SUSE Linux Enterprise Server의 Azure VM에 있는 SAP HANA의 고가용성
SAP HANA 시스템 복제 또는 공유 스토리지를 사용하여 온-프레미스 SAP HANA 배포에서 고가용성을 설정할 수 있습니다.
현재 Azure VM(Virtual Machines)에서 지원되는 유일한 고가용성 기능은 Azure의 HANA 시스템 복제입니다.
SAP HANA 복제는 하나의 기본 노드와 하나 이상의 보조 노드로 구성됩니다. 기본 노드의 데이터를 변경하면 보조 노드에 동기적 또는 비동기적으로 복제됩니다.
이 문서에서는 VM을 배포 및 구성하며, 클러스터 프레임워크를 설치하고, SAP HANA 시스템 복제를 설치 및 구성하는 방법을 설명합니다.
시작하기 전에 다음 SAP Note와 문서를 읽어보세요.
- SAP Note 1928533. 메모에는 다음이 포함됩니다.
- SAP 소프트웨어 배포에 지원되는 Azure VM 크기 목록.
- Azure VM 크기에 대한 중요한 용량 정보.
- 지원되는 SAP 소프트웨어 및 OS(운영 체제)와 데이터베이스 조합.
- Microsoft Azure에서 Windows 및 Linux에 필요한 SAP 커널 버전.
- SAP Note 2015553은 Azure에서 SAP를 지원하는 SAP 소프트웨어 배포에 대한 필수 구성 요소가 나열되어 있습니다.
- SAP Note 2205917에는 SAP 애플리케이션용 SUSE Linux Enterprise Server 12(SLES 12)에 대한 권장 OS 설정이 나와 있습니다.
- SAP Note 2684254에는 SAP 애플리케이션용 SUSE Linux Enterprise Server 15(SLES 15)에 대한 권장 OS 설정이 나와 있습니다.
- SAP Note 2235581에 SAP HANA 지원 운영 체제가 있음
- SAP Note 2178632는 Azure에서 SAP에 대해 보고된 모든 모니터링 메트릭에 대한 자세한 정보를 포함하고 있습니다.
- SAP Note 2191498은 Azure에서 Linux에 필요한 SAP Host Agent 버전을 포함하고 있습니다.
- SAP Note 2243692는 Azure에서 Linux용 SAP 라이선싱에 대한 정보를 포함하고 있습니다.
- SAP Note 1984787은 SUSE LINUX Enterprise Server 12에 대한 일반 정보를 포함하고 있습니다.
- SAP Note 1999351에는 SAP용 Azure 고급 모니터링 확장에 대한 추가 문제 해결 정보가 있습니다.
- SAP Note 401162에는 HANA 시스템 복제를 설정할 때 “이미 사용 중인 주소” 오류를 피하는 방법에 대한 정보가 포함되어 있습니다.
- SAP 커뮤니티 지원 Wiki에는 Linux에 필요한 모든 SAP 노트가 포함되어 있습니다.
- SAP HANA 인증 IaaS 플랫폼.
- Linux에서 SAP용 Azure Virtual Machines 계획 및 구현 가이드.
- Linux에서 SAP용 Azure Virtual Machines 배포 가이드.
- Linux에서 SAP용 Azure Virtual Machines DBMS 배포 가이드.
- SUSE Linux Enterprise Server for SAP 애플리케이션의 15개 우수 사례 가이드 및 SUSE Linux Enterprise Server for SAP 애플리케이션의 12개 우수 사례 가이드:
- SAP HANA SR 성능 최적화 인프라 설정(SAP 애플리케이션용 SLES). 이 가이드에는 온-프레미스 개발을 위한 SAP HANA 시스템 복제를 설정하는 데 필요한 모든 정보가 포함되어 있습니다. 이 가이드를 기준으로 사용합니다.
- SAP HANA SR 비용 최적화 인프라 설정(SAP 애플리케이션용 SLES).
SAP HANA 고가용성을 위한 플랜
고가용성을 달성하려면 두 VM에 SAP HANA를 설치합니다. HANA 시스템 복제를 사용하여 데이터가 복제됩니다.
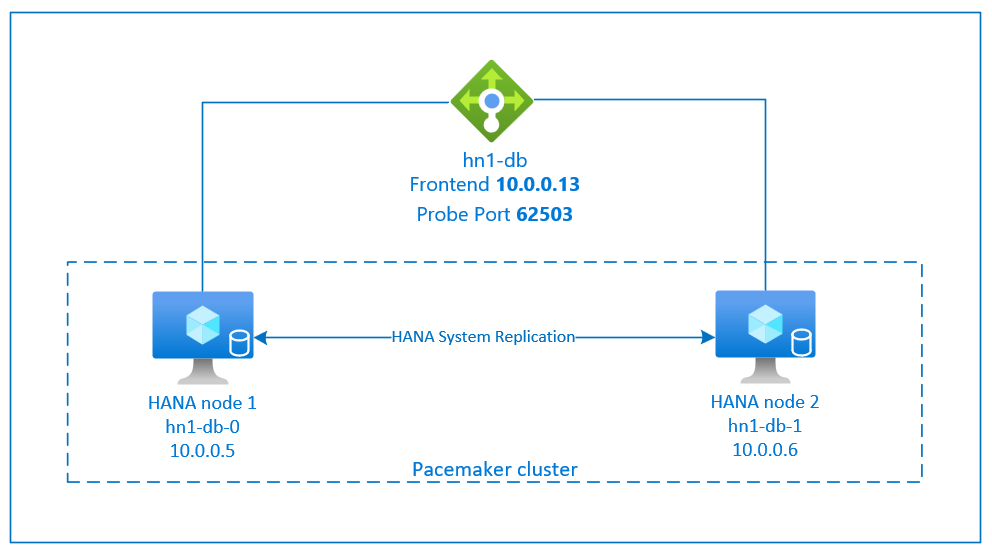
SAP HANA 시스템 복제 설정은 전용 가상 호스트 이름과 가상 IP 주소를 사용합니다. Azure에서 가상 IP 주소를 배포하려면 부하 분산 장치가 필요합니다.
위의 그림에서는 다음과 같은 구성이 있는 부하 분산 장치 예제를 보여줍니다.
- 프런트 엔드 IP 주소: HN1-db의 경우 10.0.0.13
- 프로브 포트: 62503
인프라 준비
SAP HANA의 리소스 에이전트는 SAP 애플리케이션의 SUSE Linux Enterprise Server에 포함되어 있습니다. SAP 애플리케이션 12 또는 15용 SUSE Linux Enterprise Server에 대한 이미지는 Azure Marketplace에서 사용할 수 있습니다. 이미지를 사용하여 새 VM을 배포할 수 있습니다.
Azure Portal을 통해 수동으로 Linux VM 배포
이 문서에서는 리소스 그룹, Azure Virtual Network 및 서브넷을 이미 배포했다고 가정합니다.
SAP HANA용 가상 머신을 배포합니다. HANA 시스템에 지원되는 적합한 SLES 이미지를 선택합니다. 가상 머신 확장 집합, 가용성 영역 또는 가용성 집합과 같은 가용성 옵션 중 하나에서 VM을 배포할 수 있습니다.
Important
선택한 운영 체제가 배포에 사용하려는 특정 VM 유형에서 SAP HANA용으로 인증된 SAP인지 확인해야 합니다. SAP HANA 인증 IaaS 플랫폼에서 SAP HANA 인증 VM 유형 및 해당 OS 릴리스 를 조회할 수 있습니다. 특정 VM 형식에 대한 SAP HANA 지원 OS 릴리스의 전체 목록을 보려면 VM 유형의 세부 정보를 확인하세요.
Azure Load Balancer 구성
VM 구성 중에 네트워킹 섹션에서 기존 부하 분산 장치를 만들거나 선택할 수 있는 옵션이 있습니다. HANA 데이터베이스의 고가용성 설정을 위해 표준 부하 분산 장치를 설정하려면 아래 단계를 따릅니다.
- Azure Portal
- Azure CLI
- PowerShell
Azure Portal을 사용하여 고가용성 SAP 시스템용 표준 Load Balancer를 설정하려면 부하 분산 장치 만들기의 단계를 따릅니다. 부하 분산 장치를 설정하는 동안 다음 사항을 고려합니다.
- 프런트 엔드 IP 구성: 프런트 엔드 IP를 만듭니다. 데이터베이스 가상 머신과 동일한 가상 네트워크 및 서브넷 이름을 선택합니다.
- 백 엔드 풀: 백 엔드 풀을 만들고 데이터베이스 VM을 추가합니다.
- 인바운드 규칙: 부하 분산 규칙을 만듭니다. 두 부하 분산 규칙 모두에 대해 동일한 단계를 수행합니다.
- 프런트 엔드 IP 주소: 프런트 엔드 IP를 선택합니다.
- 백 엔드 풀: 백 엔드 풀을 선택합니다.
- 고가용성 포트: 이 옵션을 선택합니다.
- 프로토콜: TCP를 선택합니다.
- 상태 프로브: 다음 세부 정보를 사용하여 상태 프로브를 만듭니다.
- 프로토콜: TCP를 선택합니다.
- 포트: 예, 625<instance-no.>.
- 간격: 5를 입력합니다.
- 프로브 임계값: 2를 입력합니다.
- 유휴 시간 제한(분): 30을 입력합니다.
- 부동 IP 사용: 이 옵션을 선택합니다.
참고 항목
포털에서 비정상 임계값이라고도 알려진 상태 프로브 구성 속성 numberOfProbes는 준수되지 않습니다. 성공하거나 실패한 연속 프로브 수를 제어하려면 probeThreshold 속성을 2로 설정합니다. 현재 Azure Portal을 사용하여 이 속성을 설정할 수 없으므로 Azure CLI 또는 PowerShell 명령을 사용합니다.
SAP HANA에 필요한 포트에 대한 자세한 내용은 SAP HANA 테넌트 데이터베이스 가이드의 테넌트 데이터베이스에 연결 챕터 또는 SAP Note 2388694를 참조하세요.
참고 항목
공용 IP 주소가 없는 VM이 Azure Load Balancer의 내부(공용 IP 주소 없음) 표준 인스턴스의 백 엔드 풀에 배치되는 경우 기본 구성은 아웃바운드 인터넷 연결이 아닙니다. 퍼블릭 엔드포인트로 라우팅할 수 있도록 추가 단계를 수행할 수 있습니다. 아웃바운드 연결을 설정하는 방법에 대한 자세한 내용은 SAP 고가용성 시나리오에서 Azure 표준 Load Balancer를 사용하는 Virtual Machines에 대한 퍼블릭 엔드포인트 연결을 참조하세요.
Important
- Azure Load Balancer 뒤에 배치되는 Azure VM에서 TCP 타임스탬프를 사용하도록 설정하면 안 됩니다. TCP 타임스탬프를 사용하도록 설정하면 상태 프로브에 오류가 발생합니다. 매개 변수
net.ipv4.tcp_timestamps를0으로 설정합니다. 자세한 내용은 Load Balancer 상태 프로브 또는 SAP Note 2382421을 참조하세요. - saptune이 수동으로 설정된
net.ipv4.tcp_timestamps값을0에서 다시1(으)로 변경하지 못하게 하려면 saptune 버전을 3.1.1 이상으로 업데이트합니다. 자세한 내용은 saptune 3.1.1 – 업데이트가 필요하나요?를 참조하세요.
Pacemaker 클러스터 만들기
이 HANA 서버에 대한 기본 Pacemaker 클러스터를 만들려면 Azure의 SUSE Linux Enterprise Server에서 Pacemaker 설정 단계를 따르세요. SAP HANA 및 SAP NetWeaver (A)SCS에 동일한 Pacemaker 클러스터를 사용할 수 있습니다.
SAP HANA 설치
이 섹션에서는 단계에 다음 접두사를 사용합니다.
- [A]: 단계가 모든 노드에 적용됩니다.
- [1]: 이 단계는 노드 1에만 적용됩니다.
- [2]: 단계가 Pacemaker 클러스터의 노드 2에만 적용됩니다.
<placeholders>를 SAP HANA 설치 값으로 바꿉니다.
[A] LVM(논리 볼륨 관리자)을 사용하여 디스크 레이아웃을 설정합니다.
데이터와 로그 파일을 저장하는 볼륨의 LVM을 사용하는 것이 좋습니다. 다음 예에서는 VM에 두 개의 볼륨을 만드는 데 사용되는 4개의 데이터 디스크가 연결되어 있다고 가정합니다.
이 명령을 실행하여 사용 가능한 모든 디스크를 나열합니다.
/dev/disk/azure/scsi1/lun*예제 출력:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3사용하려는 모든 디스크의 물리적 볼륨을 만듭니다.
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3데이터 파일에 대한 볼륨 그룹을 만듭니다. 로그 파일에 대해 한 볼륨 그룹, SAP HANA의 공유 디렉터리에 대해 한 볼륨 그룹을 사용합니다.
sudo vgcreate vg_hana_data_<HANA SID> /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_<HANA SID> /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_<HANA SID> /dev/disk/azure/scsi1/lun3논리 볼륨을 만듭니다.
-i스위치 없이lvcreate를 사용하는 경우 선형 볼륨이 만들어집니다. 더 나은 I/O 성능을 위해 스트라이프 볼륨을 만드는 것이 좋습니다. 스트라이프 크기를 SAP HANA VM 스토리지 구성에 설명된 값에 맞춥니다.-i인수는 기본 실제 볼륨의 수여야 하며-I인수는 스트라이프 크기입니다.예를 들어 두 개의 실제 볼륨이 데이터 볼륨에 사용되는 경우
-i스위치 인수는 2로 설정되고 데이터 볼륨의 스트라이프 크기는 256KiB입니다. 로그 볼륨에는 하나의 실제 볼륨이 사용되므로-i또는-I스위치는 로그 볼륨 명령에 명시적으로 사용되지 않습니다.Important
각 데이터, 로그 또는 공유 볼륨에 대해 하나 이상의 물리적 볼륨을 사용하는 경우
-i스위치를 사용하고 기본 물리적 볼륨 수로 설정합니다. 스트라이프 볼륨을 만들 때-I스위치를 사용하여 스트라이프 크기를 지정합니다.스트라이프 크기 및 디스크 수를 비롯한 권장되는 스토리지 구성은 SAP HANA VM 스토리지 구성을 참조하세요.
sudo lvcreate <-i number of physical volumes> <-I stripe size for the data volume> -l 100%FREE -n hana_data vg_hana_data_<HANA SID> sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_<HANA SID> sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_<HANA SID> sudo mkfs.xfs /dev/vg_hana_data_<HANA SID>/hana_data sudo mkfs.xfs /dev/vg_hana_log_<HANA SID>/hana_log sudo mkfs.xfs /dev/vg_hana_shared_<HANA SID>/hana_shared탑재 디렉터리를 만들고 모든 논리 볼륨의 UUID(범용 고유 식별자)를 복사합니다.
sudo mkdir -p /hana/data/<HANA SID> sudo mkdir -p /hana/log/<HANA SID> sudo mkdir -p /hana/shared/<HANA SID> # Write down the ID of /dev/vg_hana_data_<HANA SID>/hana_data, /dev/vg_hana_log_<HANA SID>/hana_log, and /dev/vg_hana_shared_<HANA SID>/hana_shared sudo blkid/etc/fstab 파일을 편집하여 세 개의 논리 볼륨에 대한
fstab항목을 만듭니다.sudo vi /etc/fstab/etc/fstab 파일에서 다음 줄을 삽입합니다.
/dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_data_<HANA SID>-hana_data> /hana/data/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_log_<HANA SID>-hana_log> /hana/log/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_shared_<HANA SID>-hana_shared> /hana/shared/<HANA SID> xfs defaults,nofail 0 2새 볼륨을 탑재합니다.
sudo mount -a
[A] 일반 디스크를 사용하여 디스크 레이아웃을 설정합니다.
데모 시스템을 위해 HANA 데이터와 로그 파일을 같은 디스크에 배치할 수 있습니다.
/dev/disk/azure/scsi1/lun0에 파티션을 만들고 XFS를 사용하여 포맷합니다.
sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun0' sudo mkfs.xfs /dev/disk/azure/scsi1/lun0-part1 # Write down the ID of /dev/disk/azure/scsi1/lun0-part1 sudo /sbin/blkid sudo vi /etc/fstab/etc/fstab 파일에 다음 줄을 삽입합니다.
/dev/disk/by-uuid/<UUID> /hana xfs defaults,nofail 0 2대상 디렉터리를 만들고 디스크를 탑재합니다.
sudo mkdir /hana sudo mount -a
[A] 모든 호스트의 호스트 이름 확인을 설정합니다.
DNS 서버를 사용하거나 모든 노드의 /etc/hosts 파일을 수정할 수 있습니다. 이 예에서는 /etc/hosts 파일을 사용하는 방법을 보여줍니다. 다음 명령에서 IP 주소와 호스트 이름을 바꿉니다.
/etc/hosts 파일을 편집합니다.
sudo vi /etc/hosts/etc/hosts 파일에서 다음 줄을 삽입합니다. 사용자 환경에 맞게 IP 주소와 호스트 이름을 변경합니다.
10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] SAP 설명서에 따라 SAP HANA를 설치합니다.
SAP HANA 2.0 시스템 복제 구성
이 섹션의 다음 단계에서는 다음과 같은 접두사를 사용합니다.
- [A]: 단계가 모든 노드에 적용됩니다.
- [1]: 이 단계는 노드 1에만 적용됩니다.
- [2]: 단계가 Pacemaker 클러스터의 노드 2에만 적용됩니다.
<placeholders>를 SAP HANA 설치 값으로 바꿉니다.
[1] 테넌트 데이터베이스를 만듭니다.
SAP HANA 2.0 또는 SAP HANA MDC를 사용하는 경우 SAP NetWeaver 시스템에 대한 테넌트 데이터베이스를 만듭니다.
다음 명령을 <HANA SID>adm으로 실행합니다.
hdbsql -u SYSTEM -p "<password>" -i <instance number> -d SYSTEMDB 'CREATE DATABASE <SAP SID> SYSTEM USER PASSWORD "<password>"'[1] 첫 번째 노드에서 시스템 복제를 구성합니다.
먼저 데이터베이스를 <HANA SID>adm으로 백업합니다.
hdbsql -d SYSTEMDB -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SYS>')" hdbsql -d <HANA SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for HANA SID>')" hdbsql -d <SAP SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SAP SID>')"그런 다음, 보조 사이트에 시스템 PKI(공개 키 인프라) 파일을 복사합니다.
scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/SSFS_<HANA SID>.DAT hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/ scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/SSFS_<HANA SID>.KEY hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/기본 사이트를 만듭니다.
hdbnsutil -sr_enable --name=<site 1>[2] 두 번째 노드에서 시스템 복제를 구성합니다.
두 번째 노드를 등록하여 시스템 복제를 시작합니다.
다음 명령을 <HANA SID>adm으로 실행합니다.
sapcontrol -nr <instance number> -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2>
HANA 리소스 에이전트 구현
SUSE는 Pacemaker 리소스 에이전트가 SAP HANA를 관리하기 위한 두 가지 소프트웨어 패키지를 제공합니다. 소프트웨어 패키지 SAPHanaSR 및 SAPHanaSR-angi는 약간 다른 구문과 매개 변수를 사용하며 호환되지 않습니다. SAPHanaSR과 SAPHanaSR-angi 간의 세부 정보 및 차이점은 SUSE 릴리스 정보 및 설명서를 참조하세요. 이 문서에서는 각 섹션의 별도 탭에 있는 두 패키지에 대해 설명합니다.
Warning
이미 구성된 클러스터에서 SAPHanaSR-angi로 SAPHanaSR 패키지를 대체하지 마세요. SAPHanaSR에서 SAPHanaSR-angi로 업그레이드하려면 특정 절차가 필요합니다.
- [A] SAP HANA 고가용성 패키지를 설치합니다.
다음 명령을 실행하여 고가용성 패키지를 설치합니다.
sudo zypper install SAPHanaSR
SAP HANA HA/DR 공급자 설정
SAP HANA HA/DR 공급자는 클러스터와의 통합을 최적화하고 클러스터 장애 조치(failover)가 필요할 때 검색을 개선합니다. 기본 후크 스크립트는 SAPHanaSR(SAPHanaSR 패키지용) /susHanaSR(SAPHanaSR-angi용)입니다. SAPHanaSR/susHanaSR Python 후크를 구성하는 것이 좋습니다. HANA 2.0 SPS 05 이상의 경우 SAPHanaSR/susHanaSR 및 susChkSrv 후크를 모두 구현하는 것이 좋습니다.
susChkSrv 후크는 주 SAPHanaSR/susHanaSR HA 공급자의 기능을 확장합니다. HANA 프로세스 hdbindexserver가 충돌할 때 작동합니다. 단일 프로세스가 충돌하는 경우 HANA는 일반적으로 프로세스를 다시 시작하려고 시도합니다. 인덱스 서버 프로세스를 다시 시작하는 데 시간이 오래 걸릴 수 있으며 이 시간 동안 HANA 데이터베이스가 응답하지 않습니다.
susChkSrv를 구현하면 즉시 구성 가능한 작업이 실행됩니다. 이 작업은 hdbindexserver 프로세스가 동일한 노드에서 다시 시작될 때까지 기다리지 않고 구성된 시간 제한 기간에 장애 조치(failover)를 트리거합니다.
- [A] 두 노드에서 HANA를 중지합니다.
sap-sid>adm으로 <다음 코드를 실행합니다.
sapcontrol -nr <instance number> -function StopSystem
[A] HANA 시스템 복제 후크를 설치합니다. 후크는 두 HANA 데이터베이스 노드에 모두 설치해야 합니다.
팁
SAPHanaSR Python 후크는 HANA 2.0에 대해서만 구현할 수 있습니다. SAPHanaSR 패키지는 버전 0.153 이상이어야 합니다.
SAPHanaSR-angi Python 후크는 HANA 2.0 SPS 05 이상에 대해서만 구현할 수 있습니다.
susChkSrv Python 후크에는 SAP HANA 2.0 SPS 05가 필요하며 SAPHanaSR 버전 0.161.1_BF 이상을 설치해야 합니다.[A] 각 클러스터 노드에서 global.ini 조정합니다.
susChkSrv 후크에 대한 요구 사항이 충족되지 않는 경우 다음 매개 변수에서 전체
[ha_dr_provider_suschksrv]블록을 제거합니다.action_on_lost매개 변수를 사용하여susChkSrv의 동작을 조정할 수 있습니다. 유효한 값은 [ignore|stop|kill|fence]입니다.[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /usr/share/SAPHanaSR execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR execution_order = 3 action_on_lost = fence [trace] ha_dr_saphanasr = info매개 변수 경로를 기본
/usr/share/SAPHanaSR위치로 가리키면 Python 후크 코드는 OS 업데이트 또는 패키지 업데이트를 통해 자동으로 업데이트됩니다. HANA는 다음에 다시 시작될 때 후크 코드 업데이트를 사용합니다. 다음과 같은/hana/shared/myHooks선택적 고유 경로를 사용하면 사용하는 후크 버전에서 OS 업데이트를 분리할 수 있습니다.[A] 클러스터에는 sap-sid>adm에 대한 각 클러스터 노드에 대한 <sudoers 구성이 필요합니다. 이 예제에서는 새 파일을 만들어 수행합니다.
다음 명령을 루트로 실행합니다. sid>를 소문자 SAP 시스템 ID로, <SID>를 대문자 SAP 시스템 ID로, <siteA/B>를 선택한 HANA 사이트 이름으로 바꿉<니다.
cat << EOF > /etc/sudoers.d/20-saphana # Needed for SAPHanaSR and susChkSrv Python hooks Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteA> -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteA> -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteB> -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteB> -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias HELPER_TAKEOVER = /usr/sbin/SAPHanaSR-hookHelper --sid=<SID> --case=checkTakeover Cmnd_Alias HELPER_FENCE = /usr/sbin/SAPHanaSR-hookHelper --sid=<SID> --case=fenceMe <sid>adm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB, HELPER_TAKEOVER, HELPER_FENCE EOF
SAP HANA 시스템 복제 후크 구현에 대한 자세한 내용은 HANA HA/DR 공급자 설정을 참조하세요.
[A] 두 노드에서 SAP HANA를 시작합니다. sap-sid>adm으로 <다음 명령을 실행합니다.
sapcontrol -nr <instance number> -function StartSystem[1] 후크 설치를 확인합니다. 활성 HANA 시스템 복제 사이트에서 sap-sid>adm으로 <다음 명령을 실행합니다.
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_* # Example output # 2021-04-08 22:18:15.877583 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:18:46.531564 ha_dr_SAPHanaSR SFAIL # 2021-04-08 22:21:26.816573 ha_dr_SAPHanaSR SOK
- [1] susChkSrv 후크 설치를 확인합니다.
HANA VM에서 sap-sid>adm으로 <다음 명령을 실행합니다.
cdtrace egrep '(LOST:|STOP:|START:|DOWN:|init|load|fail)' nameserver_suschksrv.trc # Example output # 2022-11-03 18:06:21.116728 susChkSrv.init() version 0.7.7, parameter info: action_on_lost=fence stop_timeout=20 kill_signal=9 # 2022-11-03 18:06:27.613588 START: indexserver event looks like graceful tenant start # 2022-11-03 18:07:56.143766 START: indexserver event looks like graceful tenant start (indexserver started)
SAP HANA 클러스터 리소스 만들기
- [1] 먼저 HANA 토폴로지 리소스를 만듭니다.
Pacemaker 클러스터 노드 중 하나에서 다음 명령을 실행합니다.
sudo crm configure property maintenance-mode=true
# Replace <placeholders> with your instance number and HANA system ID
sudo crm configure primitive rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> ocf:suse:SAPHanaTopology \
operations \$id="rsc_sap2_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10" timeout="600" \
op start interval="0" timeout="600" \
op stop interval="0" timeout="300" \
params SID="<HANA SID>" InstanceNumber="<instance number>"
sudo crm configure clone cln_SAPHanaTopology_<HANA SID>_HDB<instance number> rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> \
meta clone-node-max="1" target-role="Started" interleave="true"
- [1] 다음으로 HANA 리소스를 만듭니다.
참고 항목
이 문서에는 Microsoft가 더 이상 사용하지 않는 용어에 대한 참조가 포함되어 있습니다. 해당 용어가 소프트웨어에서 제거되면 이 문서에서도 제거할 것입니다.
# Replace <placeholders> with your instance number and HANA system ID.
sudo crm configure primitive rsc_SAPHana_<HANA SID>_HDB<instance number> ocf:suse:SAPHana \
operations \$id="rsc_sap_<HANA SID>_HDB<instance number>-operations" \
op start interval="0" timeout="3600" \
op stop interval="0" timeout="3600" \
op promote interval="0" timeout="3600" \
op monitor interval="60" role="Master" timeout="700" \
op monitor interval="61" role="Slave" timeout="700" \
params SID="<HANA SID>" InstanceNumber="<instance number>" PREFER_SITE_TAKEOVER="true" \
DUPLICATE_PRIMARY_TIMEOUT="7200" AUTOMATED_REGISTER="false"
# Run the following command if the cluster nodes are running on SLES 12 SP05.
sudo crm configure ms msl_SAPHana_<HANA SID>_HDB<instance number> rsc_SAPHana_<HANA SID>_HDB<instance number> \
meta notify="true" clone-max="2" clone-node-max="1" \
target-role="Started" interleave="true"
# Run the following command if the cluster nodes are running on SLES 15 SP03 or later.
sudo crm configure clone msl_SAPHana_<HANA SID>_HDB<instance number> rsc_SAPHana_<HANA SID>_HDB<instance number> \
meta notify="true" clone-max="2" clone-node-max="1" \
target-role="Started" interleave="true" promotable="true"
sudo crm resource meta msl_SAPHana_<HANA SID>_HDB<instance number> set priority 100
- [1] 가상 IP, 기본값 및 제약 조건에 대한 클러스터 리소스를 계속 사용합니다.
# Replace <placeholders> with your instance number, HANA system ID, and the front-end IP address of the Azure load balancer.
sudo crm configure primitive rsc_ip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_ip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<front-end IP address>"
sudo crm configure primitive rsc_nc_<HANA SID>_HDB<instance number> azure-lb port=625<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
sudo crm configure group g_ip_<HANA SID>_HDB<instance number> rsc_ip_<HANA SID>_HDB<instance number> rsc_nc_<HANA SID>_HDB<instance number>
sudo crm configure colocation col_saphana_ip_<HANA SID>_HDB<instance number> 4000: g_ip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Master
sudo crm configure order ord_SAPHana_<HANA SID>_HDB<instance number> Optional: cln_SAPHanaTopology_<HANA SID>_HDB<instance number> \
msl_SAPHana_<HANA SID>_HDB<instance number>
# Clean up the HANA resources. The HANA resources might have failed because of a known issue.
sudo crm resource cleanup rsc_SAPHana_<HANA SID>_HDB<instance number>
sudo crm configure property priority-fencing-delay=30
sudo crm configure property maintenance-mode=false
sudo crm configure rsc_defaults resource-stickiness=1000
sudo crm configure rsc_defaults migration-threshold=5000
Important
실패한 주 인스턴스가 자동으로 보조 인스턴스로 등록되지 않도록 철저한 장애 조치(failover) 테스트를 완료하는 동안에만 AUTOMATED_REGISTER를 false로 설정하는 것이 좋습니다. 장애 조치(failover) 테스트가 성공적으로 완료되면 인수 후 시스템 복제가 자동으로 다시 시작되도록 AUTOMATED_REGISTER를 true로 설정합니다.
클러스터 상태가 OK이며 모든 리소스가 시작되었는지 확인합니다. 리소스가 실행되는 노드는 중요하지 않습니다.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
Pacemaker 클러스터에서 HANA 활성/읽기 사용 시스템 복제 구성
SAP HANA 2.0 SPS 01 이상 버전에서 SAP는 SAP HANA 시스템 복제를 위한 활성/읽기 사용 설정을 허용합니다. 이 시나리오에서는 SAP HANA 시스템 복제의 보조 시스템을 읽기 집약적인 워크로드에 적극적으로 사용할 수 있습니다.
클러스터에서 이 설정을 지원하려면 클라이언트가 보조 읽기 사용 SAP HANA 데이터베이스에 액세스할 수 있도록 두 번째 가상 IP 주소가 필요합니다. 인수 후에도 보조 복제 사이트에 액세스할 수 있도록 클러스터에서 가상 IP 주소를 SAPHana 리소스의 보조로 이동해야 합니다.
해당 섹션에서는 두 번째 가상 IP를 사용하는 SUSE 고가용성 클러스터에서 HANA 활성/읽기 사용 시스템 복제를 관리하는 데 필요한 추가 단계에 대해 설명합니다.
계속하기 전에 이전 섹션에서 설명한 대로 SAP HANA 데이터베이스를 관리하는 SUSE 고가용성 클러스터를 완전히 구성했는지 확인합니다.
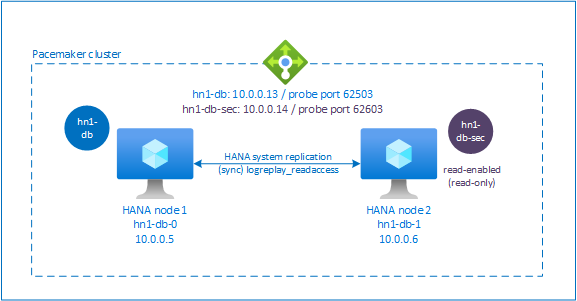
활성/읽기 사용 시스템 복제에 대한 부하 분산 장치 설정
두 번째 가상 IP를 프로비전하는 추가 단계를 진행하려면 Azure Portal을 통해 수동으로 Linux VM 배포에 설명된 대로 Azure Load Balancer를 구성했는지 확인합니다.
표준 부하 분산 장치의 경우 이전에 만든 것과 동일한 부하 분산 장치에서 이러한 추가 단계를 완료합니다.
- 두 번째 프런트 엔드 IP 풀 만들기:
- 부하 분산 장치를 열고, 프런트 엔드 IP 풀을 선택하고, 추가를 선택합니다.
- 두 번째 프런트 엔드 IP 풀의 이름을 입력합니다(예: hana-secondaryIP).
- 할당을 정적으로 설정하고 IP 주소(예: 10.0.0.14)를 입력합니다.
- 확인을 선택합니다.
- 새 프런트 엔드 IP 풀을 만든 후, 프런트 엔드 IP 주소를 적어 둡니다.
- 상태 프로브 만들기:
- 부하 분산 장치에서 상태 프로브를 선택하고 추가를 선택합니다.
- 새 상태 프로브의 이름(예: hana-secondaryhp)을 입력합니다.
- 프로토콜 및 포트 626<인스턴스 번호>로 TCP를 선택합니다. 5로 설정된 간격 값, 2로 설정된 비정상 임계값 값을 유지합니다.
- 확인을 선택합니다.
- 부하 분산 규칙 만들기:
- 부하 분산 장치에서 부하 분산 규칙을 선택하고 추가를 선택합니다.
- 새 부하 분산 장치 규칙의 이름(예: hana-secondarylb)을 입력합니다.
- 이전에 만든 프런트 엔드 IP 주소, 백 엔드 풀, 상태 프로브를 선택합니다(예: hana-secondaryIP, hana-backend 및 hana-secondaryhp).
- HA 포트를 선택합니다.
- 유휴 상태 시간 제한을 30분으로 늘립니다.
- 부동 IP를 사용하도록 설정해야 합니다.
- 확인을 선택합니다.
HANA 활성/읽기 사용 시스템 복제 설정
HANA 시스템 복제를 구성하는 단계는 SAP HANA 2.0 시스템 복제 구성에 설명되어 있습니다. 읽기 지원 보조 시나리오를 배포하는 경우 두 번째 노드에서 시스템 복제를 설정할 때 <HANA SID>adm으로 다음 명령을 실행합니다.
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> --operationMode=logreplay_readaccess
보조 가상 IP 주소 리소스 추가
다음 명령을 사용하여 두 번째 가상 IP 및 적절한 공동 배치 제약 조건을 설정할 수 있습니다.
crm configure property maintenance-mode=true
crm configure primitive rsc_secip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
operations \$id="rsc_secip_<HANA SID>_HDB<instance number>-operations" \
op monitor interval="10s" timeout="20s" \
params ip="<secondary IP address>"
crm configure primitive rsc_secnc_<HANA SID>_HDB<instance number> azure-lb port=626<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
crm configure group g_secip_<HANA SID>_HDB<instance number> rsc_secip_<HANA SID>_HDB<instance number> rsc_secnc_<HANA SID>_HDB<instance number>
crm configure colocation col_saphana_secip_<HANA SID>_HDB<instance number> 4000: g_secip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHana_<HANA SID>_HDB<instance number>:Slave
crm configure property maintenance-mode=false
클러스터 상태가 OK이며 모든 리소스가 시작되었는지 확인합니다. 두 번째 가상 IP는 보조 사이트에서 SAPHana 보조 리소스와 함께 실행됩니다.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# Resource Group: g_secip_HN1_HDB03:
# rsc_secip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
# rsc_secnc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
다음 섹션에서는 실행할 일반적인 장애 조치(failover) 테스트 세트를 설명합니다.
읽기 사용 보조 데이터베이스로 구성된 HANA 클러스터를 테스트할 때 고려 사항:
SAPHana_<HANA SID>_HDB<instance number>클러스터 리소스를hn1-db-1로 마이그레이션할 때 두 번째 가상 IP는hn1-db-0으로 이동합니다.AUTOMATED_REGISTER="false"를 구성했고 HANA 시스템 복제가 자동으로 등록되지 않은 경우 서버를 사용할 수 있고 클러스터 서비스가 온라인 상태이기 때문에 두 번째 가상 IP가hn1-db-0에서 실행됩니다.서버 충돌을 테스트할 때 두 번째 가상 IP 리소스(
rsc_secip_<HANA SID>_HDB<instance number>)와 Azure Load Balancer 포트 리소스(rsc_secnc_<HANA SID>_HDB<instance number>)는 주 가상 IP 리소스와 함께 주 서버에서 실행됩니다. 보조 서버가 다운 상태인 동안 읽기 사용 HANA 데이터베이스에 연결된 애플리케이션은 주 HANA 데이터베이스에 연결됩니다. 보조 서버를 사용할 수 없는 동안 읽기 사용 HANA 데이터베이스에 연결된 애플리케이션에 액세스할 수 없도록 하려는 것이 아니므로 이 동작은 예상됩니다.보조 서버를 사용할 수 있고 클러스터 서비스가 온라인 상태이면 HANA 시스템 복제가 보조 서버로 등록되지 않은 경우에도 두 번째 가상 IP 및 포트 리소스가 보조 서버로 자동 이동합니다. 해당 서버에서 클러스터 서비스를 시작하기 전에 보조 HANA 데이터베이스를 읽기 가능으로 등록했는지 확인하세요. 매개 변수를
AUTOMATED_REGISTER="true"로 설정하여 보조 복제본을 자동으로 등록하도록 HANA 인스턴스 클러스터 리소스를 구성할 수 있습니다.장애 조치(failover) 및 대체 중에 두 번째 가상 IP를 사용하여 HANA 데이터베이스에 연결하는 애플리케이션의 기존 연결이 중단될 수 있습니다.
클러스터 설정 테스트
이 섹션에서는 설정을 테스트하는 방법을 설명합니다. 모든 테스트에서는 루트로 로그인하고 SAP HANA 마스터가 hn1-db-0 VM에서 실행되고 있다고 가정합니다.
마이그레이션 테스트
테스트를 시작하기 전에 Pacemaker에 실패한 작업이 없으며(crm_mon -r 실행), 예기치 않은 위치 제약 조건이 없고(예: 마이그레이션 테스트의 결과), 예를 들어 SAPHanaSR-showAttr을 실행하여 해당 HANA가 동기화 상태에 있는지 확인합니다.
hn1-db-0:~ # SAPHanaSR-showAttr
Sites srHook
----------------
SITE2 SOK
Global cib-time
--------------------------------
global Mon Aug 13 11:26:04 2018
Hosts clone_state lpa_hn1_lpt node_state op_mode remoteHost roles score site srmode sync_state version vhost
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
hn1-db-0 PROMOTED 1534159564 online logreplay nws-hana-vm-1 4:P:master1:master:worker:master 150 SITE1 sync PRIM 2.00.030.00.1522209842 nws-hana-vm-0
hn1-db-1 DEMOTED 30 online logreplay nws-hana-vm-0 4:S:master1:master:worker:master 100 SITE2 sync SOK 2.00.030.00.1522209842 nws-hana-vm-1
다음 명령을 실행하여 SAP HANA 마스터 노드를 마이그레이션할 수 있습니다.
crm resource move msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1 force
클러스터는 SAP HANA 마스터 노드와 가상 IP 주소가 포함된 그룹을 hn1-db-1로 마이그레이션합니다.
마이그레이션이 완료되면 crm_mon -r 출력은 다음 예제와 같습니다.
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Failed Actions:
* rsc_SAPHana_HN1_HDB03_start_0 on hn1-db-0 'not running' (7): call=84, status=complete, exitreason='none',
last-rc-change='Mon Aug 13 11:31:37 2018', queued=0ms, exec=2095ms
이 AUTOMATED_REGISTER="false"경우 클러스터는 실패한 HANA 데이터베이스를 다시 시작하거나 새 주 데이터베이스에 hn1-db-0등록하지 않습니다. 이 경우 다음 명령을 실행하여 HANA 인스턴스를 보조로 구성합니다.
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> sapcontrol -nr <instance number> -function StopWait 600 10
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
마이그레이션을 통해 다시 삭제해야 하는 위치 제약조건을 만듭니다.
# Switch back to root and clean up the failed state
exit
hn1-db-0:~ # crm resource clear msl_SAPHana_<HANA SID>_HDB<instance number>
보조 노드 리소스의 상태도 정리해야 합니다.
hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
crm_mon -r을 사용하여 HANA 리소스의 상태를 모니터링합니다. hn1-db-0에서 HANA가 시작되면 출력은 다음 예제와 같습니다.
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
네트워크 통신 차단
테스트 시작 전 리소스 상태:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
방화벽 규칙을 실행하여 노드 중 하나에서 통신을 차단합니다.
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
클러스터 노드가 서로 통신할 수 없는 경우 분할 브레인 시나리오의 위험이 있습니다. 이러한 상황에서 클러스터 노드는 동시에 서로 울타리를 시도하여 펜스 경합을 초래합니다.
펜싱 디바이스를 구성할 때는 pcmk_delay_max 속성을 구성하는 것이 좋습니다. 따라서 split-brain 시나리오의 경우 클러스터는 각 노드의 펜싱 작업에 pcmk_delay_max 값까지 임의 지연을 도입합니다. 가장 짧은 지연이 있는 노드가 펜싱에 대해 선택됩니다.
또한 HANA 마스터를 실행하는 노드가 우선 순위를 사용하고 분할 브레인 시나리오에서 펜스 경합에서 승리하도록 하려면 클러스터 구성에서 priority-fencing-delay 속성을 설정하는 것이 좋습니다. priority-fencing-delay 속성을 사용하도록 설정하면 클러스터는 HANA 마스터 리소스를 호스트하는 노드에서 특히 펜싱 작업에 추가 지연을 발생시켜 노드가 펜스 경합에서 이길 수 있도록 할 수 있습니다.
아래 명령을 실행하여 방화벽 규칙을 삭제합니다.
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
SBD 펜싱 테스트
인퀴지터 프로세스를 종료하여 SBD의 설정을 테스트할 수 있습니다.
hn1-db-0:~ # ps aux | grep sbd
root 1912 0.0 0.0 85420 11740 ? SL 12:25 0:00 sbd: inquisitor
root 1929 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014056f268462316e4681b704a9f73 - slot: 0 - uuid: 7b862dba-e7f7-4800-92ed-f76a4e3978c8
root 1930 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014059bc9ea4e4bac4b18808299aaf - slot: 0 - uuid: 5813ee04-b75c-482e-805e-3b1e22ba16cd
root 1931 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-36001405b8dddd44eb3647908def6621c - slot: 0 - uuid: 986ed8f8-947d-4396-8aec-b933b75e904c
root 1932 0.0 0.0 90524 16656 ? SL 12:25 0:00 sbd: watcher: Pacemaker
root 1933 0.0 0.0 102708 28260 ? SL 12:25 0:00 sbd: watcher: Cluster
root 13877 0.0 0.0 9292 1572 pts/0 S+ 12:27 0:00 grep sbd
hn1-db-0:~ # kill -9 1912
<HANA SID>-db-<database 1> 클러스터 노드가 다시 부팅됩니다. Pacemaker 서비스가 다시 시작되지 않을 수 있습니다. 다시 시작해야 합니다.
수동 장애 조치(failover) 테스트
hn1-db-0 노드에서 Pacemaker 서비스를 중지하여 수동 장애 조치(failover)를 테스트할 수 있습니다.
service pacemaker stop
장애 조치 후에 서비스를 다시 시작할 수 있습니다. AUTOMATED_REGISTER="false"로 설정하면 hn1-db-0 노드에서 SAP HANA 리소스를 보조로 시작하는 데 실패합니다.
이 경우 다음 명령을 실행하여 HANA 인스턴스를 보조로 구성합니다.
service pacemaker start
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
# Switch back to root and clean up the failed state
exit
crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
SUSE 테스트
Important
선택하는 OS가 사용하려는 특정 VM 유형에서 SAP HANA용으로 인증된 SAP인지 반드시 확인하세요. SAP HANA 인증 IaaS 플랫폼에서 SAP HANA 인증 VM 유형 및 해당 OS 릴리스를 조회할 수 있습니다. 해당 VM 유형에 대한 SAP HANA 지원 OS 릴리스의 전체 목록을 가져오는 데 사용할 VM 유형의 세부 정보를 확인해야 합니다.
시나리오에 따라 SAP HANA SR 성능 최적화 시나리오 가이드 또는 SAP HANA SR 비용 최적화 시나리오 가이드에 나열된 모든 테스트 사례를 실행합니다. 가이드는 SAP용 SLES 모범 사례에서 찾을 수 있습니다.
다음 테스트는 SAP HANA SR 성능 최적화 시나리오 SAP 애플리케이션 12 SP1용 SUSE Linux Enterprise Server 가이드의 테스트 설명을 복사한 것입니다. 최신 버전의 경우 자체 가이드를 읽습니다. 테스트를 시작하기 전에 항상 HANA가 동기화되어 있는지 확인하고, Pacemaker 구성이 올바른지 확인합니다.
다음 테스트 설명에서는 PREFER_SITE_TAKEOVER="true" 및 AUTOMATED_REGISTER="false"라고 가정합니다.
참고 항목
다음 테스트는 순서대로 실행되도록 설계되었습니다. 각 테스트는 이전 테스트의 종료 상태에 따라 달라집니다.
테스트 1: 노드 1에서 주 데이터베이스 중지.
테스트 시작 전 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0hn1-db-0노드에서 <hana sid>adm으로 다음 명령을 실행합니다.hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB stopPacemaker는 중지된 HANA 인스턴스 및 다른 노드로의 장애 조치(failover)를 감지합니다. 장애 조치(failover)가 완료되면 Pacemaker는 노드를 HANA 보조로 자동으로 등록하지 않으므로
hn1-db-0노드에서 HANA 인스턴스가 중지됩니다.다음 명령을 실행하여
hn1-db-0노드를 보조로 등록하고 실패한 리소스를 정리합니다.hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0테스트 후 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1테스트 2: 노드 2에서 주 데이터베이스 중지.
테스트 시작 전 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1hn1-db-1노드에서 <hana sid>adm으로 다음 명령을 실행합니다.hn1adm@hn1-db-1:/usr/sap/HN1/HDB01> HDB stopPacemaker는 중지된 HANA 인스턴스 및 다른 노드로의 장애 조치(failover)를 감지합니다. 장애 조치(failover)가 완료되면 Pacemaker는 노드를 HANA 보조로 자동으로 등록하지 않으므로
hn1-db-1노드에서 HANA 인스턴스가 중지됩니다.다음 명령을 실행하여
hn1-db-1노드를 보조로 등록하고 실패한 리소스를 정리합니다.hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1테스트 후 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0테스트 3: 노드 1에서 주 데이터베이스 크래시.
테스트 시작 전 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0hn1-db-0노드에서 <hana sid>adm으로 다음 명령을 실행합니다.hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker는 종료된 HANA 인스턴스 및 다른 노드로의 장애 조치(failover)를 감지합니다. 장애 조치(failover)가 완료되면 Pacemaker는 노드를 HANA 보조로 자동으로 등록하지 않으므로
hn1-db-0노드에서 HANA 인스턴스가 중지됩니다.다음 명령을 실행하여
hn1-db-0노드를 보조로 등록하고 실패한 리소스를 정리합니다.hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0테스트 후 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1테스트 4: 노드 2에서 주 데이터베이스 크래시.
테스트 시작 전 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1hn1-db-1노드에서 <hana sid>adm으로 다음 명령을 실행합니다.hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker는 종료된 HANA 인스턴스 및 다른 노드로의 장애 조치(failover)를 감지합니다. 장애 조치(failover)가 완료되면 Pacemaker는 노드를 HANA 보조로 자동으로 등록하지 않으므로
hn1-db-1노드에서 HANA 인스턴스가 중지됩니다.다음 명령을 실행하여
hn1-db-1노드를 보조로 등록하고 실패한 리소스를 정리합니다.hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1테스트 후 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0테스트 5: 주 사이트 노드 크래시(노드 1).
테스트 시작 전 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0hn1-db-0노드에서 루트로 다음 명령을 실행합니다.hn1-db-0:~ # echo 'b' > /proc/sysrq-triggerPacemaker는 중단된 클러스터 노드를 감지하고 노드를 펜스합니다. 노드가 펜스되면 Pacemaker는 HANA 인스턴스의 인수를 트리거합니다. 펜스된 노드가 다시 부팅되는 경우 Pacemaker는 자동으로 시작되지 않습니다.
다음 명령을 실행하여 Pacemaker를 시작하고,
hn1-db-0노드에 대한 SBD 메시지를 정리하고,hn1-db-0노드를 보조로 등록하고, 실패한 리소스를 정리합니다.# run as root # list the SBD device(s) hn1-db-0:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-0:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-0 clear hn1-db-0:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0테스트 후 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1테스트 6: 보조 사이트 노드 크래시(노드 2).
테스트 시작 전 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1hn1-db-1노드에서 루트로 다음 명령을 실행합니다.hn1-db-1:~ # echo 'b' > /proc/sysrq-triggerPacemaker는 중단된 클러스터 노드를 감지하고 노드를 펜스합니다. 노드가 펜스되면 Pacemaker는 HANA 인스턴스의 인수를 트리거합니다. 펜스된 노드가 다시 부팅되는 경우 Pacemaker는 자동으로 시작되지 않습니다.
다음 명령을 실행하여 Pacemaker를 시작하고,
hn1-db-1노드에 대한 SBD 메시지를 정리하고,hn1-db-1노드를 보조로 등록하고, 실패한 리소스를 정리합니다.# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1테스트 후 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0 </code></pre>테스트 7: 노드 2에서 보조 데이터베이스 중지
테스트 시작 전 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0hn1-db-1노드에서 <hana sid>adm으로 다음 명령을 실행합니다.hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB stopPacemaker는 중지된 HANA 인스턴스를 검색하고
hn1-db-1노드에서 리소스를 실패로 표시합니다. Pacemaker는 HANA 인스턴스를 자동으로 다시 시작합니다.다음 명령을 실행하여 실패한 상태를 정리합니다.
# run as root hn1-db-1>:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1테스트 후 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0테스트 8: 노드 2에서 보조 데이터베이스 크래시
테스트 시작 전 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0hn1-db-1노드에서 <hana sid>adm으로 다음 명령을 실행합니다.hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Pacemaker는 종료된 HANA 인스턴스를 감지하고
hn1-db-1노드에서 리소스를 실패로 표시합니다. 다음 명령을 실행하여 실패한 상태를 정리합니다. Pacemaker는 HANA 인스턴스를 자동으로 다시 시작합니다.# run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> HN1-db-1테스트 후 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0테스트 9: 보조 HANA 데이터베이스를 실행하는 보조 사이트 노드(노드 2)를 크래시합니다.
테스트 시작 전 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0hn1-db-1노드에서 루트로 다음 명령을 실행합니다.hn1-db-1:~ # echo b > /proc/sysrq-triggerPacemaker는 중단된 클러스터 노드를 감지하고 노드를 펜스합니다. 펜스된 노드가 다시 부팅되는 경우 Pacemaker는 자동으로 시작되지 않습니다.
다음 명령을 실행하여 Pacemaker를 시작하고,
hn1-db-1노드에 대한 SBD 메시지를 정리하고, 실패한 리소스를 정리합니다.# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1테스트 후 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0테스트 10: 주 데이터베이스 indexserver 크래시
이 테스트는 HANA 리소스 에이전트 구현에 설명된 대로 susChkSrv 후크를 설정한 경우에만 관련이 있습니다.
테스트 시작 전 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0hn1-db-0노드에서 루트로 다음 명령을 실행합니다.hn1-db-0:~ # killall -9 hdbindexserver인덱스 서버가 종료되면 susChkSrv 후크는 이벤트를 감지하고 'hn1-db-0' 노드를 펜스하고 인수 프로세스를 시작하는 작업을 트리거합니다.
다음 명령을 실행하여
hn1-db-0노드를 보조로 등록하고 실패한 리소스를 정리합니다.# run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0테스트 후 리소스 상태:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1보조 노드의 인덱스 서버가 충돌하도록 하여 비교 가능한 테스트 사례를 실행할 수 있습니다. 인덱스 서버 크래시가 발생하는 경우 susChkSrv 후크는 발생을 인식하고 보조 노드를 펜스하는 작업을 시작합니다.