Azure AI Search는 Azure Blob Storage에 저장된 PDF 문서에서 텍스트와 이미지를 추출하고 인덱싱할 수 있습니다. 이 자습서에서는 문서 구조에 따라 데이터를 청크 하고 이미지 구두 화를 사용하여 이미지를 설명하는 다중 모달 인덱싱 파이프라인을 빌드하는 방법을 보여 줍니다. 잘린 이미지는 지식 저장소에 저장되고 시각적 콘텐츠는 자연어로 설명되고 검색 가능한 인덱스 텍스트와 함께 수집됩니다. 청크는 문서 구조를 인식하는 Foundry Tools에서의 Azure 문서 인텔리전스 레이아웃 모델을 기반으로 합니다.
이미지 언어화를 가져오기 위해 추출된 각 이미지는 간결한 텍스트 설명을 생성하기 위해 채팅 완성 모델을 호출하는 GenAI 프롬프트 기술(미리 보기) 에 전달됩니다. 이러한 설명은 원래 문서 텍스트와 함께 Azure OpenAI의 text-embedding-3-large 모델을 사용하여 벡터 표현에 포함됩니다. 결과는 텍스트 및 구두 이미지의 두 형식에서 검색 가능한 콘텐츠를 포함하는 단일 인덱스입니다.
이 자습서에서는 다음을 사용합니다.
차트, 인포그래픽 및 스캔한 페이지와 같은 풍부한 시각적 콘텐츠를 기존 텍스트와 결합하는 36페이지 분량의 PDF 문서입니다.
기술을 통한 AI 보강을 포함하는 인덱싱 파이프라인을 만드는 인덱서 및 기술 세트입니다.
문서 레이아웃 기술은 페이지 번호나 경계 영역과 같은 다양한 문서에서
locationMetadata와 함께 텍스트 및 정규화된 이미지를 추출하는 기능을 제공합니다.채팅 완성 모델을 호출하여 시각적 콘텐츠에 대한 설명을 만드는 GenAI 프롬프트 기술(미리 보기) 입니다.
추출된 텍스트 및 이미지 서술을 저장하도록 구성된 검색 인덱스입니다. 일부 콘텐츠는 벡터 기반 유사성 검색을 위해 벡터화됩니다.
Prerequisites
Microsoft Foundry 리소스. 이 리소스는 이 자습서에서 사용되는 Azure Document Intelligence 레이아웃 모델에 대한 액세스를 제공합니다. 이 리소스에 대한 기술 세트 액세스를 위해 Foundry 리소스를 사용해야 합니다.
Azure AI 검색. 역할 기반 액세스 제어 및 관리 ID에 대한 검색 서비스를 구성합니다. 서비스는 기본 계층 이상에 있어야 합니다. 이 자습서는 무료 계층에서 지원되지 않습니다.
샘플 데이터를 저장하고 지식 저장소를 만드는 데 사용되는 Azure Storage입니다.
배포를 사용하는 Azure OpenAI
Foundry 또는 다른 원본에서 호스트되는 채팅 완료 모델입니다. 모델은 이미지 콘텐츠를 구두로 사용하는 데 사용됩니다. GenAI 프롬프트 기술 정의에서 호스트된 모델에 URI를 제공합니다. 채팅 완료 모델을 사용할 수 있습니다.
Foundry에 배포된 텍스트 포함 모델입니다. 이 모델은 원본 문서에서 텍스트 콘텐츠 끌어오기 및 채팅 완성 모델에서 생성된 이미지 설명을 벡터화하는 데 사용됩니다. 통합 벡터화의 경우 포함 모델은 Foundry에 있어야 하며 text-embedding-ada-002, text-embedding-3-large 또는 text-embedding-3-small이어야 합니다. 외부 포함 모델을 사용하려면 Azure OpenAI 포함 기술 대신 사용자 지정 기술을 사용합니다.
Limitations
- 문서 레이아웃 기술에는 지역 가용성이 제한됩니다. 지원되는 지역 목록은 문서 레이아웃 기술> 지원 지역을 참조하세요.
데이터 준비
다음 지침은 샘플 데이터를 제공하고 지식 저장소를 호스트하는 Azure Storage에 적용됩니다. 검색 서비스 ID는 샘플 데이터를 검색하기 위해 Azure Storage에 대한 읽기 액세스 권한이 필요하며 지식 저장소를 만들려면 쓰기 액세스 권한이 필요합니다. 검색 서비스는 환경 변수에 제공한 이름을 사용하여 기술 세트 처리 중에 잘린 이미지에 대한 컨테이너를 만듭니다.
다음 샘플 PDF 다운로드: sustainable-ai-pdf
Azure Storage에서 sustainable-ai-pdf라는 새 컨테이너를 만듭니다.
샘플 데이터 파일을 업로드합니다.
역할 할당을 만들고 연결 문자열에서 관리 ID를 지정합니다.
데이터 검색을 위해 인덱서에 Storage Blob 데이터 리더 역할을 할당합니다. Storage Blob 데이터 기여자 및 스토리지 테이블 데이터 기여자를 할당하여 지식 저장소를 만들고 로드합니다. 검색 서비스 역할 할당에 시스템 할당 관리 ID 또는 사용자 할당 관리 ID를 사용할 수 있습니다.
시스템 할당 관리 ID를 사용하여 만든 연결의 경우 계정 키 또는 암호 없이 ResourceId가 포함된 연결 문자열을 가져옵니다. ResourceId에는 스토리지 계정의 구독 ID, 스토리지 계정의 리소스 그룹 및 스토리지 계정 이름이 포함되어야 합니다. 연결 문자열은 다음 예제와 유사합니다.
"credentials" : { "connectionString" : "ResourceId=/subscriptions/00000000-0000-0000-0000-00000000/resourceGroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.Storage/storageAccounts/MY-DEMO-STORAGE-ACCOUNT/;" }사용자 할당 관리 ID를 사용하여 만든 연결의 경우 계정 키 또는 암호 없이 ResourceId가 포함된 연결 문자열을 가져옵니다. ResourceId에는 스토리지 계정의 구독 ID, 스토리지 계정의 리소스 그룹 및 스토리지 계정 이름이 포함되어야 합니다. 다음 예제에 표시된 구문을 사용하여 ID를 제공합니다. userAssignedIdentity를 사용자 할당 관리 ID로 설정 연결 문자열은 다음 예제와 유사합니다.
"credentials" : { "connectionString" : "ResourceId=/subscriptions/00000000-0000-0000-0000-00000000/resourceGroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.Storage/storageAccounts/MY-DEMO-STORAGE-ACCOUNT/;" }, "identity" : { "@odata.type": "#Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity" : "/subscriptions/00000000-0000-0000-0000-00000000/resourcegroups/MY-DEMO-RESOURCE-GROUP/providers/Microsoft.ManagedIdentity/userAssignedIdentities/MY-DEMO-USER-MANAGED-IDENTITY" }
모델 준비
이 자습서에서는 GenAI 프롬프트에 대한 채팅 완성 모델 및 벡터화를 위한 텍스트 포함 모델이라는 기존 Azure OpenAI 리소스를 보유하고 있다고 가정합니다. 검색 서비스는 기술 세트 처리 중 및 관리 ID를 사용하여 쿼리를 실행하는 동안 모델에 연결합니다. 이 섹션에서는 권한 있는 액세스에 대한 역할을 할당하기 위한 지침과 링크를 제공합니다.
Foundry 리소스를 통해 Azure Document Intelligence 레이아웃 모델에 액세스하기 위한 역할 할당도 필요합니다.
Foundry에서 역할 할당
Foundry 포털이 아닌 Azure Portal에 로그인하고 Foundry 리소스를 찾습니다. Azure Document Intelligence 레이아웃 모델을 제공하는 지역에 있는지 확인합니다.
액세스 제어(IAM) 를 선택합니다.
추가를 선택한 다음 역할 할당 추가를 선택합니다.
Cognitive Services 사용자를 검색한 후 선택합니다.
관리 ID를 선택한 다음 검색 서비스 관리 ID를 할당합니다.
Azure OpenAI에서 역할 할당
Foundry 포털이 아닌 Azure Portal에 로그인하고 Azure OpenAI 리소스를 찾습니다.
액세스 제어(IAM) 를 선택합니다.
추가를 선택한 다음 역할 할당 추가를 선택합니다.
Cognitive Services OpenAI 사용자를 검색한 다음 선택합니다.
관리 ID를 선택한 다음 검색 서비스 관리 ID를 할당합니다.
자세한 내용은 Foundry 모델의 Azure OpenAI에 대한 역할 기반 액세스 제어를 참조하세요.
REST 파일 설정
이 자습서에서는 Azure AI Search에 대한 로컬 REST 클라이언트 연결에 엔드포인트 및 API 키가 필요합니다. Azure Portal에서 이러한 값을 가져올 수 있습니다. 대체 연결 방법은 검색 서비스에 연결을 참조하세요.
인덱서 및 기술 세트 처리 중에 발생하는 인증된 연결의 경우 검색 서비스는 이전에 정의한 역할 할당을 사용합니다.
Visual Studio Code를 시작하고 새 파일을 만듭니다.
요청에 사용되는 변수에 대한 값을 제공합니다. 연결
@storageConnection문자열에 후행 세미콜론 또는 따옴표가 없는지 확인합니다. 의 경우@imageProjectionContainerBlob Storage에서 고유한 컨테이너 이름을 제공합니다. Azure AI 검색은 기술 처리 중에 이 컨테이너를 만듭니다.@searchUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @searchApiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnection = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @cognitiveServicesUrl = PUT-YOUR-AZURE-AI-FOUNDRY-ENDPOINT-HERE @openAIResourceUri = PUT-YOUR-OPENAI-URI-HERE @openAIKey = PUT-YOUR-OPENAI-KEY-HERE @chatCompletionResourceUri = PUT-YOUR-CHAT-COMPLETION-URI-HERE @chatCompletionKey = PUT-YOUR-CHAT-COMPLETION-KEY-HERE @imageProjectionContainer=sustainable-ai-pdf-images.rest또는.http파일 확장자를 사용하여 파일을 저장합니다. REST 클라이언트에 대한 도움말은 빠른 시작: REST를 사용한 전체 텍스트 검색을 참조하세요.
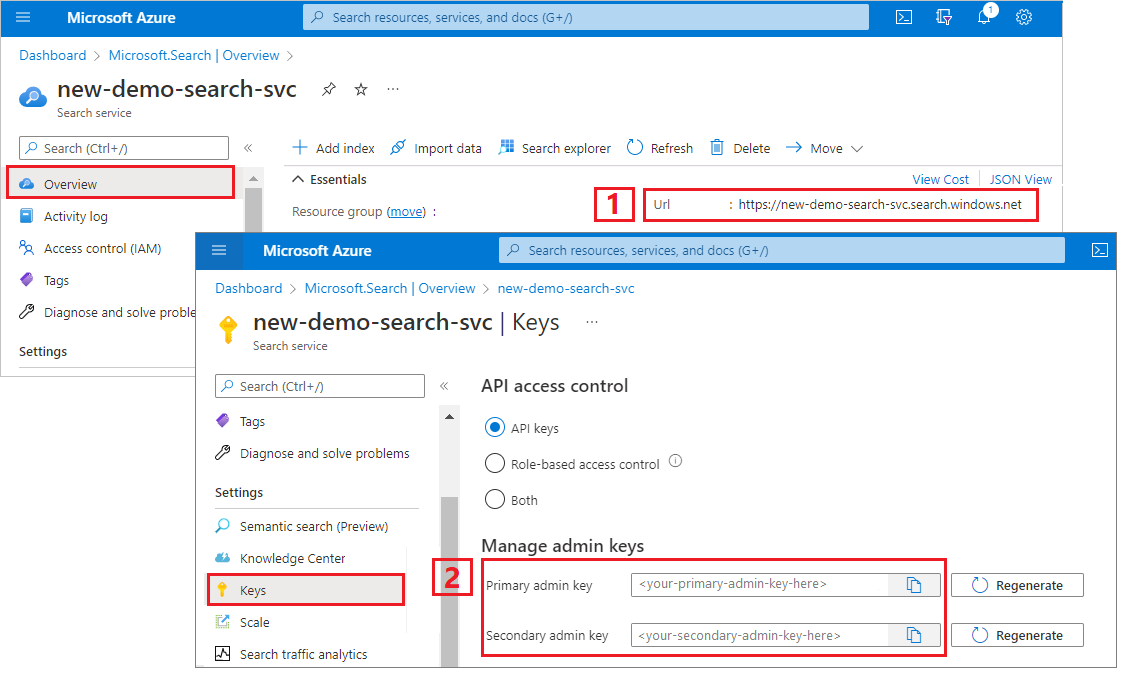
Azure AI Search 엔드포인트 및 API 키를 얻으려면 다음을 수행합니다.
Azure Portal에 로그인하고 검색 서비스 개요 페이지로 이동한 다음, URL을 복사합니다. 엔드포인트의 예는 다음과 같습니다.
https://mydemo.search.windows.net설정>키에서 관리자 키를 복사합니다. 관리자 키는 개체를 추가, 수정, 삭제하는 데 사용됩니다. 교환 가능한 관리자 키는 2개입니다. 둘 중 하나를 복사합니다.
데이터 원본 만들기
REST(데이터 원본 만들기)에 인덱싱할 데이터를 지정하는 데이터 원본 연결을 만듭니다.
### Create a data source using system-assigned managed identities
POST {{searchUrl}}/datasources?api-version=2025-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name": "doc-intelligence-image-verbalization-ds",
"description": "A data source to store multi-modality documents",
"type": "azureblob",
"subtype": null,
"credentials":{
"connectionString":"{{storageConnection}}"
},
"container": {
"name": "sustainable-ai-pdf",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
요청을 보냅니다. 응답은 다음과 같아야 합니다.
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows-int.net:443/datasources('doc-extraction-multimodal-embedding-ds')?api-version=2025-11-01-preview -Preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 4eb8bcc3-27b5-44af-834e-295ed078e8ed
elapsed-time: 346
Date: Sat, 26 Apr 2025 21:25:24 GMT
Connection: close
{
"name": "doc-extraction-multimodal-embedding-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"indexerPermissionOptions": [],
"credentials": {
"connectionString": null
},
"container": {
"name": "sustainable-ai-pdf",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
인덱스 만들기
인덱스 만들기(REST) 검색 서비스에 검색 인덱스가 만들어집니다. 인덱스는 모든 매개 변수 및 해당 특성을 지정합니다.
중첩된 JSON의 경우 인덱스 필드는 원본 필드와 동일해야 합니다. 현재 Azure AI Search는 중첩된 JSON에 대한 필드 매핑을 지원하지 않으므로 필드 이름과 데이터 형식이 완전히 일치해야 합니다. 다음 인덱스는 원시 콘텐츠의 JSON 요소에 맞춥니다.
### Create an index
POST {{searchUrl}}/indexes?api-version=2025-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name": "doc-intelligence-image-verbalization-index",
"fields": [
{
"name": "content_id",
"type": "Edm.String",
"retrievable": true,
"key": true,
"analyzer": "keyword"
},
{
"name": "text_document_id",
"type": "Edm.String",
"searchable": false,
"filterable": true,
"retrievable": true,
"stored": true,
"sortable": false,
"facetable": false
},
{
"name": "document_title",
"type": "Edm.String",
"searchable": true
},
{
"name": "image_document_id",
"type": "Edm.String",
"filterable": true,
"retrievable": true
},
{
"name": "content_text",
"type": "Edm.String",
"searchable": true,
"retrievable": true
},
{
"name": "content_embedding",
"type": "Collection(Edm.Single)",
"dimensions": 3072,
"searchable": true,
"retrievable": true,
"vectorSearchProfile": "hnsw"
},
{
"name": "content_path",
"type": "Edm.String",
"searchable": false,
"retrievable": true
},
{
"name": "offset",
"type": "Edm.String",
"searchable": false,
"retrievable": true
},
{
"name": "location_metadata",
"type": "Edm.ComplexType",
"fields": [
{
"name": "page_number",
"type": "Edm.Int32",
"searchable": false,
"retrievable": true
},
{
"name": "bounding_polygons",
"type": "Edm.String",
"searchable": false,
"retrievable": true,
"filterable": false,
"sortable": false,
"facetable": false
}
]
}
],
"vectorSearch": {
"profiles": [
{
"name": "hnsw",
"algorithm": "defaulthnsw",
"vectorizer": "demo-vectorizer"
}
],
"algorithms": [
{
"name": "defaulthnsw",
"kind": "hnsw",
"hnswParameters": {
"m": 4,
"efConstruction": 400,
"metric": "cosine"
}
}
],
"vectorizers": [
{
"name": "demo-vectorizer",
"kind": "azureOpenAI",
"azureOpenAIParameters": {
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"modelName": "text-embedding-3-large"
}
}
]
},
"semantic": {
"defaultConfiguration": "semanticconfig",
"configurations": [
{
"name": "semanticconfig",
"prioritizedFields": {
"titleField": {
"fieldName": "document_title"
},
"prioritizedContentFields": [
],
"prioritizedKeywordsFields": []
}
}
]
}
}
주요 정보:
텍스트 및 이미지 임베딩은
content_embedding필드에 저장되며, 3072와 같은 적절한 차원과 벡터 검색 프로필을 포함해야 합니다.location_metadata는 각 텍스트 청크 및 정규화된 이미지에 대한 경계 다각형 및 페이지 번호 메타데이터를 캡처하여 정확한 공간 검색 또는 UI 오버레이를 가능하게 합니다.벡터 검색에 대한 자세한 내용은 Azure AI Search의 벡터를 참조하세요.
의미 체계 순위에 대한 자세한 내용은 Azure AI Search의 의미 체계 순위를 참조하세요.
기술 역량을 개발하기
기술 세트 만들기(REST) 는 검색 서비스에 기술 세트를 만듭니다. 기술 세트는 인덱싱 전에 콘텐츠를 청크하고 포함하는 작업을 정의합니다. 이 기술 세트는 문서 레이아웃 기술을 사용하여 텍스트 및 이미지를 추출하고 RAG 애플리케이션의 인용에 유용한 위치 메타데이터를 유지합니다. Azure OpenAI 포함 기술을 사용하여 텍스트 콘텐츠를 벡터화합니다.
또한 기술 세트는 이미지와 관련된 작업을 수행합니다. GenAI 프롬프트 기술을 사용하여 이미지 설명을 생성합니다. 또한 쿼리에서 반환할 수 있도록 그대로 이미지를 저장하는 지식 저장소를 만듭니다.
### Create a skillset
POST {{searchUrl}}/skillsets?api-version=2025-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"name": "doc-intelligence-image-verbalization-skillset",
"description": "A sample skillset for multi-modality using image verbalization",
"skills": [
{
"@odata.type": "#Microsoft.Skills.Util.DocumentIntelligenceLayoutSkill",
"name": "document-cracking-skill",
"description": "Document Layout skill for document cracking",
"context": "/document",
"outputMode": "oneToMany",
"outputFormat": "text",
"extractionOptions": ["images", "locationMetadata"],
"chunkingProperties": {
"unit": "characters",
"maximumLength": 2000,
"overlapLength": 200
},
"inputs": [
{
"name": "file_data",
"source": "/document/file_data"
}
],
"outputs": [
{
"name": "text_sections",
"targetName": "text_sections"
},
{
"name": "normalized_images",
"targetName": "normalized_images"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "text-embedding-skill",
"description": "Azure Open AI Embedding skill for text",
"context": "/document/text_sections/*",
"inputs": [
{
"name": "text",
"source": "/document/text_sections/*/content"
}
],
"outputs": [
{
"name": "embedding",
"targetName": "text_vector"
}
],
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"dimensions": 3072,
"modelName": "text-embedding-3-large"
},
{
"@odata.type": "#Microsoft.Skills.Custom.ChatCompletionSkill",
"uri": "{{chatCompletionResourceUri}}",
"timeout": "PT1M",
"apiKey": "{{chatCompletionKey}}",
"name": "genAI-prompt-skill",
"description": "GenAI Prompt skill for image verbalization",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "systemMessage",
"source": "='You are tasked with generating concise, accurate descriptions of images, figures, diagrams, or charts in documents. The goal is to capture the key information and meaning conveyed by the image without including extraneous details like style, colors, visual aesthetics, or size.\n\nInstructions:\nContent Focus: Describe the core content and relationships depicted in the image.\n\nFor diagrams, specify the main elements and how they are connected or interact.\nFor charts, highlight key data points, trends, comparisons, or conclusions.\nFor figures or technical illustrations, identify the components and their significance.\nClarity & Precision: Use concise language to ensure clarity and technical accuracy. Avoid subjective or interpretive statements.\n\nAvoid Visual Descriptors: Exclude details about:\n\nColors, shading, and visual styles.\nImage size, layout, or decorative elements.\nFonts, borders, and stylistic embellishments.\nContext: If relevant, relate the image to the broader content of the technical document or the topic it supports.\n\nExample Descriptions:\nDiagram: \"A flowchart showing the four stages of a machine learning pipeline: data collection, preprocessing, model training, and evaluation, with arrows indicating the sequential flow of tasks.\"\n\nChart: \"A bar chart comparing the performance of four algorithms on three datasets, showing that Algorithm A consistently outperforms the others on Dataset 1.\"\n\nFigure: \"A labeled diagram illustrating the components of a transformer model, including the encoder, decoder, self-attention mechanism, and feedforward layers.\"'"
},
{
"name": "userMessage",
"source": "='Please describe this image.'"
},
{
"name": "image",
"source": "/document/normalized_images/*/data"
}
],
"outputs": [
{
"name": "response",
"targetName": "verbalizedImage"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill",
"name": "verbalizedImage-embedding-skill",
"description": "Azure Open AI Embedding skill for verbalized image embedding",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "text",
"source": "/document/normalized_images/*/verbalizedImage",
"inputs": []
}
],
"outputs": [
{
"name": "embedding",
"targetName": "verbalizedImage_vector"
}
],
"resourceUri": "{{openAIResourceUri}}",
"deploymentId": "text-embedding-3-large",
"apiKey": "{{openAIKey}}",
"dimensions": 3072,
"modelName": "text-embedding-3-large"
},
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "#5",
"context": "/document/normalized_images/*",
"inputs": [
{
"name": "normalized_images",
"source": "/document/normalized_images/*",
"inputs": []
},
{
"name": "imagePath",
"source": "='my_container_name/'+$(/document/normalized_images/*/imagePath)",
"inputs": []
}
],
"outputs": [
{
"name": "output",
"targetName": "new_normalized_images"
}
]
}
],
"indexProjections": {
"selectors": [
{
"targetIndexName": "doc-intelligence-image-verbalization-index",
"parentKeyFieldName": "text_document_id",
"sourceContext": "/document/text_sections/*",
"mappings": [
{
"name": "content_embedding",
"source": "/document/text_sections/*/text_vector"
},
{
"name": "content_text",
"source": "/document/text_sections/*/content"
},
{
"name": "location_metadata",
"source": "/document/text_sections/*/locationMetadata"
},
{
"name": "document_title",
"source": "/document/document_title"
}
]
},
{
"targetIndexName": "doc-intelligence-image-verbalization-index",
"parentKeyFieldName": "image_document_id",
"sourceContext": "/document/normalized_images/*",
"mappings": [
{
"name": "content_text",
"source": "/document/normalized_images/*/verbalizedImage"
},
{
"name": "content_embedding",
"source": "/document/normalized_images/*/verbalizedImage_vector"
},
{
"name": "content_path",
"source": "/document/normalized_images/*/new_normalized_images/imagePath"
},
{
"name": "document_title",
"source": "/document/document_title"
},
{
"name": "location_metadata",
"source": "/document/normalized_images/*/locationMetadata"
}
]
}
],
"parameters": {
"projectionMode": "skipIndexingParentDocuments"
}
},
"knowledgeStore": {
"storageConnectionString": "{{storageConnection}}",
"identity": null,
"projections": [
{
"files": [
{
"storageContainer": "{{imageProjectionContainer}}",
"source": "/document/normalized_images/*"
}
]
}
]
}
}
이 기술 세트는 텍스트와 이미지를 추출하고, 이미지를 구두로 처리하고, 인덱스에 프로젝션하기 위한 이미지 메타데이터를 셰이프합니다.
주요 정보:
content_text필드는 다음 두 가지 방법으로 채워집니다.문서 레이아웃 기술을 사용하여 추출하고 분할한 문서 텍스트에서 시작합니다.
정규화된 각 이미지에 대한 설명 캡션을 생성하는 GenAI 프롬프트 기술을 사용하는 이미지 콘텐츠에서
필드에는
content_embedding페이지 텍스트와 구두로 설명된 이미지에 대한 3072차원 임베딩이 포함되어 있습니다. Azure OpenAI에서 text-embedding-3-large 모델을 사용하여 생성됩니다.content_path에는 지정된 이미지 프로젝션 컨테이너 내의 이미지 파일에 대한 상대 경로가 포함됩니다. 이 필드는extractOption가["images", "locationMetadata"]또는["images"]로 설정될 때 문서에서 추출된 이미지에 대해서만 생성되며, 원본 필드/document/normalized_images/*/imagePath에서 보강된 문서로 매핑할 수 있습니다.Azure OpenAI 포함 기술을 사용하면 텍스트 데이터를 포함할 수 있습니다. 자세한 내용은 Azure OpenAI 포함 기술을 참조하세요.
인덱서 만들기 및 실행
인덱서 만들기 검색 서비스에 인덱서가 만들어집니다. 인덱서는 데이터 원본에 연결하고, 데이터를 로드하고, 기술 세트를 실행하고, 보강된 데이터를 인덱싱합니다.
### Create and run an indexer
POST {{searchUrl}}/indexers?api-version=2025-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"dataSourceName": "doc-intelligence-image-verbalization-ds",
"targetIndexName": "doc-intelligence-image-verbalization-index",
"skillsetName": "doc-intelligence-image-verbalization-skillset",
"parameters": {
"maxFailedItems": -1,
"maxFailedItemsPerBatch": 0,
"batchSize": 1,
"configuration": {
"allowSkillsetToReadFileData": true
}
},
"fieldMappings": [
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "document_title"
}
],
"outputFieldMappings": []
}
쿼리 실행
첫 번째 문서를 로드하는 즉시 검색을 시작할 수 있습니다.
### Query the index
POST {{searchUrl}}/indexes/doc-intelligence-image-verbalization-index/docs/search?api-version=2025-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"search": "*",
"count": true
}
요청을 보냅니다. 인덱스에 검색 가능한 것으로 표시된 모든 필드와 문서 수를 반환하는 지정되지 않은 전체 텍스트 검색 쿼리입니다. 응답은 다음과 같아야 합니다.
{
"@odata.count": 100,
"@search.nextPageParameters": {
"search": "*",
"count": true,
"skip": 50
},
"value": [
],
"@odata.nextLink": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes/doc-intelligence-image-verbalization-index/docs/search?api-version=2025-11-01-preview "
}
100 문서가 응답에 반환됩니다.
필터의 경우 논리 연산자(및, 그렇지 않음) 및 비교 연산자(eq, ne, gt, lt, ge, le)를 사용할 수도 있습니다. 문자열 비교는 대/소문자를 구분합니다. 자세한 내용 및 예제는 간단한 검색 쿼리의 예를 참조하세요.
Note
매개 변수는 $filter 인덱스 생성 중에 필터링 가능한 것으로 표시된 필드에서만 작동합니다.
### Query for only images
POST {{searchUrl}}/indexes/doc-intelligence-image-verbalization-index/docs/search?api-version=2025-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"search": "*",
"count": true,
"filter": "image_document_id ne null"
}
### Query for text or images with content related to energy, returning the id, parent document, and text (only populated for text chunks), and the content path where the image is saved in the knowledge store (only populated for images)
POST {{searchUrl}}/indexes/doc-intelligence-image-verbalization-index/docs/search?api-version=2025-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{searchApiKey}}
{
"search": "energy",
"count": true,
"select": "content_id, document_title, content_text, content_path"
}
다시 설정하고 다시 실행
인덱서를 다시 설정하여 실행 기록을 지울 수 있으므로 전체 다시 실행할 수 있습니다. 다음 POST 요청은 다시 설정하고 다시 실행합니다.
### Reset the indexer
POST {{searchUrl}}/indexers/doc-intelligence-image-verbalization-indexer/reset?api-version=2025-11-01-preview HTTP/1.1
api-key: {{searchApiKey}}
### Run the indexer
POST {{searchUrl}}/indexers/doc-intelligence-image-verbalization-indexer/run?api-version=2025-11-01-preview HTTP/1.1
api-key: {{searchApiKey}}
### Check indexer status
GET {{searchUrl}}/indexers/doc-intelligence-image-verbalization-indexer/status?api-version=2025-11-01-preview HTTP/1.1
api-key: {{searchApiKey}}
자원을 정리하세요
사용자 고유의 구독에서 작업하는 경우 프로젝트의 끝에서 더 이상 필요하지 않은 리소스를 제거하는 것이 좋습니다. 리소스를 실행 상태로 남겨두면 비용이 발생할 수 있습니다. 리소스를 개별적으로 삭제하거나 리소스 그룹을 삭제하여 전체 리소스 세트를 삭제할 수 있습니다.
Azure Portal을 사용하여 인덱스, 인덱서 및 데이터 원본을 삭제할 수 있습니다.
참고하십시오
이제 다중 모드 인덱싱 시나리오의 샘플 구현에 익숙해졌으므로 다음을 확인하세요.