4 | 4 | 28 | 180 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC8as_T4_v3 | T4 | 8 | 56 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC16as_T4_v3 | T4 | 16 | 110 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC64as_T4_v3 | T4 | 64 | 440 | 2880 | 4 | 64 | 32 | 120 | 3 |
A100/V100 SKU 모두 노드당 최대 네트워크 대역폭이 24Gbit/s입니다. 단일 계정에서 데이터를 읽는 각 노드가 이론적 최댓값인 24Gbit/s에 가깝게 읽을 수 있다면 송신 용량은 5개 노드에서 발생합니다. 6개 이상의 컴퓨팅 노드를 사용하면 모든 노드에서 데이터 처리량이 저하되기 시작합니다.
Important
워크로드에 A100/V100의 노드가 6개 넘게 필요하거나 스토리지의 기본 송신 용량(120Gbit/s)을 초과할 것으로 생각되는 경우 Azure Portal을 통해 지원팀에 문의하여 스토리지 송신 한도 증가를 요청합니다.
여러 스토리지 계정에 걸쳐 크기 조정
스토리지의 최대 송신 용량을 초과하거나 요청률 한도에 도달할 수 있습니다. 이러한 문제가 발생하면 먼저 지원팀에 문의하여 스토리지 계정에 대한 이러한 한도를 늘리는 것이 좋습니다.
최대 송신 용량이나 요청 속도 제한을 늘릴 수 없는 경우 여러 스토리지 계정에 걸쳐 데이터를 복제하는 것을 고려해야 합니다. Azure Data Factory, Azure Storage Explorer 또는 azcopy를 사용하여 여러 계정에 데이터를 복사하고 학습 작업에 모든 계정을 탑재합니다. 탑재에서 액세스된 데이터만 다운로드됩니다. 따라서 학습 코드는 환경 변수에서 RANK를 읽고 여러 입력 탑재 중 읽을 대상을 선택할 수 있습니다. 작업 정의는 스토리지 계정의 목록을 전달합니다.
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
그러면 학습 Python 코드는 RANK를 사용하여 해당 노드와 관련된 스토리지 계정을 가져올 수 있습니다.
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
작은 파일이 많은 문제
스토리지에서 파일을 읽는 작업에는 각 파일에 대한 요청이 포함됩니다. 파일당 요청 수는 파일 크기와 파일 읽기를 처리하는 소프트웨어 설정에 따라 다릅니다.
일반적으로 파일은 1~4MB 크기의 블록으로 읽습니다. 블록보다 작은 파일은 단일 요청(GET file.jpg 0-4MB)으로 읽고, 블록보다 큰 파일은 블록당 하나의 요청(GET file.jpg 0-4MB, GET file.jpg 4-8 MB)을 갖습니다. 다음 표에서는 4MB 블록보다 작은 파일이 큰 파일에 비해 더 많은 스토리지 요청을 발생시킨다는 것을 보여 줍니다.
| #개의 파일 | 파일 크기 | 총 데이터 크기 | 블록 크기 | # 저장 요청 |
|---|---|---|---|---|
| 2,000,000 | 500KB | 1TB | 4MB | 2,000,000 |
| 1,000 | 1GB | 1TB | 4MB | 256,000 |
작은 파일의 경우 대기 시간 간격에는 주로 데이터 전송 대신 스토리지에 대한 요청 처리가 포함됩니다. 따라서 파일 크기를 늘리기 위해 다음 권장 사항을 제공합니다.
- 구조화되지 않은 데이터(이미지, 텍스트, 동영상 등)의 경우 작은 파일을 함께 보관(zip/tar)하여 여러 청크로 읽을 수 있는 더 큰 파일로 저장합니다. 이러한 대용량 보관 파일은 컴퓨팅 리소스에서 열 수 있으며 PyTorch Archive DataPipes는 더 작은 파일을 추출할 수 있습니다.
- 구조화된 데이터(CSV, Parquet 등)의 경우 ETL 프로세스를 검사하여 파일을 통합하여 크기를 늘리는지 확인합니다. Spark에는 파일 크기를 늘리는 데 도움이 되는
repartition()및coalesce()메서드가 있습니다.
파일 크기를 늘릴 수 없는 경우 Azure Storage 옵션을 살펴봅니다.
Azure Storage 옵션
Azure Storage는 표준과 프리미엄의 두 가지 계층을 제공합니다.
| 스토리지 | 시나리오 |
|---|---|
| Azure Blob - 표준(HDD) | 데이터는 이미지, 동영상 등 더 큰 Blob으로 구성됩니다. |
| Azure Blob - 프리미엄(SSD) | 높은 트랜잭션 속도, 더 작은 개체 또는 지속적으로 낮은 스토리지 대기 시간 요구 사항 |
팁
작은 파일(KB 크기)이 “많은” 경우 저장 비용이 GPU 컴퓨팅 실행 비용보다 낮기 때문에 프리미엄(SSD)을 사용하는 것이 좋습니다.
V1 데이터 자산 읽기
이 섹션에서는 V2 작업에서 V1 FileDataset 및 TabularDataset 데이터 엔터티를 읽는 방법을 간략하게 설명합니다.
FileDataset 읽기
Input 개체에서 type을 AssetTypes.MLTABLE로 지정하고 mode를 InputOutputModes.EVAL_MOUNT로 지정합니다.
참고 항목
서버리스 컴퓨팅을 사용하려면 이 코드에서 compute="cpu-cluster",를 삭제합니다.
MLClient 개체, MLClient 개체 초기화 옵션 및 작업 영역에 연결하는 방법에 대한 자세한 내용은 작업 영역에 연결을 참조하세요.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
TabularDataset 읽기
Input 개체에서 type을 AssetTypes.MLTABLE로 지정하고 mode를 InputOutputModes.DIRECT로 지정합니다.
참고 항목
서버리스 컴퓨팅을 사용하려면 이 코드에서 compute="cpu-cluster",를 삭제합니다.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint