자습서: 클라우드 워크스테이션에서 모델 개발
Azure Machine Learning 클라우드 워크스테이션에서 Notebook을 사용하여 학습 스크립트를 개발하는 방법을 알아봅니다. 이 자습서에서는 시작하는 데 필요한 기본 사항을 다룹니다.
- 클라우드 워크스테이션을 설정하고 구성합니다. 클라우드 워크스테이션은 다양한 모델 개발 요구 사항을 지원하는 환경으로 미리 구성된 Azure Machine Learning 컴퓨팅 인스턴스로 구동됩니다.
- 클라우드 기반 개발 환경을 사용합니다.
- MLflow를 사용하여 Notebook 내에서 모델 메트릭을 모두 추적합니다.
필수 조건
Azure Machine Learning을 사용하려면 작업 영역이 필요합니다. 작업 영역이 없으면 시작하는 데 필요한 리소스 만들기를 완료하여 작업 영역을 만들고 사용 방법에 대해 자세히 알아봅니다.
Important
Azure Machine Learning 작업 영역이 관리형 가상 네트워크로 구성된 경우 공용 Python 패키지 리포지토리에 대한 액세스를 허용하는 아웃바운드 규칙을 추가해야 할 수 있습니다. 자세한 내용은 시나리오: 공용 기계 학습 패키지에 액세스합니다.
컴퓨팅 시작
작업 영역의 컴퓨팅 섹션에서 컴퓨팅 리소스를 만들 수 있습니다. 컴퓨팅 인스턴스는 Azure Machine Learning에서 완전히 관리되는 클라우드 기반 워크스테이션입니다. 이 자습서 시리즈에서는 컴퓨팅 인스턴스를 사용합니다. 사용자 고유의 코드를 실행하고 모델을 개발하고 테스트하는 데 사용할 수도 있습니다.
- Azure Machine Learning Studio에 로그인합니다.
- 아직 열려 있지 않은 경우 작업 영역을 선택합니다.
- 왼쪽 탐색 창에서 컴퓨팅을 선택합니다.
- 컴퓨팅 인스턴스가 없는 경우 화면 중간에 새로 만들기가 표시됩니다. 새로 만들기를 선택하고 양식을 작성합니다. 모든 기본값을 사용할 수 있습니다.
- 컴퓨팅 인스턴스가 있는 경우 목록에서 선택합니다. 중지된 경우 시작을 선택합니다.
VS Code(Visual Studio Code) 열기
실행 중인 컴퓨팅 인스턴스가 있으면 다양한 방법으로 액세스할 수 있습니다. 이 자습서에서는 VS Code에서 컴퓨팅 인스턴스를 사용하는 방법을 보여 줍니다. VS Code는 Azure Machine Learning 리소스의 기능을 갖춘 전체 IDE(통합 개발 환경)를 제공합니다.
컴퓨팅 인스턴스 목록에서 사용하려는 컴퓨팅 인스턴스에 대한 VS Code(웹) 또는 VS Code(데스크톱) 링크를 선택합니다. VS Code(데스크톱)을 선택하면 애플리케이션을 열 것인지 묻는 팝업이 표시될 수 있습니다.

이 VS Code 인스턴스는 컴퓨팅 인스턴스 및 작업 영역 파일 시스템에 연결됩니다. 바탕 화면에서 열더라도 표시되는 파일은 작업 영역에 있는 파일입니다.
프로토타입 제작을 위한 새 환경 설정(선택 사항)
스크립트를 실행하려면 코드에서 예상하는 종속성과 라이브러리로 구성된 환경에서 작업해야 합니다. 이 섹션에서는 코드에 맞는 환경을 만드는 데 도움이 됩니다. Notebook이 연결되는 새로운 Jupyter 커널을 만들려면 종속성을 정의하는 YAML 파일을 사용합니다.
파일을 업로드합니다.
업로드하는 파일은 Azure 파일 공유에 저장되며, 이러한 파일은 각 컴퓨팅 인스턴스에 탑재되고 작업 영역 내에서 공유됩니다.
오른쪽 상단에 있는 원시 파일 다운로드 단추를 사용하여 Conda 환경 파일인 workstation_env.yml을 컴퓨터에 다운로드합니다.
컴퓨터에서 VS Code 창으로 파일을 끌어옵니다. 파일이 작업 영역에 업로드됩니다.
사용자 이름 폴더 아래의 파일을 이동합니다.
이 파일을 선택하여 미리 보고 지정된 종속성을 확인합니다. 다음과 같은 콘텐츠가 표시됩니다.
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlib커널을 만듭니다.
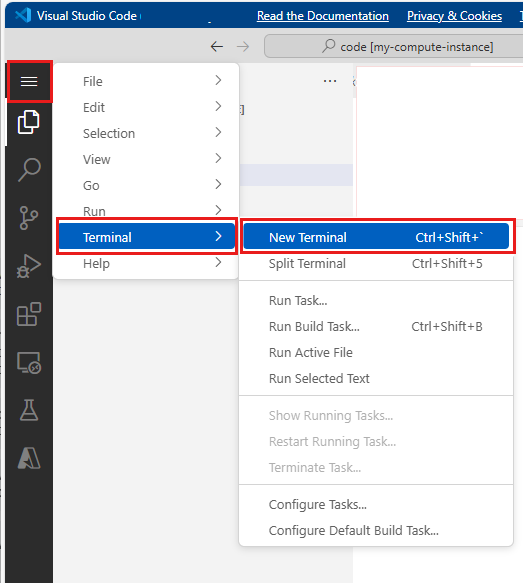
이제 터미널을 사용하여 workstation_env.yml 파일을 기반으로 새 Jupyter 커널을 만듭니다.
위쪽 메뉴 모음에서 터미널 > 새 터미널을 선택합니다.
현재 Conda 환경을 확인합니다. 활성 환경에는 *가 표시됩니다.
conda env listworkstation_env.yml파일을 업로드한 폴더로
cd. 예를 들어 사용자 폴더에 업로드한 경우:cd Users/myusernameworkstation_env.yml이 이 폴더에 있는지 확인합니다.
ls제공된 conda 파일을 기반으로 환경을 만듭니다. 이 환경을 빌드하는 데 몇 분 정도 걸립니다.
conda env create -f workstation_env.yml새 환경을 활성화합니다.
conda activate workstation_env참고 항목
CommandNotFoundError가 표시되면 지침에 따라
conda init bash을(를) 실행하고 터미널을 닫고 새 터미널을 엽니다. 그런 다음conda activate workstation_env명령을 다시 시도합니다.올바른 환경이 활성화되어 있는지 유효성을 검사하고 *로 표시된 환경을 다시 찾습니다.
conda env list활성 환경을 기반으로 새 Jupyter 커널을 만듭니다.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"터미널 창을 닫습니다.
이제 새로운 커널이 생겼습니다. 다음으로 Notebook을 열고 이 커널을 사용할 예정입니다.
Notebook 만들기
- 위쪽 메뉴 모음에서 파일 > 새 파일을 선택합니다.
- develop-tutorial.ipynb로 새 파일의 이름을 지정하거나 원하는 이름을 입력합니다. .ipynb 확장을 사용해야 합니다.
커널 설정
- 오른쪽 위에서 커널 선택을 선택합니다.
- Azure ML 컴퓨팅 인스턴스(computeinstance-name)를 선택합니다.
- 만든 커널을 선택합니다(자습서 워크스테이션 Env). 표시되지 않으면 오른쪽 위에 있는 새로 고침 도구를 선택합니다.
학습 스크립트 개발
이 섹션에서는 UCI 데이터 세트에서 준비된 테스트 및 학습 데이터 세트를 사용하여 신용 카드 기본 결제를 예측하는 Python 학습 스크립트를 개발합니다.
이 코드는 학습에는 sklearn을 사용하고 메트릭 로깅에는 MLflow를 사용합니다.
학습 스크립트에서 사용할 패키지와 라이브러리를 가져오는 코드로 시작합니다.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_split다음으로 이 실험에 대한 데이터를 로드하고 처리합니다. 이 자습서에서는 인터넷에 있는 파일의 데이터를 읽습니다.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )학습을 위해 데이터를 준비합니다.
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.values메트릭과 결과를 추적할 수 있도록
MLflow를 사용하여 자동 로깅을 시작하는 코드를 추가합니다. 모델 개발의 반복적 특성을 통해MLflow는 모델 매개 변수 및 결과를 기록하는 데 도움이 됩니다. 해당 실행을 다시 참조하여 모델 성능을 비교하고 이해합니다. 또한 로그는 Azure Machine Learning 내에서 워크플로의 개발 단계에서 학습 단계로 이동할 준비가 된 시기에 대한 컨텍스트를 제공합니다.# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()모델을 학습합니다.
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()참고 항목
mlflow 경고는 무시할 수 있습니다. 추적해야 하는 모든 결과는 계속해서 가져올 수 있습니다.
Iterate
이제 모델 결과가 있으므로 무언가를 변경하고 다시 시도할 수 있습니다. 예를 들어, 다른 분류자 기술을 사용해 보세요.
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()참고 항목
mlflow 경고는 무시할 수 있습니다. 추적해야 하는 모든 결과는 계속해서 가져올 수 있습니다.
결과 검사
두 가지 다른 모델을 시도했으므로 이제 MLFfow에서 추적한 결과를 사용하여 어떤 모델이 더 나은지 결정합니다. 정확도와 같은 메트릭이나 시나리오에 가장 중요한 기타 메트릭을 참조할 수 있습니다.
MLflow에 의해 만들어진 일자리를 살펴보면 이러한 결과를 더 자세히 알아볼 수 있습니다.
Azure Machine Learning 스튜디오의 작업 영역으로 돌아갑니다.
왼쪽 탐색 영역에서 작업을 선택합니다.
클라우드 기반 개발 자습서 링크를 선택합니다.
시도한 각 모델에 대해 하나씩 두 가지 다른 작업이 표시됩니다. 이러한 이름은 자동 생성됩니다. 이름 위에 마우스를 가리키고 이름을 바꾸려면 이름 옆에 있는 연필 도구를 사용합니다.
첫 번째 작업에 대한 링크를 선택합니다. 이름이 상단에 나타납니다. 여기에서 연필 도구를 사용하여 이름을 바꿀 수도 있습니다.
이 페이지에는 속성, 출력, 태그, 매개 변수 등 작업의 세부 정보가 표시됩니다. 태그 아래에는 모델 형식을 설명하는 estimator_name이 표시됩니다.
MLflow에서 기록한 메트릭을 보려면 메트릭 탭을 선택합니다. (학습 집합이 다르기 때문에 결과가 다를 수 있습니다.)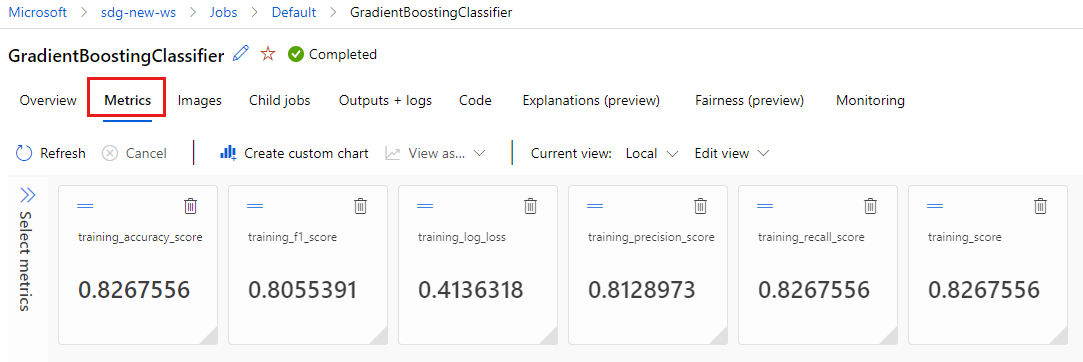
MLflow에서 생성된 이미지를 보려면 이미지 탭을 선택합니다.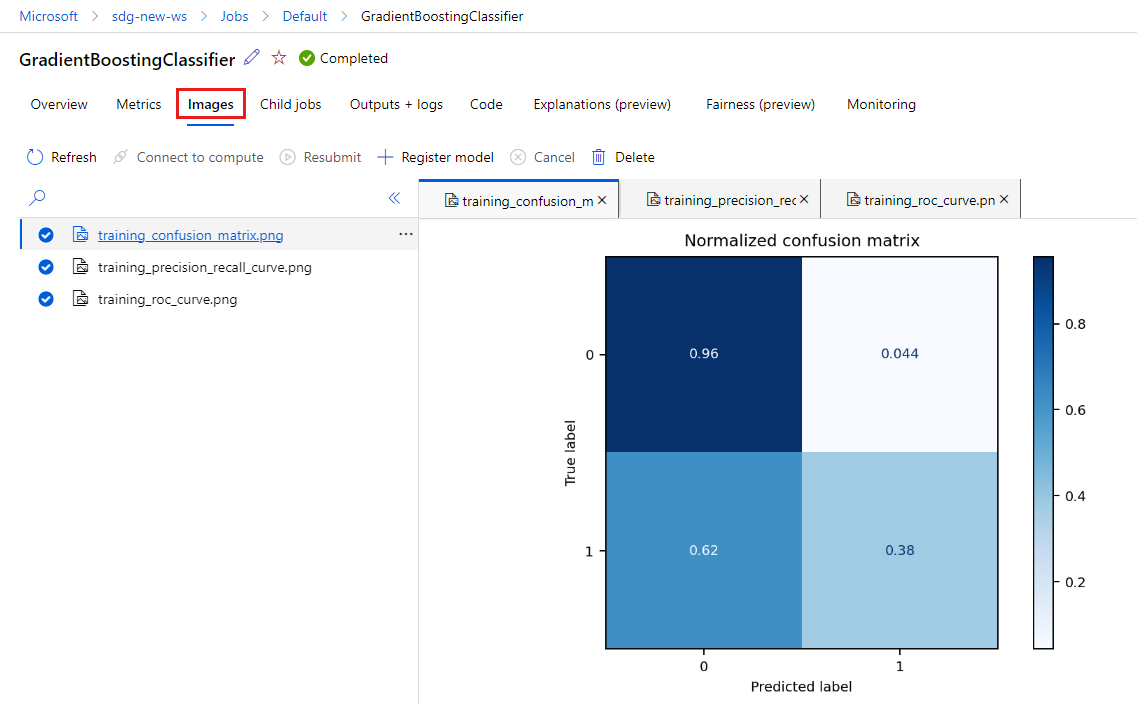
돌아가서 다른 모델의 메트릭과 이미지를 검토합니다.
Python 스크립트 만들기
이제 모델 학습을 위해 Notebook에서 Python 스크립트를 만듭니다.
VS Code 창에서 Notebook 파일 이름을 마우스 오른쪽 단추로 클릭하고 스크립트로 Notebook 가져오기를 선택합니다.
파일 > 저장 메뉴를 사용하여 이 새 스크립트 파일을 저장합니다. train.py라고 호명합니다.
이 파일을 살펴보고 학습 스크립트에서 원하지 않는 코드를 삭제합니다. 예를 들어, 사용하려는 모델의 코드는 유지하고, 원하지 않는 모델의 코드는 삭제합니다.
- 자동 로깅을 시작하는 코드(
mlflow.sklearn.autolog())를 유지합니다. - 여기서 수행하는 것처럼 Python 스크립트를 대화형으로 실행할 때 실험 이름(
mlflow.set_experiment("Develop on cloud tutorial"))을 정의하는 줄을 유지할 수 있습니다. 또는 작업 섹션에서 다른 항목으로 표시되도록 다른 이름을 지정할 수도 있습니다. 그러나 학습 작업을 위해 스크립트를 준비할 때 해당 줄은 적용되지 않으며 생략해야 합니다. 작업 정의에는 실험 이름이 포함됩니다. - 단일 모델을 학습할 때 실행을 시작하고 종료하는 줄(
mlflow.start_run()및mlflow.end_run())도 필요하지 않지만(효과가 없음) 원하는 경우 그대로 둘 수 있습니다.
- 자동 로깅을 시작하는 코드(
편집이 끝나면 파일을 저장합니다.
이제 기본 설정하는 모델을 학습하는 데 사용할 Python 스크립트가 생겼습니다.
Python 스크립트 실행
지금은 Azure Machine Learning 개발 환경인 컴퓨팅 인스턴스에서 이 코드를 실행하고 있습니다. 자습서: 모델 학습은 더 강력한 컴퓨팅 리소스에서 더 확장 가능한 방식으로 학습 스크립트를 실행하는 방법을 보여 줍니다.
이 자습서의 앞부분에서 만든 환경을 Python 버전(workstations_env)으로 선택합니다. Notebook의 오른쪽 아래에 환경 이름이 표시됩니다. 선택한 다음 화면 중간에 있는 환경을 선택합니다.
이제 Python 스크립트를 실행합니다. 오른쪽 위의 Python 파일 실행 도구를 사용합니다.
참고 항목
mlflow 경고는 무시할 수 있습니다. 자동 로깅에서 모든 메트릭과 이미지를 계속 가져올 수 있습니다.
스크립트 결과 검사
Azure Machine Learning 스튜디오의 작업 영역에서 작업으로 돌아가서 학습 스크립트의 결과를 확인합니다. 학습 데이터는 분할할 때마다 변경되므로 실행 간에도 결과가 달라집니다.
리소스 정리
지금 다른 자습서를 계속 진행하려면 다음 단계로 건너뛰세요.
컴퓨팅 인스턴스 중지
지금 사용하지 않으려면 컴퓨팅 인스턴스를 중지합니다.
- 스튜디오의 왼쪽 탐색 영역에서 컴퓨팅을 선택합니다.
- 맨 위 탭에서 컴퓨팅 인스턴스를 선택합니다.
- 목록에서 컴퓨팅 인스턴스를 선택합니다.
- 맨 위의 도구 모음에서 중지를 선택합니다.
모든 리소스 삭제
Important
사용자가 만든 리소스는 다른 Azure Machine Learning 자습서 및 방법 문서의 필수 구성 요소로 사용할 수 있습니다.
사용자가 만든 리소스를 사용하지 않으려면 요금이 발생하지 않도록 해당 리소스를 삭제합니다.
Azure Portal의 검색 상자에 리소스 그룹을 입력하고 결과에서 선택합니다.
목록에서 만든 리소스 그룹을 선택합니다.
개요 페이지에서 리소스 그룹 삭제를 선택합니다.
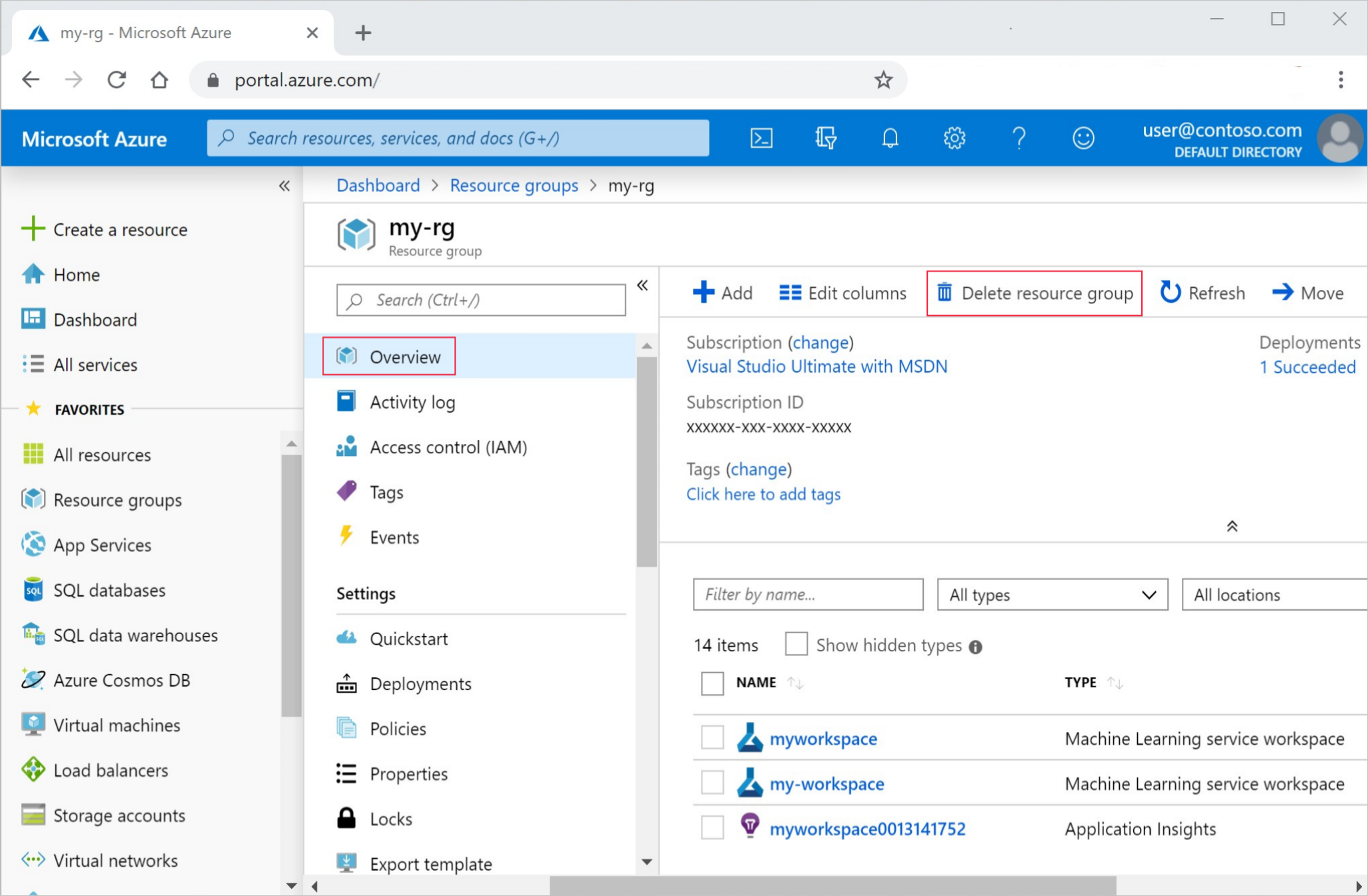
리소스 그룹 이름을 입력합니다. 그런 다음 삭제를 선택합니다.
다음 단계
자세히 알아보기:
- 아티팩트에서 MLflow 모델로
- Azure Machine Learning에서 Git 사용
- 작업 영역에서 Jupyter Notebooks 실행
- 작업 영역에서 컴퓨팅 인스턴스 터미널 작업
- Notebook 및 터미널 세션 관리
이 자습서에서는 모델을 만들고 코드가 있는 동일한 컴퓨터에서 프로토타입을 작성하는 초기 단계를 보여 주었습니다. 프로덕션 학습의 경우 보다 강력한 원격 컴퓨팅 리소스에서 해당 학습 스크립트를 사용하는 방법을 알아봅니다.