Azure Machine Learning으로 큐레이팅된 오픈 소스 기초 모델을 사용하는 방법
이 문서에서는 모델 카탈로그에서 기초 모델을 미세 조정, 평가 및 배포하는 방법을 알아봅니다.
모델 카드의 샘플 유추 양식을 사용하여 미리 학습된 모델을 신속하게 테스트하고 결과를 테스트하기 위한 자체 샘플 입력을 제공할 수 있습니다. 또한 각 모델의 모델 카드에는 모델에 대한 간략한 설명과 모델의 코드 기반 추론, 미세 조정 및 평가를 위한 샘플 링크가 포함되어 있습니다.
자체 테스트 데이터를 사용하여 기초 모델을 평가하는 방법
UI 평가 양식을 사용하거나 모델 카드에 연결된 코드 기반 샘플을 사용하여 테스트 데이터 세트에 대해 기초 모델을 평가할 수 있습니다.
스튜디오를 이용한 평가
기초 모델의 모델 카드에 있는 평가 단추를 선택하여 모델 평가 양식을 호출할 수 있습니다.
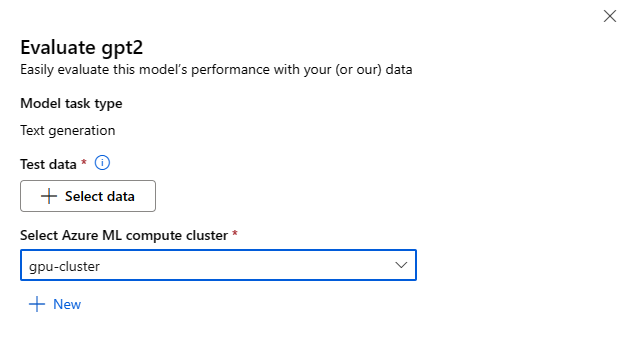
모델이 사용될 특정 유추 작업에 대해 각 모델을 평가할 수 있습니다.
테스트 데이터:
- 모델을 평가하는 데 사용할 테스트 데이터를 전달합니다. 로컬 파일(JSONL 형식)을 업로드하거나 작업 영역에서 기존에 등록된 데이터 세트를 선택하도록 선택할 수 있습니다.
- 데이터 세트를 선택한 후에는 작업에 필요한 스키마를 기반으로 입력 데이터의 열을 매핑해야 합니다. 예를 들어, 텍스트 분류를 위해 '문장' 및 '레이블' 키에 해당하는 열 이름을 매핑합니다.

컴퓨팅:
모델 미세 조정에 사용하려는 Azure Machine Learning 컴퓨팅 클러스터를 제공합니다. 평가는 GPU 컴퓨팅에서 실행되어야 합니다. 사용하려는 컴퓨팅 SKU에 대한 컴퓨팅 할당량이 충분한지 확인합니다.
평가 양식에서 마침을 선택하여 평가 작업을 제출합니다. 작업이 완료되면 모델에 대한 평가 메트릭을 볼 수 있습니다. 평가 메트릭을 기반으로 자체 학습 데이터를 사용하여 모델을 미세 조정할지 여부를 결정할 수 있습니다. 또한 모델을 등록하고 엔드포인트에 배포할지 여부를 결정할 수 있습니다.
코드 기반 샘플을 사용하여 평가
사용자가 모델 평가를 시작할 수 있도록 azureml-examples git repo의 평가 샘플에 샘플(Python Notebooks 및 CLI 예 모두)을 게시했습니다. 각 모델 카드는 해당 작업에 대한 평가 샘플에 대한 링크도 제공합니다.
자체 학습 데이터를 사용하여 기초 모델을 미세 조정하는 방법
워크로드에서 모델 성능을 개선시키기 위해 자체 학습 데이터를 사용하여 기초 모델을 미세 조정할 수 있습니다. 스튜디오의 미세 조정 설정을 사용하거나 모델 카드에서 연결된 코드 기반 샘플을 사용하여 이러한 기초 모델을 쉽게 미세 조정할 수 있습니다.
스튜디오를 사용한 미세 조정
기초 모델의 모델 카드에 있는 미세 조정 단추를 선택하여 미세 조정 설정 양식을 호출할 수 있습니다.
미세 조정 설정:
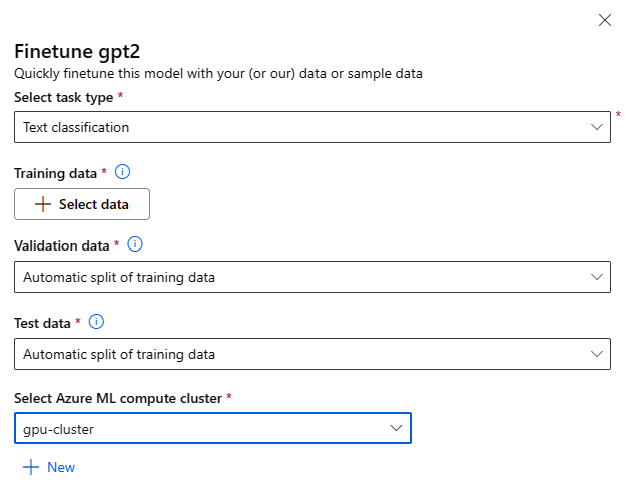
미세 조정 작업 유형
- 모델 카탈로그의 미리 학습된 모든 모델은 특정 작업 집합(예: 텍스트 분류, 토큰 분류, 질문 답변)에 맞게 미세 조정할 수 있습니다. 드롭다운에서 사용하려는 작업을 선택합니다.
학습 데이터
모델을 미세 조정하는 데 사용하려는 학습 데이터를 전달합니다. 로컬 파일(JSONL, CSV 또는 TSV 형식)을 업로드하거나 작업 영역에서 기존에 등록된 데이터 세트를 선택할 수 있습니다.
데이터 세트를 선택한 후에는 작업에 필요한 스키마를 기반으로 입력 데이터의 열을 매핑해야 합니다. 예: 텍스트 분류를 위한 '문장' 및 '레이블' 키에 해당하는 열 이름 매핑

- 유효성 검사 데이터: 모델 유효성 검사에 사용할 데이터를 전달합니다. 자동 분할을 선택하면 유효성 검사를 위해 학습 데이터의 자동 분할이 예약됩니다. 또는 다른 유효성 검사 데이터 세트를 제공할 수 있습니다.
- 테스트 데이터: 미세 조정된 모델을 평가하는 데 사용하려는 테스트 데이터를 전달합니다. 자동 분할을 선택하면 테스트용 학습 데이터의 자동 분할이 예약됩니다.
- 컴퓨팅: 모델 미세 조정에 사용하려는 Azure Machine Learning 컴퓨팅 클러스터를 제공합니다. 미세 조정은 GPU 컴퓨팅에서 실행되어야 합니다. 미세 조정 시 A100/V100 GPU와 함께 컴퓨팅 SKU를 사용하는 것이 좋습니다. 사용하려는 컴퓨팅 SKU에 대한 컴퓨팅 할당량이 충분한지 확인합니다.
- 미세 조정 작업을 제출하려면 미세 조정 양식에서 마침을 선택합니다. 작업이 완료되면 미세 조정된 모델에 대한 평가 메트릭을 볼 수 있습니다. 그런 다음 미세 조정 작업을 통해 미세 조정된 모델 출력을 등록하고 추론을 위해 이 모델을 엔드포인트에 배포할 수 있습니다.
코드 기반 샘플을 사용한 미세 조정
현재 Azure Machine Learning은 다음 언어 작업에 대한 모델 미세조정을 지원합니다.
- 텍스트 분류
- 토큰 분류
- 질문 답변
- 요약
- Translation
사용자가 신속하게 미세 조정을 시작할 수 있도록 Microsoft에서 azureml-examples git 리포지토리 미세 조정 샘플에 각 작업의 샘플(Python Notebooks 및 CLI 예제 모두)을 게시했습니다. 각 모델 카드는 지원되는 미세 조정 작업을 위한 미세 조정 샘플에도 연결됩니다.
유추를 위해 엔드포인트에 기초 모델 배포
추론에 사용할 수 있는 기초 모델(모델 카탈로그의 미리 학습된 모델과 작업 영역에 등록된 후 미세 조정된 모델 모두)을 엔드포인트에 배포할 수 있습니다. 서버리스 API와 관리 컴퓨팅에 배포가 공통적으로 지원됩니다. UI 배포 마법사를 사용하거나 모델 카드에 연결된 코드 기반 샘플을 사용하여 이러한 모델을 배포할 수 있습니다.
스튜디오를 사용하여 배포
기본 모델의 모델 카드에서 배포 단추를 선택하고, Azure AI 콘텐츠 보안을 사용하는 서버리스 API 또는 Azure AI 콘텐츠 보안을 사용하지 않는 관리 컴퓨팅을 선택하면 배포 UI 형식을 호출할 수 있습니다.

배포 설정
채점 스크립트와 환경은 기초 모델에 자동으로 포함되므로 사용할 가상 머신 SKU, 인스턴스 수 및 배포에 사용할 엔드포인트 이름만 지정하면 됩니다.
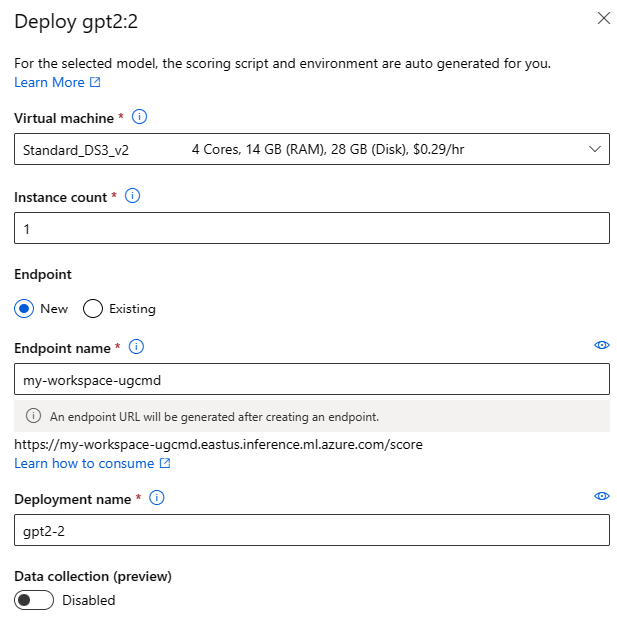
공유 할당량
모델 카탈로그에서 Llama-2, Phi, Nemotron, Mistral, Dolly 또는 Deci-DeciLM 모델을 배포 중이지만 배포에 사용할 수 있는 할당량이 충분하지 않은 경우 Azure Machine Learning을 사용하면 제한된 시간 동안 공유 할당량 풀의 할당량을 사용할 수 있습니다. 공유 할당량에 대한 자세한 내용은 Azure Machine Learning 공유 할당량을 참조하세요.

코드 기반 샘플을 사용하여 배포
사용자가 배포 및 유추를 빠르게 시작할 수 있도록 azureml-examples git repo의 유추 샘플에 샘플을 게시했습니다. 게시된 샘플에는 Python Notebooks 예 및 CLI 예가 포함되어 있습니다. 각 모델 카드는 실시간 및 Batch 유추를 위한 유추 샘플에도 연결됩니다.
기초 모델 가져오기
모델 카탈로그에 포함되지 않은 오픈 소스 모델을 사용하려는 경우 Hugging Face에서 Azure Machine Learning 작업 영역으로 모델을 가져올 수 있습니다. Hugging Face는 자주 사용되는 NLP 작업을 위해 미리 학습된 모델을 제공하는 NLP(자연어 처리)를 위한 오픈 소스 라이브러리입니다. 현재 모델 가져오기는 모델이 모델 가져오기 Notebook에 나열된 요구 사항을 충족하는 한 다음 작업에 대한 모델 가져오기를 지원합니다.
- fill-mask
- token-classification
- question-answering
- 요약
- text-generation
- text-classification
- 번역
- image-classification
- text-to-image
참고 항목
Hugging Face의 모델에는 Hugging Face 모델 세부 정보 페이지에서 확인할 수 있는 타사 라이선스 사용 조건이 적용됩니다. 모델의 라이선스 사용 조건을 준수하는 것은 사용자의 책임입니다.
모델 카탈로그의 오른쪽 위에 있는 가져오기 단추를 선택하여 모델 가져오기 Notebook을 사용할 수 있습니다.
모델 가져오기 Notebook은 여기의 azureml-examples git repo에도 포함되어 있습니다.
모델을 가져오려면 Hugging Face에서 가져오려는 모델의 MODEL_ID를 전달해야 합니다. Hugging Face 허브에서 모델을 찾아보고 가져올 모델을 식별합니다. 모델의 작업 종류가 지원되는 작업 종류에 속하는지 확인합니다. 페이지의 URI에서 사용 가능하거나 모델 이름 옆에 있는 복사 아이콘을 사용하여 복사할 수 있는 모델 ID를 복사합니다. 모델 가져오기 Notebook의 'MODEL_ID' 변수에 할당합니다. 예시:
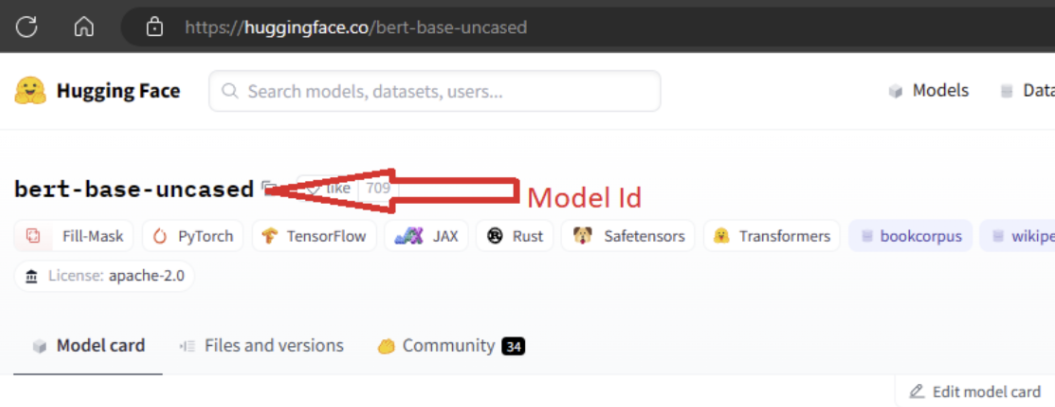
모델 가져오기를 실행하려면 컴퓨팅을 제공해야 합니다. 모델 가져오기를 실행하면 지정된 모델이 Hugging Face에서 가져오고 Azure Machine Learning 작업 영역에 등록됩니다. 그런 다음, 이 모델을 미세 조정하거나 추론을 위해 엔드포인트에 배포할 수 있습니다.
자세한 정보
- Azure Machine Learning 스튜디오의 모델 카탈로그를 살펴봅니다. 카탈로그를 탐색하려면 Azure Machine Learning 작업 영역이 필요합니다.
- 모델 카탈로그 및 컬렉션 탐색
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기