데이터 드리프트(미리 보기)가 사용 중지되고 모델 모니터로 대체됩니다.
데이터 드리프트(미리 보기)는 2025년 9월 1일부터 사용 중지되며 데이터 드리프트 작업에 모델 모니터를 사용할 수 있습니다. 아래 콘텐츠를 확인하여 교체, 기능 격차, 수동 변경 단계를 알아보세요.
적용 대상:  Python SDK azureml v1
Python SDK azureml v1
데이터 드리프트를 모니터링하고 드리프트가 높을 때 경고를 설정하는 방법을 알아봅니다.
참고 항목
Azure Machine Learning 모델 모니터링(v2)은 신호 및 메트릭을 모니터링하기 위한 추가 기능과 함께 개선된 데이터 드리프트 기능을 제공합니다. Azure Machine Learning(v2)의 모델 모니터링 기능에 대해 자세히 알아보려면 Azure Machine Learning을 사용한 모델 모니터링을 참조하세요.
Azure Machine Learning 데이터 세트 모니터(미리 보기)를 사용하여 다음을 수행할 수 있습니다.
- 데이터의 드리프트를 분석하여 시간별로 어떻게 변화하는지 파악합니다.
- 모델 데이터를 모니터링하여 학습 데이터 세트와 서비스 제공 데이터 세트의 차이를 파악합니다. 먼저 배포된 모델에서 모델 데이터를 수집합니다.
- 새로운 데이터를 모니터링하여 기준선과 대상 데이터 세트 간의 차이를 파악합니다.
- 데이터의 특징을 프로파일링하여 시간이 지나면서 통계 속성이 어떻게 변하는지 추적합니다.
- 잠재적 문제에 대한 조기 경고를 위해 데이터 드리프트에 대한 경고를 설정합니다.
- 데이터가 너무 많이 드리프트되었다고 확인되는 경우 새 데이터 세트 버전을 만듭니다.
Azure Machine Learning 데이터 세트는 모니터를 만드는 데 사용됩니다. 데이터 세트에는 타임스탬프 열이 포함되어야 합니다.
데이터 드리프트 메트릭은 Python SDK 또는 Azure Machine Learning 스튜디오에서 볼 수 있습니다. 다른 메트릭 및 인사이트는 Azure Machine Learning 작업 영역과 연결된 Azure Application Insights 리소스를 통해 제공됩니다.
Important
데이터 세트에 대한 데이터 드리프트 검색은 현재 공개 미리 보기로 제공됩니다. 미리 보기 버전은 서비스 수준 계약 없이 제공되며 프로덕션 워크로드에는 권장되지 않습니다. 특정 기능이 지원되지 않거나 기능이 제한될 수 있습니다. 자세한 내용은 Microsoft Azure Preview에 대한 추가 사용 약관을 참조하세요.
필수 조건
데이터 세트 모니터를 만들고 사용하려면 다음이 필요합니다.
- Azure 구독 Azure 구독이 아직 없는 경우 시작하기 전에 체험 계정을 만듭니다. 지금 Azure Machine Learning 평가판 또는 유료 버전을 사용해 보세요.
- Azure Machine Learning 작업 영역
- azureml-datasets 패키지가 포함된 Python용 Azure Machine Learning SDK가 설치되어 있습니다.
- 데이터의 열, 파일 경로 또는 파일 이름에 타임스탬프가 지정되어 있는 구조화된(테이블 형식) 데이터
필수 구성 요소(모델 모니터로 마이그레이션)
모델 모니터로 마이그레이션하는 경우 이 Azure Machine Learning 모델 모니터링의 필수 구성 요소 문서에 설명된 필수 구성 요소를 확인하세요.
데이터 드리프트란?
모델 정확도는 시간이 지남에 따라 저하되는데, 이는 주로 데이터 드리프트로 인해 발생합니다. 기계 학습 모델의 경우 데이터 드리프트는 모델의 성능 저하를 초래하는 모델 입력 데이터의 변화입니다. 데이터 드리프트를 모니터링하면 이러한 모델 성능 문제를 감지하는 데 도움이 됩니다.
데이터 드리프트의 원인은 다음과 같습니다.
- 업스트림 프로세스 변경(예: 센서가 교체되어 측정 단위가 인치에서 센티미터로 변경되는 경우)
- 데이터 품질 문제(예: 센서가 고장 나서 항상 0을 읽는 경우)
- 자연 발생적인 데이터 드리프트(예: 계절에 따라 변화하는 평균 기온)
- 특징 간의 관계 변화 또는 공변량 변화
Azure Machine Learning은 비교되는 데이터 세트의 복잡성을 추상화하는 단일 메트릭을 컴퓨팅하여 드리프트 검색을 간소화합니다. 이러한 데이터 세트에는 수백 개의 특징과 수만 개의 행이 있을 수 있습니다. 드리프트가 검색되면 어떤 특징이 드리프트를 유발하는지 드릴다운합니다. 그런 다음, 특징 수준 메트릭을 검사하여 드리프트의 근본 원인을 디버그하고 격리합니다.
이러한 하향식 접근 방식을 사용하면 기존의 규칙 기반 기술 대신 데이터를 쉽게 모니터링할 수 있습니다. 규칙 기반 기술(예 : 허용된 데이터 범위 또는 허용된 고유 값)은 시간이 많이 걸리고 오류가 발생하기 쉽습니다.
Azure Machine Learning에서는 데이터 세트 모니터를 사용하여 데이터 드리프트를 검색하고 경고합니다.
데이터 세트 모니터
데이터 세트 모니터를 사용하여 다음을 수행할 수 있습니다.
- 데이터 세트의 새 데이터에 대한 데이터 드리프트를 검색하고 경고합니다.
- 드리프트에 대한 과거 데이터를 분석합니다.
- 시간별 새 데이터를 프로파일링합니다.
데이터 드리프트 알고리즘은 데이터의 전반적인 변화를 측정하고 추가 조사를 유발하는 특징을 알려줍니다. 데이터 세트 모니터는 timeseries 데이터 세트에서 새 데이터를 프로파일링하여 다른 많은 메트릭을 생성합니다.
사용자 지정 경고는 Azure Application Insights를 통해 모니터에서 생성된 모든 메트릭에 대해 설정할 수 있습니다. 데이터 세트 모니터를 사용하면 데이터 문제를 빠르게 파악하고 가능한 원인을 식별하여 문제를 디버그하는 시간을 줄일 수 있습니다.
개념적으로 Azure Machine Learning에서 데이터 세트 모니터를 설정하는 세 가지 기본 시나리오가 있습니다.
| 시나리오 | 설명 |
|---|---|
| 모델의 제공 데이터가 학습 데이터에서 벗어나는지 모니터링 | 이 시나리오의 결과는 모델의 정확도에 대한 프록시 모니터링으로 해석될 수 있습니다. 제공 데이터가 학습 데이터에서 벗어나면 모델 정확도가 저하되기 때문입니다. |
| 시계열 데이터 세트가 이전 기간에서 벗어나는지 모니터링 | 이 시나리오는 보다 일반적이며 모델 빌드 업스트림 또는 다운스트림과 관련된 데이터 세트를 모니터링하는 데 사용할 수 있습니다. 대상 데이터 세트에는 타임스탬프 열이 있어야 합니다. 기준 데이터 세트는 대상 데이터 세트와 공통된 특징이 있는 테이블 형식의 데이터 세트일 수 있습니다. |
| 과거 데이터에 대한 분석 수행 | 이 시나리오는 기록 데이터를 이해하고 데이터 세트 모니터 설정에서 결정을 내리는 데 사용할 수 있습니다. |
데이터 세트 모니터는 다음 Azure 서비스에 따라 달라집니다.
| Azure 서비스 | 설명 |
|---|---|
| 데이터 세트 | 드리프트는 Machine Learning 데이터 세트를 사용하여 학습 데이터를 검색하고 모델 학습을 위해 데이터를 비교합니다. 데이터의 프로필 생성은 보고된 메트릭(예: 최소, 최대, 고유 값, 고유 값 수 등) 중 일부를 생성하는 데 사용됩니다. |
| Azure Machine Learning 파이프라인 및 컴퓨팅 | 드리프트 계산 작업은 Azure Machine Learning 파이프라인에서 호스트됩니다. 이 작업은 요청 시 또는 일정에 따라 트리거되어 드리프트 모니터 생성 시간에 구성된 컴퓨팅에서 실행됩니다. |
| 애플리케이션 인사이트 | 드리프트는 기계 학습 작업 영역에 속하는 Application Insights에 메트릭을 내보냅니다. |
| Azure Blob Storage | 드리프트는 Azure Blob Storage에 json 형식의 메트릭을 내보냅니다. |
기준 및 대상 데이터 세트
Azure Machine Learning 데이터 세트에서 데이터 드리프트를 모니터링합니다. 데이터 세트 모니터를 만들 때 다음을 참조하세요.
- 기준 데이터 세트 - 일반적으로 모델용 학습 데이터 세트입니다.
- 대상 데이터 세트(일반적으로 모델 입력 데이터) - 시간별로 기준 데이터 세트와 비교됩니다. 이렇게 비교하려면 대상 데이터 세트에 타임스탬프 열이 지정되어 있어야 합니다.
모니터는 기준 데이터 세트와 대상 데이터 세트를 비교합니다.
모델 모니터로 마이그레이션
모델 모니터에서 다음과 같은 해당 개념을 찾을 수 있으며, 이 Azure Machine Learning에 프로덕션 데이터를 가져와 모델 모니터링 설정 문서에서 자세한 내용을 찾을 수 있습니다.
- 참조 데이터 세트: 데이터 드리프트 검색을 위한 기준 데이터 세트와 유사하게, 최근 프로덕션 추론 데이터 세트로 설정됩니다.
- 프로덕션 추론 데이터: 데이터 드리프트 검색의 대상 데이터 세트와 유사하게, 프로덕션에 배포된 모델에서 프로덕션 추론 데이터를 자동으로 수집할 수 있습니다. 저장한 추론 데이터가 될 수도 있습니다.
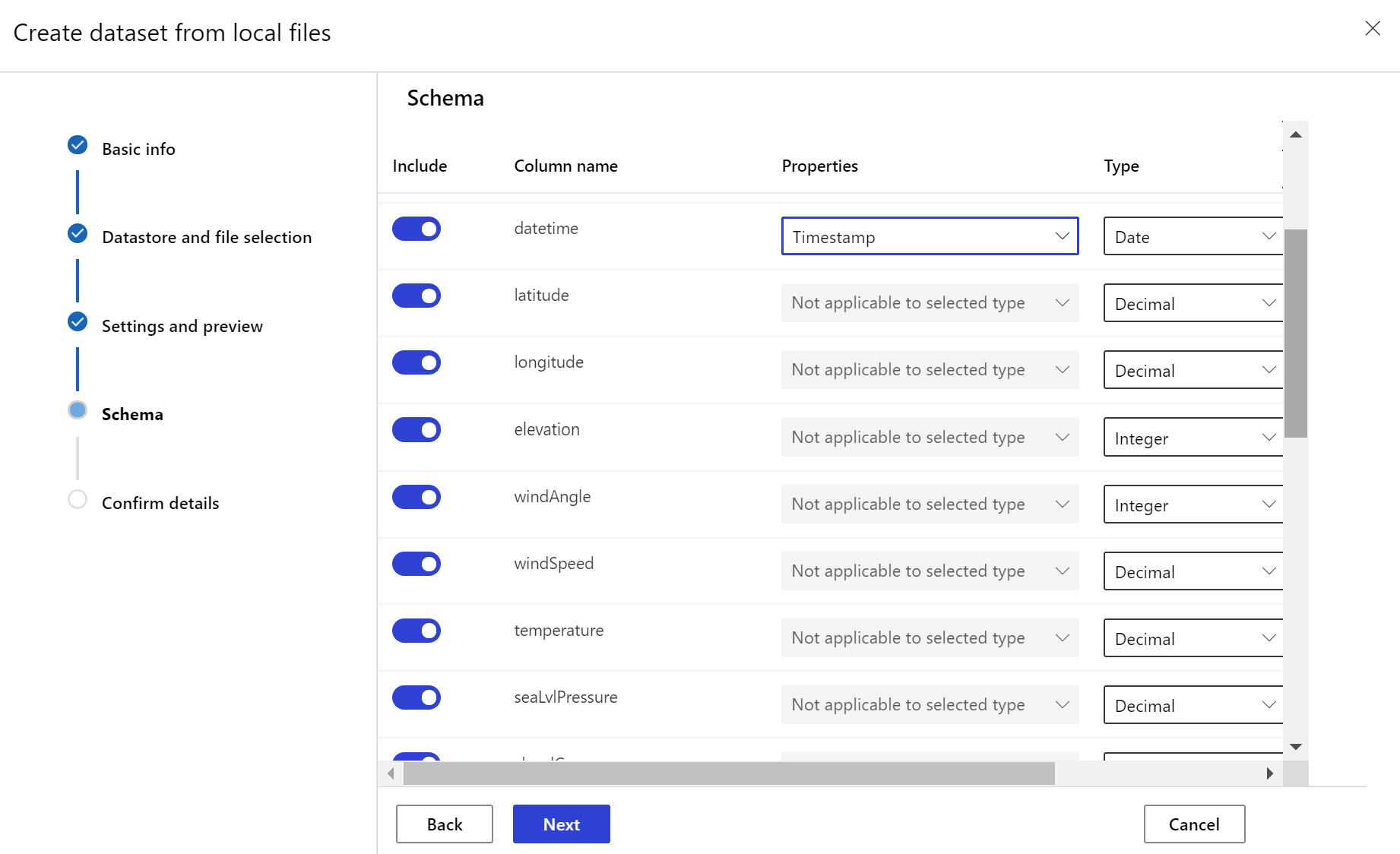
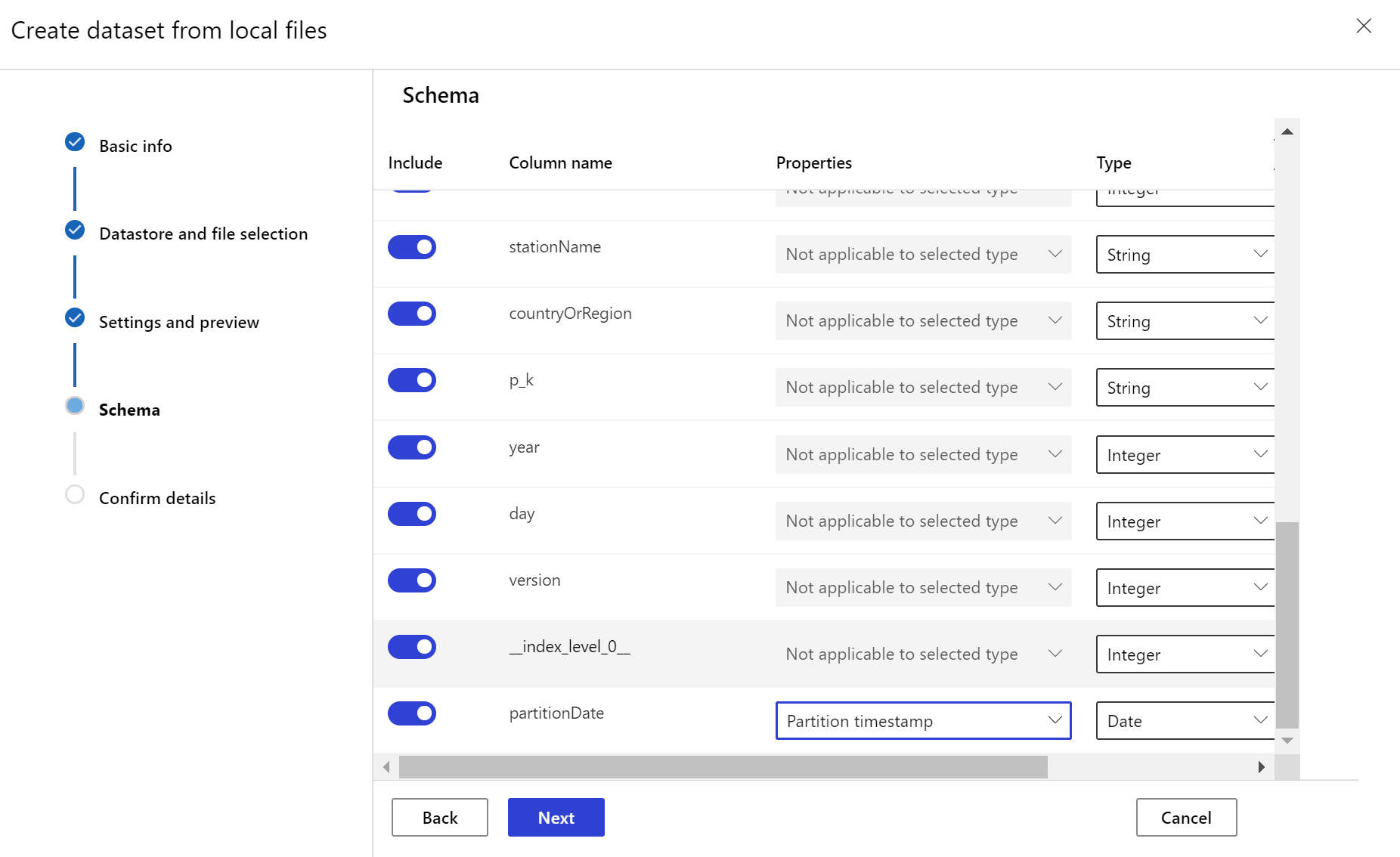
대상 데이터 세트 만들기
대상 데이터 세트에는 데이터의 열 또는 파일의 경로 패턴에서 파생된 가상 열에서 타임스탬프 열을 지정하여 timeseries 특성 집합이 필요합니다. 타임스탬프가 있는 데이터 세트는 Python SDK 또는 Azure Machine Learning 스튜디오를 통해 만듭니다. 데이터 세트에 timeseries 특성을 추가하려면 타임스탬프를 나타내는 열이 지정되어 있어야 합니다. 데이터가 '{yyyy/MM/dd}'와 같은 시간 정보를 사용하여 폴더 구조로 분할된 경우, 경로 패턴 설정을 통해 가상 열을 만든 다음 '파티션 타임스탬프'로 설정하여 시계열 API 기능을 사용하도록 설정합니다.
적용 대상: Python SDK azureml v1
Dataset 클래스 with_timestamp_columns() 메서드는 데이터 세트의 타임스탬프 열을 정의합니다.
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
팁
데이터 세트의 timeseries 특성을 사용하는 전체 예제는 예제 노트북 또는 데이터 세트 SDK 설명서를 참조하세요.

데이터 세트 모니터 만들기
새 데이터 세트에서 데이터 드리프트를 검색하고 경고하는 데이터 세트 모니터를 만듭니다. Python SDK 또는 Azure Machine Learning 스튜디오중 하나를 사용합니다.
나중에 설명하는 것처럼 데이터 세트 모니터는 설정된 빈도(일별, 주간, 월간) 간격으로 실행됩니다. 마지막 실행 이후 대상 데이터 세트에서 사용 가능한 새 데이터를 분석합니다. 어떤 경우에는 최신 데이터에 대한 분석만으로는 충분하지 않을 수 있습니다.
- 데이터 파이프라인이 손상되어 업스트림 원본의 새 데이터가 지연되었으며 데이터 세트 모니터가 실행될 때 이 새 데이터를 사용할 수 없었습니다.
- 시계열 데이터 세트에는 과거 데이터만 있었고 시간 경과에 따른 데이터 세트의 드리프트 패턴을 분석하려고 합니다. 예를 들어, 겨울과 여름 시즌에 웹 사이트로 유입되는 트래픽을 비교하여 계절적 패턴을 식별합니다.
- 데이터 세트 모니터를 처음 사용합니다. 향후 모니터링을 위해 기능을 설정하기 전에 기능이 기존 데이터와 어떻게 작동하는지 평가하려고 합니다. 이러한 시나리오에서는 특정 대상 데이터 세트 집합 날짜 범위를 사용하여 주문형 실행을 제출하여 기준 데이터 세트와 비교할 수 있습니다.
backfill 함수는 지정된 시작 및 종료 날짜 범위 동안 백필 작업을 실행합니다. 백필 작업은 데이터 정확도와 완전성을 보장하기 위한 방법으로 데이터 세트에서 예상되는 누락 데이터 포인트를 채웁니다.
참고 항목
Azure Machine Learning 모델 모니터링은 수동 백필 기능을 지원하지 않습니다. 특정 시간 범위에 대해 모델 모니터를 다시 실행하려는 경우 해당 특정 시간 범위에 대한 다른 모델 모니터를 만들 수 있습니다.
적용 대상: Python SDK azureml v1
전체 세부 정보는 데이터 드리프트에 대한 Python SDK 참조 문서를 확인하세요.
다음 예제에서는 Python SDK를 사용하여 데이터 세트 모니터를 만드는 방법을 보여 줍니다.
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
팁
timeseries 데이터 세트 및 데이터 드리프트 감지기를 설정하는 전체 예제는 예제 노트북을 참조하세요.
모델 모니터 만들기(모델 모니터로 마이그레이션)
모델 모니터로 마이그레이션할 때 Azure Machine Learning 온라인 엔드포인트에서 프로덕션에 모델을 배포하고 배포 시 데이터 수집을 사용하도록 설정한 경우 Azure Machine Learning은 프로덕션 추론 데이터를 수집하고 Microsoft Azure Blob Storage에 자동으로 저장합니다. 그런 다음, Azure Machine Learning 모델 모니터링을 사용하여 이 프로덕션 추론 데이터를 지속적으로 모니터링하고 모델을 직접 선택하여 대상 데이터 세트(모델 모니터의 프로덕션 추론 데이터)를 만들 수 있습니다.
모델 모니터로 마이그레이션할 때 Azure Machine Learning 온라인 엔드포인트에서 프로덕션에 모델을 배포하지 않았거나 데이터 수집을 사용하지 않으려는 경우 사용자 지정 신호 및 메트릭을 사용하여 모델 모니터링을 설정할 수도 있습니다.
다음 섹션에는 모델 모니터로 마이그레이션하는 방법에 대한 자세한 내용이 포함되어 있습니다.
자동으로 수집된 프로덕션 데이터를 통해 모델 모니터 만들기(모델 모니터로 마이그레이션)
Azure Machine Learning 온라인 엔드포인트에서 프로덕션에 모델을 배포하고 배포 시 데이터 수집을 사용하도록 설정한 경우입니다.
다음 코드를 사용하여 기본 모델 모니터링을 설정할 수 있습니다.
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
AlertNotification,
MonitoringTarget,
MonitorDefinition,
MonitorSchedule,
RecurrencePattern,
RecurrenceTrigger,
ServerlessSparkCompute
)
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(),
subscription_id="subscription_id",
resource_group_name="resource_group_name",
workspace_name="workspace_name",
)
# create the compute
spark_compute = ServerlessSparkCompute(
instance_type="standard_e4s_v3",
runtime_version="3.3"
)
# specify your online endpoint deployment
monitoring_target = MonitoringTarget(
ml_task="classification",
endpoint_deployment_id="azureml:credit-default:main"
)
# create alert notification object
alert_notification = AlertNotification(
emails=['abc@example.com', 'def@example.com']
)
# create the monitor definition
monitor_definition = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
alert_notification=alert_notification
)
# specify the schedule frequency
recurrence_trigger = RecurrenceTrigger(
frequency="day",
interval=1,
schedule=RecurrencePattern(hours=3, minutes=15)
)
# create the monitor
model_monitor = MonitorSchedule(
name="credit_default_monitor_basic",
trigger=recurrence_trigger,
create_monitor=monitor_definition
)
poller = ml_client.schedules.begin_create_or_update(model_monitor)
created_monitor = poller.result()


사용자 지정 데이터 전처리 구성 요소를 통해 모델 모니터 만들기(모델 모니터로 마이그레이션)
모델 모니터로 마이그레이션할 때 Azure Machine Learning 온라인 엔드포인트에서 프로덕션에 모델을 배포하지 않았거나 데이터 수집을 사용하지 않으려는 경우 사용자 지정 신호 및 메트릭을 사용하여 모델 모니터링을 설정할 수도 있습니다.
배포가 없지만 프로덕션 데이터가 있는 경우 데이터를 사용하여 지속적인 모델 모니터링을 수행할 수 있습니다. 이러한 모델을 모니터링하려면 다음을 수행할 수 있어야 합니다.
- 프로덕션에 배포된 모델에서 프로덕션 유추 데이터를 수집합니다.
- 프로덕션 유추 데이터를 Azure Machine Learning 데이터 자산으로 등록하고 데이터의 지속적인 업데이트를 보장합니다.
- 사용자 지정 데이터 전처리 구성 요소를 제공하고 Azure Machine Learning 구성 요소로 등록합니다.
데이터 수집기로 데이터를 수집하지 않는 경우 사용자 지정 데이터 전처리 구성 요소를 제공해야 합니다. 이 사용자 지정 데이터 전처리 구성 요소가 없으면 Azure Machine Learning 모델 모니터링 시스템에서 시간 창을 지원하는 테이블 형식으로 데이터를 처리하는 방법을 알 수 없습니다.
사용자 지정 전처리 구성 요소에는 다음과 같은 입력 및 출력 서명이 있어야 합니다.
| 입/출력 | 서명 이름 | Type | 설명 | 예제 값 |
|---|---|---|---|---|
| input | data_window_start |
리터럴, 문자열 | ISO8601 형식의 데이터 창 시작 시간 | 2023-05-01T04:31:57.012Z |
| input | data_window_end |
리터럴, 문자열 | ISO8601 형식의 데이터 창 종료 시간 | 2023-05-01T04:31:57.012Z |
| input | input_data |
uri_folder | Azure Machine Learning 데이터 자산으로 등록된 수집된 프로덕션 유추 데이터 | azureml:myproduction_inference_data:1 |
| output | preprocessed_data |
mltable | 참조 데이터 스키마의 하위 집합과 일치하는 테이블 형식 데이터 세트 |
사용자 지정 데이터 전처리 구성 요소의 예제는 azuremml-examples GitHub 리포지토리의 custom_preprocessing을 참조하세요.
데이터 드리프트 결과 이해
이 섹션에서는 Azure Studio의 데이터 세트 / 데이터 세트 모니터 페이지에 있는 데이터 세트 모니터링 결과를 보여줍니다. 이 페이지에서 설정을 업데이트하고 특정 기간의 기존 데이터를 분석할 수 있습니다.
데이터 드리프트의 규모에 대한 최상위 인사이트 및 추가로 조사할 특징에 대한 하이라이트부터 살펴봅니다.
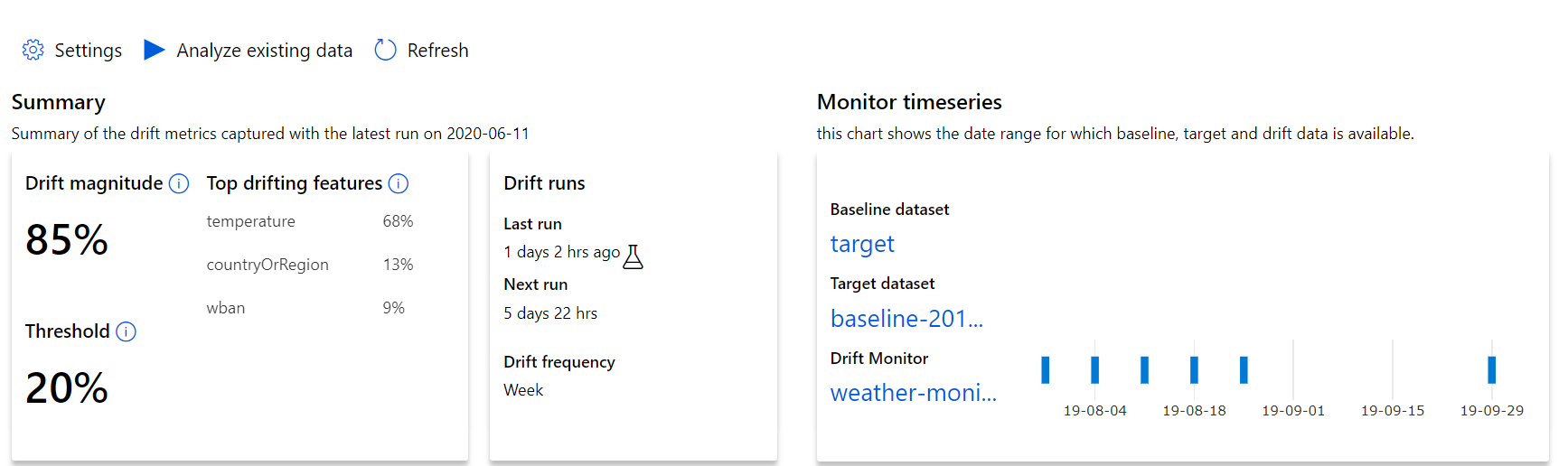
| 메트릭 | 설명 |
|---|---|
| 데이터 드리프트 규모 | 시간 경과에 따른 기준 데이터 세트와 대상 데이터 세트 간의 드리프트 비율입니다. 이 백분율 범위는 0에서 100까지이며, 0은 동일한 데이터 세트를 나타내고 100은 Azure Machine Learning 데이터 드리프트 모델이 두 데이터 세트를 완전히 구분할 수 있음을 나타냅니다. 이 규모를 생성하는 데 기계 학습 기술이 사용되기 때문에 측정된 정확한 백분율에 노이즈가 예상됩니다. |
| 상위 드리프팅 특징 | 가장 많이 드리프트되어 드리프트 규모 메트릭에 가장 많이 기여한 데이터 세트의 특징을 보여줍니다. 공변량 변화로 인해 기능 중요도가 상대적으로 높아지도록 특징의 기본 분포를 반드시 변경해야 하는 것은 아닙니다. |
| Threshold | 설정된 임계값을 초과하는 데이터 드리프트 규모는 경고를 트리거합니다. 모니터 설정에서 임계값을 구성합니다. |
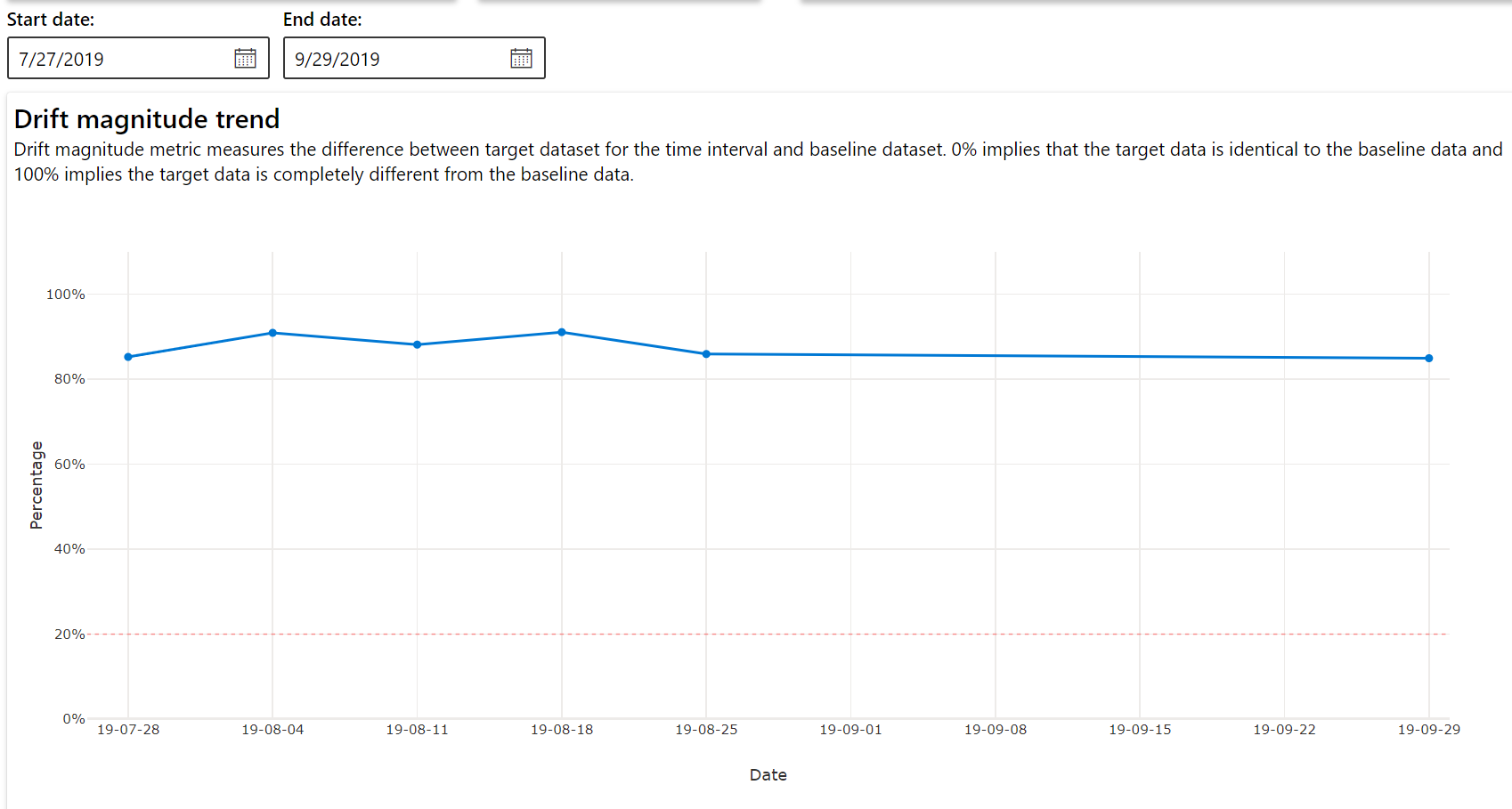
드리프트 규모 추세
지정된 기간 동안 데이터 세트가 대상 데이터 세트와 얼마나 다른지 확인할 수 있습니다. 100%에 가까울수록 두 데이터 세트는 서로 더 많이 다릅니다.
특징별 드리프트 규모
이 섹션에는 시간 경과에 따른 선택한 기능의 배포 및 기타 인사이트 변화에 대한 기능 수준 인사이트가 포함되어 있습니다.
대상 데이터 세트도 시간별로 프로파일링됩니다. 각 특징의 기준 분포 사이 통계적 거리는 시간별로 대상 데이터 세트와 비교됩니다. 개념적으로 이는 데이터 드리프트 크기와 유사합니다. 단, 이러한 통계적 거리는 모든 특징보다는 개별 특징에 대한 것입니다. 최소, 최대 및 평균도 사용할 수 있습니다.
Azure Machine Learning 스튜디오에서 그래프의 막대를 선택하면 해당 날짜의 기능 수준 세부 정보를 볼 수 있습니다. 기본적으로 기준 데이터 세트의 분포 및 동일한 특징의 가장 최근 작업 분포가 표시됩니다.
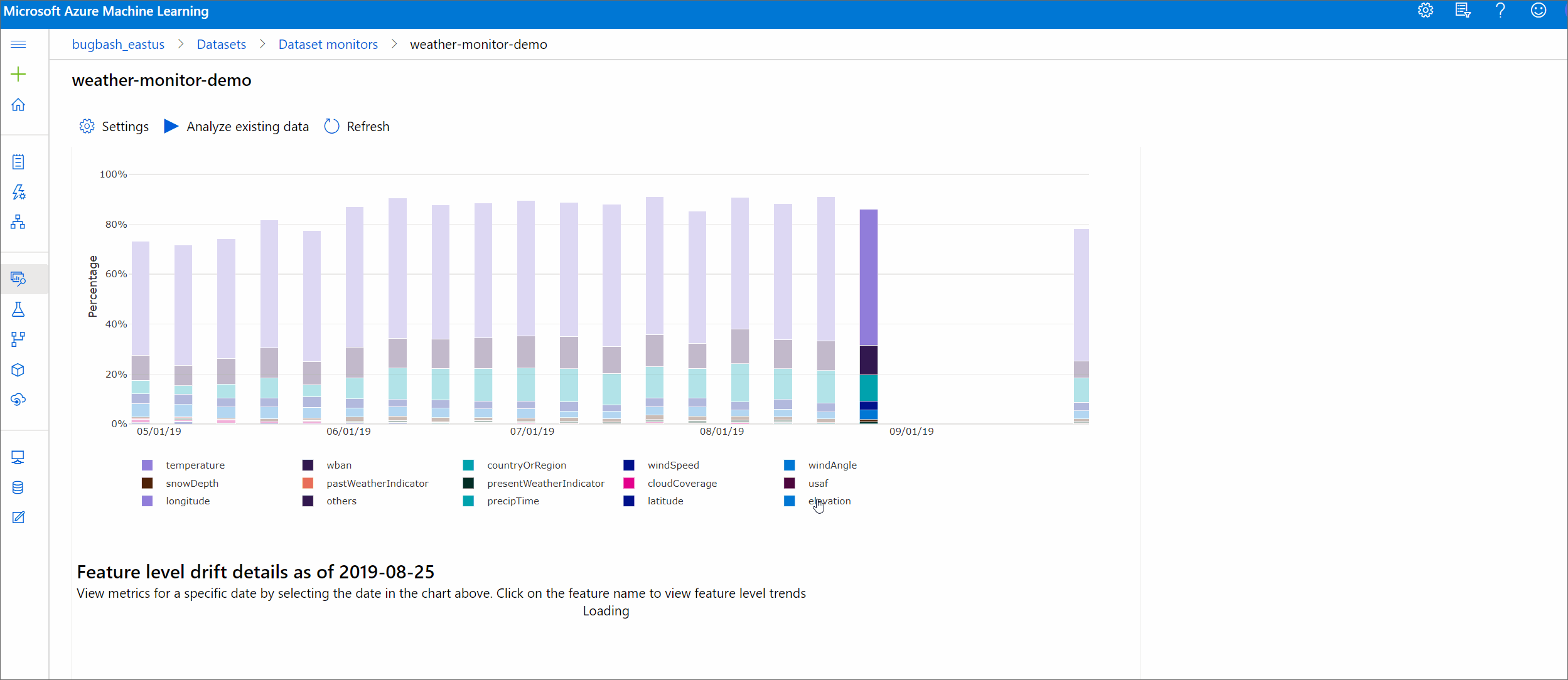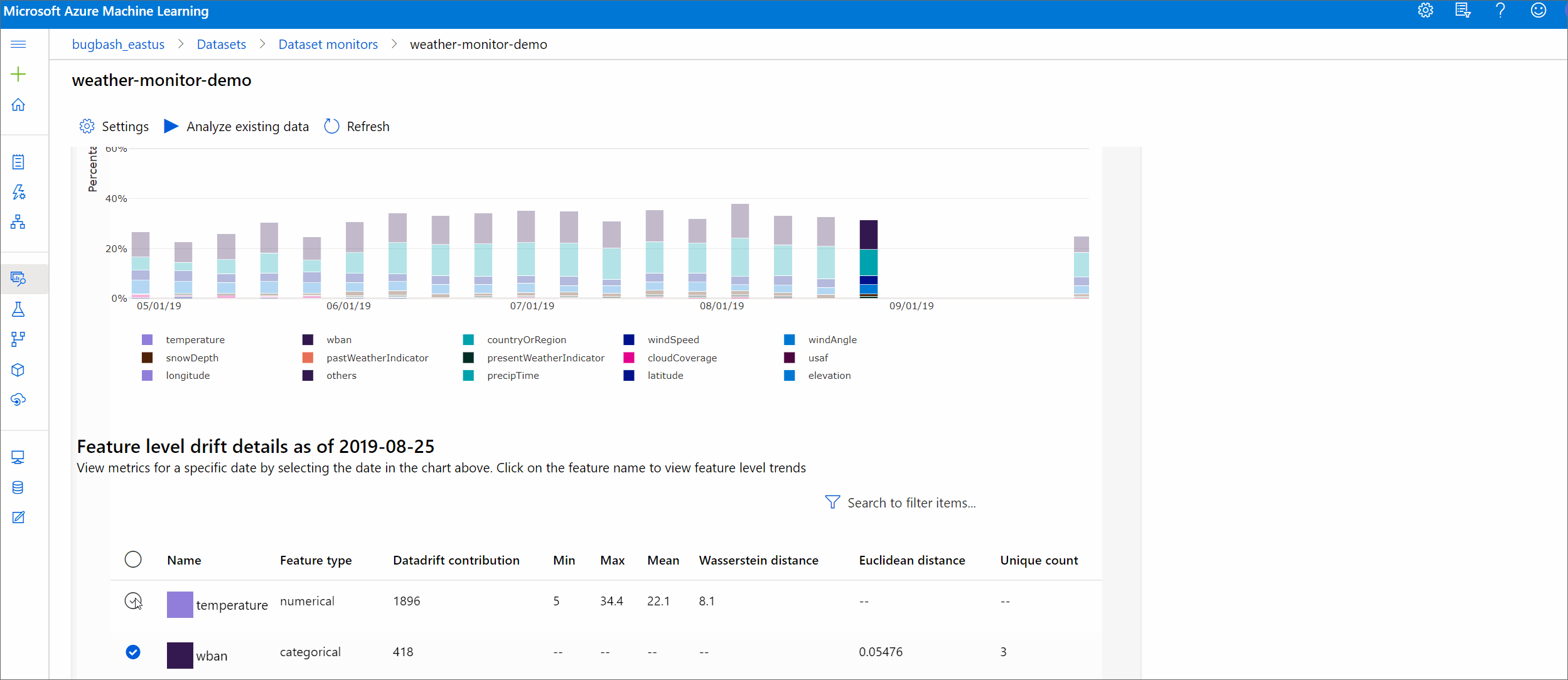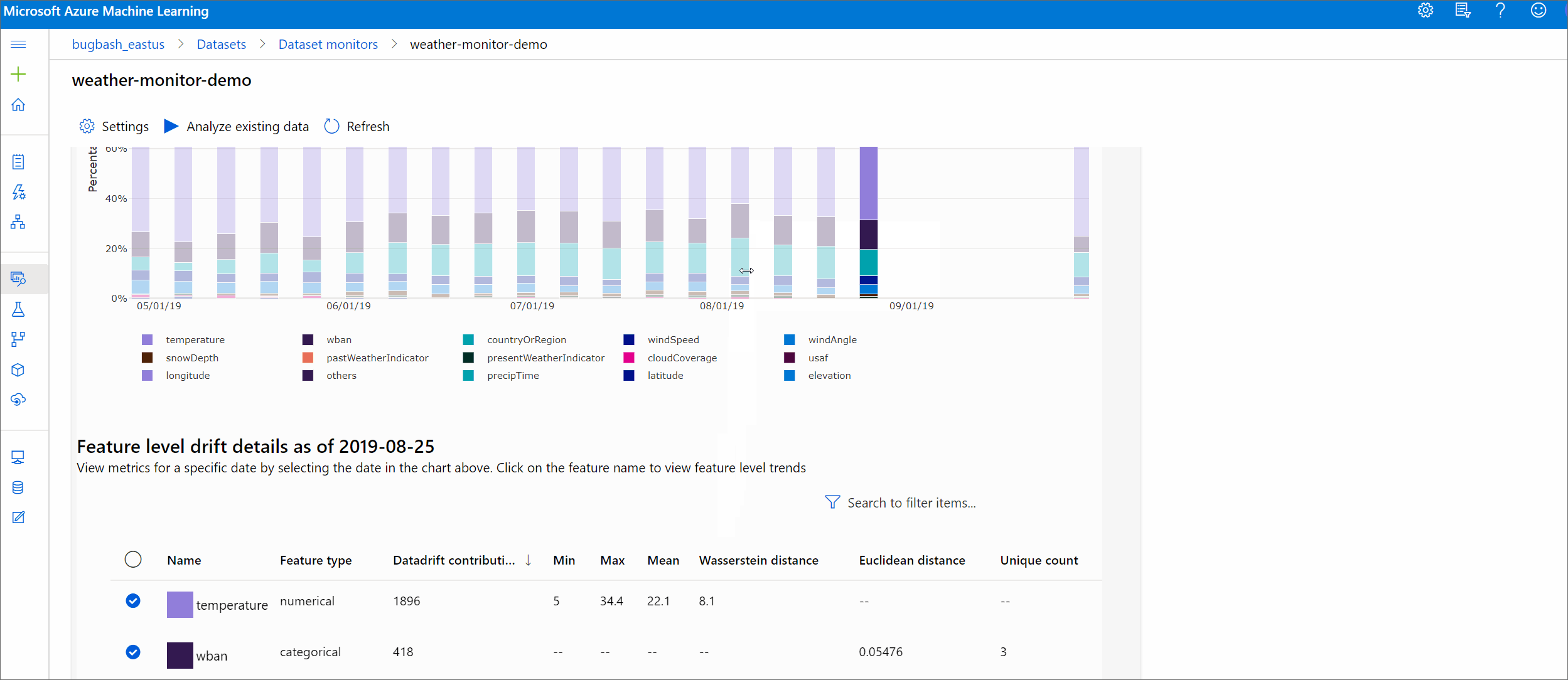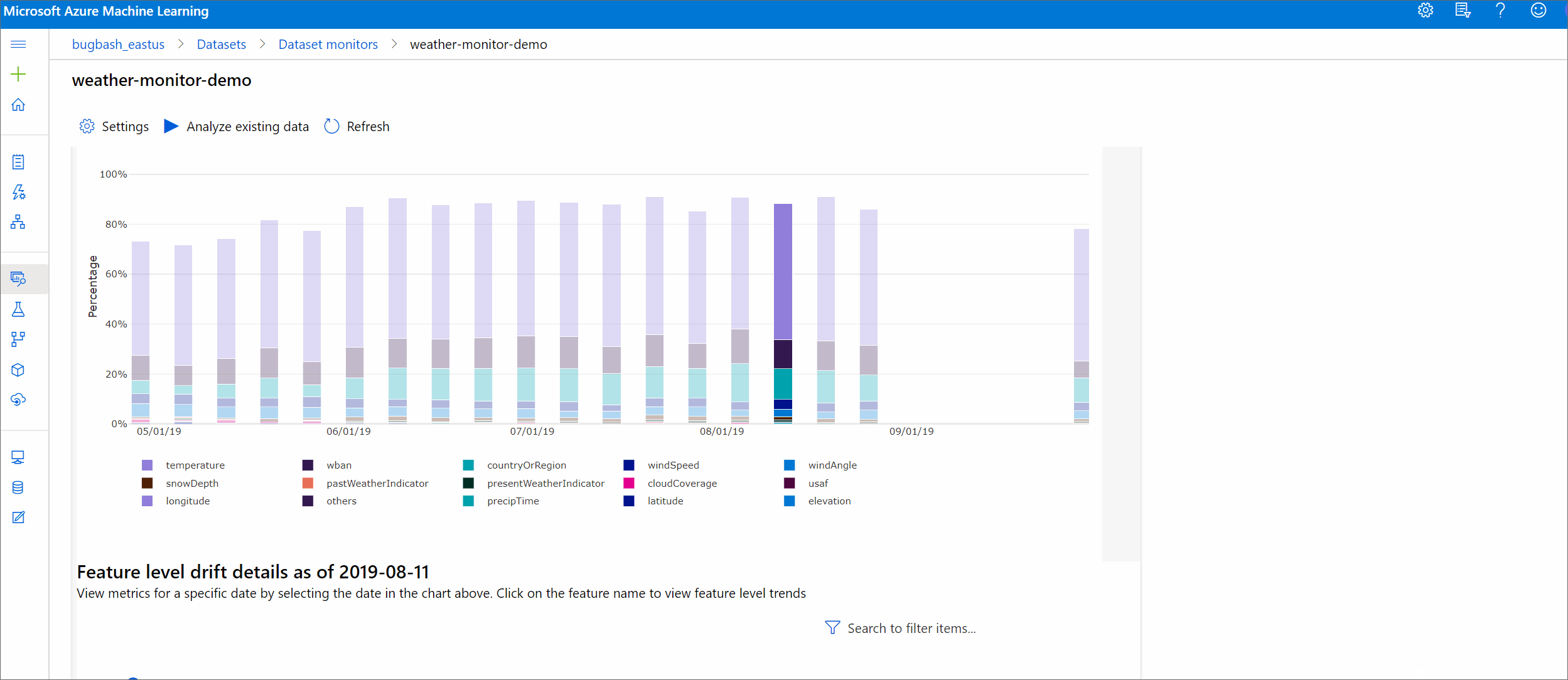
이러한 메트릭은 DataDriftDetector 개체의 get_metrics() 메서드를 통해 Python SDK에서 검색할 수도 있습니다.
기능 세부 정보
마지막으로 아래로 스크롤하여 각 개별 특징에 대한 세부 정보를 봅니다. 차트 위의 드롭다운을 사용하면 특징을 선택할 수 있고 보려는 메트릭도 선택할 수 있습니다.
차트의 메트릭은 특징 유형에 따라 달라집니다.
숫자형 특징
메트릭 설명 워서스테인 거리 기준 분포를 대상 분포로 변환하기 위한 최소 작업량입니다. 평균값 특징의 평균값입니다. 최솟값 특징의 최솟값입니다. 최댓값 특징의 최댓값입니다. 범주형 특징
메트릭 설명 유클리디안 거리 범주형 열에 대해 계산됩니다. 유클리디안 거리는 두 데이터 세트에서 동일한 범주형 열의 경험적 분포에서 생성된 두 벡터에 대해 계산됩니다. 0은 경험적 배포에 차이가 없음을 나타냅니다. 0에서 멀어질수록 이 열은 더 많이 드리프트됩니다. 추세는 이 메트릭의 시계열 도표에서 관찰할 수 있으며 드리프트 특징을 발견하는 데 도움이 될 수 있습니다. 고유 값 특징에서 고유한 값(카디널리티)의 수입니다.
이 차트에서 단일 날짜를 선택하면 표시된 특징에 대해 대상 날짜와 선택한 날짜 사이의 특징 분포를 비교할 수 있습니다. 숫자형 특징의 경우 두 가지 확률 분포를 보여줍니다. 특징이 숫자인 경우 막대형 차트가 표시됩니다.
메트릭, 경고 및 이벤트
메트릭은 기계 학습 작업 영역과 연결된 Azure Application Insights 리소스에서 쿼리할 수 있습니다. 이메일/SMS/푸시/음성 또는 Azure Function과 같은 작업을 트리거하는 작업 그룹 및 사용자 지정 경고 규칙에 대한 설정을 포함하여 Application Insights의 모든 기능에 액세스할 수 있습니다. 자세한 내용은 전체 Application Insights 설명서를 참조하세요.
시작하려면 Azure Portal로 이동하여 작업 영역의 개요 페이지를 선택합니다. 연결된 Application Insights 리소스는 오른쪽 끝에 있습니다.

왼쪽 창의 모니터링 아래에서 로그(분석)를 선택합니다.
데이터 세트 모니터 메트릭은 customMetrics로 저장됩니다. 데이터 세트 모니터를 설정한 후 쿼리를 작성하고 실행하여 볼 수 있습니다.

경고 규칙을 설정하기 위한 메트릭을 식별한 후 새 경고 규칙을 만듭니다.
기존 작업 그룹을 사용하거나 새 작업 그룹을 만들어서 설정한 조건이 충족될 때 수행할 작업을 정의할 수 있습니다.
문제 해결
데이터 드리프트 모니터의 제한 사항 및 알려진 문제:
기록 데이터를 분석할 때 시간 범위는 모니터의 빈도 설정 간격 31개로 제한됩니다.
특징 목록이 지정되지 않은 경우(모든 특징이 사용됨) 특징은 200개로 제한됩니다.
컴퓨팅 크기는 데이터를 처리할 수 있을 만큼 커야 합니다.
데이터 세트에는 지정된 모니터 작업의 시작 및 종료 날짜 내의 데이터가 있어야 합니다.
데이터 세트 모니터는 50개 이상의 행을 포함하는 데이터 세트에서만 작동합니다.
데이터 세트의 열 또는 특징은 다음 표의 조건에 따라 범주형 또는 숫자형으로 분류됩니다. 특징이 이러한 조건을 충족하지 않는 경우(예: 고유한 값이 >100개를 초과하는 문자열 유형의 열) 데이터 드리프트 알고리즘에서 특징이 삭제되지만 여전히 프로파일링됩니다.
기능 유형 데이터 형식 조건 제한 사항 범주 string 특징의 고유 값 개수가 100개 미만이고 행 수의 5% 미만입니다. Null은 자체 범주로 처리됩니다. 숫자 정수, 부동 소수점 특징의 값은 숫자형 데이터 형식이며 범주형 특징의 조건을 충족하지 않습니다. null이 값의 15%를 초과하면 특징이 삭제됩니다. 데이터 드리프트 모니터를 만들었지만 Azure Machine Learning 스튜디오의 데이터 세트 모니터 페이지에서 데이터를 볼 수 없는 경우 다음을 시도해보세요.
- 페이지 맨 위에서 올바른 날짜 범위를 선택했는지 확인합니다.
- 데이터 세트 모니터 탭에서 실험 링크를 선택하여 작업 상태를 확인합니다. 이 링크는 테이블의 오른쪽 끝에 있습니다.
- 작업이 성공적으로 완료되면 드라이버 로그를 확인하여 생성된 메트릭 수를 확인하거나 경고 메시지가 있는지 확인합니다. 실험을 선택한 후 출력 + 로그 탭에서 드라이버 로그를 찾습니다.
SDK
backfill()함수가 예상되는 출력을 생성하지 않는 경우 인증 문제가 원인일 수 있습니다. 이 함수에 전달할 컴퓨팅을 만들 때Run.get_context().experiment.workspace.compute_targets를 사용하지 마세요. 대신 ServicePrincipalAuthentication을 아래와 같이 사용하여backfill()함수에 전달할 컴퓨팅을 만듭니다.
참고 항목
서비스 주체 암호를 코드에 하드 코딩하지 마세요. 대신 Python 환경, 키 저장소 또는 비밀에 액세스하는 다른 안전한 방법을 통해 이를 검색합니다.
auth = ServicePrincipalAuthentication(
tenant_id=tenant_id,
service_principal_id=app_id,
service_principal_password=client_secret
)
ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx")
compute = ws.compute_targets.get("xxx")
모델 데이터 수집기에서 데이터가 Blob Storage 계정에 도착하는 데 최대 10분이 걸릴 수 있습니다. 그러나 일반적으로 시간이 덜 걸립니다. 스크립트 또는 Notebook에서 아래 셀이 성공적으로 실행될 때까지 10분 동안 기다립니다.
import time time.sleep(600)
다음 단계
- Azure Machine Learning 스튜디오 또는 Python Notebook으로 이동하여 데이터 세트 모니터를 설정합니다.
- Azure Kubernetes Service에 배포된 모델에서 데이터 드리프트를 설정하는 방법을 참조하세요.
- Azure Event Grid로 데이터 세트 드리프트 모니터를 설정합니다.