Azure Machine Learning 디자이너의 파이프라인 및 데이터 세트 예제
Azure Machine Learning 디자이너에서 기본 제공되는 예제를 사용하여 고유한 기계 학습 파이프라인 빌드를 신속하게 시작합니다. Azure Machine Learning 디자이너 GitHub 리포지토리는 몇 가지 일반적인 기계 학습 시나리오를 이해하는 데 도움이 되는 자세한 설명서를 포함합니다.
필수 구성 요소
- Azure 구독 Azure 구독이 없는 경우 체험 계정 만들기
- Azure Machine Learning 작업 영역
Important
스튜디오 또는 디자이너의 단추와 같이 이 문서에 언급된 그래픽 요소가 보이지 않는 경우 작업 영역에 대한 적절한 사용 권한이 없는 것일 수 있습니다. Azure 구독 관리자에게 문의하여 적절한 액세스 권한이 부여되었는지 확인하세요. 자세한 내용은 사용자 및 역할 관리를 참조하세요.
샘플 파이프라인 사용
디자이너는 샘플 파이프라인의 복사본을 스튜디오 작업 영역에 저장합니다. 파이프라인을 편집하여 사용자의 요구에 맞게 조정하고 사용자의 파이프라인으로 저장할 수 있습니다. 이를 시작점으로 사용하여 프로젝트를 신속하게 시작합니다.
디자이너 샘플을 사용하는 방법은 다음과 같습니다.
ml.azure.com에 로그인하고, 사용하려는 작업 영역을 선택합니다.
디자이너를 선택합니다.
새 파이프라인 섹션에서 샘플 파이프라인을 선택합니다.
샘플의 전체 목록을 보려면 더 많은 샘플 표시를 선택합니다.
파이프라인을 실행하려면 먼저 파이프라인을 실행할 기본 컴퓨팅 대상을 설정해야 합니다.
캔버스 오른쪽에 있는 설정 창에서 컴퓨팅 대상 선택을 선택합니다.
표시되는 대화 상자에서 기존 컴퓨팅 대상을 선택하거나 새로 만듭니다. 저장을 선택합니다.
캔버스 맨 위에 있는 제출을 선택하여 파이프라인 작업을 제출합니다.
샘플 파이프라인 및 컴퓨팅 설정에 따라 작업을 완료하는 데 다소 시간이 걸릴 수 있습니다. 기본 컴퓨팅 설정의 최소 노드 크기는 0입니다. 즉, 디자이너가 유휴 상태가 된 후에 리소스를 할당해야 합니다. 컴퓨팅 리소스가 이미 할당되었기 때문에 반복되는 파이프라인 작업은 시간이 덜 걸립니다. 또한 디자이너는 각 구성 요소에 대해 캐시된 결과를 사용하여 효율성을 더욱 향상시킵니다.
파이프라인 실행이 완료되면 파이프라인을 검토하고 각 구성 요소의 출력을 확인하여 자세히 알아볼 수 있습니다. 다음 단계를 사용하여 구성 요소 출력을 봅니다.
- 표시하려는 출력의 캔버스에서 구성 요소를 마우스 오른쪽 단추로 클릭합니다.
- 시각화를 선택합니다.
가장 일반적인 기계 학습 시나리오 중 일부에 대한 샘플을 시작점으로 사용합니다.
회귀
이러한 기본 제공 회귀 샘플을 살펴보세요.
| 샘플 제목 | 설명 |
|---|---|
| 회귀 - 자동차 가격 예측(기본) | 선형 회귀를 사용하여 자동차 가격을 예측합니다. |
| 회귀 - 자동차 가격 예측(고급) | 의사 결정 포리스트와 향상된 의사 결정 트리 회귀 변수를 사용하여 자동차 가격을 예측합니다. 모델을 비교하여 가장 적합한 알고리즘을 찾습니다. |
분류
이러한 기본 제공 분류 샘플을 살펴보세요. 샘플을 열고 디자이너에서 구성 요소 주석을 보면 샘플에 대해 자세히 알아볼 수 있습니다.
| 샘플 제목 | 설명 |
|---|---|
| 기능 선택을 통한 이진 분류 - 수입 예측 | 2클래스 향상된 의사 결정 트리를 사용하여 수입을 높음 또는 낮음으로 예측합니다. 피어슨 상관 관계를 사용하여 기능을 선택합니다. |
| 사용자 지정 Python 스크립트를 통한 이진 분류 - 신용 위험 예측 | 신용 애플리케이션을 위험 수준 높음 또는 위험 수준 낮음으로 분류합니다. Python 스크립트 실행 구성 요소를 사용하여 데이터에 가중치를 부여합니다. |
| 이진 분류 - 고객 관계 예측 | 2클래스 향상된 의사 결정 트리를 사용하여 고객 이탈을 예측합니다. SMOTE를 사용하여 편향 데이터를 샘플링합니다. |
| 텍스트 분류 - Wikipedia SP 500 데이터 세트 | 다중 클래스 로지스틱 회귀를 사용하여 Wikipedia 문서의 회사 유형을 분류합니다. |
| 다중 클래스 분류 - 문자 인식 | 작성된 문자를 분류하는 이진 분류자의 앙상블을 만듭니다. |
컴퓨터 비전
기본 제공 컴퓨터 비전 예제를 살펴보세요. 샘플을 열고 디자이너에서 구성 요소 주석을 보면 샘플에 대해 자세히 알아볼 수 있습니다.
| 샘플 제목 | 설명 |
|---|---|
| DenseNet을 통한 이미지 분류 | 컴퓨터 비전 구성 요소를 통해 PyTorch DenseNet을 기반으로 하여 이미지 분류 모델을 빌드합니다. |
추천
이러한 기본 제공 추천 샘플을 살펴보세요. 샘플을 열고 디자이너에서 구성 요소 주석을 보면 샘플에 대해 자세히 알아볼 수 있습니다.
| 샘플 제목 | 설명 |
|---|---|
| 광범위한 심층 분석 기반 추천 - 식당 등급 예측 | 식당/사용자 특성 및 등급에서 식당 추천 엔진을 빌드합니다. |
| 권장 사항 - 영화 등급 트윗 | 영화/사용자 기능 및 등급에서 영화 추천 엔진을 빌드합니다. |
Utility
기계 학습 유틸리티 및 기능을 보여 주는 샘플에 대해 자세히 알아보세요. 샘플을 열고 디자이너에서 구성 요소 주석을 보면 샘플에 대해 자세히 알아볼 수 있습니다.
| 샘플 제목 | 설명 |
|---|---|
| Vowpal Wabbit 모델을 통한 이진 분류 - 성인 수입 예측 | Vowpal Wabbit은 온라인, 해싱, allreduce, 감소, learning2search, 활성 및 대화형 학습과 같은 기술을 사용하여 기계 학습의 경계를 넓히고 있는 기계 학습 시스템입니다. 이 샘플에서는 Vowpal Wabbit 모델을 통해 이진 분류 모델을 빌드하는 방법을 보여 줍니다. |
| 사용자 지정 R 스크립트 사용 - 항공편 지연 예측 | 사용자 지정 R 스크립트를 통해 예약된 승객 항공편이 15분 넘게 지연되는지 여부를 예측합니다. |
| 이진 분류자 교차 유효성 검사 - 성인 수입 예측 | 교차 유효성 검사를 사용하여 성인 수입에 대한 이진 분류자를 빌드합니다. |
| 순열 기능 중요도 | 순열 기능 중요도를 사용하여 테스트 데이터 세트의 중요도 점수를 계산합니다. |
| 이진 분류자 매개 변수 튜닝 - 성인 수입 예측 | 모델 하이퍼 매개 변수 튜닝을 사용하여 이진 분류자를 빌드하기 위한 최적의 하이퍼 매개 변수를 찾습니다. |
데이터 집합
Azure Machine Learning 디자이너에서 새 파이프라인을 만들 때 다양한 샘플 데이터 세트가 기본적으로 포함됩니다. 이러한 샘플 데이터 세트는 디자이너 홈페이지의 샘플 파이프라인에서 사용됩니다.
샘플 데이터 세트는 데이터 세트-샘플 범주에서 사용할 수 있습니다. 디자이너의 캔버스 왼쪽에 있는 구성 요소 팔레트에서 찾을 수 있습니다. 캔버스로 끌어와 이러한 데이터 세트를 파이프라인에서 사용할 수 있습니다.
| 데이터 세트 이름 | 데이터 세트 설명 |
|---|---|
| 성인 인구 조사 소득 이진 분류 데이터 세트 | 조정 소득 지수가 100보다 큰 16세 이상 취업한 성인을 대상으로 한 1994 인구 조사 데이터베이스의 하위 집합입니다. 사용: 인구 통계를 기반으로 사람을 분류하여 개인의 소득이 연간 50,000을 초과할지 예측합니다. 관련 조사: Kohavi, R., Becker, B., (1996). UCI Machine Learning 리포지토리 Irvine, CA: University of California, School of Information and Computer Science |
| 자동차 가격 데이터(원시) | 가격, 실린더 및 MPG 수와 같은 기능, 보험 위험 점수를 포함하여 상표 및 모델별 자동차에 대한 정보입니다. 위험 점수는 처음에 자동차 가격과 연관이 있습니다. 그런 다음 보험 회계사에게 기호화로 알려진 프로세스에서 실제 위험에 맞게 조정됩니다. +3 값은 자동차가 위험함을 나타내고 -3 값은 안전함을 나타냅니다. 사용: 회귀 및 다변수 분류를 사용하여 기능별 위험 점수를 예측합니다. 관련 연구: Schlimmer, J.C. (1987). UCI Machine Learning 리포지토리 Irvine, CA: University of California, School of Information and Computer Science. |
| CRM 욕구 레이블 공유 | KDD Cup 2009 고객 관계 예측 챌린지의 레이블(orange_small_train_appetency.labels). |
| CRM 이탈 레이블 공유 | KDD Cup 2009 고객 관계 예측 챌린지의 레이블(orange_small_train_churn.labels). |
| CRM 데이터 세트 공유 | 이 데이터는 KDD Cup 2009 고객 관계 예측 챌린지(orange_small_train.data.zip)에서 제공됩니다. 데이터 세트에는 French Telecom 회사인 Orange의 고객 50,000명이 포함됩니다. 각 고객은 익명으로 처리되는 230개 기능을 가지며, 이 중 190개는 숫자이고 40개는 범주입니다. 기능이 매우 희박합니다. |
| CRM 상향 판매 레이블 공유 | KDD Cup 2009 고객 관계 예측 챌린지의 레이블(orange_large_train_upselling.labels) |
| 비행 지연 데이터 | 미국 운수부 TranStats 데이터 컬렉션에서 가져온 여객기 운항정시성 데이터(정시) 데이터 세트는 2013년 4월-10월 기간에 해당합니다. 디자이너로 업로드하기 전에 데이터 세트는 다음과 같이 처리되었습니다. - 데이터 세트는 미국 본토에서 비행이 가장 많은 공항 70곳만을 포함하도록 필터링되었습니다. - 취소된 비행은 15분 초과 지연으로 레이블이 지정되었습니다. - 우회 비행은 필터링되었습니다. - 다음 열이 선택되었습니다. Year, Month, DayofMonth, DayOfWeek, Carrier, OriginAirportID, DestAirportID, CRSDepTime, DepDelay, DepDel15, CRSArrTime, ArrDelay, ArrDel15, Canceled |
| 독일 신용 카드 UCI 데이터 세트 | german.data 파일을 사용한 UCI Statlog(독일 신용 카드) 데이터 세트(Statlog+German+Credit+Data). 데이터 세트는 특성 집합으로 설명된 사람을 낮은 신용 위험 또는 높은 신용 위험으로 분류합니다. 각 예제는 개인을 나타냅니다. 숫자 및 범주의 기능 20개와 이진 레이블(신용 위험 값)이 있습니다. 높은 신용 위험 항목의 레이블은 2이고, 낮은 신용 위험 항목의 레이블은 1입니다. 낮은 위험 예제를 높은 위험으로 잘못 분류한 비용은 1이지만, 높은 위험 예제를 낮은 위험으로 분류한 비용은 5입니다. |
| IMDB 영화 제목 | 이 데이터 세트에는 Twitter 트윗에서 평가된 영화에 대한 정보가 포함됩니다(IMDB 영화 ID, 영화 제목, 장르, 제작 연도). 이 데이터 세트에는 170,000 개의 영화가 있습니다. 데이터 세트는 논문 "S. Dooms, T. De Pessemier 및 L. Martens. MovieTweetings: a Movie Rating Dataset Collected From Twitter. Workshop on Crowdsourcing and Human Computation for Recommender Systems, CrowdRec at RecSys 2013"에서 소개되었습니다. |
| 영화 등급 | 이 데이터 세트는 Movie Tweetings 데이터 세트의 확장된 버전입니다. 이 데이터 세트에는 잘 구성된 Twitter 트윗에서 추출한 170,000개의 영화 등급이 있습니다. 각 인스턴스는 트윗을 나타내며 사용자 ID, IMDB 영화 ID, 등급, 타임 스탬프, 해당 트윗에 대한 즐겨찾기 수, 해당 트윗의 리트윗 수 등과 같은 튜플입니다. 이 데이터 세트는 A. Said, S. Dooms, B. Loni 및 D. Tikk가 Recommender Systems Challenge 2014를 위해 제공했습니다. |
| 날씨 데이터 세트 | NOAA에서 제공한 시간별 지상 기상 관측(201304부터 201310까지의 병합된 데이터). 기상 데이터는 2013년 4월-10월 기간에 공항 기상 관측소에서 수행된 관측을 포함합니다. 디자이너로 업로드하기 전에 데이터 세트는 다음과 같이 처리되었습니다. - 날씨 관측소 ID가 해당 공항 ID에 매핑되었습니다. - 비행이 가장 많은 공항 70곳과 연계되지 않은 기상 관측소가 필터링되었습니다. - Date 열은 Year, Month 및 Day 열로 분할되었습니다. - 다음 열이 선택되었습니다. AirportID, Year, Month, Day, Time, TimeZone, SkyCondition, Visibility, WeatherType, DryBulbFarenheit, DryBulbCelsius, WetBulbFarenheit, WetBulbCelsius, DewPointFarenheit, DewPointCelsius, RelativeHumidity, WindSpeed, WindDirection, ValueForWindCharacter, StationPressure, PressureTendency, PressureChange, SeaLevelPressure, RecordType, HourlyPrecip, Altimeter |
| Wikipedia SP 500 데이터 세트 | 데이터는 XML 데이터로 저장되는 각 S&P 500 회사의 자료에 따라 Wikipedia(https://www.wikipedia.org/)에서 파생됩니다. 디자이너로 업로드하기 전에 데이터 세트는 다음과 같이 처리되었습니다. - 각 특정 회사에 대한 텍스트 콘텐츠 추출 - 위치 형식 지정 제거 - 영숫자가 아닌 문자 제거 - 모든 텍스트를 소문자로 변환 - 알려진 회사 범주가 추가됨 일부 회사의 경우 문서를 찾을 수 없으므로 레코드 수가 500개 미만입니다. |
| 음식점 기능 데이터 | 음식점 및 음식 종료, 식사 스타일, 위치 같은 기능에 대한 메타데이터 집합입니다. 사용: 이 데이터 세트를 다른 두 가지 음식점 데이터 세트와 함께 사용하여 추천 시스템을 학습 및 테스트합니다. 관련 조사: Bache, K. and Lichman, M. (2013). UCI Machine Learning 리포지토리 Irvine, CA: University of California, School of Information and Computer Science. |
| 음식점 등급 | 0-2점 사이에 사용자가 제공한 음식점 등급을 포함합니다. 사용: 이 데이터 세트를 다른 두 가지 음식점 데이터 세트와 함께 사용하여 추천 시스템을 학습 및 테스트합니다. 관련 조사: Bache, K. and Lichman, M. (2013). UCI Machine Learning 리포지토리 Irvine, CA: University of California, School of Information and Computer Science. |
| 음식점 고객 데이터 | 인구 통계 및 선호도를 비롯한 고객에 대한 메타데이터 집합입니다. 사용: 이 데이터 세트를 다른 두 가지 음식점 데이터 세트와 함께 사용하여 추천 시스템을 학습 및 테스트합니다. 관련 조사: Bache, K. and Lichman, M. (2013). UCI Machine Learning 리포지토리 Irvine, CA: University of California, School of Information and Computer Science. |
리소스 정리
Important
만든 리소스를 다른 Azure Machine Learning 자습서 및 사용 방법 문서의 필수 구성 요소로 사용할 수 있습니다.
모든 항목 삭제
사용자가 만든 항목을 사용하지 않으려면 요금이 발생하지 않도록 전체 리소스 그룹을 삭제하세요.
Azure Portal의 창 왼쪽에서 리소스 그룹을 선택합니다.
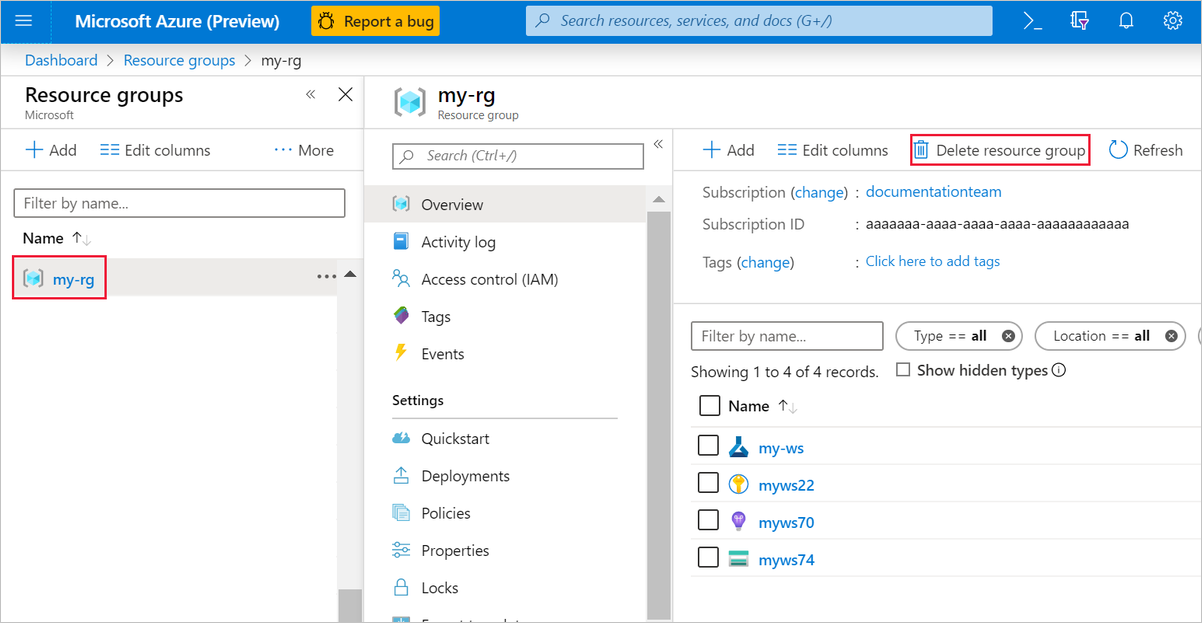
목록에서 만든 리소스 그룹을 선택합니다.
리소스 그룹 삭제를 선택합니다.
리소스 그룹을 삭제하면 디자이너에서 만든 모든 리소스도 삭제됩니다.
개별 자산 삭제
실험을 만든 디자이너에서 개별 자산을 선택한 다음, 삭제 단추를 선택하여 자산을 삭제합니다.
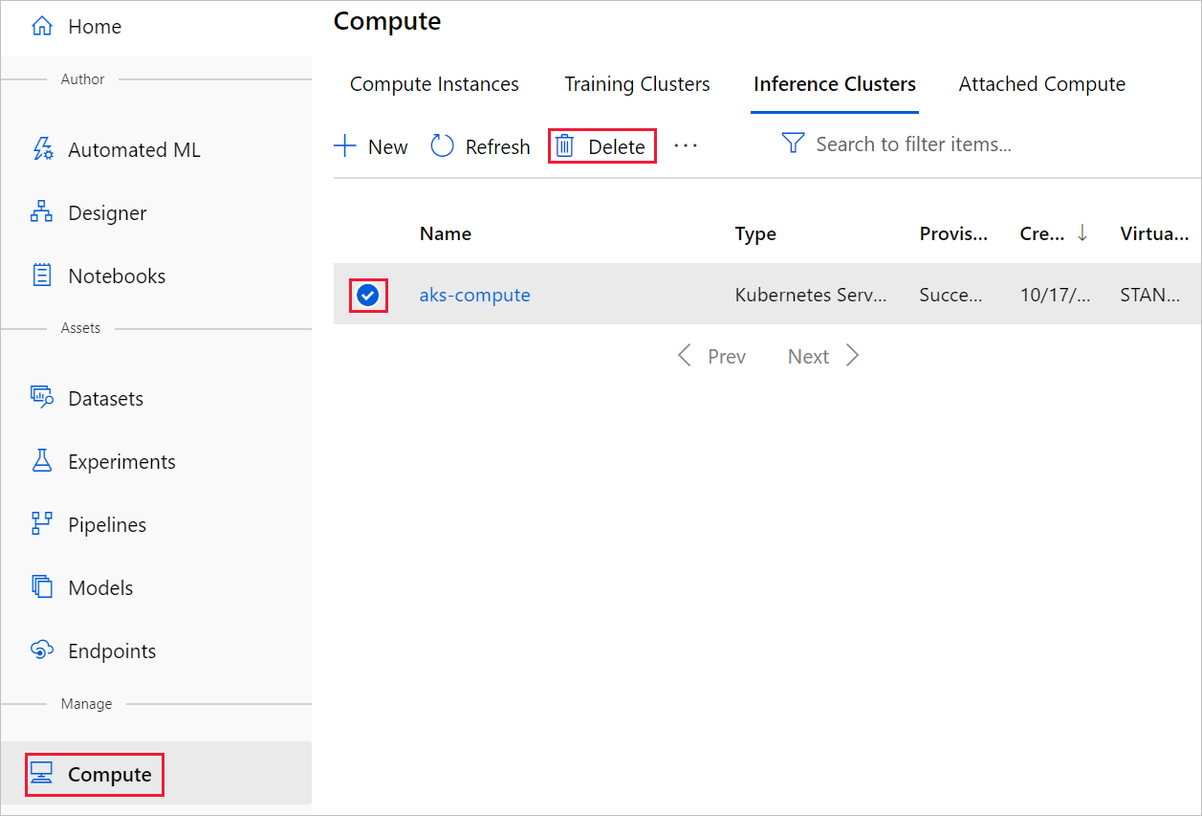
여기에서 만든 컴퓨팅 대상은 사용하지 않을 경우 제로 노드로 자동으로 크기 조정됩니다. 이 작업은 요금을 최소화하기 위해 수행됩니다. 컴퓨팅 대상을 삭제하려는 경우 다음 단계를 수행합니다.
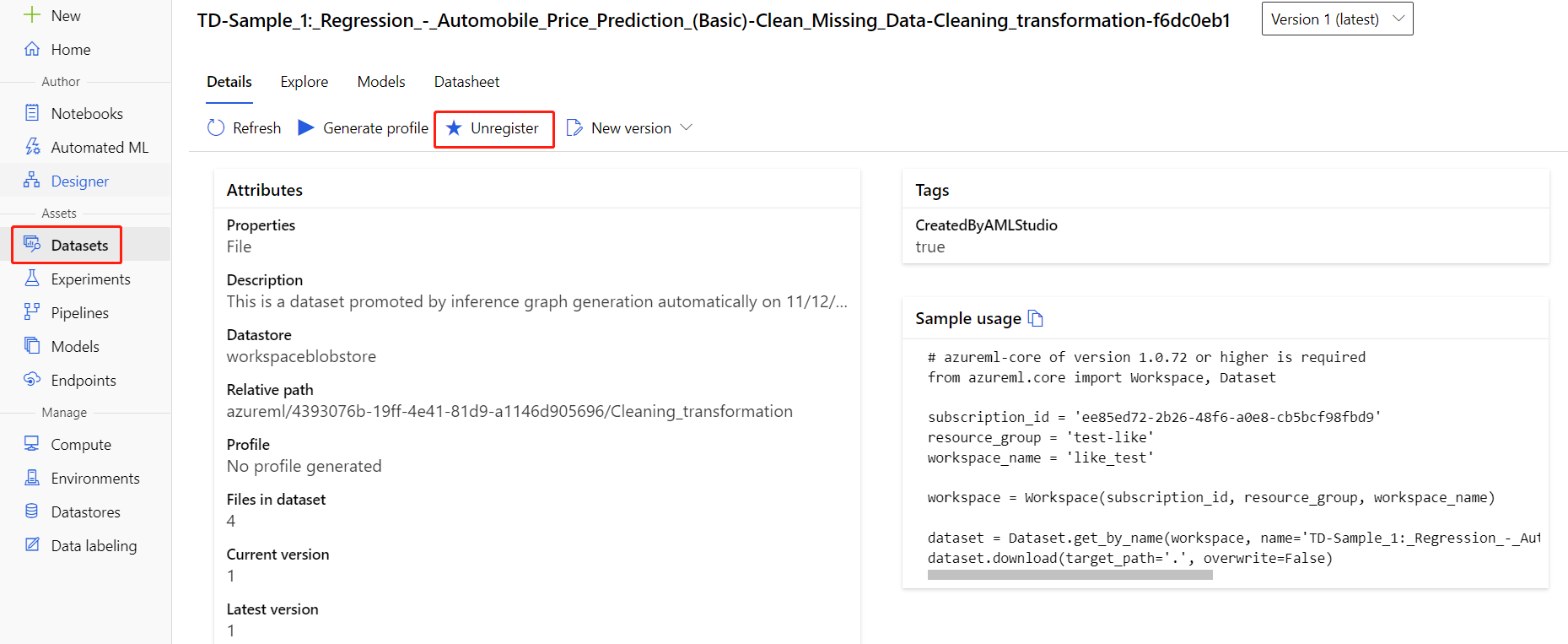
각 데이터 세트를 선택하고 등록 취소를 선택하여 작업 영역에서 데이터 세트를 등록 취소할 수 있습니다.
데이터 세트를 삭제하려면 Azure Portal 또는 Azure Storage Explorer를 사용하여 스토리지 계정으로 이동하여 해당 자산을 수동으로 삭제합니다.
다음 단계
자습서: 디자이너와 함께 자동차 가격 예측을 통해 예측 분석 및 기계 학습의 기본 사항을 알아봅니다.