AI 에이전트는 LLM(대규모 언어 모델)과 외부 도구 및 데이터베이스를 결합하여 애플리케이션이 데이터와 상호 작용하는 방식을 변환하고 있습니다. 에이전트는 복잡한 워크플로를 자동화하고, 정보 검색의 정확도를 향상시키며, 데이터베이스에 대한 자연어 인터페이스를 용이하게 합니다.
이 문서에서는 Azure Database for PostgreSQL에서 데이터를 검색하고 분석할 수 있는 지능형 AI 에이전트를 만드는 방법을 살펴봅니다. 법률 연구 도우미를 예로 사용하여 설정, 구현 및 테스트를 안내합니다.
AI 에이전트란?
AI 에이전트는 LLM과 외부 도구 및 데이터베이스를 결합하여 간단한 챗봇을 넘어갑니다. 독립 실행형 LLM 또는 RAG(표준 검색 보강 세대) 시스템과 달리 AI 에이전트는 다음을 수행할 수 있습니다.
- 계획: 복잡한 작업을 더 작은 순차적 단계로 세분화합니다.
- 도구 사용: API, 코드 실행 및 검색 시스템을 사용하여 정보를 수집하거나 작업을 수행합니다.
- 인식: 다양한 데이터 원본의 입력을 이해하고 처리합니다.
- 기억하세요. 더 나은 의사 결정을 위해 이전 상호 작용을 저장하고 기억하십시오.
Azure Database for PostgreSQL과 같은 데이터베이스에 AI 에이전트를 연결하면 에이전트는 데이터를 기반으로 보다 정확하고 컨텍스트 인식 응답을 제공할 수 있습니다. AI 에이전트는 기본 사용자 대화를 넘어 자연어를 기반으로 작업을 수행합니다. 이러한 작업에는 전통적으로 코딩된 논리가 필요했습니다. 그러나 에이전트는 사용자가 제공한 컨텍스트에 따라 실행하는 데 필요한 작업을 계획할 수 있습니다.
AI 에이전트 구현
Azure Database for PostgreSQL을 사용하여 AI 에이전트를 구현하려면 고급 AI 기능을 강력한 데이터베이스 기능과 통합하여 지능형 컨텍스트 인식 시스템을 만듭니다. 개발자는 벡터 검색, 포함 및 Foundry 에이전트 서비스와 같은 도구를 사용하여 자연어 쿼리를 이해하고 관련 데이터를 검색하며 실행 가능한 인사이트를 제공하는 에이전트를 빌드할 수 있습니다.
다음 섹션에서는 AI 에이전트를 설정, 구성 및 배포하는 단계별 프로세스를 간략하게 설명합니다. 이 프로세스를 통해 AI 모델과 PostgreSQL 데이터베이스 간의 원활한 상호 작용이 가능합니다.
프레임워크
다양한 프레임워크와 도구를 사용하면 AI 에이전트의 개발과 배포를 지원할 수 있습니다. 이러한 모든 프레임워크는 Azure Database for PostgreSQL을 도구로 사용할 수 있습니다.
구현 예제
이 문서의 예제에서는 에이전트 계획, 도구 사용 및 인식에 에이전트 서비스를 사용합니다. Azure Database for PostgreSQL을 벡터 데이터베이스 및 의미 체계 검색 기능을 위한 도구로 사용합니다.
다음 섹션에서는 법률 팀이 워싱턴 주에서 고객을 지원하기 위해 관련 사례를 조사하는 데 도움이 되는 AI 에이전트를 빌드하는 방법을 안내합니다. 에이전트:
- 법적 상황에 대한 자연어 쿼리를 허용합니다.
- Azure Database for PostgreSQL에서 벡터 검색을 사용하여 관련 사례 판례를 찾습니다.
- 법률 전문가를 위한 유용한 형식으로 결과를 분석하고 요약합니다.
필수 조건
해당 확장을 사용하도록 설정하고 구성
azure_aipg_vector합니다.모델 배포
gpt-4o-mini및 기타text-embedding-small.Visual Studio Code를 설치합니다.
Python 확장을 설치 합니다 .
Python 3.11.x를 설치합니다.
Azure CLI(최신 버전)를 설치합니다.
비고
에이전트에 대해 만든 배포된 모델의 키와 엔드포인트가 필요합니다.
시작하기
모든 코드 및 샘플 데이터 세트는 이 GitHub 리포지토리에서 사용할 수 있습니다.
1단계: Azure Database for PostgreSQL에서 벡터 검색 설정
먼저 벡터 포함을 사용하여 법적 사례 데이터를 저장하고 검색하도록 데이터베이스를 준비합니다.
환경 설정
macOS 및 Bash를 사용하는 경우 다음 명령을 실행합니다.
python -m venv .pg-azure-ai
source .pg-azure-ai/bin/activate
pip install -r requirements.txt
Windows 및 PowerShell을 사용하는 경우 다음 명령을 실행합니다.
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\Activate.ps1
pip install -r requirements.txt
Windows에서 cmd.exe를 사용하는 경우, 다음 명령어들을 실행하세요.
python -m venv .pg-azure-ai
.pg-azure-ai \Scripts\activate.bat
pip install -r requirements.txt
환경 변수 구성
자격 증명을 사용하여 .env 파일을 만듭니다.
AZURE_OPENAI_API_KEY=""
AZURE_OPENAI_ENDPOINT=""
EMBEDDING_MODEL_NAME=""
AZURE_PG_CONNECTION=""
문서 및 벡터 로드
Python 파일 load_data/main.py Azure Database for PostgreSQL에 데이터를 로드하기 위한 중앙 진입점 역할을 합니다. 이 코드는 워싱턴의 사례에 대한 정보를 포함하여 샘플 사례에 대한 데이터를 처리합니다.
main.py 파일:
- 필요한 확장을 만들고, OpenAI API 설정을 설정하고, 기존 확장을 삭제하고, 사례 데이터를 저장하기 위한 새 확장을 만들어 데이터베이스 테이블을 관리합니다.
- CSV 파일에서 데이터를 읽고 임시 테이블에 삽입한 다음 처리하여 주 사례 테이블로 전송합니다.
- 사례 테이블에 포함할 새 열을 추가하고 OpenAI의 API를 사용하여 사례 의견에 대한 포함을 생성합니다. 새 열에 임베딩을 저장합니다. 포함 프로세스는 약 3~5분이 걸립니다.
데이터 로드 프로세스를 시작하려면 디렉터리에서 load_data 다음 명령을 실행합니다.
python main.py
의 출력 main.py은 다음과 같습니다.
Extensions created successfully
OpenAI connection established successfully
The case table was created successfully
Temp cases table created successfully
Data loaded into temp_cases_data table successfully
Data loaded into cases table successfully.
Adding Embeddings will take a while, around 3-5 mins.
Embeddings added successfully All Data loaded successfully!
2단계: 에이전트에 대한 Postgres 도구 만들기
다음으로 Postgres에서 데이터를 검색하도록 AI 에이전트 도구를 구성합니다. 그런 다음 에이전트 서비스 SDK를 사용하여 AI 에이전트를 Postgres 데이터베이스에 연결합니다.
에이전트가 호출할 함수 정의
먼저 문서 문자열에서 해당 구조 및 필수 매개 변수를 설명하여 에이전트가 호출할 함수를 정의합니다. 모든 함수 정의를 legal_agent_tools.py 단일 파일에 포함합니다. 그런 다음 파일을 기본 스크립트로 가져올 수 있습니다.
def vector_search_cases(vector_search_query: str, start_date: datetime ="1911-01-01", end_date: datetime ="2025-12-31", limit: int = 10) -> str:
"""
Fetches the case information in Washington State for the specified query.
:param query(str): The query to fetch cases specifically in Washington.
:type query: str
:param start_date: The start date for the search defaults to "1911-01-01"
:type start_date: datetime, optional
:param end_date: The end date for the search, defaults to "2025-12-31"
:type end_date: datetime, optional
:param limit: The maximum number of cases to fetch, defaults to 10
:type limit: int, optional
:return: Cases information as a JSON string.
:rtype: str
"""
db = create_engine(CONN_STR)
query = """
SELECT id, name, opinion,
opinions_vector <=> azure_openai.create_embeddings(
'text-embedding-3-small', %s)::vector as similarity
FROM cases
WHERE decision_date BETWEEN %s AND %s
ORDER BY similarity
LIMIT %s;
"""
# Fetch case information from the database
df = pd.read_sql(query, db, params=(vector_search_query,datetime.strptime(start_date, "%Y-%m-%d"), datetime.strptime(end_date, "%Y-%m-%d"),limit))
cases_json = json.dumps(df.to_json(orient="records"))
return cases_json
3단계: Postgres를 사용하여 AI 에이전트 만들기 및 구성
이제 AI 에이전트를 설정하고 Postgres 도구와 통합합니다. Python 파일 src/simple_postgres_and_ai_agent.py 에이전트를 만들고 사용하기 위한 중앙 진입점 역할을 합니다.
simple_postgres_and_ai_agent.py 파일:
- 특정 모델을 사용하여 Foundry 프로젝트에서 에이전트를 초기화합니다.
- 에이전트를 초기화하는 동안 데이터베이스에서 벡터 검색을 위한 Postgres 도구를 추가합니다.
- 통신 스레드를 설정합니다. 이 스레드는 처리를 위해 에이전트에 메시지를 보내는 데 사용됩니다.
- 에이전트 및 도구를 사용하여 사용자의 쿼리를 처리합니다. 에이전트는 도구를 활용하여 계획을 세워 정확한 답변을 얻을 수 있습니다. 이 사용 사례에서 에이전트는 함수 서명 및 문서 문자열을 기반으로 Postgres 도구를 호출하여 벡터 검색을 수행하고 관련 데이터를 검색하여 질문에 대답합니다.
- 사용자의 쿼리에 대한 에이전트의 응답을 표시합니다.
Foundry에서 프로젝트 연결 문자열 찾기
Foundry 프로젝트의 개요 페이지에서 프로젝트 연결 문자열을 찾습니다. 이 문자열을 사용하여 프로젝트를 에이전트 서비스 SDK에 연결합니다. 이 문자열을 파일에 추가합니다 .env .
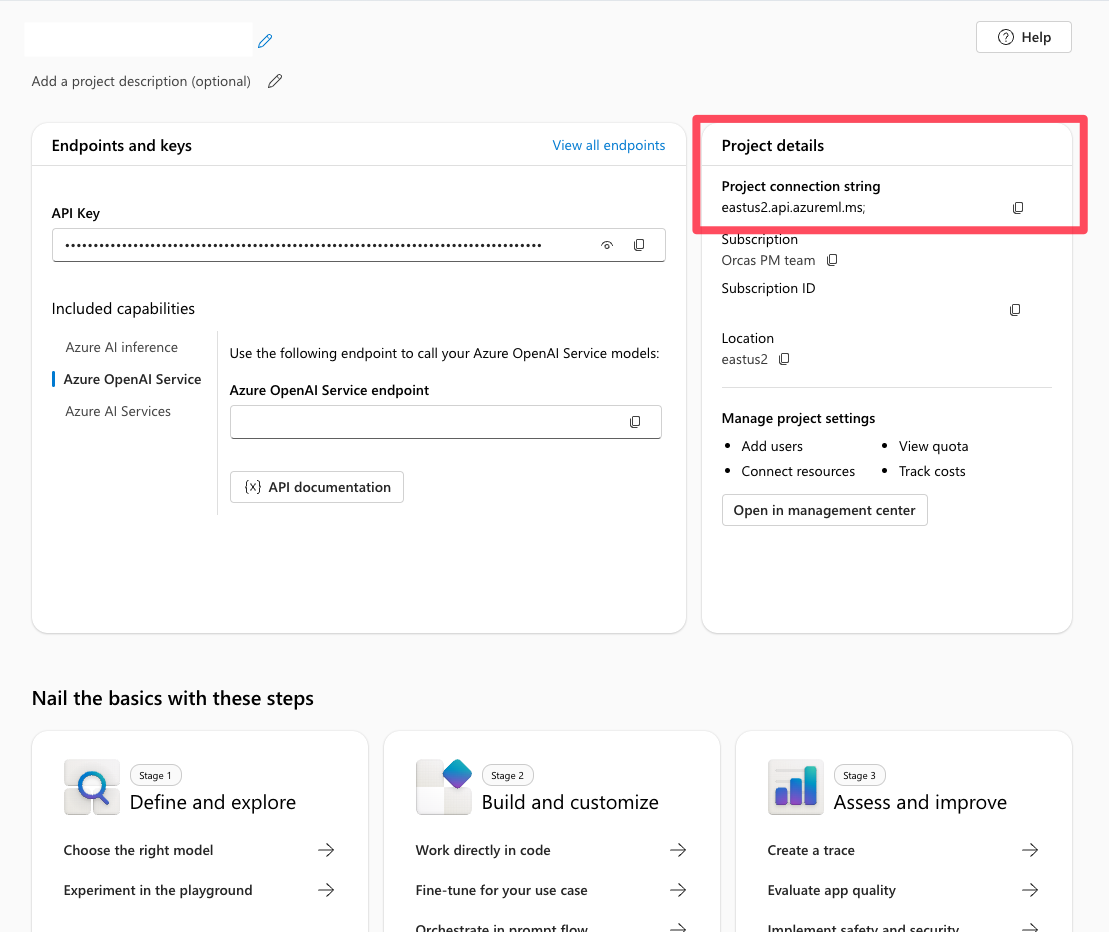
연결 설정
루트 디렉터리의 파일에 다음 변수 .env 를 추가합니다.
PROJECT_CONNECTION_STRING=" "
MODEL_DEPLOYMENT_NAME="gpt-4o-mini"
AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLED="true"
### Create the agent with tool access
We created the agent in the Foundry project and added the Postgres tools needed to query the database. The code snippet below is an excerpt from the file [simple_postgres_and_ai_agent.py](https://github.com/Azure-Samples/postgres-agents/blob/main/azure-ai-agent-service/src/simple_postgres_and_ai_agent.py).
# Create a Foundry client
project_client = AIProjectClient.from_connection_string(
credential=DefaultAzureCredential(),
conn_str=os.environ["PROJECT_CONNECTION_STRING"],
)
# Initialize the agent toolset with user functions
functions = FunctionTool(user_functions)
toolset = ToolSet()
toolset.add(functions)
agent = project_client.agents.create_agent(
model= os.environ["MODEL_DEPLOYMENT_NAME"],
name="legal-cases-agent",
instructions= "You are a helpful legal assistant who can retrieve information about legal cases.",
toolset=toolset
)
통신 스레드 만들기
이 코드 조각은 에이전트 스레드와 메시지를 만드는 방법을 보여 하며 에이전트는 실행에서 처리합니다.
# Create a thread for communication
thread = project_client.agents.create_thread()
# Create a message to thread
message = project_client.agents.create_message(
thread_id=thread.id,
role="user",
content="Water leaking into the apartment from the floor above. What are the prominent legal precedents in Washington regarding this problem in the last 10 years?"
)
요청 처리
다음 코드 조각은 에이전트가 메시지를 처리하고 적절한 도구를 사용하여 최상의 결과를 제공하는 실행을 만듭니다.
에이전트는 도구를 사용하여 Postgres 및 벡터 검색을 호출하여 "위의 바닥에서 아파트로 누수되는 물"을 검색하여 질문에 가장 잘 대답하는 데 필요한 데이터를 검색할 수 있습니다.
from pprint import pprint
# Create and process an agent run in the thread with tools
run = project_client.agents.create_and_process_run(
thread_id=thread.id,
agent_id=agent.id
)
# Fetch and log all messages
messages = project_client.agents.list_messages(thread_id=thread.id)
pprint(messages['data'][0]['content'][0]['text']['value'])
에이전트 실행
에이전트를 실행하려면 디렉터리에서 src 다음 명령을 실행합니다.
python simple_postgres_and_ai_agent.py
에이전트는 Azure Database for PostgreSQL 도구를 사용하여 Postgres 데이터베이스에 저장된 사례 데이터에 액세스하여 비슷한 결과를 생성합니다.
에이전트의 출력 코드 조각은 다음과 같습니다.
1. Pham v. Corbett
Citation: Pham v. Corbett, No. 4237124
Summary: This case involved tenants who counterclaimed against their landlord for relocation assistance and breached the implied warranty of habitability due to severe maintenance issues, including water and sewage leaks. The trial court held that the landlord had breached the implied warranty and awarded damages to the tenants.
2. Hoover v. Warner
Citation: Hoover v. Warner, No. 6779281
Summary: The Warners appealed a ruling finding them liable for negligence and nuisance after their road grading project caused water drainage issues affecting Hoover's property. The trial court found substantial evidence supporting the claim that the Warners' actions impeded the natural water flow and damaged Hoover's property.
4단계: 에이전트 플레이그라운드를 사용하여 테스트 및 디버그
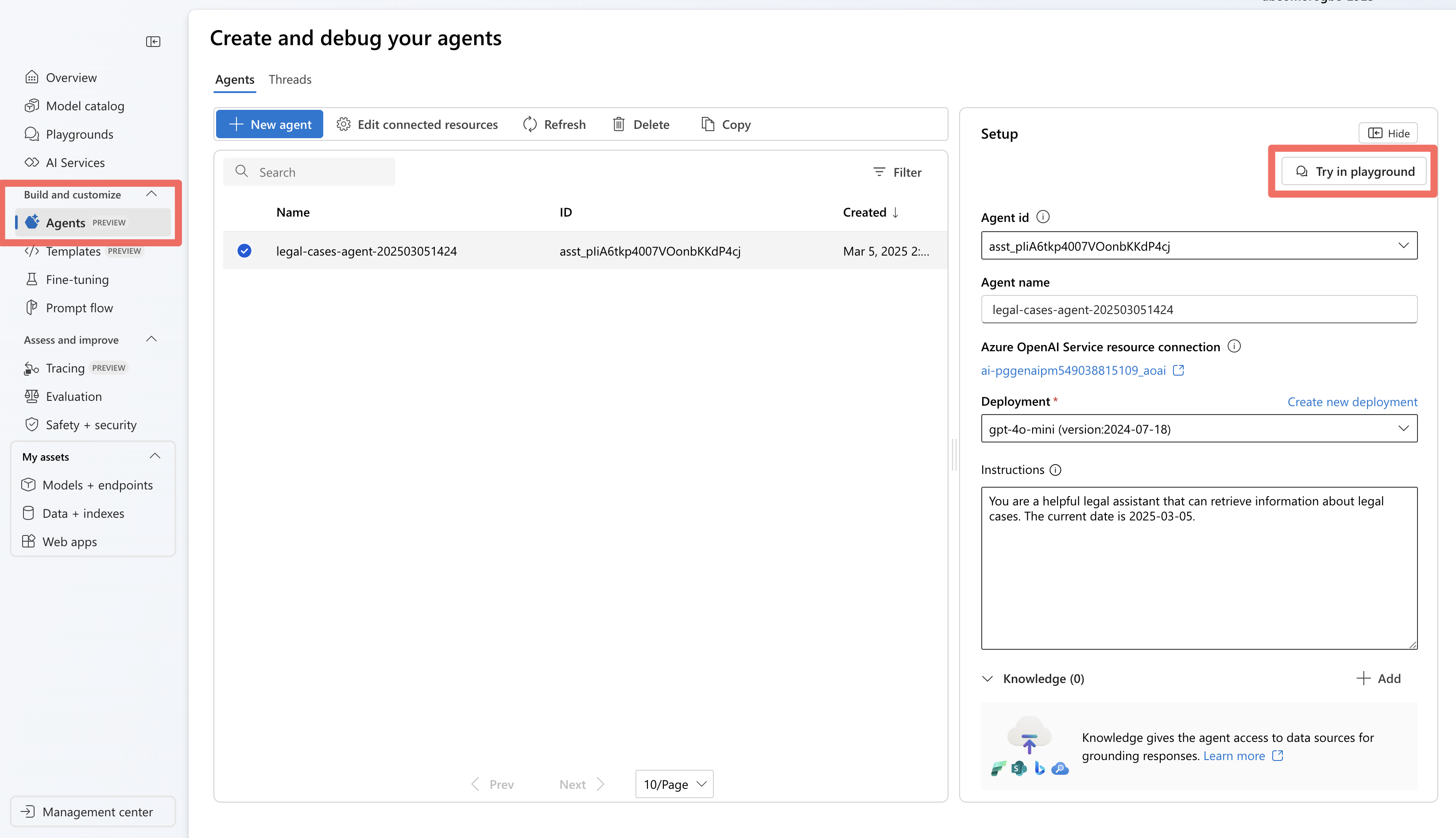
에이전트 서비스 SDK를 사용하여 에이전트를 실행하면 에이전트가 프로젝트에 저장됩니다. 에이전트 플레이그라운드에서 에이전트를 실험할 수 있습니다.
Foundry에서 에이전트 섹션으로 이동합니다.
목록에서 에이전트를 찾아서 선택하여 엽니다.
플레이그라운드 인터페이스를 사용하여 다양한 법적 쿼리를 테스트합니다.
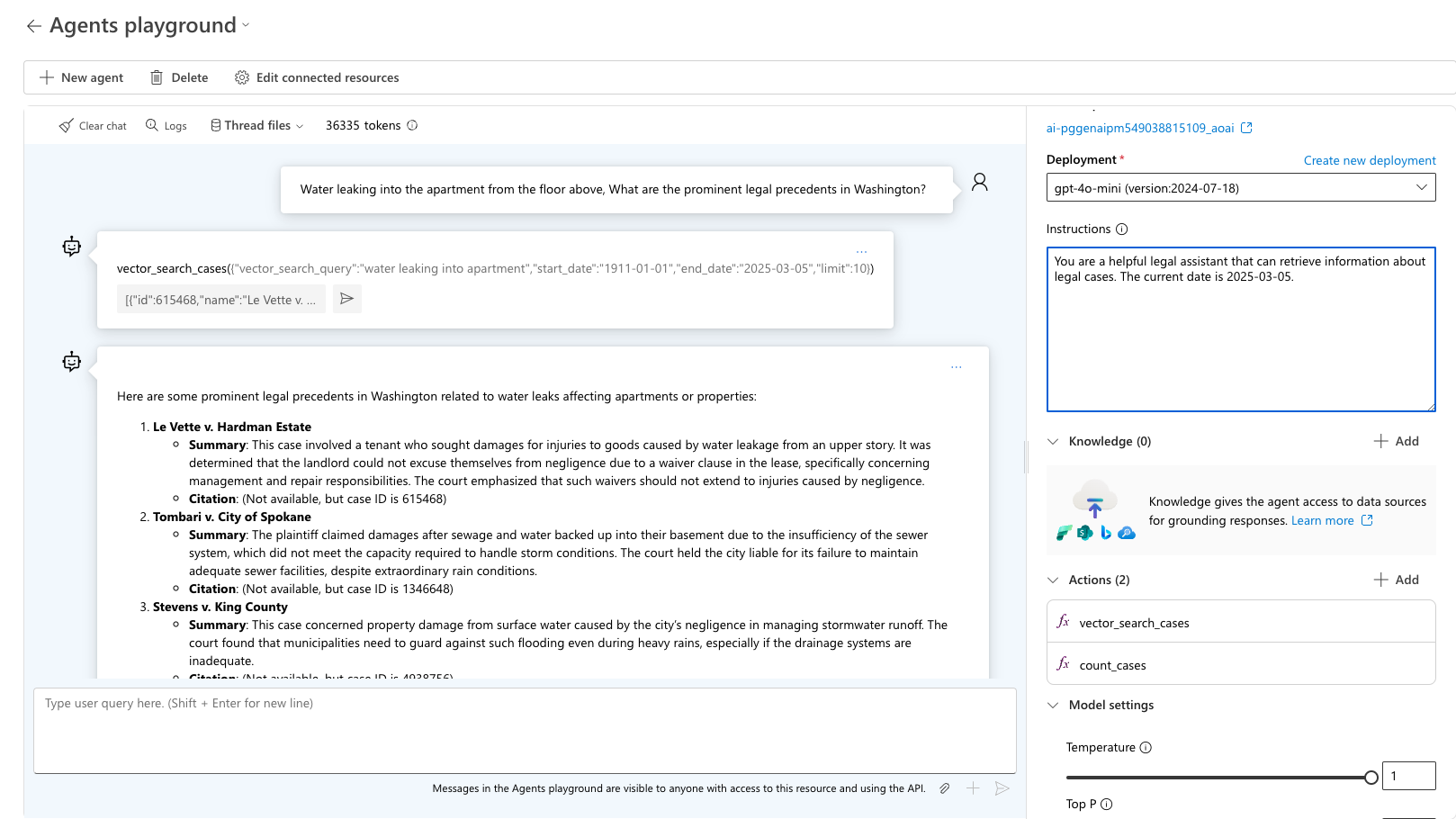
"위의 바닥에서 아파트로 물이 누출되는 경우 워싱턴에서 눈에 띄는 법적 판례는 무엇입니까?" 쿼리를 테스트합니다. 에이전트는 사용할 올바른 도구를 선택하고 해당 쿼리에 대한 예상 출력을 요청합니다. sample_vector_search_cases_output.json 샘플 출력으로 사용합니다.
5단계: Foundry 추적을 사용하여 디버그
에이전트 서비스 SDK를 사용하여 에이전트를 개발하는 경우 추적을 사용하여 에이전트를 디버그할 수 있습니다. 추적을 사용하면 Postgres와 같은 도구에 대한 호출을 디버그하고 에이전트가 각 작업을 오케스트레이션하는 방법을 확인할 수 있습니다.
Foundry에서 추적으로 이동합니다.
새 Application Insights 리소스를 만들려면 새로 만들기를 선택합니다. 기존 리소스를 연결하려면 Application Insights 리소스 이름 상자에서 리소스를 선택한 다음 연결을 선택합니다.
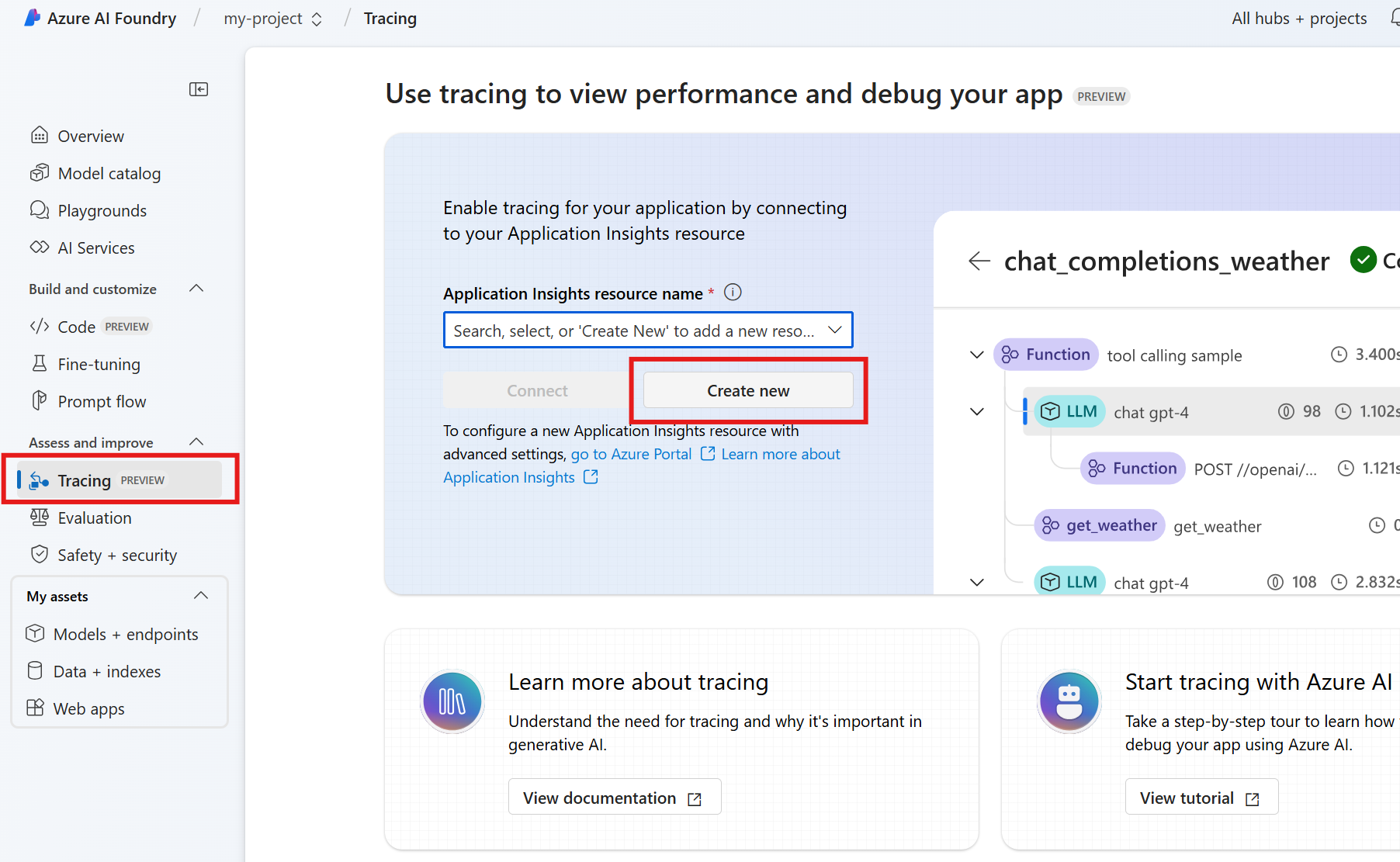
에이전트 작업의 자세한 추적 정보를 확인합니다.
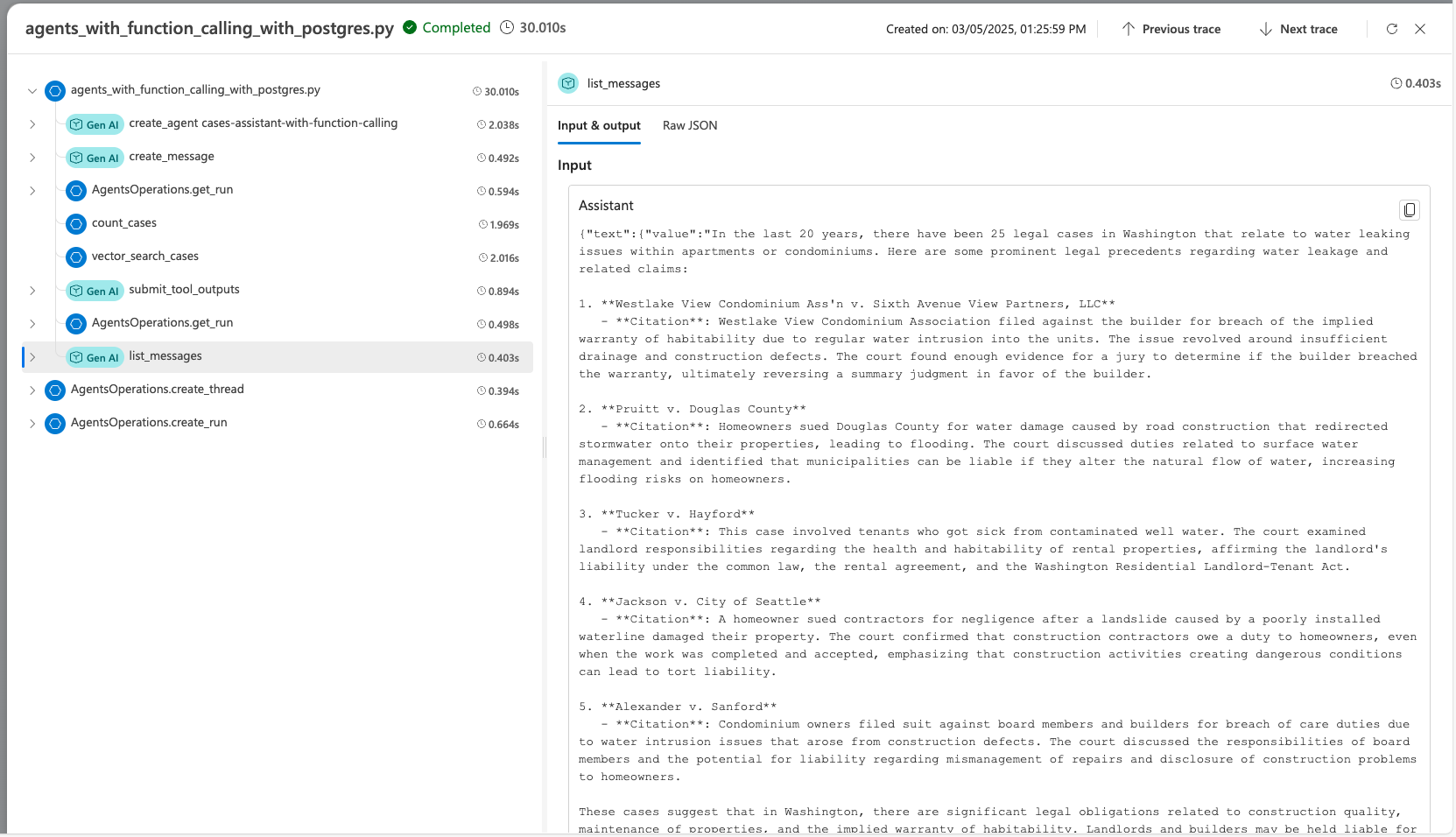
GitHub의 advanced_postgres_and_ai_agent_with_tracing.py 파일에서 AI 에이전트 및 Postgres를 사용하여 추적을 설정하는 방법에 대해 자세히 알아봅니다.
관련 콘텐츠
- AI 애플리케이션에 대한 Azure Database for PostgreSQL 통합
- Azure Database for PostgreSQL에서 LangChain 사용
- Azure Database for PostgreSQL에서 Azure OpenAI를 사용하여 벡터 포함 생성
- Azure Database for PostgreSQL의 Azure AI 확장
- Azure Database for PostgreSQL 및 Azure OpenAI를 사용하여 의미 체계 검색 만들기
- Azure Database for PostgreSQL에서 pgvector 사용 설정 및 사용