Azure Machine Learning의 실험 및 작업(또는 실행)은 MLflow를 사용하여 쿼리할 수 있습니다. 학습 작업 내에서 발생하는 작업을 관리하기 위해 특정 SDK를 설치할 필요가 없으므로 클라우드별 종속성을 제거하여 로컬 실행과 클라우드 간에 보다 원활한 전환이 가능합니다. 이 문서에서는 Python에서 Azure Machine Learning 및 MLflow SDK를 사용하여 작업 영역에서 실험 및 실행을 쿼리하고 비교하는 방법을 알아봅니다.
MLflow를 사용하면 다음을 수행할 수 있습니다.
- 작업 영역에서 실험을 만들고, 쿼리하고, 삭제하고, 검색합니다.
- 작업 영역에서 실행을 쿼리하고, 삭제하고, 검색합니다.
- 실행에서 메트릭, 매개 변수, 아티팩트 및 모델을 추적하고 검색합니다.
Azure Machine Learning에 연결된 경우 MLflow 오픈 소스와 MLflow를 자세히 비교하려면 Azure Machine Learning의 실행 및 실험 쿼리를 위한 지원 행렬을 참조하세요.
참고 항목
Azure Machine Learning Python SDK v2는 네이티브 로깅 또는 추적 기능을 제공하지 않습니다. 이는 로깅뿐만 아니라 로깅된 메트릭 쿼리에도 적용됩니다. 대신 MLflow를 사용하여 실험 및 실행을 관리합니다. 이 문서에서는 MLflow를 사용하여 Azure Machine Learning에서 실험 및 실행을 관리하는 방법을 설명합니다.
MLflow REST API를 사용하여 실험과 실행을 쿼리하고 검색할 수도 있습니다. 사용 방법에 대한 예는 Azure Machine Learning과 함께 MLflow REST 사용을 참조하세요.
필수 조건
다음과 같이 MLflow SDK
mlflow패키지 및 MLflow용 Azure Machine Learningazureml-mlflow플러그 인을 설치합니다.pip install mlflow azureml-mlflow팁
SQL 스토리지, 서버, UI 또는 데이터 과학 종속성이 없는 경량 MLflow 패키지인
mlflow-skinny패키지를 사용할 수 있습니다. 이 패키지는 배포를 비롯한 전체 기능 제품군을 가져오지 않고 MLflow 추적 및 로깅 기능이 주로 필요한 사용자에게 권장됩니다.Azure Machine Learning 작업 영역을 만듭니다. 작업 영역을 만들려면 시작해야 하는 리소스 만들기를 참조하세요. 작업 영역에서 MLflow 작업을 수행하는 데 필요한 액세스 권한을 검토합니다.
원격 추적을 수행하거나 Azure Machine Learning 외부에서 실행되는 실험을 추적하려면 Azure Machine Learning 작업 영역의 추적 URI를 가리키도록 MLflow를 구성합니다. MLflow를 작업 영역에 연결하는 방법에 대한 자세한 내용은 Azure Machine Learning에 대한 MLflow 구성을 참조하세요.
쿼리 및 검색 실험
MLflow를 사용하여 작업 영역 내부에서 실험을 검색합니다. 다음 예제를 참조하세요.
모든 활성 실험을 가져옵니다.
mlflow.search_experiments()참고 항목
레거시 버전의 MLflow(<2.0)에서는 대신
mlflow.list_experiments()메서드를 사용합니다.보관된 실험을 포함한 모든 실험을 가져옵니다.
from mlflow.entities import ViewType mlflow.search_experiments(view_type=ViewType.ALL)이름으로 특정 실험 가져오기:
mlflow.get_experiment_by_name(experiment_name)ID별로 특정 실험 가져오기:
mlflow.get_experiment('1234-5678-90AB-CDEFG')
검색 실험
Mlflow 2.0부터 사용 가능한 search_experiments() 메서드를 사용하면 filter_string을 사용하여 기준과 일치하는 실험을 검색할 수 있습니다.
ID를 기준으로 여러 실험을 검색합니다.
mlflow.search_experiments(filter_string="experiment_id IN (" "'CDEFG-1234-5678-90AB', '1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')" )특정 시간 이후에 만들어진 모든 실험을 검색합니다.
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_experiments(filter_string=f"creation_time > {int(dt.timestamp())}")특정 태그가 있는 모든 실험을 검색합니다.
mlflow.search_experiments(filter_string=f"tags.framework = 'torch'")
쿼리 및 검색 실행
MLflow를 사용하면 동시에 여러 실험을 포함하여 모든 실험 내에서 실행을 검색할 수 있습니다.
mlflow.search_runs() 메서드는 검색할 실험을 표시하기 위해 experiment_ids 및 experiment_name 인수를 허용합니다. 작업 영역의 모든 실험을 검색하려면 search_all_experiments=True를 표시할 수도 있습니다.
실험 이름별:
mlflow.search_runs(experiment_names=[ "my_experiment" ])실험 ID별:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ])작업 영역의 모든 실험을 검색합니다.
mlflow.search_runs(filter_string="params.num_boost_round='100'", search_all_experiments=True)
experiment_ids는 일련의 실험을 제공하므로 필요한 경우 여러 실험에서 실행을 검색할 수 있습니다. 이는 다른 실험(예: 다른 사람 또는 다른 프로젝트 반복)에 기록될 때 동일한 모델의 실행을 비교하려는 경우에 유용할 수 있습니다.
중요합니다
experiment_ids, experiment_names 또는 search_all_experiments가 지정되지 않은 경우 MLflow는 기본적으로 현재 활성 실험에서 검색합니다.
mlflow.set_experiment()를 사용하여 활성 실험을 설정할 수 있습니다.
기본적으로 MLflow는 Pandas Dataframe 형식으로 데이터를 반환하므로 실행 분석을 추가로 처리할 때 편리합니다. 반환된 데이터에는 다음이 포함된 열이 포함됩니다.
- 실행에 대한 기본 정보.
- 열 이름이
params.<parameter-name>인 매개 변수. - 열 이름이
metrics.<metric-name>인 메트릭(각각의 마지막으로 기록된 값).
쿼리가 실행되면 모든 메트릭과 매개 변수도 반환됩니다. 그러나 여러 값(예: 손실 곡선 또는 PR 곡선)이 포함된 메트릭의 경우 메트릭의 마지막 값만 반환됩니다. 지정된 메트릭의 모든 값을 검색하려면 mlflow.get_metric_history 메서드를 사용합니다. 예를 보려면 실행에서 매개 변수 및 메트릭 가져오기를 참조하세요.
주문 실행
기본적으로 실험은 실험이 Azure Machine Learning에서 큐에 대기된 시간인 start_time을 기준으로 내림차순으로 정렬됩니다. 그러나 order_by 매개 변수를 사용하여 이 기본값을 변경할 수 있습니다.
주문은
start_time과 같은 특성에 따라 실행됩니다.mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.start_time DESC"])실행을 주문하고 결과를 제한합니다. 다음 예에서는 실험의 마지막 단일 실행을 반환합니다.
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["attributes.start_time DESC"])주문은
duration특성에 따라 실행됩니다.mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], order_by=["attributes.duration DESC"])팁
attributes.duration은 MLflow OSS에는 없지만 편의를 위해 Azure Machine Learning에 제공됩니다.메트릭 값에 따라 순서가 실행됩니다.
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ]).sort_values("metrics.accuracy", ascending=False)경고
매개 변수
order_by에metrics.*,params.*또는tags.*가 포함된 식과 함께order_by를 사용하는 것은 현재 지원되지 않습니다. 대신 예에 표시된 대로 Pandas의sort_values메서드를 사용합니다.
필터 실행
filter_string 매개 변수를 사용하여 하이퍼 매개 변수에서 특정 조합으로 실행을 찾을 수도 있습니다. 실행 매개 변수에 액세스하려면 params를 사용하고, 실행에 기록된 메트릭에 액세스하려면 metrics를 사용하고, 실행 정보 세부 정보에 액세스하려면 attributes를 사용합니다. MLflow는 AND 키워드로 조인된 식을 지원합니다(구문은 OR을 지원하지 않음).
매개 변수 값을 기준으로 검색이 실행됩니다.
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="params.num_boost_round='100'")경고
=필터링에는 연산자like,!=및parameters만 지원됩니다.메트릭 값을 기반으로 검색이 실행됩니다.
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="metrics.auc>0.8")특정 태그로 검색이 실행됩니다.
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="tags.framework='torch'")특정 사용자가 만든 검색 실행:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.user_id = 'John Smith'")실패한 검색 실행입니다. 가능한 값은 상태별 실행 필터링을 참조하세요.
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.status = 'Failed'")특정 시간 이후에 만들어진 검색 실행:
import datetime dt = datetime.datetime(2022, 6, 20, 5, 32, 48) mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.creation_time > '{int(dt.timestamp())}'")팁
키
attributes의 경우 값은 항상 문자열이어야 하므로 따옴표 사이에 인코딩되어야 합니다.1시간 이상 걸리는 검색 실행:
duration = 360 * 1000 # duration is in milliseconds mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string=f"attributes.duration > '{duration}'")팁
attributes.duration은 MLflow OSS에는 없지만 편의를 위해 Azure Machine Learning에 제공됩니다.지정된 집합에 해당 ID가 있는 검색 실행:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], filter_string="attributes.run_id IN ('1234-5678-90AB-CDEFG', '5678-1234-90AB-CDEFG')")
상태별로 필터 실행
실행을 상태별로 필터링하면 MLflow는 Azure Machine Learning과 비교하여 다른 규칙을 사용하여 가능한 실행 상태의 이름을 다르게 지정합니다. 다음 표에는 가능한 값이 나와 있습니다.
| Azure Machine Learning 작업 상태 | MLFlow의 attributes.status |
의미 |
|---|---|---|
| 시작되지 않음 | Scheduled |
작업/실행이 Azure Machine Learning에서 수신되었습니다. |
| 큐 | Scheduled |
작업/실행이 실행되도록 예약되었지만 아직 시작되지 않았습니다. |
| 준비 | Scheduled |
작업/실행이 아직 시작되지 않았지만 실행을 위해 컴퓨팅이 할당되었으며 환경과 입력을 준비하는 중입니다. |
| 실행 중 | Running |
작업/실행이 현재 활성 실행 중입니다. |
| 완료됨 | Finished |
작업/실행이 오류 없이 완료되었습니다. |
| 실패함 | Failed |
작업/실행이 오류와 함께 완료되었습니다. |
| 취소됨 | Killed |
작업/실행이 사용자에 의해 취소되었거나 시스템에 의해 종료되었습니다. |
예시:
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="attributes.status = 'Failed'")
메트릭, 매개 변수, 아티팩트, 모델 가져오기
search_runs 메서드는 기본적으로 제한된 양의 정보를 포함하는 Pandas Dataframe을 반환합니다. 필요한 경우 Python 개체를 가져올 수 있으며, 이는 개체에 대한 세부 정보를 가져오는 데 유용할 수 있습니다.
output_format 매개 변수를 사용하여 출력이 반환되는 방법을 제어합니다.
runs = mlflow.search_runs(
experiment_ids=[ "1234-5678-90AB-CDEFG" ],
filter_string="params.num_boost_round='100'",
output_format="list",
)
그러면 info 멤버가 세부 정보에 액세스할 수 있습니다. 다음 샘플은 run_id를 가져오는 방법을 보여 줍니다.
last_run = runs[-1]
print("Last run ID:", last_run.info.run_id)
실행에서 매개 변수 및 메트릭 가져오기
output_format="list"를 사용하여 실행이 반환되면 data 키를 사용하여 매개 변수에 쉽게 액세스할 수 있습니다.
last_run.data.params
같은 방식으로 메트릭을 쿼리할 수 있습니다.
last_run.data.metrics
여러 값(예: 손실 곡선 또는 PR 곡선)이 포함된 메트릭의 경우 메트릭의 마지막으로 기록된 값만 반환됩니다. 지정된 메트릭의 모든 값을 검색하려면 mlflow.get_metric_history 메서드를 사용합니다. 이 방법을 사용하려면 MlflowClient를 사용해야 합니다.
client = mlflow.tracking.MlflowClient()
client.get_metric_history("1234-5678-90AB-CDEFG", "log_loss")
실행에서 아티팩트 가져오기
MLflow는 실행에 의해 로그된 모든 아티팩트를 쿼리할 수 있습니다. 아티팩트는 실행 개체 자체를 사용하여 액세스할 수 없으며 대신 MLflow 클라이언트를 사용해야 합니다.
client = mlflow.tracking.MlflowClient()
client.list_artifacts("1234-5678-90AB-CDEFG")
앞의 방법은 실행에 기록된 모든 아티팩트를 나열하지만 아티팩트 저장소(Azure Machine Learning 스토리지)에 저장된 상태로 유지됩니다. 이들 중 하나를 다운로드하려면 download_artifact 메서드를 사용합니다.
file_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path="feature_importance_weight.png"
)
참고 항목
레거시 버전의 MLflow(<2.0)에서는 대신 MlflowClient.download_artifacts() 메서드를 사용합니다.
실행에서 모델 가져오기
모델은 실행 중에 기록된 다음 직접 검색할 수도 있습니다. 모델을 검색하려면 해당 모델이 저장된 아티팩트의 경로를 알아야 합니다. MLflow 모델은 항상 폴더이므로 list_artifacts 메서드를 사용하여 모델을 나타내는 아티팩트를 찾을 수 있습니다.
download_artifact 메서드를 사용하여 모델이 저장되는 경로를 지정하여 모델을 다운로드할 수 있습니다.
artifact_path="classifier"
model_local_path = mlflow.artifacts.download_artifacts(
run_id="1234-5678-90AB-CDEFG", artifact_path=artifact_path
)
그런 다음, 버전별 네임스페이스에서 일반적인 함수 load_model을 사용하여 다운로드한 아티팩트에서 모델을 다시 로드할 수 있습니다. 다음 예제에서는 xgboost를 사용합니다.
model = mlflow.xgboost.load_model(model_local_path)
또한 MLflow를 사용하면 두 작업을 동시에 수행하고 단일 명령으로 모델을 다운로드하고 로드할 수 있습니다. MLflow는 모델을 임시 폴더에 다운로드하고 해당 위치에서 로드합니다. 메서드 load_model은 URI 형식을 사용하여 모델을 검색해야 하는 위치를 나타냅니다. 실행에서 모델을 로드하는 경우 URI 구조는 다음과 같습니다.
model = mlflow.xgboost.load_model(f"runs:/{last_run.info.run_id}/{artifact_path}")
팁
모델 레지스트리에 등록된 모델을 쿼리하고 로드하려면 MLflow를 사용하여 Azure Machine Learning에서 모델 레지스트리 관리를 참조하세요.
자식(중첩) 실행 가져오기
MLflow는 자식(중첩) 실행의 개념을 지원합니다. 이러한 실행은 기본 학습 프로세스와 독립적으로 추적해야 하는 학습 루틴을 분리해야 할 때 유용합니다. 하이퍼 매개 변수 튜닝 최적화 프로세스 또는 Azure Machine Learning 파이프라인은 여러 자식 실행을 생성하는 작업의 일반적인 예입니다. 부모 실행의 실행 ID가 포함된 속성 태그 mlflow.parentRunId를 사용하여 특정 실행의 모든 자식 실행을 쿼리할 수 있습니다.
hyperopt_run = mlflow.last_active_run()
child_runs = mlflow.search_runs(
filter_string=f"tags.mlflow.parentRunId='{hyperopt_run.info.run_id}'"
)
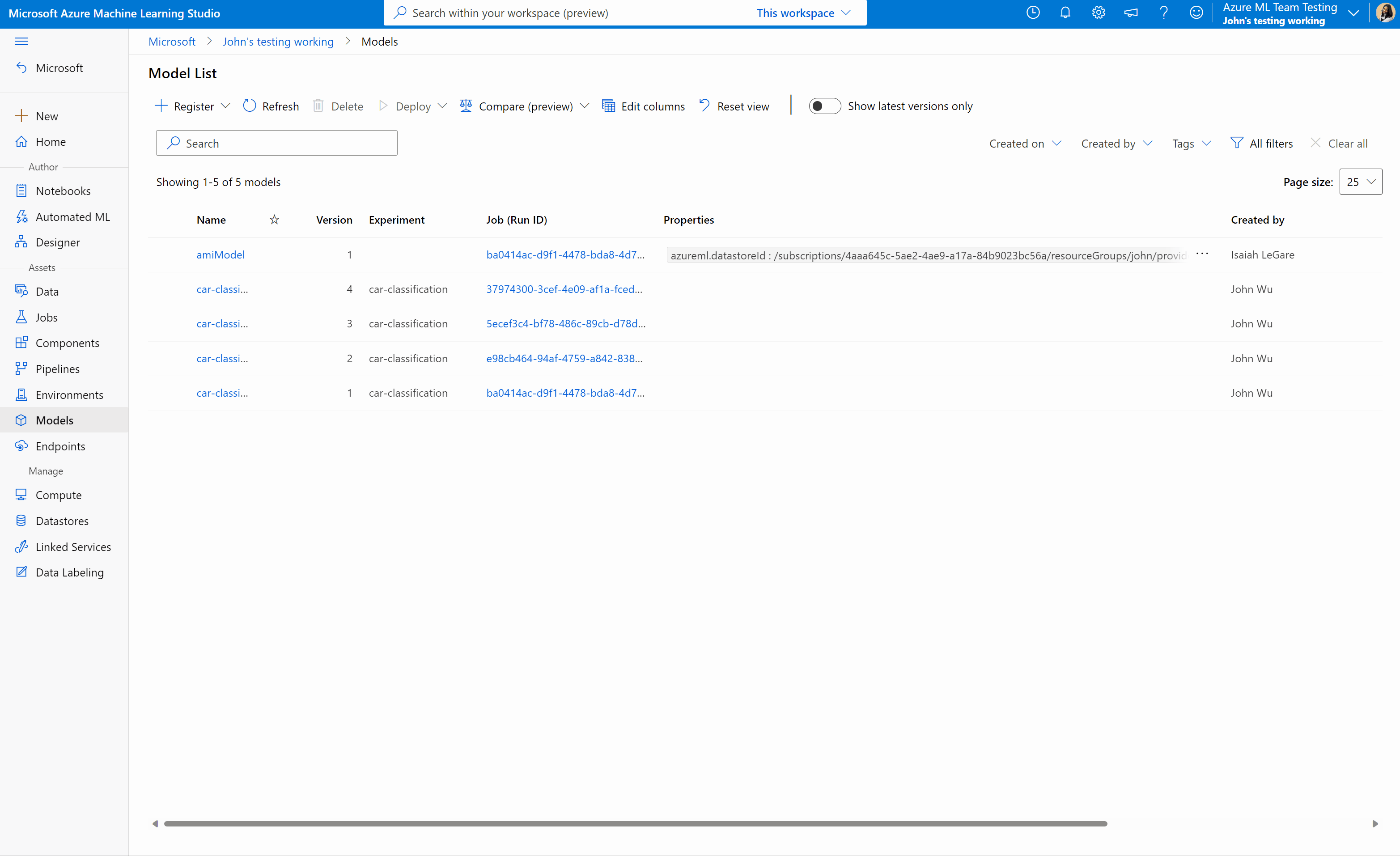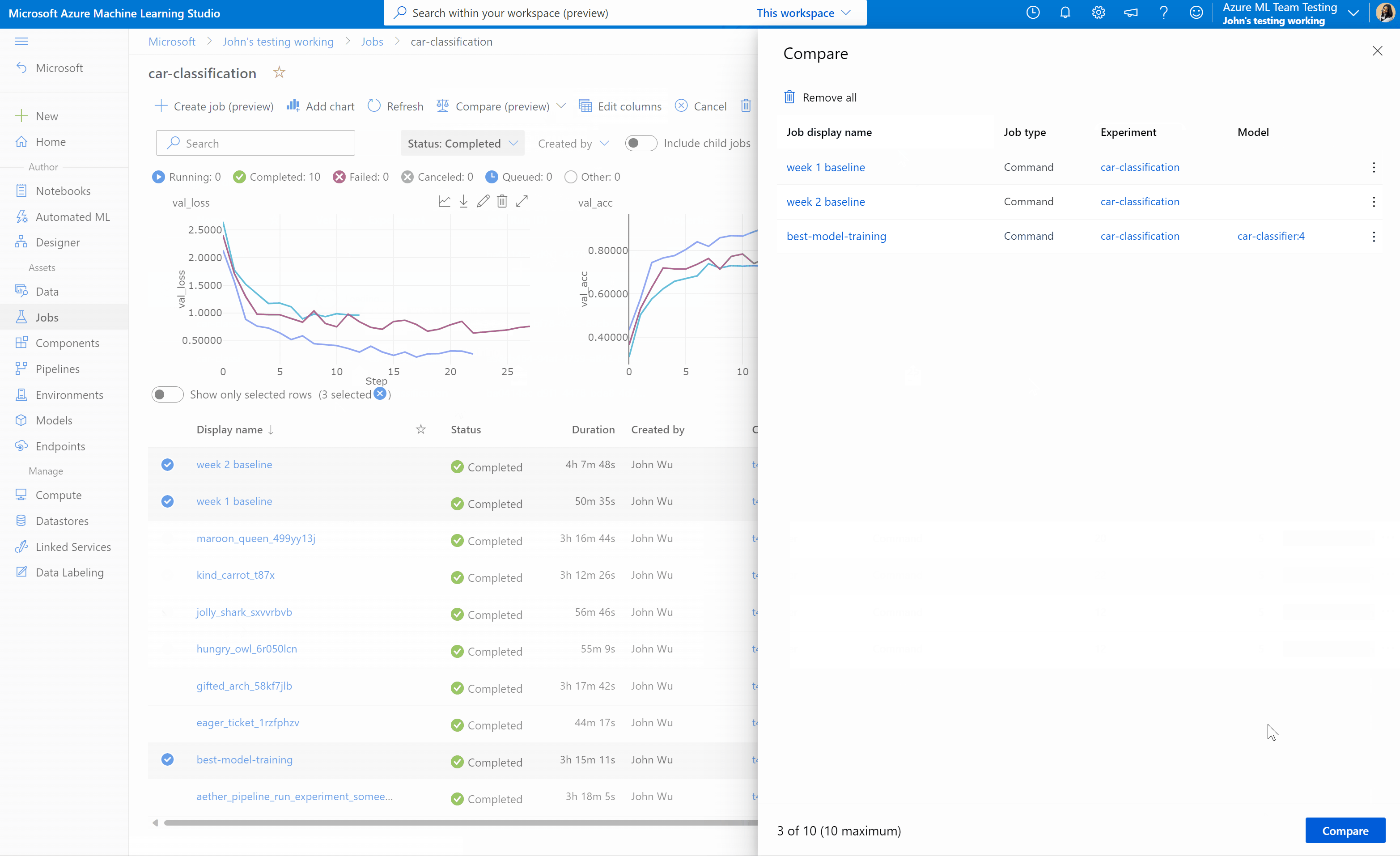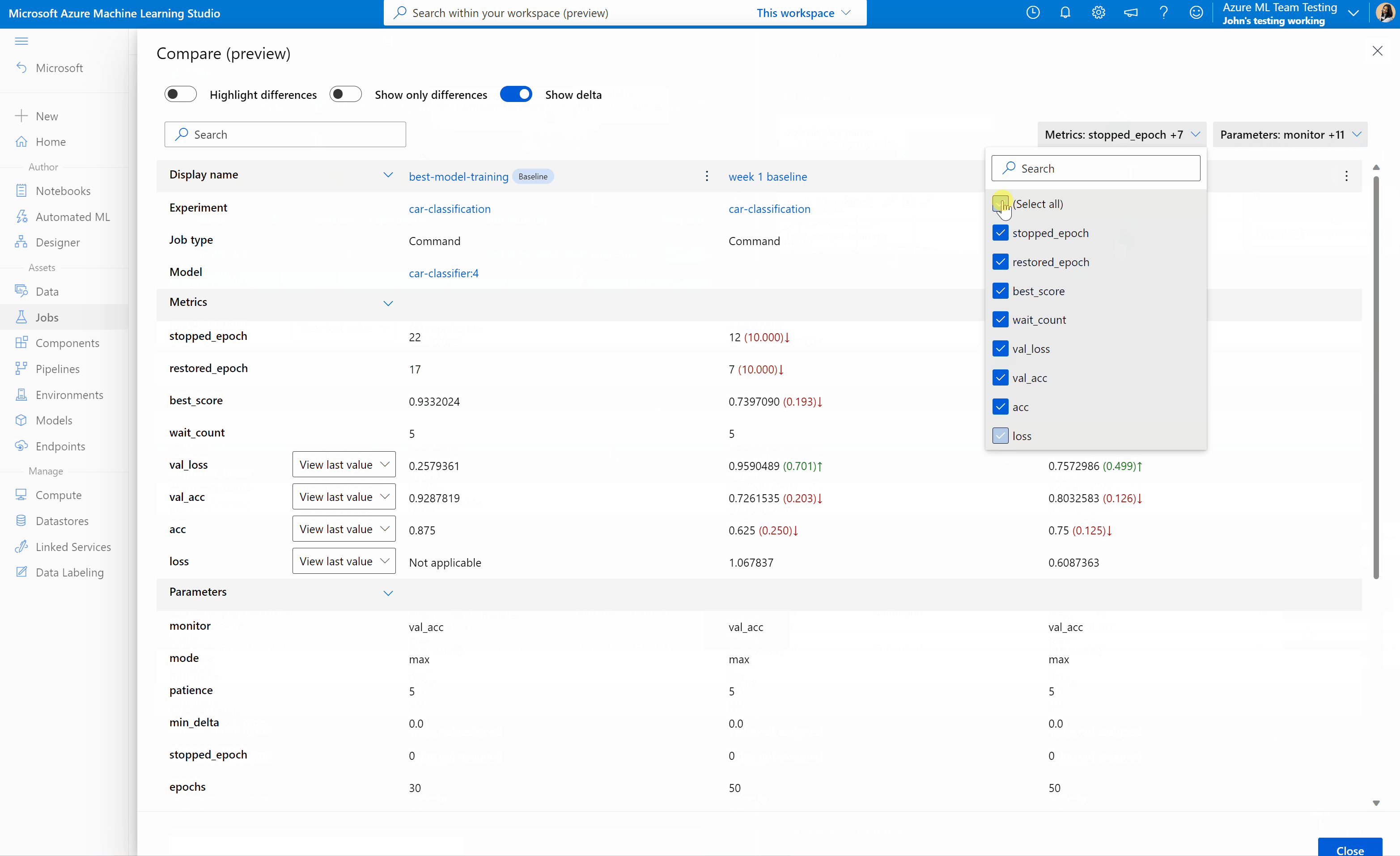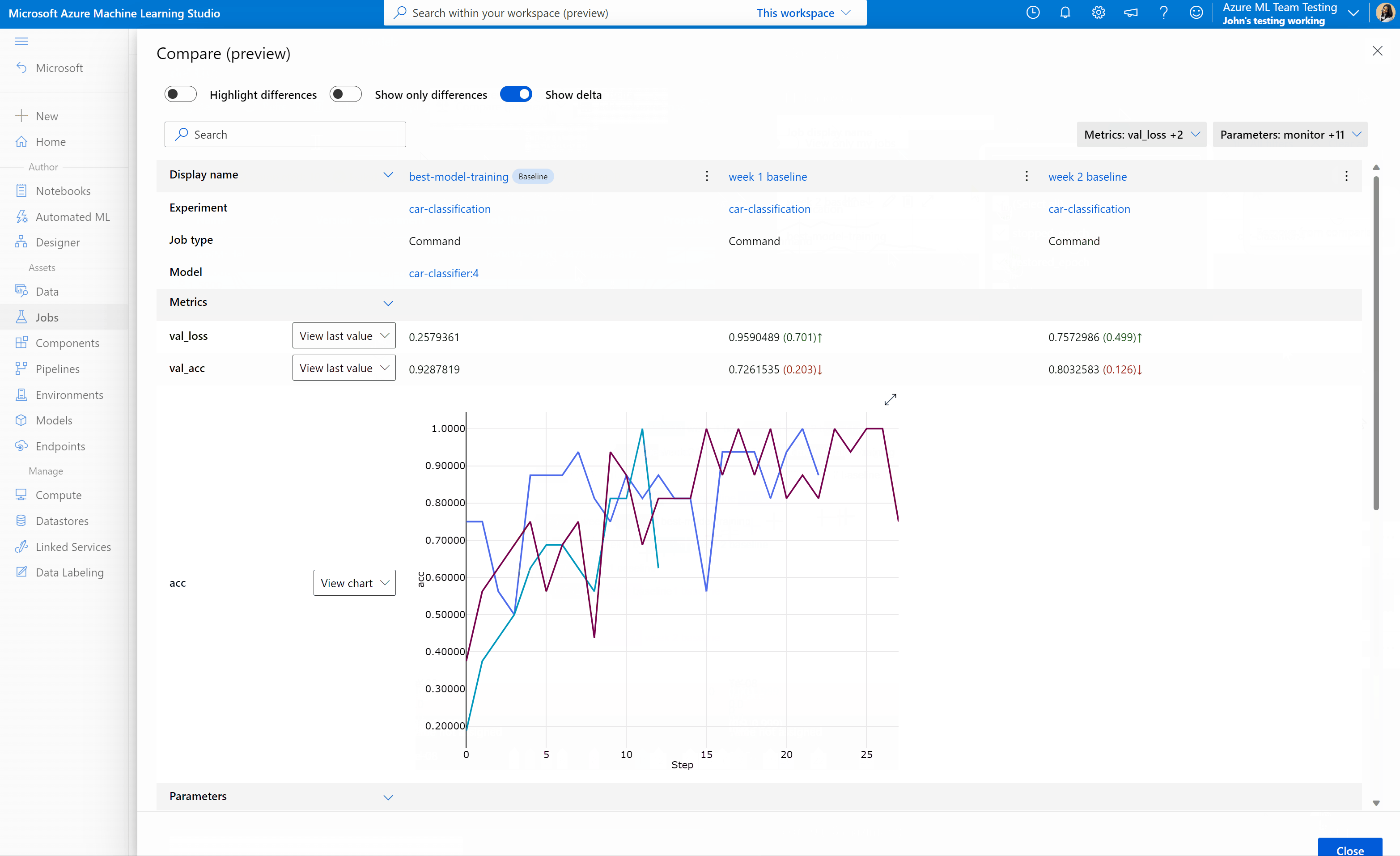
Azure Machine Learning 스튜디오에서 작업 및 모델 비교(미리 보기)
Azure Machine Learning 스튜디오에서 작업 및 모델의 품질을 비교하고 평가하려면 미리 보기 패널을 사용하여 기능을 사용하도록 설정합니다. 사용하도록 설정되면 선택한 작업 및/또는 모델 간에 매개 변수, 메트릭 및 태그를 비교할 수 있습니다.
중요합니다
이 문서에 표시된 항목(미리 보기)은 현재 퍼블릭 미리 보기에서 확인할 수 있습니다. 미리 보기 버전은 서비스 수준 계약 없이 제공되며 프로덕션 워크로드에는 권장되지 않습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
Azure Machine Learning Notebook을 사용한 MLflow는 이 문서에 나와 있는 개념에 따라 시연하고 확장합니다.
- MLflow를 사용하여 분류자 학습 및 추적: MLflow를 사용하여 실험을 추적하고, 모델을 기록하고, 여러 버전을 파이프라인에 결합하는 방법을 보여 줍니다.
- MLflow로 실험 및 실행 관리: MLflow를 사용하여 Azure Machine Learning에서 실험, 실행, 메트릭, 매개 변수 및 아티팩트를 쿼리하는 방법을 보여 줍니다.
실행 및 실험 쿼리를 위한 지원 행렬
MLflow SDK는 반환되는 항목과 방법을 제어하는 옵션을 포함하여 실행을 검색하는 여러 메서드를 공개합니다. 다음 표를 사용하여 Azure Machine Learning에 연결된 경우 MLflow에서 현재 지원되는 방법에 대해 알아봅니다.
| 기능 | MLflow에서 지원 | Azure Machine Learning에서 지원됨 |
|---|---|---|
| 특성별로 실행 순서 지정 | ✓ | ✓ |
| 메트릭별로 실행 순서 지정 | ✓ | 1 |
| 매개 변수로 실행 순서 지정 | ✓ | 1 |
| 태그별 실행 주문 | ✓ | 1 |
| 특성별 실행 필터링 | ✓ | ✓ |
| 메트릭별 실행 필터링 | ✓ | ✓ |
| 특수 문자(이스케이프 처리)가 있는 메트릭별로 실행 필터링 | ✓ | |
| 매개 변수로 실행 필터링 | ✓ | ✓ |
| 태그로 실행 필터링 | ✓ | ✓ |
=, !=, >, >=, < 및 <=를 포함하는 숫자 비교기(메트릭)로 필터링 실행 |
✓ | ✓ |
문자열 비교기(매개 변수, 태그 및 특성)로 필터링 실행: = 및 != |
✓ | ✓2 |
문자열 비교기(매개 변수, 태그 및 특성)로 필터링 실행: LIKE/ILIKE |
✓ | ✓ |
비교기 AND로 실행 필터링 |
✓ | ✓ |
비교기 OR로 실행 필터링 |
||
| 실험 이름 바꾸기 | ✓ |
참고 항목
- 1 Azure Machine Learning에서 동일한 기능을 달성하는 방법에 대한 지침과 예는 실행 순서 지정 섹션을 확인합니다.
-
2
!=태그의 경우 지원되지 않습니다.