az postgres flexible-server index-tuning list-recommendations 명령을 통해 기존 서버에서 인덱스 튜닝으로 생성된 인덱스 튜닝 권장 사항을 나열할 수 있습니다.
모든 CREATE INDEX 권장 사항을 나열하려면 다음 명령을 사용합니다.
az postgres flexible-server index-tuning list-recommendations \
--resource-group <resource_group> \
--server-name <server> \
--recommendation-type createindex
이 명령은 인덱스 튜닝에 의해 생성된 CREATE INDEX 권장 사항에 대한 모든 정보를 반환하며, 다음 출력과 유사합니다.
[
{
"analyzedWorkload": {
"endTime": "2025-02-26T14:40:18.788628+00:00",
"queryCount": 18,
"startTime": "2025-02-26T13:40:18.788628+00:00"
},
"details": {
"databaseName": "<database>",
"includedColumns": "",
"indexColumns": "\"<table>\".\"<column>\"",
"indexName": "<index>",
"indexType": "BTREE",
"schema": "<schema>",
"table": "<table>"
},
"estimatedImpact": [
{
"absoluteValue": 0.3984375,
"dimensionName": "IndexSize",
"queryId": null,
"unit": "MB"
},
{
"absoluteValue": 62.86969111969111,
"dimensionName": "QueryCostImprovement",
"queryId": -555955670159268890,
"unit": "Percentage"
}
],
"id": "/subscriptions/<subscription_id>/resourceGroups/<resource_group>/providers/Microsoft.DBforPostgreSQL/flexibleServers/<server>/tuningOptions/index/recommendations/<recommendation_id>",
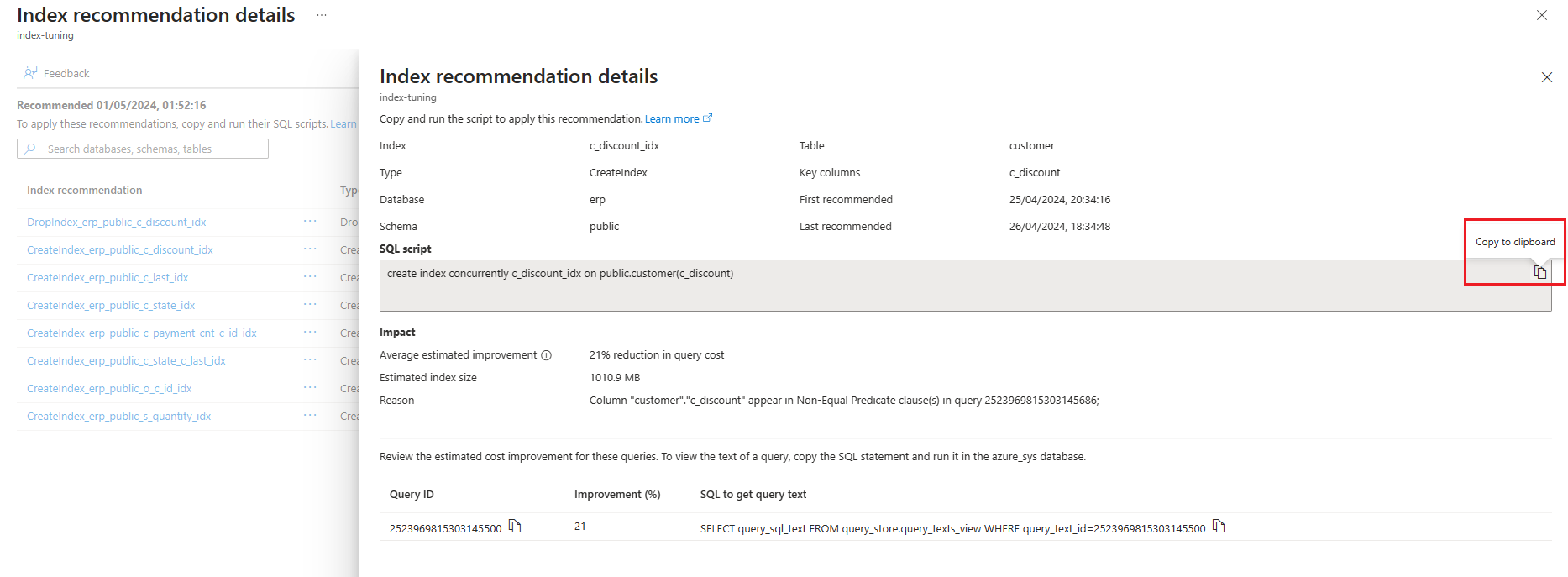
"implementationDetails": {
"method": "SQL",
"script": "create index concurrently <index> on <schema>.<table>(<column>)"
},
"improvedQueryIds": [
-555955670159268890
],
"initialRecommendedTime": "2025-02-26T14:40:19.707617+00:00",
"kind": "",
"lastRecommendedTime": "2025-02-26T14:40:19.707617+00:00",
"name": "CreateIndex_<database>_<schema>_<column>_idx",
"recommendationReason": "Column \"<table>\".\"<column>\" appear in Equal Predicate clause(s) in query -555955670159268890;",
"recommendationType": "CreateIndex",
"resourceGroup": "<resource_group>",
"systemData": null,
"timesRecommended": 1,
"type": "Microsoft.DBforPostgreSQL/flexibleServers/tuningOptions/index"
},
{
.
.
.
}
]
모든 DROP INDEX 권장 사항을 나열하려면 다음 명령을 사용합니다.
az postgres flexible-server index-tuning list-recommendations \
--resource-group <resource_group> \
--server-name <server> \
--recommendation-type dropindex
이 명령은 인덱스 튜닝에 의해 생성된 DROP INDEX 권장 사항에 대한 모든 정보를 반환하며, 다음 출력과 유사합니다.
[
{
"analyzedWorkload": {
"endTime": "2025-02-26T19:02:47.522193+00:00",
"queryCount": 0,
"startTime": "2025-01-22T19:02:47.522193+00:00"
},
"details": {
"databaseName": "<database>",
"includedColumns": "",
"indexColumns": "<column>",
"indexName": "<index>",
"indexType": "BTREE",
"schema": "<schema>",
"table": "<table>"
},
"estimatedImpact": [
{
"absoluteValue": 35.0,
"dimensionName": "Benefit",
"queryId": null,
"unit": "Percentage"
},
{
"absoluteValue": 31.28125,
"dimensionName": "IndexSize",
"queryId": null,
"unit": "MB"
}
],
"id": "/subscriptions/<subscription_id>/resourceGroups/<resource_group>/providers/Microsoft.DBforPostgreSQL/flexibleServers/<server>/tuningOptions/index/recommendations/<recommendation_id>",
"implementationDetails": {
"method": "SQL",
"script": "drop index concurrently \"<schema>\".\"<index>\";"
},
"improvedQueryIds": null,
"initialRecommendedTime": "2025-02-26T19:02:47.556792+00:00",
"kind": "",
"lastRecommendedTime": "2025-02-26T19:02:47.556792+00:00",
"name": "DropIndex_<database>_<sechema>_<index>",
"recommendationReason": "Duplicate of \"<index>\". The equivalent index \"<index>\" has a shorter length compared to \"<index>\".",
"recommendationType": "DropIndex",
"resourceGroup": "<resource_group>",
"systemData": null,
"timesRecommended": 1,
"type": "Microsoft.DBforPostgreSQL/flexibleServers/tuningOptions/index"
}
]
기본 설정의 PostgreSQL 클라이언트 도구 사용:
인스턴스에 연결할 수 있는 권한이 있는 역할을 사용하여 서버에서 사용할 수 있는 azure_sys 데이터베이스에 연결합니다.
public 역할의 구성원은 이러한 보기에서 읽을 수 있습니다.
sessions 뷰에서 쿼리를 실행하여 권장 사항 세션에 대한 세부 정보를 검색합니다.
recommendations 뷰에서 쿼리를 실행하여 CREATE INDEX 및 DROP INDEX에 대한 인덱스 튜닝으로 생성된 권장 사항을 검색합니다.
보기
azure_sys 데이터베이스의 뷰를 활용하면 인덱스 튜닝으로 생성된 인덱스 권장 사항에 편리하게 액세스하고 이러한 항목을 검색할 수 있습니다. 특히, createindexrecommendations 및 dropindexrecommendations 뷰에는 각각 CREATE INDEX 및 DROP INDEX 권장 사항에 대한 자세한 정보가 포함되어 있습니다. 이러한 뷰에는 세션 ID, 데이터베이스 이름, 관리자 유형, 튜닝 세션의 시작 및 중지 시간, 권장 사항 ID, 권장 사항 유형, 권장 사항 이유 및 기타 관련 세부 정보와 같은 데이터가 표시됩니다. 사용자는 이러한 뷰를 쿼리하여 인덱스 튜닝으로 생성된 인덱스 권장 사항에 쉽게 액세스하고 분석할 수 있습니다.
sessions 뷰는 모든 인덱스 튜닝 세션에 대한 모든 세부 정보를 표시합니다.
| 열 이름 |
데이터 형식 |
설명 |
| 세션_아이디 |
uuid |
시작된 모든 새 튜닝 세션에 할당된 전역 고유 식별자입니다. |
| 데이터베이스_이름 |
varchar(64) |
인덱스 튜닝 세션이 실행된 컨텍스트의 데이터베이스 이름입니다. |
| 세션 유형 |
intelligentperformance.recommendation_type |
이 인덱스 튜닝 세션에서 생성할 수 있는 권장 사항 유형을 나타냅니다. 가능한 값은 CreateIndex, DropIndex입니다.
CreateIndex 형식 세션은 CreateIndex 형식의 권장 사항을 생성할 수 있습니다.
DropIndex 형식 세션 은 DropIndex 또는 ReIndex 형식의 권장 사항을 생성할 수 있습니다. |
| 실행 유형 |
intelligentperformance.recommendation_run_type |
이 세션이 시작된 방법을 나타냅니다. 가능한 값은 Scheduled입니다.
index_tuning.analysis_interval 값 에 따라 자동으로 실행되는 세션에는 실행 형식 Scheduled가 할당됩니다. |
| state |
intelligentperformance.recommendation_state |
세션의 현재 상태를 나타냅니다. 가능한 값: Error, Success, InProgress. 실행이 실패한 세션은 Error로 설정됩니다. 권장 사항을 생성했는지 여부에 관계없이 실행을 올바르게 완료한 세션은 Success로 설정됩니다. 여전히 실행 중인 세션은 InProgress로 설정됩니다. |
| 시작_시간 |
표준 시간대가 없는 타임스탬프 |
이 권장 사항을 생성한 튜닝 세션이 시작된 타임스탬프입니다. |
| 중지 시간 |
표준 시간대가 없는 타임스탬프 |
이 권장 사항을 생성한 튜닝 세션이 시작된 타임스탬프입니다. 세션이 진행 중이거나 일부 오류로 인해 중단된 경우 NULL입니다. |
| 추천 수량 |
integer |
이 세션에서 생성된 권장 사항의 총 수입니다. |
recommendations 뷰는 해당 데이터를 기본 테이블에서 계속 사용할 수 있는 튜닝 세션에서 생성된 모든 권장 사항에 대한 모든 세부 정보를 표시합니다.
| 열 이름 |
데이터 형식 |
설명 |
| 추천_아이디 |
integer |
전체 서버에서 권장 사항을 고유하게 식별하는 숫자입니다. |
| 마지막_알려진_세션_ID |
uuid |
모든 인덱스 튜닝 세션에는 전역 고유 식별자가 할당됩니다. 이 열의 값은 가장 최근에 이 권장 사항을 생성한 세션의 값을 나타냅니다. |
| 데이터베이스_이름 |
varchar(64) |
컨텍스트에서 권장 사항을 생성한 데이터베이스의 이름입니다. |
| 추천 유형 |
intelligentperformance.recommendation_type |
생성된 권장 사항의 유형을 나타냅니다. 가능한 값: CreateIndex, DropIndex, ReIndex. |
| 초기 권장 시간 |
표준 시간대가 없는 타임스탬프 |
이 권장 사항을 생성한 튜닝 세션이 시작된 타임스탬프입니다. |
| 최종 추천 시간 |
표준 시간대가 없는 타임스탬프 |
이 권장 사항을 생성한 튜닝 세션이 시작된 타임스탬프입니다. |
| times_recommended |
integer |
이 권장 사항을 생성한 튜닝 세션이 시작된 타임스탬프입니다. |
| 이유 |
문자 메시지 |
이 권장 사항이 생성된 이유를 정당화하는 이유입니다. |
| 추천 문맥 |
json : |
권장 사항의 영향을 받는 쿼리에 대한 쿼리 식별자 목록, 권장되는 인덱스 유형, 스키마 이름 및 인덱스가 권장되는 테이블의 이름, 인덱스 열, 인덱스 이름 및 권장 인덱스의 예상 크기(바이트)를 포함합니다. |
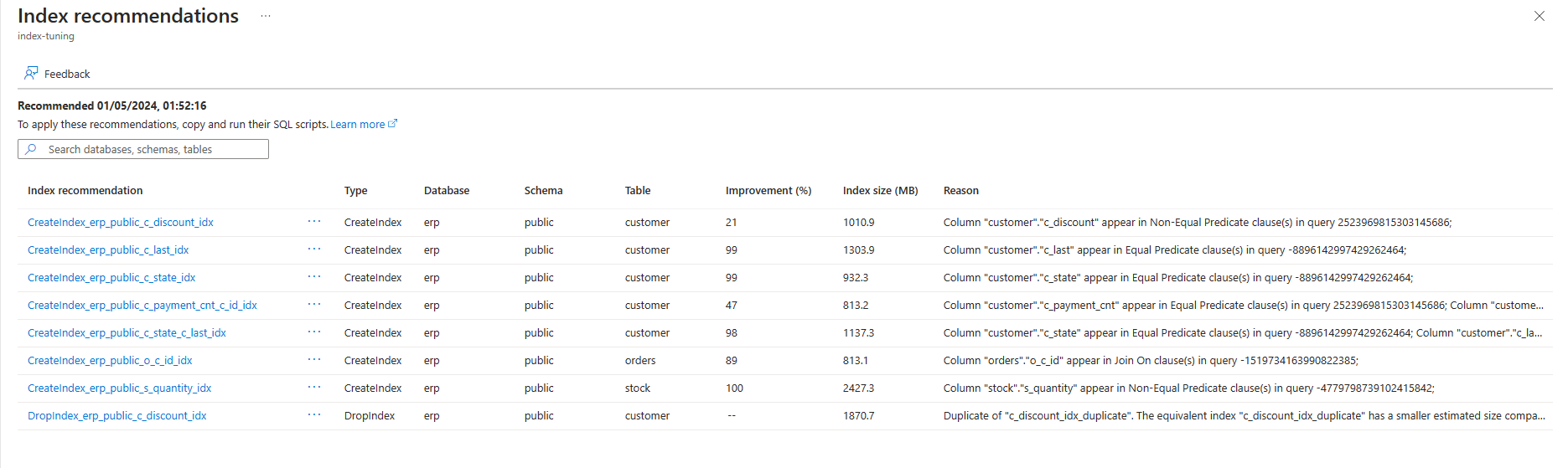
인덱스 권장 사항을 만드는 이유
인덱스 튜닝에서 인덱스 생성을 권장하는 경우 다음 이유 중 하나 이상을 추가로 표시합니다.
| 이유 |
Column <column> appear in Join On clause(s) in query <queryId> |
Column <column> appear in Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Non-Equal Predicate clause(s) in query <queryId> |
Column <column> appear in Group By clause(s) in query <queryId> |
Column <column> appear in Order By clause(s) in query <queryId> |
인덱스 권장 사항을 삭제하는 이유
인덱스 튜닝이 잘못된 것으로 표시된 인덱스를 식별하면 다음과 같은 이유로 인덱스를 삭제할 것을 제안합니다.
The index is invalid and the recommended recovery method is to reindex.
인덱스가 잘못된 것으로 표시되는 이유와 시기에 대한 자세한 내용은 PostgreSQL의 REINDEX 공식 설명서를 참조하세요.
인덱스 권장 사항을 삭제하는 이유
인덱스 튜닝이 index_tuning.unused_min_period에 설정된 기간(일) 넘게 사용되지 않는 인덱스를 감지하면 다음과 같은 이유로 인덱스를 삭제할 것을 제안합니다.
The index is unused in the past <days_unused> days.
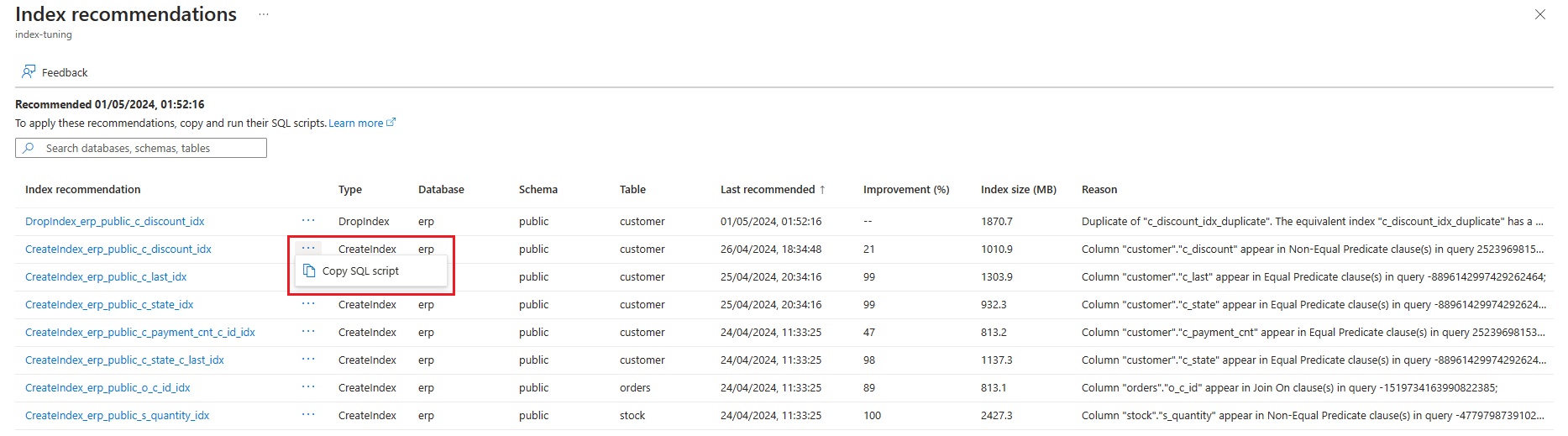
인덱스 튜닝이 중복 인덱스를 검색하면 중복 항목 중 하나가 유지되고 나머지 인덱스를 삭제할 것을 제안합니다. 제공된 이유에는 항상 다음과 같은 시작 텍스트가 있습니다.
Duplicate of <surviving_duplicate>.
각 중복 항목을 삭제하기 위해 선택한 이유를 설명하는 다른 텍스트가 뒤에 잇습니다.
| 이유 |
The equivalent index "<surviving_duplicate>" is a Primary key, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a unique index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a constraint, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" is a valid index, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" has been chosen as replica identity, while "<droppable_duplicate>" is not. |
The equivalent index "<surviving_duplicate>" was used to cluster the table, while "<droppable_duplicate>" was not. |
The equivalent index "<surviving_duplicate>" has a smaller estimated size compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more tuples compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has more index scans compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been fetched more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has been read more times compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a shorter length compared to "<droppable_duplicate>". |
The equivalent index "<surviving_duplicate>" has a smaller oid compared to "<droppable_duplicate>". |
인덱스가 중복으로 인해 제거 가능할 뿐만 아니라 index_tuning.unused_min_period에 설정된 기간(일) 넘게 사용되지 않는 경우 다음 텍스트가 해당 이유에 추가됩니다.
Also, the index is unused in the past <days_unused> days.