Azure AI Search는 데이터를 검색 인덱스로 가져오는 두 가지 기본 방법을 지원합니다. 즉, 프로그래밍 방식으로 데이터를 인덱스로 푸시하거나 지원되는 데이터 원본에 인덱서로 데이터를 끌어와야 합니다.
이 자습서에서는 요청을 일괄 처리하고 지수 백오프 다시 시도 전략을 사용하여 푸시 모델을 통해 데이터를 효율적으로 인덱싱하는 방법을 설명합니다. 샘플 애플리케이션을 다운로드하고 실행할 수 있습니다. 또한 이 자습서에서는 애플리케이션의 주요 측면과 데이터를 인덱싱할 때 고려해야 할 요소에 대해서도 설명합니다.
이 자습서에서는 .NET용 Azure SDK에서 C# 및 Azure.Search.Documents 라이브러리 를 사용하여 다음을 수행합니다.
- 인덱스 만들기
- 다양한 일괄 처리 크기를 테스트하여 가장 효율적인 크기 결정
- 비동기식으로 일괄 처리 인덱싱
- 여러 스레드를 사용하여 인덱싱 속도 향상
- 지수 백오프 다시 시도 전략을 사용하여 실패한 문서 다시 시도
필수 구성 요소
- 활성 구독이 있는 Azure 계정. 무료로 계정을 만듭니다.
- Visual Studio
파일 다운로드
이 자습서의 소스 코드는 Azure-Samples/azure-search-dotnet-scale GitHub 리포지토리의 optimzize-data-indexing/v11 폴더에 있습니다.
주요 고려 사항
다음 요소는 인덱싱 속도에 영향을 줍니다. 자세한 내용은 큰 데이터 집합 인덱싱을 참조하세요.
- 가격 책정 계층 및 파티션/복제본 수: 파티션을 추가하거나 계층을 업그레이드하면 인덱싱 속도가 향상됩니다.
- 인덱스 스키마 복잡성: 필드 및 필드 속성을 추가하면 인덱싱 속도가 낮아질 수 있습니다. 인덱스가 작을수록 인덱스가 더 빠릅니다.
- 일괄 처리 크기: 최적의 일괄 처리 크기는 인덱스 스키마 및 데이터 세트에 따라 달라집니다.
- 스레드/작업자수: 단일 스레드는 인덱싱 속도를 최대한 활용하지 않습니다.
- 재시도 전략: 지수 백오프 재시도 전략은 최적의 인덱싱을 위한 모범 사례입니다.
- 네트워크 데이터 전송 속도: 데이터 전송 속도는 제한 요인이 될 수 있습니다. 데이터 전송 속도를 높이려면 Azure 환경 내에서 데이터를 인덱싱합니다.
검색 서비스 만들기
이 자습서에는 Azure Portal 에서 만들 수 있는 Azure AI Search 서비스가 필요합니다. 현재 구독 에서 기존 서비스를 찾을 수도 있습니다. 인덱싱 속도를 정확하게 테스트하고 최적화하려면 프로덕션 환경에서 사용하려는 것과 동일한 가격 책정 계층을 사용하는 것이 좋습니다.
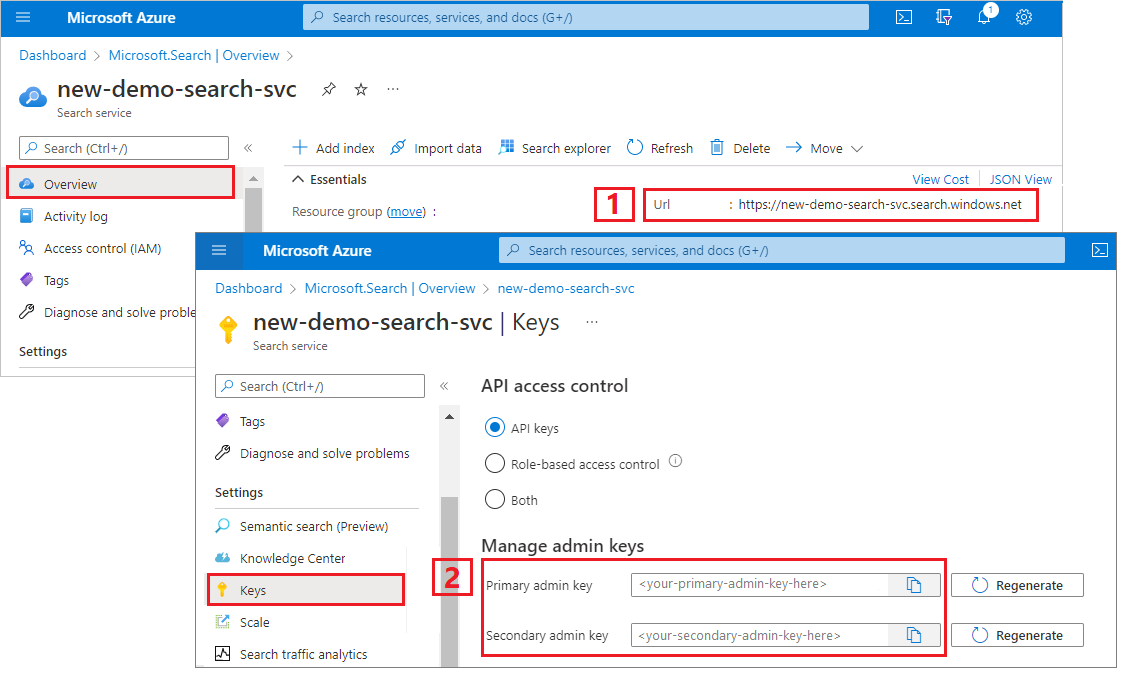
Azure AI 검색에 대한 관리자 키와 URL 가져오기
이 자습서에서는 키 기반 인증을 사용합니다. 관리자 API 키를 복사하여 파일에 붙여넣습니다 appsettings.json .
Azure Portal에서 검색 서비스로 이동합니다.
왼쪽 창에서 개요 를 선택하고 엔드포인트를 복사합니다. 다음 형식이어야 합니다.
https://my-service.search.windows.net왼쪽 창에서 설정>키를 선택하고 서비스에 대한 모든 권한을 위해 관리 키를 복사합니다. 교체 가능한 두 개의 관리자 키가 있으며, 하나를 롤오버해야 하는 경우 비즈니스 연속성을 위해 다른 하나가 제공됩니다. 요청에서 키를 사용하여 개체를 추가, 수정 또는 삭제할 수 있습니다.
환경 설정
Visual Studio에서
OptimizeDataIndexing.sln파일을 엽니다.솔루션 탐색기에서 이전 단계에서 수집한 연결 정보를 사용하여
appsettings.json파일을 편집합니다.{ "SearchServiceUri": "https://{service-name}.search.windows.net", "SearchServiceAdminApiKey": "", "SearchIndexName": "optimize-indexing" }
코드 탐색
업데이트 appsettings.json한 후에는 샘플 프로그램을 OptimizeDataIndexing.sln 빌드하고 실행할 준비가 되어 있어야 합니다.
이 코드는 .NET SDK 작업의 기본 사항에 대한 자세한 정보를 제공하는 빠른 시작: 전체 텍스트 검색의 C# 섹션에서 파생됩니다.
이 간단한 C#/.NET 콘솔 앱에서 수행하는 작업은 다음과 같습니다.
- C#
Hotel클래스(Address클래스도 참조)의 데이터 구조를 기반으로 새 인덱스를 만듭니다. - 다양한 일괄 처리 크기를 테스트하여 가장 효율적인 크기를 결정합니다.
- 데이터를 비동기적으로 인덱싱합니다.
- 여러 스레드를 사용하여 인덱싱 속도 향상
- 지수 백오프 다시 시도 전략을 사용하여 실패한 항목 다시 시도
프로그램을 실행하기 전에 잠시 시간을 내어 이 샘플의 코드 및 인덱스 정의를 연구합니다. 관련 코드는 다음과 같은 여러 파일에 있습니다.
-
Hotel.cs및Address.cs는 인덱스를 정의하는 스키마를 포함합니다. -
DataGenerator.cs에는 많은 양의 호텔 데이터를 쉽게 만들 수 있는 간단한 클래스가 포함되어 있습니다. -
ExponentialBackoff.cs에는 이 문서에 설명된 대로 인덱싱 프로세스를 최적화하는 코드가 포함되어 있습니다. -
Program.cs에는 Azure AI Search 인덱스를 만들고 삭제하고, 데이터 일괄 처리를 인덱싱하고, 다양한 일괄 처리 크기를 테스트하는 함수가 포함되어 있습니다.
인덱스 만들기
이 샘플 프로그램은 .NET용 Azure SDK를 사용하여 Azure AI 검색 인덱스를 정의하고 만듭니다.
FieldBuilder 클래스를 활용하여 C# 데이터 모델 클래스에서 인덱스 구조를 생성합니다.
데이터 모델은 Hotel 클래스에 대한 참조도 포함하는 Address 클래스에 의해 정의됩니다.
FieldBuilder 여러 클래스 정의를 드릴다운하여 인덱스에 대한 복잡한 데이터 구조를 생성합니다. 메타데이터 태그는 검색 가능인지 아니면 정렬 가능인지와 같은 각 필드의 특성을 정의하는 데 사용됩니다.
파일의 Hotel.cs 다음 코드 조각은 단일 필드와 다른 데이터 모델 클래스에 대한 참조를 지정합니다.
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
파일 내에서 Program.cs 인덱스는 이름과, FieldBuilder.Build(typeof(Hotel)) 메서드를 통해 생성된 필드 컬렉션으로 정의된 후 다음과 같이 생성됩니다.
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
데이터 생성
테스트용 데이터를 생성하기 위해 파일에 간단한 클래스가 구현됩니다 DataGenerator.cs . 이 클래스의 목적은 인덱싱을 위한 고유 ID를 사용하여 많은 수의 문서를 쉽게 생성할 수 있도록 하는 것입니다.
고유 ID가 있는 100,000개의 호텔 목록을 얻으려면 다음 코드를 실행합니다.
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
이 샘플에는 테스트에 사용할 수 있는 두 가지 크기(small 및 large)의 호텔이 있습니다.
인덱스의 스키마는 인덱싱 속도에 영향을 줍니다. 이 자습서를 완료한 후 이 클래스를 변환하여 의도한 인덱스 스키마와 가장 일치하는 데이터를 생성하는 것이 좋습니다.
일괄 처리 크기 테스트
단일 또는 여러 문서를 인덱스에 로드하기 위해 Azure AI Search는 다음 API를 지원합니다.
문서를 일괄적으로 인덱싱하면 인덱싱 성능이 크게 향상됩니다. 이러한 일괄 처리는 최대 1,000개의 문서 또는 일괄 처리당 최대 16MB까지 가능합니다.
가장 적합한 데이터 일괄 처리 크기를 결정하는 것은 인덱싱 속도를 최적화하는 핵심 구성 요소입니다. 최적의 일괄 처리 크기에 영향을 주는 두 가지 주요 요소는 다음과 같습니다.
- 인덱스의 스키마
- 데이터의 크기
최적의 일괄 처리 크기는 인덱스 및 데이터에 따라 달라지므로 가장 좋은 방법은 다양한 일괄 처리 크기를 테스트하여 시나리오에서 가장 빠른 인덱싱 속도의 결과를 결정하는 것입니다.
다음 함수에서는 일괄 처리 크기를 테스트하는 간단한 방법을 보여 줍니다.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
모든 문서의 크기가 동일하지 않으므로(이 샘플에 있지만), 검색 서비스에 보내는 데이터의 크기를 추정합니다. 먼저 개체를 JSON으로 변환한 다음 크기(바이트)를 결정하는 다음 함수를 사용하여 이 작업을 수행할 수 있습니다. 이 기법을 사용하면 MB/초 인덱싱 속도 측면에서 가장 효율적인 일괄 처리 크기를 결정할 수 있습니다.
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
이 함수를 사용하려면 SearchClient 및 각 일괄 처리 크기 테스트 시도 횟수가 필요합니다. 각 일괄 처리의 인덱싱 시간이 변동될 수 있으므로 결과의 통계적 유의미성을 높이기 위해 기본적으로 각 일괄 처리를 세 번 시도합니다.
await TestBatchSizesAsync(searchClient, numTries: 3);
함수를 실행하면 다음 예제와 유사한 출력이 콘솔에 표시됩니다.
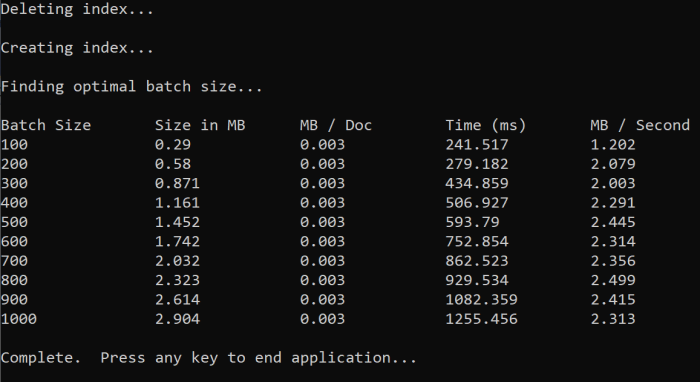
가장 효율적인 일괄 처리 크기를 식별하고 이 자습서의 다음 단계에서 해당 일괄 처리 크기를 사용합니다. 여러 일괄 처리 크기에서 정체기(MB/s)가 표시될 수 있습니다.
데이터 인덱싱
이제 사용하려는 일괄 처리 크기를 확인했으므로 다음 단계는 데이터 인덱싱을 시작하는 것입니다. 데이터를 효율적으로 인덱싱하기 위해 이 샘플에서 다음을 수행합니다.
- 여러 스레드/작업자 사용
- 지수 백오프 다시 시도 전략을 구현합니다.
41~49줄의 주석 처리를 제거한 다음 프로그램을 다시 실행합니다. 매개 변수를 변경하지 않고 코드를 실행하는 경우 이 실행에서 샘플은 문서 일괄 처리를 최대 100,000개까지 생성하고 보냅니다.
여러 스레드/작업자 사용
Azure AI Search의 인덱싱 속도를 활용하려면 여러 스레드를 사용하여 일괄 처리 인덱싱 요청을 서비스에 동시에 보냅니다.
몇 가지 주요 고려 사항은 최적의 스레드 수에 영향을 줄 수 있습니다. 이 샘플을 수정하고 다양한 스레드 수로 테스트하여 시나리오에 가장 적합한 스레드 수를 결정할 수 있습니다. 그러나 여러 스레드가 동시에 실행되는 동안에는 대부분의 효율성 이점을 활용할 수 있어야 합니다.
검색 서비스에 대한 요청을 늘리면 요청이 완전히 성공하지 못했음을 나타내는 HTTP 상태 코드가 발생할 수 있습니다. 인덱싱 중에 발생하는 두 가지 일반적인 HTTP 상태 코드는 다음과 같습니다.
- 503 서비스를 사용할 수 없음: 이 오류는 시스템이 과부하 상태이며 현재 요청을 처리할 수 없음을 의미합니다.
- 207 다중 상태: 이 오류는 일부 문서가 성공했지만 하나 이상의 문서가 실패했음을 의미합니다.
지수 백오프 다시 시도 전략 구현
오류가 발생하면 지수 백오프 재시도 전략을 사용하여 요청을 다시 시도해야 합니다.
Azure AI Search의 .NET SDK는 503 및 기타 실패한 요청을 자동으로 다시 시도하지만 207을 다시 시도하려면 사용자 고유의 논리를 구현해야 합니다. Polly와 같은 오픈 소스 도구는 재시도 전략에 유용할 수 있습니다.
이 샘플에서는 자체의 지수 백오프 다시 시도 전략을 구현합니다. 먼저 maxRetryAttempts 및 실패한 요청에 대한 초기 delay을 포함하여 몇 가지 변수를 정의합니다.
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
인덱싱 작업의 결과는 IndexDocumentResult result 변수에 저장됩니다. 이 변수를 사용하면 다음 예제와 같이 일괄 처리의 문서가 실패했는지 확인할 수 있습니다. 부분 오류가 발생하면 실패한 문서 ID를 기반으로 새 일괄 처리가 생성됩니다.
RequestFailedException 요청이 완전히 실패하고 다시 시도되었음을 나타내므로 예외도 catch해야 합니다.
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
여기에서 지수 백오프 코드를 함수로 래핑하여 쉽게 호출할 수 있습니다.
그런 다음, 활성 스레드를 관리하는 다른 함수를 만듭니다. 간단히 하기 위해 이 함수는 여기에 포함되지 않았지만 ExponentialBackoff.cs에서 확인할 수 있습니다. 다음 명령을 사용하여 함수를 호출할 수 있습니다. 여기서 hotels 업로드 1000 하려는 데이터는 일괄 처리 크기이며 8 동시 스레드의 수입니다.
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
함수를 실행하면 다음 예제와 유사한 출력이 표시됩니다.
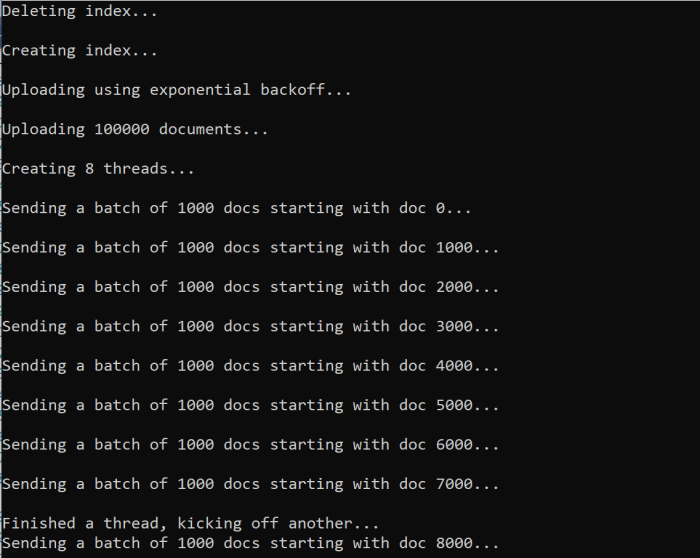
문서 일괄 처리가 실패하면 오류를 나타내는 오류와 일괄 처리가 다시 시도되고 있음을 나타내는 오류가 출력됩니다.
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
함수 실행이 완료되면 모든 문서가 인덱스에 추가되었는지 확인할 수 있습니다.
인덱스 탐색
프로그램 실행이 완료되면 프로그래밍 방식으로 또는 Azure Portal에서 검색 탐색기를 사용하여 채워진 검색 인덱스를 탐색할 수 있습니다.
프로그래밍 방식
인덱스의 문서 수를 확인하는 두 가지 주요 옵션으로 문서 수 계산 API 및 인덱스 통계 가져오기 API가 있습니다. 두 경로 모두 처리 시간이 필요하므로 반환되는 문서 수가 처음에 예상보다 낮으면 놀라지 마세요.
문서 수 계산
문서 개수 작업은 검색 인덱스의 문서 수를 검색합니다.
long indexDocCount = await searchClient.GetDocumentCountAsync();
인덱스 통계 가져오기
인덱스 통계 가져오기 작업은 현재 인덱스의 문서 수와 스토리지 사용량을 반환합니다. 인덱스 통계는 문서 수보다 업데이트하는 데 더 오래 걸립니다.
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
Azure portal
Azure Portal의 왼쪽 창에서 인덱스 목록에서 최적화 인덱싱 인덱스를 찾습니다.

문서 수 및 스토리지 크기는 인덱스 통계 가져오기 API를 기반으로 하며 업데이트하는 데 몇 분 정도 걸릴 수 있습니다.
다시 설정하고 다시 실행
초기 개발 실험 단계에서 설계 반복에 대한 가장 실용적인 방법은 Azure AI 검색에서 개체를 삭제하고 코드에서 이를 다시 작성하도록 허용하는 것입니다. 리소스 이름은 고유합니다. 개체를 삭제하면 동일한 이름을 사용하여 개체를 다시 만들 수 있습니다.
이 자습서의 샘플 코드는 기존 인덱스를 확인하고 삭제하여 코드를 다시 실행할 수 있도록 합니다.
Azure Portal을 사용하여 인덱스를 삭제할 수도 있습니다.
리소스 정리
사용자 고유의 구독에서 작업하는 경우 프로젝트의 끝에서 더 이상 필요하지 않은 리소스를 제거하는 것이 좋습니다. 계속 실행되는 리소스에는 요금이 부과될 수 있습니다. 리소스를 개별적으로 삭제하거나 리소스 그룹을 삭제하여 전체 리소스 세트를 삭제할 수 있습니다.
왼쪽 탐색 창의 모든 리소스 또는 리소스 그룹 링크를 사용하여 Azure Portal에서 리소스를 찾고 관리할 수 있습니다.
다음 단계
대량 데이터를 인덱싱하는 방법에 대해 자세히 알아보려면 다음 자습서를 시도해 보세요.