이 문서에서는 Azure Red Hat OpenShift에서 NVIDIA GPU 워크로드를 사용하는 방법을 보여 줍니다.
필수 조건
- OpenShift CLI
- jq, moreutils 및 gettext 패키지
- Azure Red Hat OpenShift 4.10
클러스터를 설치해야 하는 경우 자습서: Azure Red Hat OpenShift 4 클러스터 만들기를 참조하세요. 클러스터는 버전 4.10.x 이상이어야 합니다.
비고
4.10을 기준으로 NVIDIA 연산자를 사용할 자격을 더 이상 설정할 필요가 없습니다. 이는 GPU 워크로드를 위한 클러스터 설정을 크게 단순화했습니다.
Linux:
sudo dnf install jq moreutils gettext
macOS
brew install jq moreutils gettext
GPU 할당량 요청
Azure의 모든 GPU 할당량은 기본적으로 0입니다. Azure Portal에 로그인하고 GPU 할당량을 요청해야 합니다. GPU 작업자의 경쟁으로 인해 실제로 GPU를 예약할 수 있는 지역에서 클러스터를 프로비전해야 할 수 있습니다.
는 다음 GPU 작업자를 지원합니다.
- NC4as T4 v3
- NC6s v3
- NC8as T4 v3
- NC12s v3
- NC16as T4 v3
- NC24s v3
- NC24rs v3
- NC64as T4 v3
다음 인스턴스는 추가 MachineSets에서도 지원됩니다.
- Standard_ND96asr_v4
- NC24ads_A100_v4
- NC48ads_A100_v4
- NC96ads_A100_v4
- ND96amsr_A100_v4
비고
Azure에서는 코어당 할당량을 요청해야 합니다. 단일 NC4as T4 v3 노드를 요청하려면 4개의 그룹으로 할당량을 요청해야 합니다. NC16as T4 v3를 요청하려면 할당량 16을 요청해야 합니다.
Azure 포털에로그인합니다.
검색 상자에 할당량을 입력한 다음 컴퓨팅을 선택합니다.
검색 상자에 NCAsv3_T4를 입력하고 클러스터가 있는 지역의 상자를 선택한 다음, 할당량 증가 요청을 선택합니다.
할당량을 구성합니다.

클러스터에 로그인
클러스터 관리자 권한이 있는 사용자 계정으로 OpenShift에 로그인합니다. 아래 예에서는 kubadmin이라는 계정을 사용합니다.
oc login <apiserver> -u kubeadmin -p <kubeadminpass>
풀 비밀(조건부)
오퍼레이터를 설치하고 cloud.redhat.com에 연결할 수 있도록 풀 비밀을 업데이트합니다.
비고
cloud.redhat.com이 사용하도록 설정된 전체 풀 비밀을 이미 다시 만들었다면 이 단계를 건너뛰세요.
cloud.redhat.com에 로그인합니다.
https://cloud.redhat.com/openshift/install/azure/aro-provisioned로 이동합니다.
풀 비밀 다운로드를 선택하고 풀 비밀을
pull-secret.txt로 저장합니다.중요합니다
이 섹션의 나머지 단계는
pull-secret.txt와 동일한 작업 디렉터리에서 실행해야 합니다.기존 풀 비밀을 내보냅니다.
oc get secret pull-secret -n openshift-config -o json | jq -r '.data.".dockerconfigjson"' | base64 --decode > export-pull.json다운로드한 풀 비밀을 시스템 풀 비밀과 병합하여
cloud.redhat.com을 추가합니다.jq -s '.[0] * .[1]' export-pull.json pull-secret.txt | tr -d "\n\r" > new-pull-secret.json새 비밀 파일을 업로드합니다.
oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=new-pull-secret.json모든 항목이 cloud.redhat.com과 동기화되려면 약 1시간 정도 기다려야 할 수 있습니다.
암호를 삭제합니다.
rm pull-secret.txt export-pull.json new-pull-secret.json
GPU 컴퓨터 집합
Kubernetes MachineSet을 사용하여 머신 세트를 만듭니다. 아래 프로시저는 클러스터의 첫 번째 컴퓨터 집합을 내보내고 이를 템플릿으로 사용하여 단일 GPU 컴퓨터를 빌드하는 방법을 설명합니다.
기존 컴퓨터 집합을 봅니다.
설정을 쉽게 하기 위해 이 예에서는 첫 번째 컴퓨터 집합을 복제할 컴퓨터 집합으로 사용하여 새 GPU 컴퓨터 집합을 만듭니다.
MACHINESET=$(oc get machineset -n openshift-machine-api -o=jsonpath='{.items[0]}' | jq -r '[.metadata.name] | @tsv')예 컴퓨터 집합의 복사본을 저장합니다.
oc get machineset -n openshift-machine-api $MACHINESET -o json > gpu_machineset.json.metadata.name필드를 새로운 고유 이름으로 변경합니다.jq '.metadata.name = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonspec.replicas가 컴퓨터 집합에 대해 원하는 복제본 수와 일치하는지 확인합니다.jq '.spec.replicas = 1' gpu_machineset.json| sponge gpu_machineset.json.spec.selector.matchLabels.machine.openshift.io/cluster-api-machineset필드와 일치하도록.metadata.name필드를 변경합니다.jq '.spec.selector.matchLabels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.json.spec.template.metadata.labels.machine.openshift.io/cluster-api-machineset필드와 일치하도록.metadata.name를 변경합니다.jq '.spec.template.metadata.labels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonAzure에서 원하는 GPU 인스턴스 형식과 일치하도록
spec.template.spec.providerSpec.value.vmSize를 변경합니다.이 예에서 사용된 컴퓨터는 Standard_NC4as_T4_v3입니다.
jq '.spec.template.spec.providerSpec.value.vmSize = "Standard_NC4as_T4_v3"' gpu_machineset.json | sponge gpu_machineset.jsonAzure에서 원하는 영역과 일치하도록
spec.template.spec.providerSpec.value.zone을 변경합니다.jq '.spec.template.spec.providerSpec.value.zone = "1"' gpu_machineset.json | sponge gpu_machineset.jsonyaml 파일의
.status섹션을 삭제합니다.jq 'del(.status)' gpu_machineset.json | sponge gpu_machineset.jsonyaml 파일에서 다른 데이터를 확인합니다.
올바른 SKU가 설정되었는지 확인합니다.
컴퓨터 집합에 사용되는 이미지에 따라 두 값 image.skuimage.version 이 모두 적절하게 설정되어야 합니다. Hyper-V용 1세대 또는 2세대 가상 머신이 사용되는지 확인하기 위한 것입니다. 자세한 내용은 여기를 참조하세요.
예제:
사용하는 Standard_NC4as_T4_v3경우 두 버전이 모두 지원됩니다. 기능 지원에서 설명한 대로. 이 경우 변경이 필요하지 않습니다.
사용하는 Standard_NC24ads_A100_v4경우 2세대 VM만 지원됩니다.
이 경우 값은 image.sku 클러스터의 원래 v2이미지에 해당하는 이미지의 해당 image.sku 버전을 따라야 합니다. 이 예제에서는 값이 됩니다 v410-v2.
다음 명령을 사용하여 찾을 수 있습니다.
az vm image list --architecture x64 -o table --all --offer aro4 --publisher azureopenshift
Filtered output:
SKU VERSION
------- ---------------
v410-v2 410.84.20220125
aro_410 410.84.20220125
기본 SKU 이미지를 aro_410사용하여 클러스터를 만들고 컴퓨터 집합에 동일한 값을 유지하면 다음 오류와 함께 실패합니다.
failure sending request for machine myworkernode: cannot create vm: compute.VirtualMachinesClient#CreateOrUpdate: Failure sending request: StatusCode=400 -- Original Error: Code="BadRequest" Message="The selected VM size 'Standard_NC24ads_A100_v4' cannot boot Hypervisor Generation '1'.
GPU 컴퓨터 집합 만들기
다음 단계에서 새 GPU 컴퓨터를 만듭니다. 새 GPU 컴퓨터를 프로비전하는 데 10~15분이 걸릴 수 있습니다. 이 단계가 실패하면 Azure Portal에 로그인하고 가용성 문제가 없는지 확인합니다. 이렇게 하려면 Virtual Machines로 이동하고 이전에 만든 작업자 이름을 검색하여 VM 상태를 확인합니다.
GPU 컴퓨터 집합을 만듭니다.
oc create -f gpu_machineset.json이 명령을 완료하는 데 몇 분 정도 걸릴 수 있습니다.
GPU 컴퓨터 집합을 확인합니다.
컴퓨터를 배치해야 합니다. 다음 명령을 사용하여 컴퓨터 집합의 상태를 볼 수 있습니다.
oc get machineset -n openshift-machine-api oc get machine -n openshift-machine-api컴퓨터가 프로비전되면(5~15분 소요) 컴퓨터가 노드 목록에 노드로 표시됩니다.
oc get nodes이전에 만들어진
nvidia-worker-southcentralus1이름의 노드가 표시되어야 합니다.
NVIDIA GPU 연산자 설치
이 섹션에서는 네임스페이 nvidia-gpu-operator 스를 만들고, 연산자 그룹을 설정하고, NVIDIA GPU 연산자를 설치하는 방법을 설명합니다.
NVIDIA 네임스페이스를 만듭니다.
cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: nvidia-gpu-operator EOF운영자 그룹을 만듭니다.
cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: nvidia-gpu-operator-group namespace: nvidia-gpu-operator spec: targetNamespaces: - nvidia-gpu-operator EOF다음 명령을 사용하여 최신 NVIDIA 채널을 가져옵니다.
CHANNEL=$(oc get packagemanifest gpu-operator-certified -n openshift-marketplace -o jsonpath='{.status.defaultChannel}')
비고
끌어오기 비밀을 제공하지 않고 클러스터를 만든 경우 클러스터에는 Red Hat 또는 인증된 파트너의 샘플 또는 운영자가 포함되지 않습니다. 쿼리를 실행하면 다음과 같은 오류 메시지가 표시됩니다.
서버 오류(NotFound): packagemanifests.packages.operators.coreos.com "gpu-operator-certified"를 찾을 수 없습니다.
Azure Red Hat OpenShift 클러스터에 Red Hat 끌어오기 비밀을 추가하려면 이 지침을 따릅니다.
다음 명령을 사용하여 최신 NVIDIA 패키지를 가져옵니다.
PACKAGE=$(oc get packagemanifests/gpu-operator-certified -n openshift-marketplace -ojson | jq -r '.status.channels[] | select(.name == "'$CHANNEL'") | .currentCSV')구독을 만듭니다.
envsubst <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: gpu-operator-certified namespace: nvidia-gpu-operator spec: channel: "$CHANNEL" installPlanApproval: Automatic name: gpu-operator-certified source: certified-operators sourceNamespace: openshift-marketplace startingCSV: "$PACKAGE" EOFOperator가 설치를 마칠 때까지 기다리세요.
운영자가 설치를 완료했는지 확인할 때까지 진행하지 마세요. 또한 GPU 작업자가 온라인 상태인지 확인합니다.
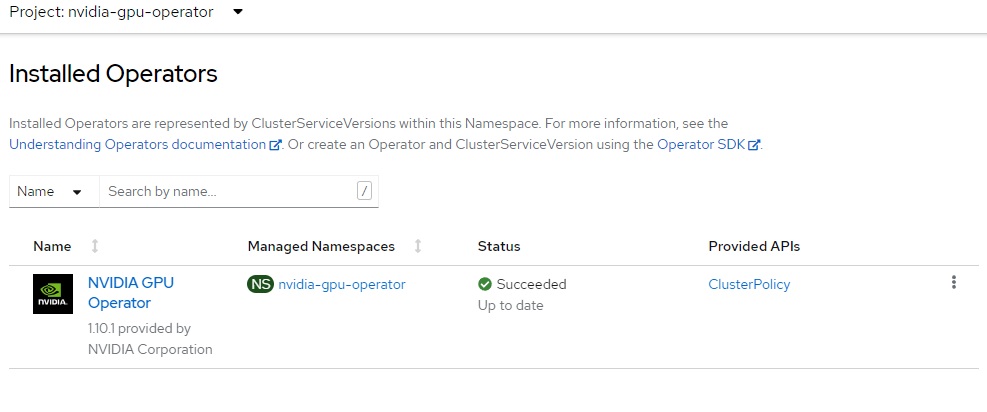
노드 기능 검색 연산자 설치
노드 기능 검색 연산자는 노드에서 GPU를 검색하고 워크로드 대상으로 지정할 수 있도록 노드에 적절하게 레이블을 지정합니다.
이 예는 NFD 연산자를 openshift-ndf 네임스페이스에 설치하고 NFD에 대한 구성인 "구독"을 만듭니다.
Node Feature Discovery Operator 설치를 위한 공식 설명서.
Namespace를 설정합니다.cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: openshift-nfd EOFOperatorGroup를 만듭니다.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: generateName: openshift-nfd- name: openshift-nfd namespace: openshift-nfd EOFSubscription를 만듭니다.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: nfd namespace: openshift-nfd spec: channel: "stable" installPlanApproval: Automatic name: nfd source: redhat-operators sourceNamespace: openshift-marketplace EOF노드 기능 검색이 설치를 완료할 때까지 기다리세요.
OpenShift 콘솔에 로그인하여 운영자를 보거나 몇 분만 기다리세요. 운영자가 설치될 때까지 기다리지 않으면 다음 단계에서 오류가 발생합니다.
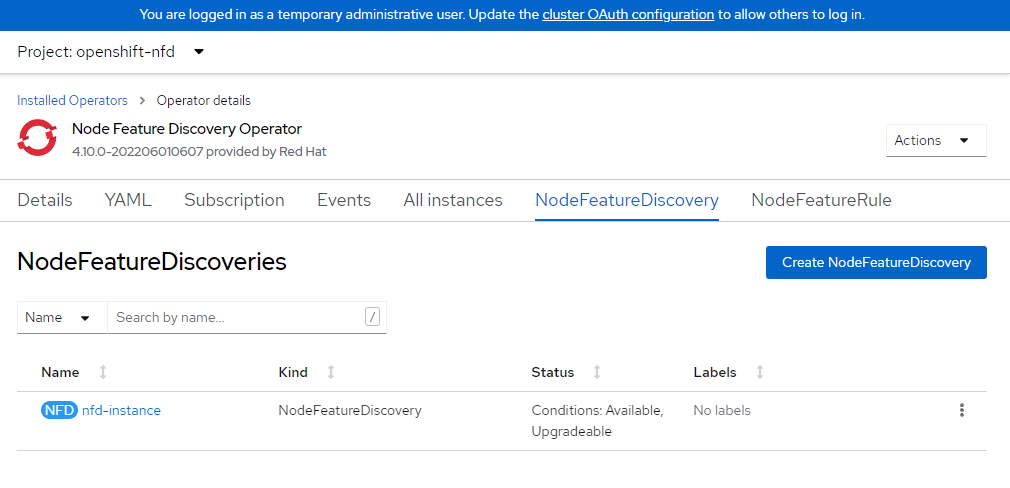
NFD 인스턴스를 만듭니다.
cat <<EOF | oc apply -f - kind: NodeFeatureDiscovery apiVersion: nfd.openshift.io/v1 metadata: name: nfd-instance namespace: openshift-nfd spec: customConfig: configData: | # - name: "more.kernel.features" # matchOn: # - loadedKMod: ["example_kmod3"] # - name: "more.features.by.nodename" # value: customValue # matchOn: # - nodename: ["special-.*-node-.*"] operand: image: >- registry.redhat.io/openshift4/ose-node-feature-discovery@sha256:07658ef3df4b264b02396e67af813a52ba416b47ab6e1d2d08025a350ccd2b7b servicePort: 12000 workerConfig: configData: | core: # labelWhiteList: # noPublish: false sleepInterval: 60s # sources: [all] # klog: # addDirHeader: false # alsologtostderr: false # logBacktraceAt: # logtostderr: true # skipHeaders: false # stderrthreshold: 2 # v: 0 # vmodule: ## NOTE: the following options are not dynamically run-time ## configurable and require a nfd-worker restart to take effect ## after being changed # logDir: # logFile: # logFileMaxSize: 1800 # skipLogHeaders: false sources: # cpu: # cpuid: ## NOTE: attributeWhitelist has priority over attributeBlacklist # attributeBlacklist: # - "BMI1" # - "BMI2" # - "CLMUL" # - "CMOV" # - "CX16" # - "ERMS" # - "F16C" # - "HTT" # - "LZCNT" # - "MMX" # - "MMXEXT" # - "NX" # - "POPCNT" # - "RDRAND" # - "RDSEED" # - "RDTSCP" # - "SGX" # - "SSE" # - "SSE2" # - "SSE3" # - "SSE4.1" # - "SSE4.2" # - "SSSE3" # attributeWhitelist: # kernel: # kconfigFile: "/path/to/kconfig" # configOpts: # - "NO_HZ" # - "X86" # - "DMI" pci: deviceClassWhitelist: - "0200" - "03" - "12" deviceLabelFields: # - "class" - "vendor" # - "device" # - "subsystem_vendor" # - "subsystem_device" # usb: # deviceClassWhitelist: # - "0e" # - "ef" # - "fe" # - "ff" # deviceLabelFields: # - "class" # - "vendor" # - "device" # custom: # - name: "my.kernel.feature" # matchOn: # - loadedKMod: ["example_kmod1", "example_kmod2"] # - name: "my.pci.feature" # matchOn: # - pciId: # class: ["0200"] # vendor: ["15b3"] # device: ["1014", "1017"] # - pciId : # vendor: ["8086"] # device: ["1000", "1100"] # - name: "my.usb.feature" # matchOn: # - usbId: # class: ["ff"] # vendor: ["03e7"] # device: ["2485"] # - usbId: # class: ["fe"] # vendor: ["1a6e"] # device: ["089a"] # - name: "my.combined.feature" # matchOn: # - pciId: # vendor: ["15b3"] # device: ["1014", "1017"] # loadedKMod : ["vendor_kmod1", "vendor_kmod2"] EOFNFD가 준비되었는지 확인합니다.
이 운영자의 상태는 사용 가능으로 표시되어야 합니다.
NVIDIA 클러스터 구성 적용
이 섹션에서는 NVIDIA 클러스터 구성을 적용하는 방법을 설명합니다. 사용자 고유의 개인 리포지토리 또는 특정 설정이 있는 경우 사용자 지정에 대한 NVIDIA 설명서를 참조하세요. 이 프로세스를 완료하는 데 몇 분 정도 걸릴 수 있습니다.
클러스터 구성을 적용합니다.
cat <<EOF | oc apply -f - apiVersion: nvidia.com/v1 kind: ClusterPolicy metadata: name: gpu-cluster-policy spec: migManager: enabled: true operator: defaultRuntime: crio initContainer: {} runtimeClass: nvidia deployGFD: true dcgm: enabled: true gfd: {} dcgmExporter: config: name: '' driver: licensingConfig: nlsEnabled: false configMapName: '' certConfig: name: '' kernelModuleConfig: name: '' repoConfig: configMapName: '' virtualTopology: config: '' enabled: true use_ocp_driver_toolkit: true devicePlugin: {} mig: strategy: single validator: plugin: env: - name: WITH_WORKLOAD value: 'true' nodeStatusExporter: enabled: true daemonsets: {} toolkit: enabled: true EOF클러스터 정책을 확인합니다.
OpenShift 콘솔에 로그인하고 운영자를 찾습니다.
nvidia-gpu-operator네임스페이스에 있는지 확인합니다.State: Ready once everything is complete이라고 표시되어야 합니다.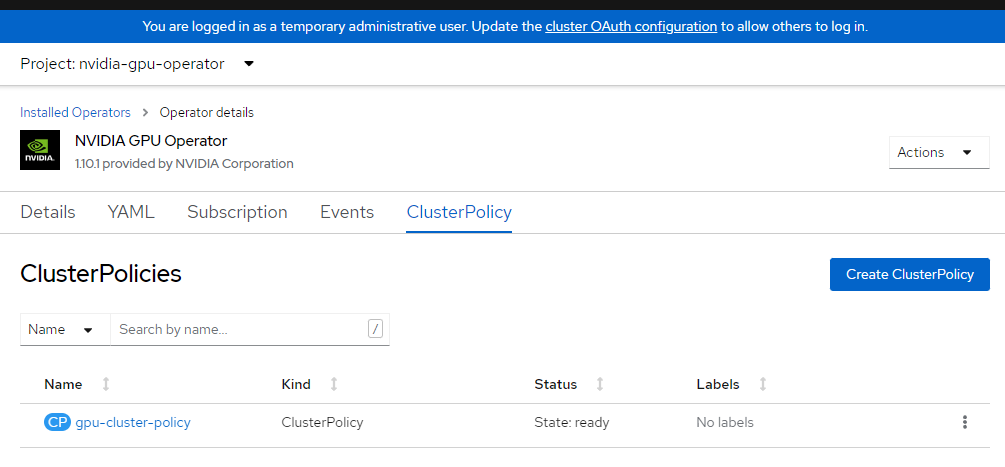
GPU 유효성 검사
NVIDIA 운영자 및 NFD가 컴퓨터를 완전히 설치하고 자체 식별하는 데 다소 시간이 걸릴 수 있습니다. 다음 명령을 실행하여 모든 것이 예상대로 실행되고 있는지 유효성을 검사합니다.
NFD가 GPU를 볼 수 있는지 확인합니다.
oc describe node | egrep 'Roles|pci-10de' | grep -v master출력은 다음과 유사합니다.
Roles: worker feature.node.kubernetes.io/pci-10de.present=true노드 레이블을 확인합니다.
OpenShift 콘솔 로그인 -> 컴퓨팅 -> 노드 -> nvidia-worker-southcentralus1-에서 노드 레이블을 볼 수 있습니다. 위에서 여러 NVIDIA GPU 레이블과 pci-10de 디바이스가 표시됩니다.
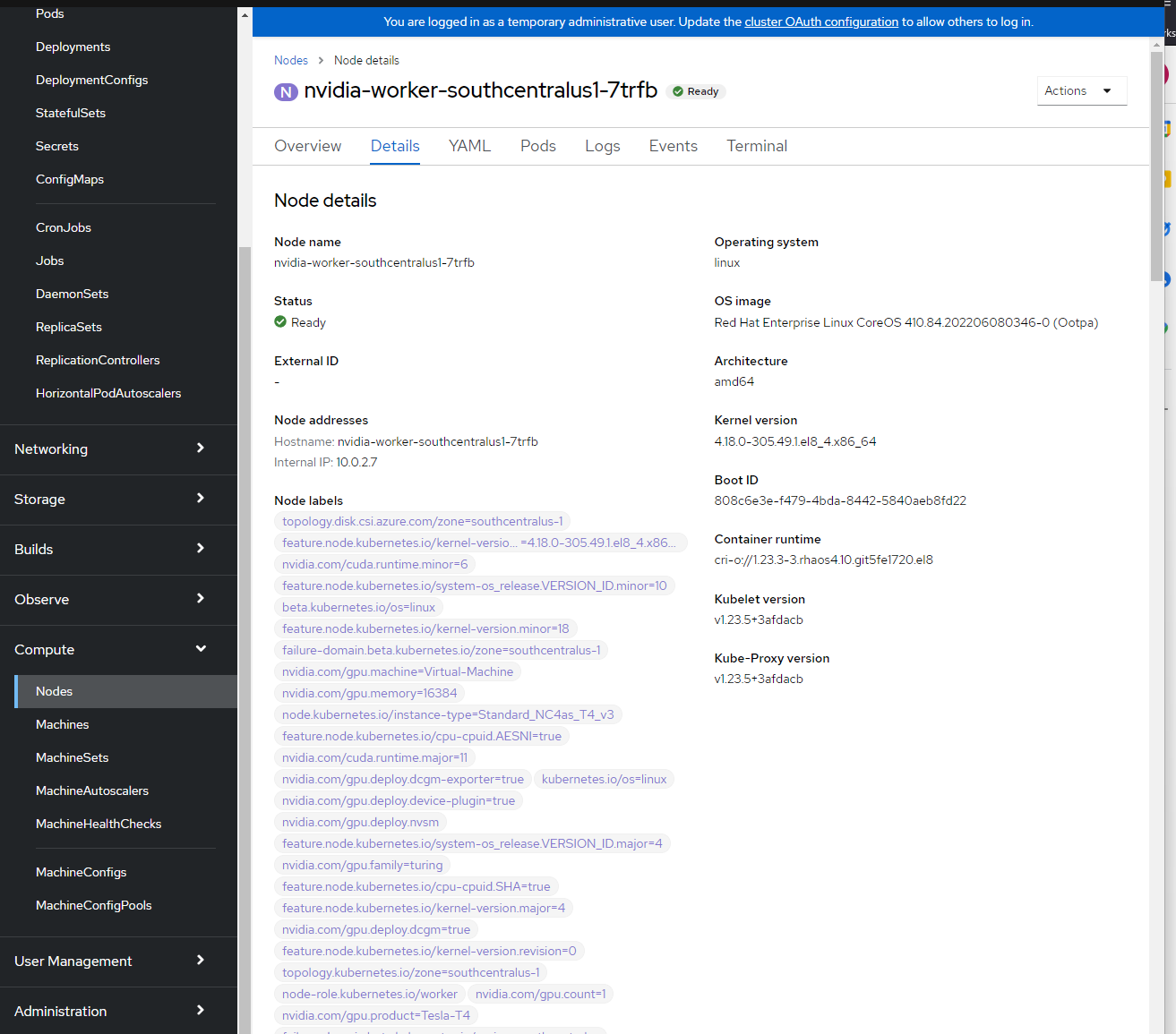
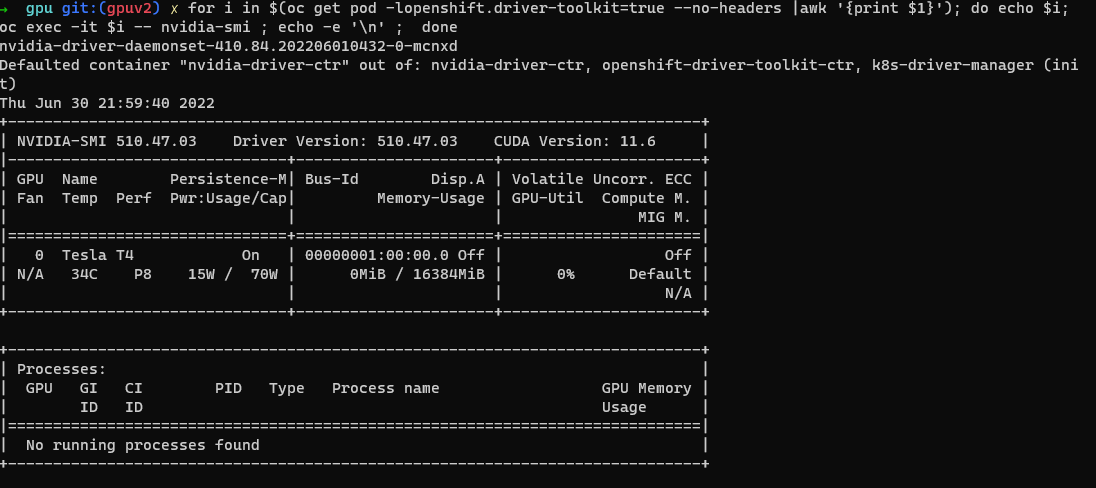
NVIDIA SMI 도구 확인.
oc project nvidia-gpu-operator for i in $(oc get pod -lopenshift.driver-toolkit=true --no-headers |awk '{print $1}'); do echo $i; oc exec -it $i -- nvidia-smi ; echo -e '\n' ; done이 예 스크린샷과 같이 호스트에서 사용 가능한 GPU를 보여 주는 출력이 표시되어야 합니다. (GPU 작업자 형식에 따라 다름)
GPU 워크로드를 실행할 Pod 만들기
oc project nvidia-gpu-operator cat <<EOF | oc apply -f - apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add image: "quay.io/giantswarm/nvidia-gpu-demo:latest" resources: limits: nvidia.com/gpu: 1 nodeSelector: nvidia.com/gpu.present: true EOF로그를 봅니다.
oc logs cuda-vector-add --tail=-1
비고
Error from server (BadRequest): container "cuda-vector-add" in pod "cuda-vector-add" is waiting to start: ContainerCreating 오류가 발생하면 oc delete pod cuda-vector-add를 실행한 다음 위의 create 문을 다시 실행합니다.
출력은 다음과 유사해야 합니다(GPU에 따라 다름).
[Vector addition of 5000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
성공하면 Pod를 삭제할 수 있습니다.
oc delete pod cuda-vector-add