좋은 프롬프트를 만드는 것은 많은 창의성, 명확성 및 관련성을 요구하는 어려운 작업입니다. 좋은 프롬프트는 미리 학습된 언어 모델에서 원하는 출력을 이끌어낼 수 있는 반면, 나쁜 프롬프트는 부정확하거나 관련성이 없거나 무의미한 출력으로 이어질 수 있습니다. 따라서 다양한 작업과 도메인에 대한 성능과 견고성을 최적화하기 위해 프롬프트를 조정해야 합니다.
따라서 다양한 문구, 형식, 컨텍스트, 온도 또는 상위 k와 같은 다양한 조건에서 모델의 동작을 테스트하고 비교하여 최상의 프롬프트 및 구성을 찾는 데 도움이 될 수 있는 변형 개념을 소개합니다. 모델의 정확도, 다양성 또는 일관성을 최대화하는 것입니다.
이 문서에서는 변형을 사용하여 프롬프트를 조정하고 다양한 변형의 실적을 평가하는 방법을 보여 줍니다.
필수 조건
이 문서를 읽기 전에 다음을 살펴보는 것이 좋습니다.
변형을 사용하여 프롬프트를 조정하는 방법은 무엇인가요?
이 문서에서는 웹 분류 샘플 흐름을 예로 사용합니다.
샘플 흐름을 열고 시작으로 prepare_examples 노드를 제거합니다.
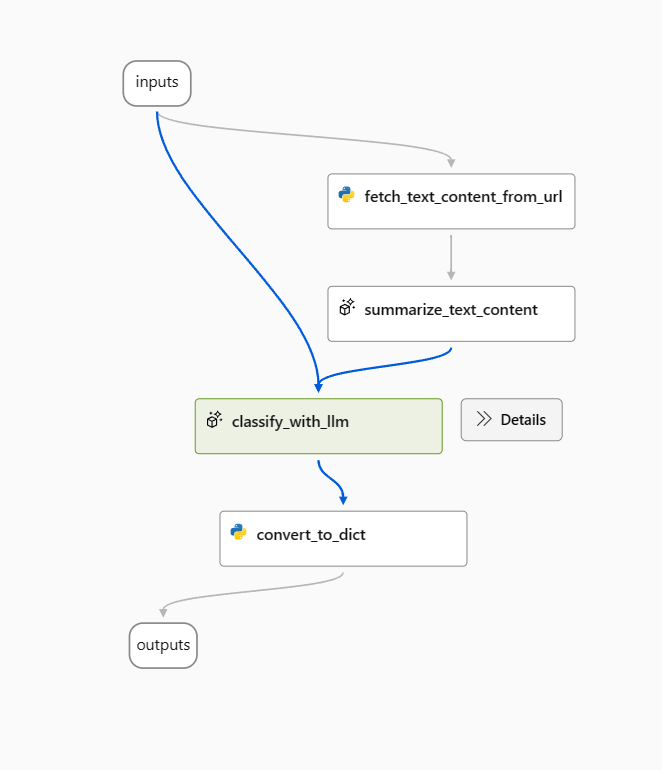
다음 프롬프트를 classify_with_llm 노드에서 기준 프롬프트로 사용합니다.

Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
The output shoule be in this format: {"category": "App", "evidence": "Both"}
OUTPUT:
이 흐름을 최적화하는 데는 여러 가지 방법이 있을 수 있으며 다음은 두 가지 방향입니다.
classify_with_llm 노드의 경우: 커뮤니티와 논문을 통해 온도가 낮을수록 정밀도는 높아지지만 창의성과 놀라움은 떨어지므로 분류 작업에는 온도가 낮을수록 적합하며 몇 번만 메시지를 표시하면 LLM 성능이 향상될 수 있다는 것을 알아보았습니다. 따라서 온도가 1에서 0으로 변경될 때와 몇 번의 예가 포함된 프롬프트가 표시될 때 내 흐름이 어떻게 작동하는지 테스트하려고 합니다.
summarize_text_content 노드의 경우: 또한 요약을 100단어에서 300단어로 변경할 때 흐름의 동작을 테스트하여 더 많은 텍스트 콘텐츠가 성능 개선에 도움이 될 수 있는지 확인하려고 합니다.
변형 만들기
- LLM 노드 오른쪽 상단에 있는 변형 표시 단추를 선택합니다. 기존 LLM 노드는 Variant_0이며 기본 변형입니다.
- 변형_0에서 복제 단추를 선택하여 변형_1을 생성한 다음 매개 변수를 다른 값으로 구성하거나 변형_1에서 프롬프트를 업데이트할 수 있습니다.
- 더 많은 변형을 만들려면 이 단계를 반복합니다.
- 더 이상 변형을 추가하지 않으려면 변형 숨기기를 선택합니다. 그리고 모든 변형이 접혀 있습니다. 노드에 대한 기본 변형이 표시됩니다.
Variant_0을 기반으로 하는 classify_with_llm 노드의 경우:
- 온도가 1에서 0으로 변경되는 변형_1을 만듭니다.
- 온도가 0인 변형_2를 만들면 몇 장의 예를 포함하여 다음 프롬프트를 사용할 수 있습니다.
Your task is to classify a given url into one of the following types:
Movie, App, Academic, Channel, Profile, PDF or None based on the text content information.
The classification will be based on the url, the webpage text content summary, or both.
Here are a few examples:
URL: https://play.google.com/store/apps/details?id=com.spotify.music
Text content: Spotify is a free music and podcast streaming app with millions of songs, albums, and original podcasts. It also offers audiobooks, so users can enjoy thousands of stories. It has a variety of features such as creating and sharing music playlists, discovering new music, and listening to popular and exclusive podcasts. It also has a Premium subscription option which allows users to download and listen offline, and access ad-free music. It is available on all devices and has a variety of genres and artists to choose from.
OUTPUT: {"category": "App", "evidence": "Both"}
URL: https://www.youtube.com/channel/UC_x5XG1OV2P6uZZ5FSM9Ttw
Text content: NFL Sunday Ticket is a service offered by Google LLC that allows users to watch NFL games on YouTube. It is available in 2023 and is subject to the terms and privacy policy of Google LLC. It is also subject to YouTube's terms of use and any applicable laws.
OUTPUT: {"category": "Channel", "evidence": "URL"}
URL: https://arxiv.org/abs/2303.04671
Text content: Visual ChatGPT is a system that enables users to interact with ChatGPT by sending and receiving not only languages but also images, providing complex visual questions or visual editing instructions, and providing feedback and asking for corrected results. It incorporates different Visual Foundation Models and is publicly available. Experiments show that Visual ChatGPT opens the door to investigating the visual roles of ChatGPT with the help of Visual Foundation Models.
OUTPUT: {"category": "Academic", "evidence": "Text content"}
URL: https://ab.politiaromana.ro/
Text content: There is no content available for this text.
OUTPUT: {"category": "None", "evidence": "None"}
For a given URL : {{url}}, and text content: {{text_content}}.
Classify above url to complete the category and indicate evidence.
OUTPUT:
summarize_text_content 노드의 경우 변형_0을 기반으로 프롬프트에서 100 words가 300 단어로 변경되는 변형_1을 만들 수 있습니다.
이제 흐름은 summarize_text_content 노드에 대한 변형 2개와 classify_with_llm 노드에 대한 변형 3개로 표시됩니다.

단일 데이터 행으로 모든 변형을 실행하고 출력을 확인합니다.
모든 변형이 성공적으로 실행되고 예상대로 작동하는지 확인하려면 단일 데이터 행을 사용하여 흐름을 실행하여 테스트하면 됩니다.
참고 항목
매번 실행할 변형이 있는 하나의 LLM 노드만 선택할 수 있으며 다른 LLM 노드는 기본 변형을 사용합니다.
이 예에서는 summarize_text_content 노드와 classify_with_llm 노드 모두에 대한 변형을 구성하므로 모든 변형을 테스트하려면 두 번 실행해야 합니다.
- 오른쪽 상단의 실행 단추를 선택합니다.
- 변형이 있는 LLM 노드를 선택합니다. 다른 LLM 노드는 기본 변형을 사용합니다.
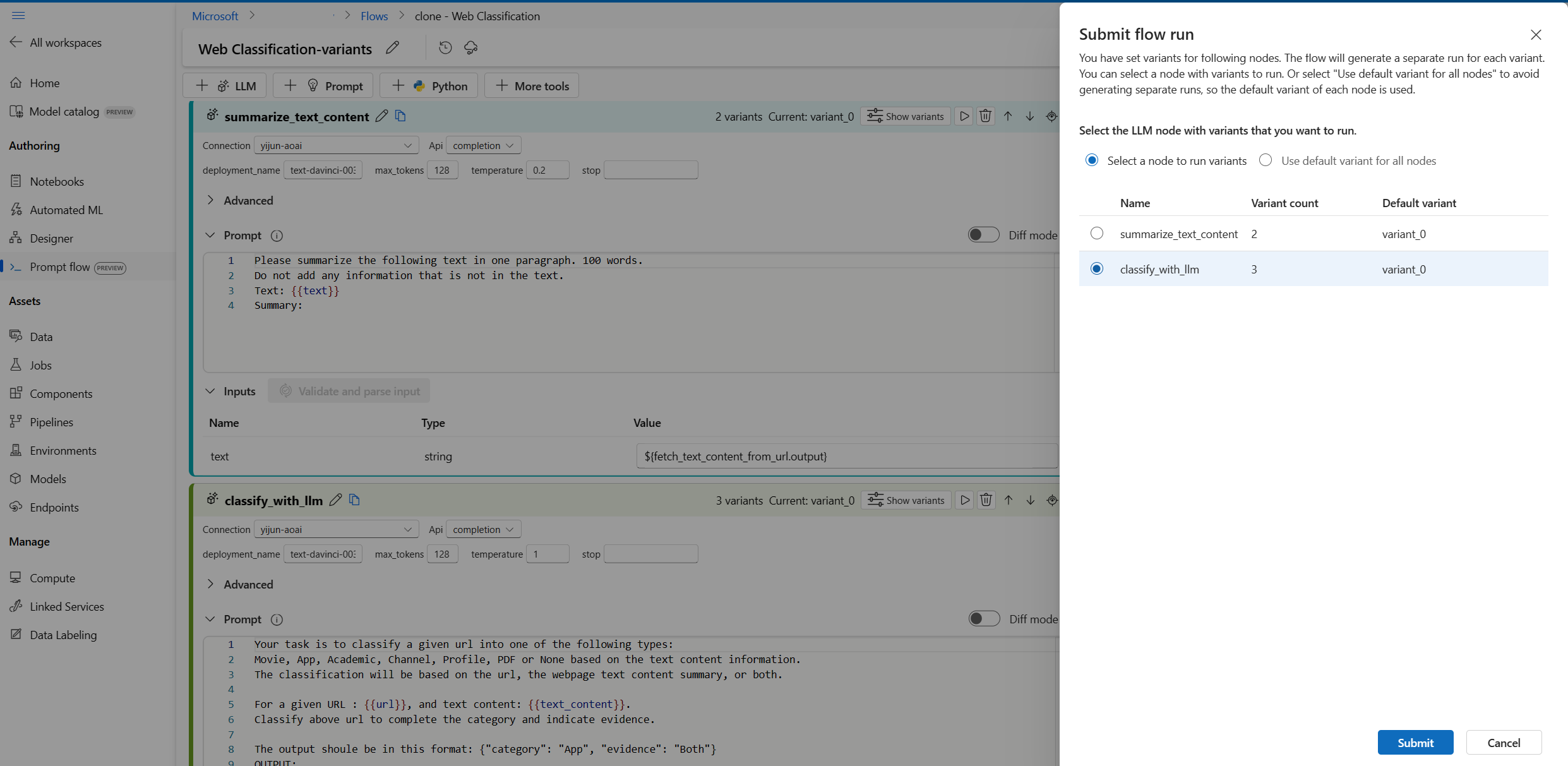
- 흐름 실행을 제출합니다.
- 흐름 실행이 완료된 후 각 변형에 대한 해당 결과를 확인할 수 있습니다.
- 변형이 있는 다른 LLM 노드를 사용하여 다른 흐름 실행을 제출하고 출력을 확인합니다.
- 다른 입력 데이터를 변경하고(예: Wikipedia 페이지 URL 사용) 위 단계를 반복하여 다양한 데이터에 대한 변형을 테스트할 수 있습니다.

변형 평가
몇 개의 단일 데이터로 변형을 실행하고 육안으로 결과를 확인하면 실제 데이터의 복잡성과 다양성을 반영할 수 없고, 한편 출력도 측정할 수 없으므로 효율성을 비교하기가 어렵습니다. 다양한 변형을 확인한 다음 가장 좋은 것을 선택합니다.
대량의 데이터로 변형을 테스트하고 메트릭으로 평가할 수 있는 일괄 처리 실행을 제출하면 가장 적합한 것을 찾는 데 도움이 됩니다.
먼저 프롬프트 흐름으로 해결하려는 실제 문제를 충분히 대표하는 데이터 세트를 준비해야 합니다. 이 예에서는 URL 목록과 해당 분류 기준 참조 자료입니다. 대안의 실적을 평가하기 위해 정확도를 사용할 예정입니다.
페이지 오른쪽 위에서 평가를 선택합니다.
Batch 실행 및 평가 마법사가 실행됩니다. 첫 번째 단계는 모든 변형을 실행할 노드를 선택하는 것입니다.
흐름의 각 노드에 대해 다양한 변형이 얼마나 잘 작동하는지 테스트하려면 변형이 하나씩 있는 각 노드에 대해 일괄 처리 실행을 실행해야 합니다. 이렇게 하면 다른 노드 변형의 영향을 피하고 이 노드 변형의 결과에 집중할 수 있습니다. 이는 대조 실험의 규칙을 따릅니다. 즉, 한 번에 하나만 변경하고 다른 모든 항목은 동일하게 유지한다는 의미입니다.
예를 들어, classify_with_llm 노드를 선택하여 모든 변형을 실행할 수 있으며, summarize_text_content 노드는 이 일괄 처리 실행에 기본 변형을 사용합니다.
다음으로 일괄 처리 실행 설정에서 일괄 처리 실행 이름을 설정하고, 런타임을 선택하고, 준비된 데이터를 업로드할 수 있습니다.
그런 다음 평가 설정에서 평가 방법을 선택합니다.
이 흐름은 분류를 위한 흐름이므로 분류 정확도 평가 방법을 선택하여 정확도를 평가할 수 있습니다.
정확도는 흐름에 의해 할당된 예측 레이블(예측)과 데이터의 참조 자료 레이블(실측)을 비교하고 일치하는 개수를 계산하여 계산됩니다.
평가 입력 매핑 섹션에서는 입력 데이터 세트의 범주 열에서 참조 자료가 나오고 예측은 흐름 출력 중 하나인 범주에서 나오도록 지정해야 합니다.
모든 설정을 검토한 후 일괄 처리 실행을 제출할 수 있습니다.
실행이 제출된 후 링크를 선택하고 실행 세부 정보 페이지로 이동합니다.
참고 항목
실행을 완료하는 데 몇 분 정도 걸릴 수 있습니다.
출력 시각화
- 일괄 처리 실행 및 평가 실행이 완료된 후 실행 세부 정보 페이지에서 각 변형에 대한 일괄 처리 실행을 다중 선택한 다음 출력 시각화를 선택합니다. classify_with_llm 노드에 대한 3가지 변형의 메트릭과 각 데이터 기록에 대한 LLM 예측 출력이 표시됩니다.
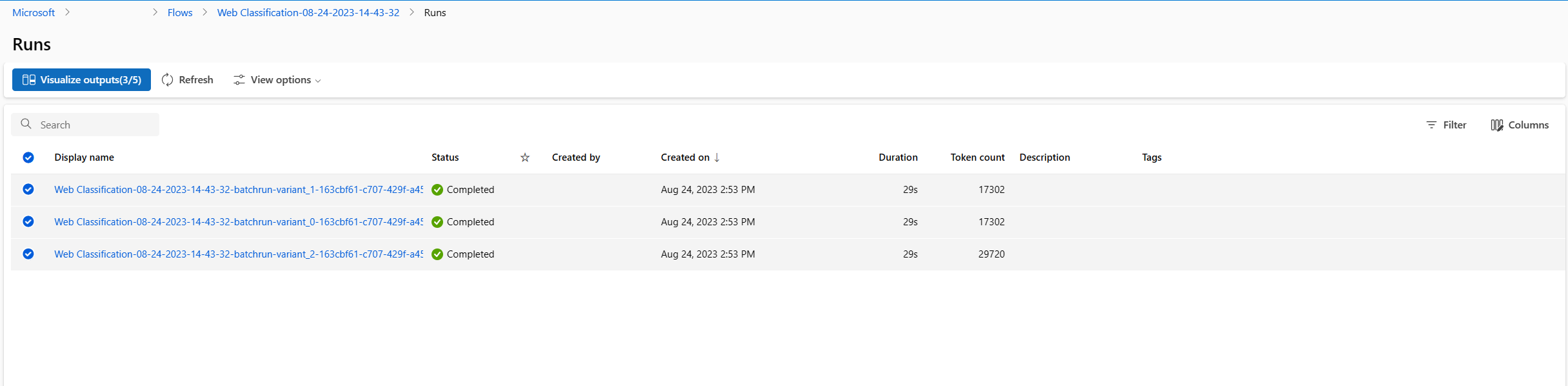
- 어떤 변형이 가장 좋은지 확인한 후 흐름 작성 페이지로 돌아가서 해당 변형을 노드의 기본 변형으로 설정할 수 있습니다.
- 위 단계를 반복하여 summarize_text_content 노드의 변형도 평가할 수 있습니다.
이제 변형을 사용하여 프롬프트를 튜닝하는 프로세스가 완료되었습니다. 이 기술을 자체 프롬프트 흐름에 적용하여 LLM 노드에 가장 적합한 변형을 찾을 수 있습니다.