2 - Python을 사용하여 검색 인덱스 만들기 및 로드
다음 단계에 따라 검색 지원 웹 사이트를 계속 빌드합니다.
- 검색 리소스 만들기
- 새 인덱스 만들기
- 샘플 스크립트 및 Azure SDK @azure/search-documents를 사용하여 Python을 통해 새 인덱스 만들기 및 데이터 가져옵니다.
Azure AI 검색 리소스 만들기
Azure CLI 또는 Azure PowerShell을 사용하여 명령줄에서 새 검색 리소스를 만듭니다. 인덱스 읽기 액세스에 사용되는 쿼리 키를 가져오고 개체를 추가하는 데 사용되는 기본 제공 관리 키를 가져옵니다.
디바이스에 Azure CLI 또는 Azure PowerShell이 설치되어 있어야 합니다. 디바이스의 로컬 관리자가 아닌 경우 Azure PowerShell을 선택하고 Scope 매개 변수를 사용하여 현재 사용자로 실행합니다.
참고 항목
이 작업에는 Azure CLI 및 Azure PowerShell용 Visual Studio Code 확장이 필요하지 않습니다. Visual Studio Code는 확장 없이 명령줄 도구를 인식합니다.
Visual Studio Code의 터미널아래에서 새 터미널을 선택합니다.
Azure에 연결:
az login새 검색 서비스를 만들기 전에 구독에 대한 기존 서비스를 나열합니다.
az resource list --resource-type Microsoft.Search/searchServices --output table사용하려는 서비스가 있는 경우 이름을 적어둔 다음, 다음 섹션으로 건너뜁니다.
새 검색 서비스를 만듭니다. 다음 명령을 템플릿으로 사용하여 리소스 그룹, 서비스 이름, 계층, 지역, 파티션 및 복제본에 유효한 값을 대체합니다. 다음 문은 이전 단계에서 만든 "cognitive-search-demo-rg" 리소스 그룹을 사용하고 "무료" 계층을 지정합니다. Azure 구독에 이미 무료 검색 서비스가 있는 경우 청구 가능한 계층(예: "기본")을 지정합니다.
az search service create --name my-cog-search-demo-svc --resource-group cognitive-search-demo-rg --sku free --partition-count 1 --replica-count 1검색 서비스에 대한 읽기 권한을 부여하는 쿼리 키를 가져옵니다. 검색 서비스는 두 개의 관리 키와 하나의 쿼리 키로 프로비전됩니다. 리소스 그룹 및 검색 서비스의 유효한 이름을 대체합니다. 쿼리 키를 메모장에 복사하여 이후 단계에서 클라이언트 코드에 붙여넣을 수 있게 합니다.
az search query-key list --resource-group cognitive-search-demo-rg --service-name my-cog-search-demo-svc검색 서비스 관리자 API 키를 가져옵니다. 관리자 API 키는 검색 서비스에 대한 쓰기 액세스를 제공합니다. 인덱스를 만들고 로드하는 대량 가져오기 단계에서 사용할 수 있도록 관리 키 중 하나를 메모장에 복사합니다.
az search admin-key show --resource-group cognitive-search-demo-rg --service-name my-cog-search-demo-svc
검색을 위해 대량 가져오기 스크립트 준비
이 스크립트는 Azure AI 검색용 Azure SDK를 사용합니다.
Visual Studio Code에서
search-website-functions-v4/bulk-upload하위 디렉터리의bulk_upload.py파일을 열고, Azure Search SDK를 사용하여 인증하기 위해 다음 변수를 사용자 고유의 값으로 바꿉니다.- YOUR-SEARCH-SERVICE-NAME
- YOUR-SEARCH-SERVICE-ADMIN-API-KEY
import sys import json import requests import pandas as pd from azure.core.credentials import AzureKeyCredential from azure.search.documents import SearchClient from azure.search.documents.indexes import SearchIndexClient from azure.search.documents.indexes.models import SearchIndex from azure.search.documents.indexes.models import ( ComplexField, CorsOptions, SearchIndex, ScoringProfile, SearchFieldDataType, SimpleField, SearchableField, ) # Get the service name (short name) and admin API key from the environment service_name = "YOUR-SEARCH-SERVICE-NAME" key = "YOUR-SEARCH-SERVICE-ADMIN-API-KEY" endpoint = "https://{}.search.windows.net/".format(service_name) # Give your index a name # You can also supply this at runtime in __main__ index_name = "good-books" # Search Index Schema definition index_schema = "./good-books-index.json" # Books catalog books_url = "https://raw.githubusercontent.com/Azure-Samples/azure-search-sample-data/main/good-books/books.csv" batch_size = 1000 # Instantiate a client class CreateClient(object): def __init__(self, endpoint, key, index_name): self.endpoint = endpoint self.index_name = index_name self.key = key self.credentials = AzureKeyCredential(key) # Create a SearchClient # Use this to upload docs to the Index def create_search_client(self): return SearchClient( endpoint=self.endpoint, index_name=self.index_name, credential=self.credentials, ) # Create a SearchIndexClient # This is used to create, manage, and delete an index def create_admin_client(self): return SearchIndexClient(endpoint=endpoint, credential=self.credentials) # Get Schema from File or URL def get_schema_data(schema, url=False): if not url: with open(schema) as json_file: schema_data = json.load(json_file) return schema_data else: data_from_url = requests.get(schema) schema_data = json.loads(data_from_url.content) return schema_data # Create Search Index from the schema # If reading the schema from a URL, set url=True def create_schema_from_json_and_upload(schema, index_name, admin_client, url=False): cors_options = CorsOptions(allowed_origins=["*"], max_age_in_seconds=60) scoring_profiles = [] schema_data = get_schema_data(schema, url) index = SearchIndex( name=index_name, fields=schema_data["fields"], scoring_profiles=scoring_profiles, suggesters=schema_data["suggesters"], cors_options=cors_options, ) try: upload_schema = admin_client.create_index(index) if upload_schema: print(f"Schema uploaded; Index created for {index_name}.") else: exit(0) except: print("Unexpected error:", sys.exc_info()[0]) # Convert CSV data to JSON def convert_csv_to_json(url): df = pd.read_csv(url) convert = df.to_json(orient="records") return json.loads(convert) # Batch your uploads to Azure Search def batch_upload_json_data_to_index(json_file, client): batch_array = [] count = 0 batch_counter = 0 for i in json_file: count += 1 batch_array.append( { "id": str(i["book_id"]), "goodreads_book_id": int(i["goodreads_book_id"]), "best_book_id": int(i["best_book_id"]), "work_id": int(i["work_id"]), "books_count": i["books_count"] if i["books_count"] else 0, "isbn": str(i["isbn"]), "isbn13": str(i["isbn13"]), "authors": i["authors"].split(",") if i["authors"] else None, "original_publication_year": int(i["original_publication_year"]) if i["original_publication_year"] else 0, "original_title": i["original_title"], "title": i["title"], "language_code": i["language_code"], "average_rating": int(i["average_rating"]) if i["average_rating"] else 0, "ratings_count": int(i["ratings_count"]) if i["ratings_count"] else 0, "work_ratings_count": int(i["work_ratings_count"]) if i["work_ratings_count"] else 0, "work_text_reviews_count": i["work_text_reviews_count"] if i["work_text_reviews_count"] else 0, "ratings_1": int(i["ratings_1"]) if i["ratings_1"] else 0, "ratings_2": int(i["ratings_2"]) if i["ratings_2"] else 0, "ratings_3": int(i["ratings_3"]) if i["ratings_3"] else 0, "ratings_4": int(i["ratings_4"]) if i["ratings_4"] else 0, "ratings_5": int(i["ratings_5"]) if i["ratings_5"] else 0, "image_url": i["image_url"], "small_image_url": i["small_image_url"], } ) # In this sample, we limit batches to 1000 records. # When the counter hits a number divisible by 1000, the batch is sent. if count % batch_size == 0: client.upload_documents(documents=batch_array) batch_counter += 1 print(f"Batch sent! - #{batch_counter}") batch_array = [] # This will catch any records left over, when not divisible by 1000 if len(batch_array) > 0: client.upload_documents(documents=batch_array) batch_counter += 1 print(f"Final batch sent! - #{batch_counter}") print("Done!") if __name__ == "__main__": start_client = CreateClient(endpoint, key, index_name) admin_client = start_client.create_admin_client() search_client = start_client.create_search_client() schema = create_schema_from_json_and_upload( index_schema, index_name, admin_client, url=False ) books_data = convert_csv_to_json(books_url) batch_upload = batch_upload_json_data_to_index(books_data, search_client) print("Upload complete")Visual Studio에서 프로젝트 디렉터리의
search-website-functions-v4/bulk-upload하위 디렉터리에 대한 통합 터미널을 열고, 다음 명령을 실행하여 종속성을 설치합니다.python3 -m pip install -r requirements.txt
검색을 위해 대량 가져오기 스크립트 실행
Visual Studio에서 프로젝트 디렉터리의
search-website-functions-v4/bulk-upload하위 디렉터리에 대한 통합 터미널을 계속 사용하고, 다음 bash 명령을 실행하여bulk_upload.py스크립트를 실행합니다.python3 bulk-upload.py코드가 실행되면서 진행률이 콘솔에 표시됩니다.
업로드가 완료되면 콘솔에 출력된 마지막 명령문은 "Done(완료)입니다! 완료된 업로드”입니다.
새 검색 인덱스 검토
업로드가 완료되면 검색 인덱스를 사용할 준비가 됩니다. Azure Portal에서 새 인덱스를 검토합니다.
Azure Portal에서 이전 단계에서 만든 검색 서비스를 찾습니다.
왼쪽에서 인덱스를 선택한 다음, 좋은 책 인덱스를 선택합니다.
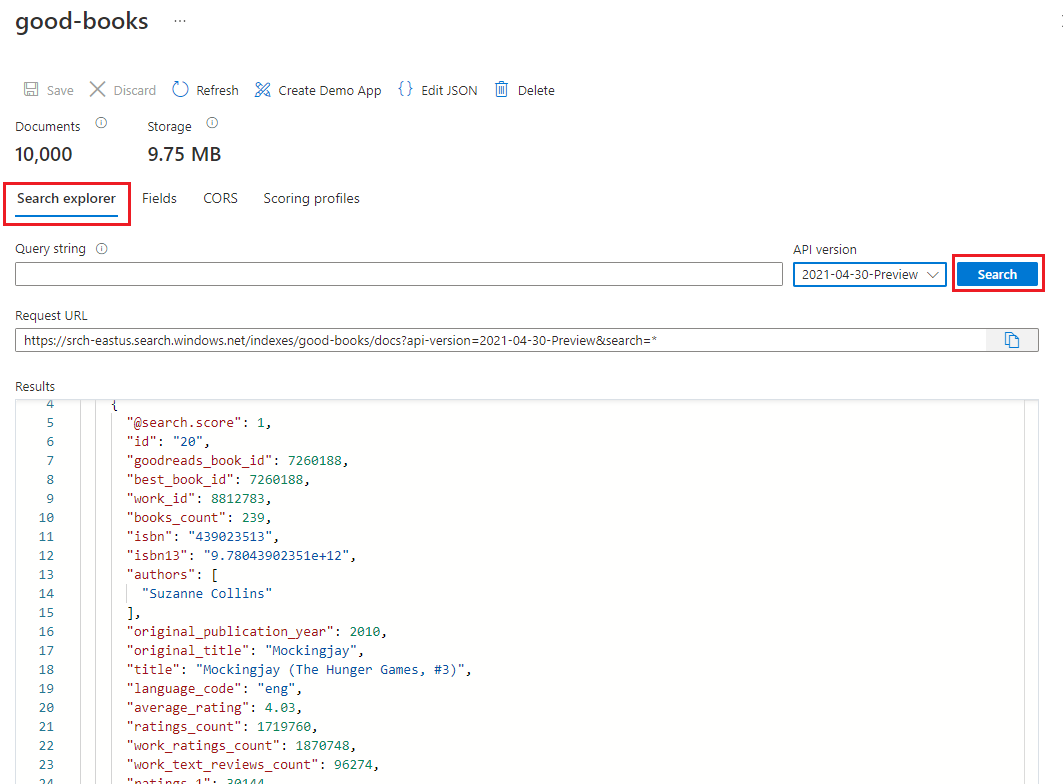
기본적으로 인덱스가 검색 탐색기 탭에서 열립니다. 검색을 선택하여 인덱스에서 문서를 반환합니다.


대량 가져오기 파일 변경 내용 롤백
bulk-insert 디렉터리에 있는 Visual Studio Code 통합 터미널에서 다음 git 명령을 사용하여 변경 내용을 롤백합니다. 이 자습서를 계속 진행하는 데 필요하지는 않으므로 이러한 비밀을 리포지토리로 저장하거나 푸시하지 않는 것이 좋습니다.
git checkout .
검색 리소스 이름 복사
검색 리소스 이름을 적어 둡니다. 이는 Azure 함수 앱을 검색 리소스에 연결하는 데 필요합니다.
주의
Azure 함수에서 검색 관리자 키를 사용하려고 할 수 있지만, 이는 최소 권한 원칙을 준수하지 않습니다. Azure 함수는 최소 권한을 준수하기 위해 쿼리 키를 사용합니다.