Azure Machine Learning에서 Spark 작업 제출
적용 대상: Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
Azure CLI ml 확장 v2(현재)Python SDK azure-ai-ml v2(현재)
Azure Machine Learning은 독립 실행형 기계 학습 작업의 제출과 여러 기계 학습 워크플로 단계를 포함하는 기계 학습 파이프라인 만들기를 지원합니다. Azure Machine Learning은 독립 실행형 Spark 작업 만들기와 Azure Machine Learning 파이프라인에서 사용할 수 있는 재사용 가능한 Spark 구성 요소 만들기를 모두 처리합니다. 이 문서에서는 다음을 사용하여 Spark 작업을 제출하는 방법을 알아봅니다.
- Azure Machine Learning 스튜디오 UI
- Azure Machine Learning CLI
- Azure Machine Learning SDK
Azure Machine Learning의 Apache Spark 개념에 대한 자세한 내용은 이 리소스를 참조하세요.
필수 조건
적용 대상:Azure CLI ml 확장 v2(현재)
- Azure 구독. Azure 구독이 아직 없는 경우 시작하기 전에 체험 계정을 만듭니다.
- Azure Machine Learning 작업 영역 작업 영역 리소스 만들기를 참조하세요.
- Azure Machine Learning 컴퓨팅 인스턴스를 만듭니다.
- Azure Machine Learning CLI를 설치합니다.
- (선택 사항): Azure Machine Learning 작업 영역의 연결된 Synapse Spark 풀.
참고 항목
- Azure Machine Learning 서버리스 Spark 컴퓨팅 및 연결된 Synapse Spark 풀을 사용하는 동안 리소스 액세스에 대해 자세히 알아보려면 Spark 작업에 대한 리소스 액세스 보장을 참조하세요.
- Azure Machine Learning은 모든 사용자가 컴퓨팅 할당량에 액세스하여 제한된 시간 동안 테스트를 수행할 수 있는 공유 할당량 풀을 제공합니다. 서버리스 Spark 컴퓨팅을 사용하는 경우 Azure Machine Learning을 사용하면 이 공유 할당량에 잠시 액세스할 수 있습니다.
CLI v2를 사용하여 사용자가 할당한 관리 ID 연결
- 작업 영역에 연결해야 하는 사용자가 할당한 관리 ID를 정의하는 YAML 파일을 만듭니다.
identity: type: system_assigned,user_assigned tenant_id: <TENANT_ID> user_assigned_identities: '/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>': {} --file매개 변수와 함께az ml workspace update명령에서 YAML 파일을 사용하여 사용자가 할당한 관리 ID를 연결합니다.az ml workspace update --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --name <AML_WORKSPACE_NAME> --file <YAML_FILE_NAME>.yaml
ARMClient를 사용하여 사용자가 할당한 관리 ID 연결
- Azure Resource Manager API를 호출하는 간단한 명령줄 도구인
ARMClient를 설치합니다. - 작업 영역에 연결해야 하는 사용자가 할당한 관리 ID를 정의하는 JSON 파일을 만듭니다.
{ "properties":{ }, "location": "<AZURE_REGION>", "identity":{ "type":"SystemAssigned,UserAssigned", "userAssignedIdentities":{ "/subscriptions/<SUBSCRIPTION_ID/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.ManagedIdentity/userAssignedIdentities/<AML_USER_MANAGED_ID>": { } } } } - 사용자 할당 관리 ID를 작업 영역에 연결하려면 PowerShell 프롬프트 또는 명령 프롬프트에서 다음 명령을 실행합니다.
armclient PATCH https://management.azure.com/subscriptions/<SUBSCRIPTION_ID>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.MachineLearningServices/workspaces/<AML_WORKSPACE_NAME>?api-version=2022-05-01 '@<JSON_FILE_NAME>.json'
참고 항목
- Spark 작업을 성공적으로 실행하려면 데이터 입력 및 출력에 사용되는 Azure 스토리지 계정에서 기여자 및 Storage Blob 데이터 기여자 역할을 Spark 작업에서 사용하는 ID에 할당합니다.
- 연결된 Synapse Spark 풀을 사용하여 Spark 작업을 성공적으로 실행하려면 Azure Synapse 작업 영역에서 공용 네트워크 액세스를 사용하도록 설정해야 합니다.
- 연결된 Synapse Spark 풀에서 Synapse Spark 풀을 가리키는 경우 데이터 액세스를 보장하기 위해 관리형 가상 네트워크가 연결된 Azure Synapse 작업 영역에서 스토리지 계정에 대한 관리형 프라이빗 엔드포인트를 구성해야 합니다.
- 서버리스 Spark 컴퓨팅은 Azure Machine Learning 관리형 가상 네트워크를 지원합니다. 서버리스 Spark 컴퓨팅을 위해 관리 네트워크가 프로비전된 경우 데이터 액세스를 보장하기 위해 스토리지 계정에 해당하는 프라이빗 엔드포인트도 프로비전되어야 합니다.
독립 실행형 Spark 작업 제출
Python 스크립트 매개 변수화에 필요한 변경을 수행한 후 대화형 데이터 랭글링에서 개발한 Python 스크립트를 사용하여 더 많은 양의 데이터를 처리하는 일괄 처리 작업을 제출할 수 있습니다. 간단한 데이터 랭글링 일괄 작업은 독립 실행형 Spark 작업으로 제출할 수 있습니다.
Spark 작업에는 대화형 데이터 랭글링서 개발된 Python 코드를 수정하여 개발할 수 있는 인수를 사용하는 Python 스크립트가 필요합니다. 아래는 샘플 Python 스크립트입니다.
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
참고 항목
이 Python 코드 샘플에서는 pyspark.pandas를 사용합니다. Spark 런타임 버전 3.2 이상에서만 이를 지원합니다.
위의 스크립트는 각각 입력 데이터의 경로와 출력 폴더의 경로를 전달하는 --titanic_data 인수와 --wrangled_data 인수를 사용합니다.
적용 대상:Azure CLI ml 확장 v2(현재)
작업을 만들려면 독립 실행형 Spark 작업을 YAML 사양 파일로 정의할 수 있습니다. 이 파일은 --file 매개 변수와 함께 az ml job create 명령에서 사용할 수 있습니다. YAML 파일에서 다음 속성을 정의합니다.
Spark 작업 사양의 YAML 속성
type-spark로 설정합니다.code- 이 작업의 소스 코드와 스크립트를 포함하는 폴더 위치를 정의합니다.entry- 작업의 진입점을 정의합니다. 다음 속성 중 하나를 포함해야 합니다.file- 작업의 진입점 역할을 하는 Python 스크립트의 이름을 정의합니다.
py_files- 작업을 성공적으로 실행하기 위해PYTHONPATH에 배치할.zip,.egg또는.py파일 목록을 정의합니다. 이 속성은 선택 사항입니다.jars- 작업을 성공적으로 실행하기 위해 Spark 드라이버에 포함할.jar파일 목록과CLASSPATH실행기를 정의합니다. 이 속성은 선택 사항입니다.files- 작업을 성공적으로 실행하기 위해 각 실행기의 작업 디렉터리에 복사해야 하는 파일 목록을 정의합니다. 이 속성은 선택 사항입니다.archives- 작업을 성공적으로 실행하기 위해 각 실행기의 작업 디렉터리로 추출해야 하는 보관 목록을 정의합니다. 이 속성은 선택 사항입니다.conf- 다음 Spark 드라이버 및 실행기 속성을 정의합니다.spark.driver.cores: Spark 드라이버의 코어 수입니다.spark.driver.memory: Spark 드라이버에 할당된 메모리(GB)입니다.spark.executor.cores: Spark 실행기의 코어 수입니다.spark.executor.memory: Spark 실행기에 할당된 메모리(GB)입니다.spark.dynamicAllocation.enabled-True또는False로 설정하여 실행기를 동적으로 할당할 것인지 여부를 결정할 수 있습니다.- 실행기를 동적으로 할당하도록 설정하는 경우 다음 속성을 정의합니다.
spark.dynamicAllocation.minExecutors- 동적으로 할당하기 위한 최소 Spark 실행기 인스턴스 수입니다.spark.dynamicAllocation.maxExecutors- 동적으로 할당하기 위한 최대 Spark 실행기 인스턴스 수입니다.
- 실행기를 동적으로 할당하지 않도록 설정하는 경우 다음 속성을 정의합니다.
spark.executor.instances- Spark 실행기 인스턴스 수입니다.
environment- 작업을 실행할 Azure Machine Learning 환경입니다.args- 작업 진입점 Python 스크립트에 전달해야 하는 명령줄 인수입니다. 예제는 여기에 제공된 YAML 사양 파일을 참조하세요.resources- 이 속성은 Azure Machine Learning 서버리스 Spark 컴퓨팅에서 사용할 리소스를 정의합니다. 다음 속성을 사용합니다.instance_type- Spark 풀에 사용할 컴퓨팅 인스턴스 유형입니다. 현재 지원되는 인스턴스 유형은 다음과 같습니다.standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
runtime_version- Spark 런타임 버전을 정의합니다. 현재 지원되는 Spark 런타임 버전은 다음과 같습니다.3.23.3Important
Apache Spark용 Azure Synapse 런타임: 공지 사항
- Apache Spark 3.2에 대한 Azure Synapse 런타임:
- EOLA 공지 사항 날짜: 2023년 7월 8일
- 지원 종료 날짜: 2024년 7월 8일. 이 날짜 이후에는 런타임이 사용하지 않도록 설정됩니다.
- 지속적인 지원과 최적의 성능을 위해서는 Apache Spark 3.3으로 마이그레이션하는 것이 좋습니다.
- Apache Spark 3.2에 대한 Azure Synapse 런타임:
예를 들면 다음과 같습니다.
resources: instance_type: standard_e8s_v3 runtime_version: "3.3"compute- 이 속성은 다음 예제와 같이 연결된 Synapse Spark 풀의 이름을 정의합니다.compute: mysparkpoolinputs- 이 속성은 Spark 작업의 입력을 정의합니다. Spark 작업의 입력은 리터럴 값이거나 파일 또는 폴더에 저장된 데이터입니다.- 리터럴 값은 숫자, 부울 값 또는 문자열입니다. 다음은 몇 가지 예제입니다.
inputs: sampling_rate: 0.02 # a number hello_number: 42 # an integer hello_string: "Hello world" # a string hello_boolean: True # a boolean value - 파일 또는 폴더에 저장된 데이터는 다음 속성을 사용하여 정의해야 합니다.
type- 이 속성은 입력 데이터가 각각 파일 또는 폴더에 포함되는uri_file또는uri_folder로 설정할 수 있습니다.path- 입력 데이터의 URI(예:azureml://,abfss://또는wasbs://)입니다.mode– 이 속성을direct로 설정합니다. 다음 샘플에서는$${inputs.titanic_data}}라고 할 수 있는 작업 입력의 정의를 보여줍니다.inputs: titanic_data: type: uri_file path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv mode: direct
- 리터럴 값은 숫자, 부울 값 또는 문자열입니다. 다음은 몇 가지 예제입니다.
outputs- 이 속성은 Spark 작업 출력을 정의합니다. Spark 작업의 출력은 다음 세 가지 속성을 사용하여 정의된 파일 또는 폴더 위치에 기록할 수 있습니다.type- 이 속성은 출력 데이터를 각각 파일 또는 폴더에 쓰는uri_file또는uri_folder로 설정할 수 있습니다.path- 이 속성은 출력 위치 URI(예:azureml://,abfss://또는wasbs://)를 정의합니다.mode– 이 속성을direct로 설정합니다. 다음 샘플에서는${{outputs.wrangled_data}}라고 할 수 있는 작업 출력의 정의를 보여줍니다.outputs: wrangled_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/data/wrangled/ mode: direct
identity- 이 선택적 속성은 이 작업을 제출하는 데 사용되는 ID를 정의합니다. 가능한 값은user_identity및managed입니다. YAML 사양이 ID를 정의하지 않으면 Spark 작업은 기본 ID를 사용합니다.
독립 실행형 Spark 작업
이 예제 YAML 사양은 독립 실행형 Spark 작업을 보여줍니다. Azure Machine Learning 서버리스 Spark 컴퓨팅을 사용합니다.
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.3"
참고 항목
연결된 Synapse Spark 풀을 사용하려면 이전에 표시된 샘플 YAML 사양 파일에서 resources 속성 대신 compute 속성을 정의합니다.
이전에 표시된 YAML 파일을 az ml job create 명령에 --file 매개 변수와 함께 사용하여 다음과 같이 독립 실행형 Spark 작업을 만들 수 있습니다.
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
위의 명령은 다음 위치에서 실행할 수 있습니다.
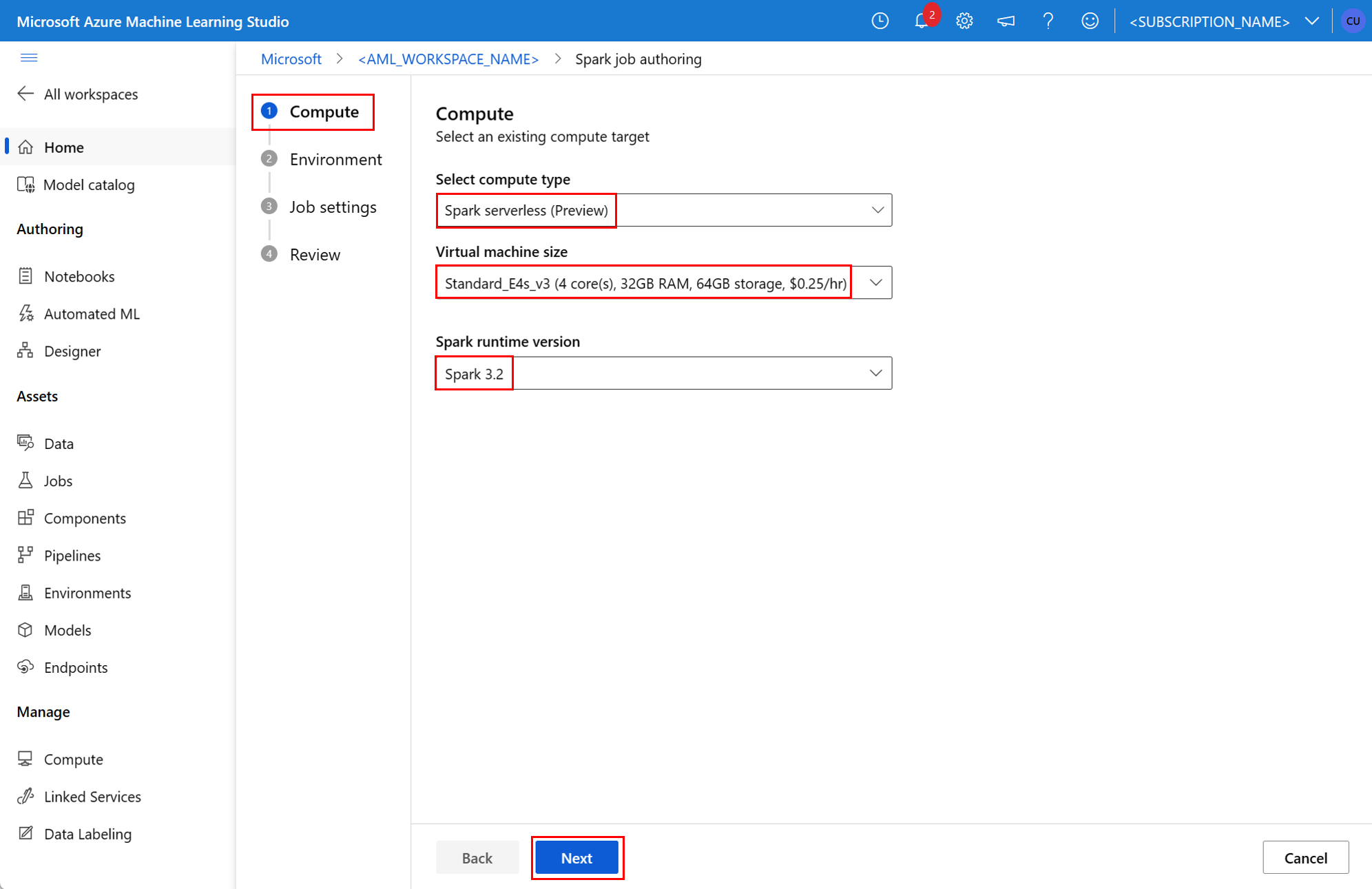
파이프라인 작업의 Spark 구성 요소
Spark 구성 요소는 여러 Azure Machine Learning 파이프라인에서 동일한 구성 요소를 파이프라인 단계로 사용할 수 있는 유연성을 제공합니다.
적용 대상:Azure CLI ml 확장 v2(현재)
Spark 구성 요소에 대한 YAML 구문은 Spark 작업 사양에 대한 YAML 구문과 대부분 비슷합니다. 이러한 속성은 다음과 같이 Spark 구성 요소 YAML 사양에서 다르게 정의됩니다.
name- Spark 구성 요소의 이름입니다.version- Spark 구성 요소의 버전입니다.display_name- UI 및 다른 곳에 표시할 Spark 구성 요소의 이름입니다.description- 구성 요소에 대한 설명입니다.inputs- 이 속성은path속성을 정의하지 않는다는 점을 제외하고는 Spark 작업 사양에 대한 YAML 구문에 설명된inputs속성과 비슷합니다. 이 코드 조각은 Spark 구성 요소inputs속성의 예를 보여줍니다.inputs: titanic_data: type: uri_file mode: directoutputs- 이 속성은path속성을 정의하지 않는다는 점을 제외하고는 Spark 작업 사양에 대한 YAML 구문에 설명된outputs속성과 비슷합니다. 이 코드 조각은 Spark 구성 요소outputs속성의 예를 보여줍니다.outputs: wrangled_data: type: uri_folder mode: direct
참고 항목
Spark 구성 요소는 identity, compute 또는 resources 속성을 정의하지 않습니다. 파이프라인 YAML 사양 파일은 이러한 속성을 정의합니다.
이 YAML 사양 파일은 다음과 같은 Spark 구성 요소의 예를 제공합니다.
$schema: http://azureml/sdk-2-0/SparkComponent.json
name: titanic_spark_component
type: spark
version: 1
display_name: Titanic-Spark-Component
description: Spark component for Titanic data
code: ./src
entry:
file: titanic.py
inputs:
titanic_data:
type: uri_file
mode: direct
outputs:
wrangled_data:
type: uri_folder
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.dynamicAllocation.enabled: True
spark.dynamicAllocation.minExecutors: 1
spark.dynamicAllocation.maxExecutors: 4
위의 YAML 사양 파일에 정의된 Spark 구성 요소는 Azure Machine Learning 파이프라인 작업에 사용할 수 있습니다. 파이프라인 작업을 정의하는 YAML 구문에 대한 자세한 내용은 파이프라인 작업 YAML 스키마를 참조하세요. 이 예에서는 Spark 구성 요소와 Azure Machine Learning 서버리스 Spark 컴퓨팅이 포함된 파이프라인 작업에 대한 YAML 사양 파일을 보여 줍니다.
$schema: http://azureml/sdk-2-0/PipelineJob.json
type: pipeline
display_name: Titanic-Spark-CLI-Pipeline
description: Spark component for Titanic data in Pipeline
jobs:
spark_job:
type: spark
component: ./spark-job-component.yaml
inputs:
titanic_data:
type: uri_file
path: azureml://datastores/workspaceblobstore/paths/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: azureml://datastores/workspaceblobstore/paths/data/wrangled/
mode: direct
identity:
type: managed
resources:
instance_type: standard_e8s_v3
runtime_version: "3.3"
참고 항목
연결된 Synapse Spark 풀을 사용하려면 위에 표시된 샘플 YAML 사양 파일에서 resources 속성 대신 compute 속성을 정의합니다.
위의 YAML 사양 파일은 다음과 같이 az ml job create 명령에서 --file 매개 변수를 사용하여 파이프라인 작업을 만드는 데 사용할 수 있습니다.
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
위의 명령은 다음 위치에서 실행할 수 있습니다.
Spark 작업 문제 해결
Spark 작업 문제를 해결하려면 Azure Machine Learning 스튜디오에서 해당 작업에 대해 생성된 로그에 액세스할 수 있습니다. Spark 작업 로그를 보려면 다음 안내를 따릅니다.
- Azure Machine Learning 스튜디오 UI의 왼쪽 패널에서 작업으로 이동합니다.
- 모든 작업 탭을 선택합니다.
- 작업의 표시 이름 값을 선택합니다.
- 작업 세부 정보 페이지에서 출력 + 로그 탭을 선택합니다.
- 파일 탐색기에서 logs 폴더를 확장한 다음 azureml 폴더를 확장합니다.
- driver 및 library Manager 폴더 내의 Spark 작업 로그에 액세스합니다.
참고 항목
Notebook 세션에서 대화형 데이터 랭글링 중에 만들어진 Spark 작업 문제를 해결하려면 Notebook UI 오른쪽 상단에 있는 작업 세부 정보를 선택합니다. 대화형 Notebook 세션의 Spark 작업은 실험 이름 notebook-runs로 만들어집니다.