큰 문서를 더 작은 청크로 분할하면 모델 포함의 최대 토큰 입력 한도 이내로 유지하는 데 도움이 될 수 있습니다. 예를 들어 Azure OpenAI text-embedding-ada-002 모델에 대한 입력 텍스트의 최대 길이는 8,191개 토큰입니다. 일반적인 OpenAI 모델의 경우 각 토큰이 약 4자의 텍스트라는 점을 고려하면 이 최대 제한은 약 6,000단어의 텍스트에 해당합니다. 이러한 모델을 사용하여 포함을 생성하는 경우 입력 텍스트가 제한 미만으로 유지되어야 합니다. 콘텐츠를 청크로 분할하면 포함 모델 요구 사항을 충족하고 잘림으로 인한 데이터 손실을 방지할 수 있습니다.
기본 제공 데이터 청크 분할 및 포함을 위해 통합된 벡터화를 사용하는 것이 좋습니다. 통합 벡터화는 텍스트를 분할하고 포함을 생성하는 인덱서 및 기술에 대한 종속성을 사용합니다. 통합 벡터화를 사용할 수 없는 경우 이 문서에서는 콘텐츠를 청크하기 위한 몇 가지 대체 방법을 설명합니다.
일반적인 청킹 기법
청크는 원본 문서가 모델에 의해 부과된 최대 입력 크기에 비해 너무 큰 경우에만 필요하지만 콘텐츠가 단일 벡터로 제대로 표현되지 않는 경우에도 유용합니다. 다양한 하위 항목을 다루는 위키 페이지를 고려해 보세요. 전체 페이지는 모델 입력 요구 사항을 충족할 수 있을 만큼 작을 수 있지만 세밀하게 청크하는 경우 더 나은 결과를 얻을 수 있습니다.
다음은 인덱서 및 기술을 사용하는 경우 기본 제공 기능과 관련된 몇 가지 일반적인 청크 기술입니다.
| 접근법 | 사용법 | 기본 제공 기능 |
|---|---|---|
| 고정 크기 청크 | 의미상 의미 있는 단락(예: 200단어 또는 600자)에 충분한 고정 크기를 정의하고 일부 겹침(예: 콘텐츠의 10-15%)을 허용하면 벡터 생성기를 포함하기 위한 입력으로 양호한 청크를 생성할 수 있습니다. | 텍스트 분할 기술, 페이지로 분할(문자 길이로 정의) |
| 콘텐츠 특성을 기반으로 하는 가변 크기 청크 | 문장을 구분하기 위해 문장 부호, 줄 끝 표시 또는 문서 구조를 감지하는 자연어 처리(NLP) 라이브러리의 기능을 사용하여 데이터를 분할합니다. HTML 또는 Markdown과 같은 포함된 태그에는 섹션별로 데이터를 청크하는 데 사용할 수 있는 제목 구문이 있습니다. | 문서 레이아웃 기술 또는 텍스트 분할 기술, 문장으로 분할. |
| 사용자 지정 조합 | 고정 청크 및 변수 크기의 청크를 조합하여 사용하거나 접근 방식을 확장합니다. 예를 들어 큰 문서를 처리할 때는 가변 크기 청크를 사용할 수 있을 뿐만 아니라 문서 중간의 청크에 문서 제목을 추가하여 컨텍스트 손실을 방지할 수도 있습니다. | 없음 |
| 문서 구문 분석 | 인덱서는 더 큰 원본 문서를 더 작은 검색 문서로 구문 분석하여 인덱싱할 수 있습니다. 엄밀히 말해, 이 방법은 청킹이 아니지만 때로는 동일한 목표를 달성할 수 있습니다. | Markdown Blob 및 파일 인덱스 또는 일대다 인덱싱 또는 JSON Blob 및 파일 인덱스 |
콘텐츠 겹침 고려 사항
고정 크기에 따라 데이터를 청크할 때 청크 간에 적은 양의 텍스트가 겹치면 컨텍스트를 유지하는 데 도움이 될 수 있습니다. 약 10%의 겹침부터 시작하는 것이 좋습니다. 예를 들어 고정 청크 크기가 256개 토큰인 경우 25개의 토큰 겹칩으로 테스트를 시작합니다. 실제 중복 크기는 데이터 형식 및 특정 사용 사례에 따라 다르지만 10~15개% 많은 시나리오에서 작동합니다.
데이터 청크에 대한 요인
데이터를 청크할 때는 다음과 같은 요인을 고려해야 합니다.
문서의 모양 및 밀도. 텍스트나 구절을 그대로 유지해야 하는 경우 문장 구조를 유지하는 더 큰 청크와 가변 청크가 더 나은 결과를 생성할 수 있습니다.
사용자 쿼리: 더 큰 청크와 겹침 전략은 특정 정보를 대상으로 하는 쿼리에 대한 컨텍스트 및 의미 체계의 풍부함을 유지하는 데 도움이 됩니다.
LLM(대규모 언어 모델)에는 청크 크기에 대한 성능 지침이 있습니다. 사용 중인 모든 모델에 가장 적합한 청크 크기를 찾습니다. 예를 들어 요약 및 포함에 모델을 사용하는 경우 둘 다에 적합한 최적의 청크 크기를 선택합니다.
워크플로에 청크를 맞추는 방법
큰 문서가 있는 경우 큰 텍스트를 분할하는 인덱싱 및 쿼리 워크플로에 청크 분할 단계를 삽입합니다. 통합 벡터화를 사용하는 경우 텍스트 분할 기술을 사용하는 기본 청크 전략이 일반적입니다. 사용자 지정 기술을 사용하여 사용자 지정 청크 분할 전략을 적용할 수도 있습니다. 청크를 제공하는 일부 외부 라이브러리는 다음과 같습니다.
대부분의 라이브러리는 모두 고정 크기, 가변 크기 또는 조합에 대한 일반적인 청크 기술을 제공합니다. 컨텍스트 유지를 위해 각 청크에서 소량의 콘텐츠를 복제하는 중복을 지정할 수도 있습니다.
청크 분할 예제
다음 예제에서는 청크 분할 전략이 NASA Earth at Night 전자책 PDF 파일에 적용되는 방법을 보여 줍니다.
텍스트 분할 기술 예제
텍스트 분할 기술을 통한 통합 데이터 청크 분할이 일반 공급됩니다.
이 섹션에서는 기술 기반 접근 방식과 텍스트 분할 기술 매개 변수를 사용하는 기본 제공 데이터 청크 분할에 대해 설명합니다.
이 예제의 샘플 Notebook은 azure-search-vector-samples 리포지토리에서 찾을 수 있습니다.
콘텐츠를 더 작은 청크로 분할하도록 textSplitMode를 설정합니다.
-
pages(기본값). 청크가 여러 문장으로 구성됩니다. -
sentences; 청크가 단일 문장으로 구성됩니다. "문장"을 구성하는 것은 언어에 따라 다릅니다. 영어에서는.또는!같은 표준 종료 부호가 사용됩니다. 언어는defaultLanguageCode매개 변수로 제어됩니다.
pages 매개 변수는 추가 매개 변수를 추가합니다.
-
maximumPageLength는 각 청크의 최대 문자 1 또는 토큰 2를 정의합니다. 텍스트 분할기는 문장 분리를 방지하므로 실제 문자 수는 콘텐츠에 따라 달라집니다. -
pageOverlapLength는 다음 페이지의 시작 부분에 포함되는 이전 페이지 끝의 문자 수를 정의합니다. 설정된 경우 최대 페이지 길이의 절반 미만이어야 합니다. -
maximumPagesToTake는 문서에서 가져올 페이지/청크 수를 정의합니다. 기본값은 0입니다. 즉, 문서에서 모든 페이지 또는 청크를 가져옵니다.
1 문자가 토큰 정의에 맞지 않습니다. LLM에서 측정한 토큰 수는 텍스트 분할 기술로 측정한 문자 크기와 다를 수 있습니다.
2 토큰 청크는 2024-09-01-preview에서 사용할 수 있으며, 청크 중 분할되지 말아야 할 토큰과 토크나이저를 지정하기 위한 추가 매개변수를 포함합니다.
다음 표에서는 선택한 매개 변수가 Earth at Night 전자책의 총 청크 수에 미치는 영향을 보여 줍니다.
textSplitMode |
maximumPageLength |
pageOverlapLength |
총 청크 수 |
|---|---|---|---|
pages |
1000 | 0 | 172 |
pages |
1000 | 200 | 216 |
pages |
2000 | 0 | 85 |
pages |
2000 | 500 | 113 |
pages |
5,000 | 0 | 34 |
pages |
5,000 | 500 | 38 |
sentences |
해당 없음 | 해당 없음 | 13361 |
textSplitMode와 pages를 사용하면 대부분의 청크에서 총 문자 수가 maximumPageLength에 가까운 결과를 얻습니다. 청크 문자 수는 청크 안에서 문장 경계의 위치가 다르므로 달라집니다. 청크 토큰 길이는 청크의 콘텐츠 차이로 인해 달라집니다.
다음 히스토그램은 Earth at Night 전자책에서 textSplitMode, pages 2000 및 maximumPageLength 500을 사용할 때 청크 문자 길이의 분포가 pageOverlapLength의 청크 토큰 길이와 어떻게 다른지를 비교해서 보여 줍니다.
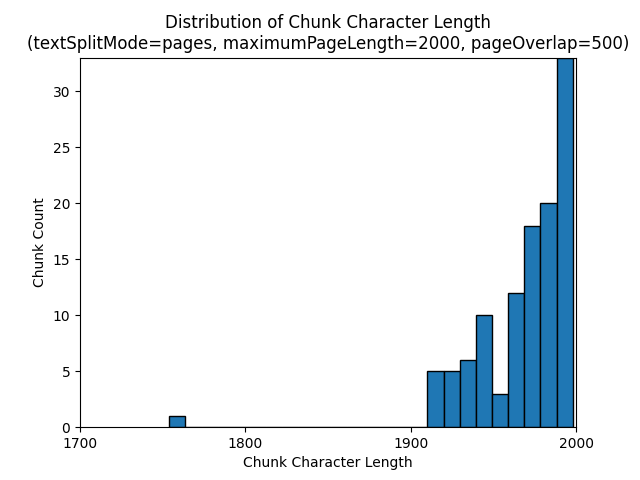
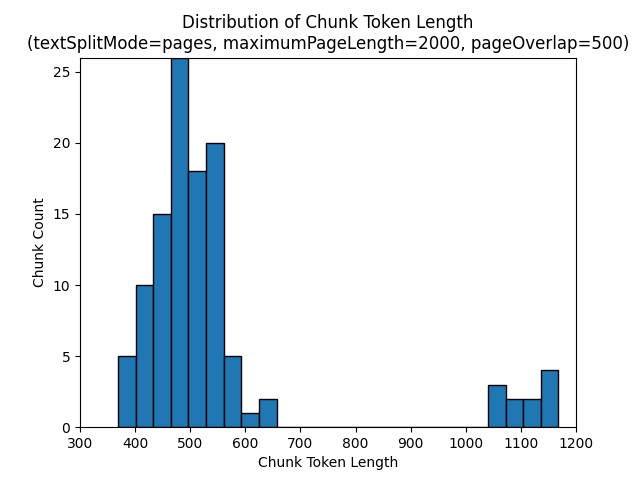
textSplitMode
sentences를 사용하면 개별 문장으로 구성된 청크가 많이 생성됩니다. 이러한 청크는 생성되는 pages청크보다 작으며 청크의 토큰 수는 문자 수와 더 밀접하게 일치합니다.
다음 히스토그램은 Earth at Night 전자책에서 textSplitMode를 사용할 때 청크 문자 길이의 분포가 sentences의 청크 토큰 길이와 어떻게 다른지를 비교해서 보여 줍니다.
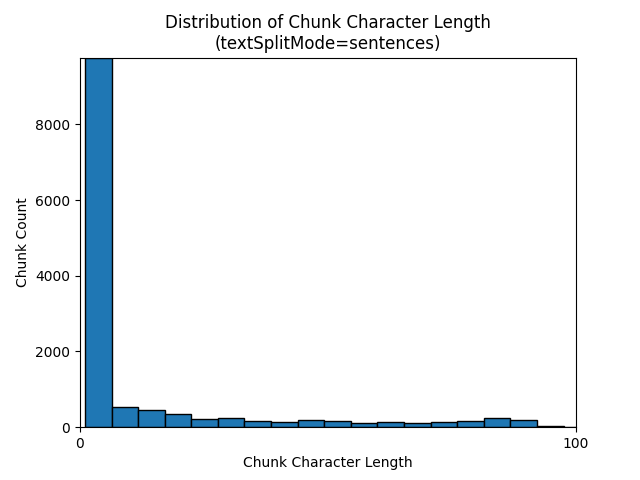
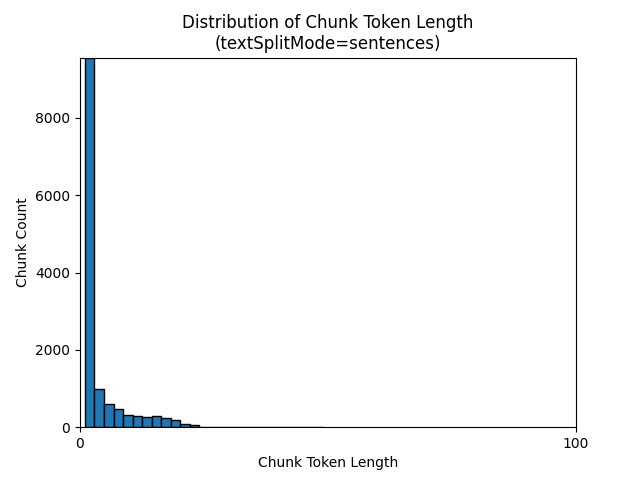
최적의 매개 변수 선택은 청크가 사용되는 방식에 따라 달라집니다. 대부분의 애플리케이션에서는 다음 기본 매개 변수로 시작하는 것이 좋습니다.
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
2000 | 500 |
LangChain 데이터 청크 분할 예제
LangChain은 문서 로더 및 텍스트 분할기를 제공합니다. 이 예제에서는 PDF를 로드하고, 토큰 수를 확인하고, 텍스트 분할자를 설정하는 방법을 보여 줍니다. 토큰 수를 확인하면 정보를 토대로 청크 크기를 조정할 수 있습니다.
이 예제의 샘플 Notebook은 azure-search-vector-samples 리포지토리에서 찾을 수 있습니다.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
출력은 PDF의 200개 문서 또는 페이지를 나타냅니다.
이러한 페이지에 대한 예상 토큰 수를 가져오려면 TikToken을 사용합니다.
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
출력은 페이지에 토큰이 0개인 페이지가 없고, 페이지당 평균 토큰 길이가 189개 토큰이고, 모든 페이지의 최대 토큰 수가 1,583개임을 나타냅니다.
평균 및 최대 토큰 크기를 알면 정보를 토대로 청크 크기를 설정할 수 있습니다. 표준 권장 사항인 500자가 겹치는 2,000자를 사용할 수 있지만, 샘플 문서의 토큰 수를 고려한다면 이 경우 문자 수를 더 낮추는 것이 좋습니다. 실제로 너무 큰 겹침 값을 설정하면 겹침이 전혀 나타나지 않을 수 있습니다.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
두 개의 연속 청크에 대한 출력은 첫 번째 청크에서 두 번째 청크에 겹치는 텍스트를 보여 줍니다. 가독성을 위해 출력을 약간 편집했습니다.
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
사용자 지정 기술
고정 크기 청크 및 포함 생성 샘플은 Azure OpenAI 포함 모델을 사용하여 청크 및 벡터 포함 생성을 모두 보여 줍니다. 이 샘플에서는 Power Skills 리포지토리에서 Azure AI 검색 사용자 지정 기술을 사용하여 청크 단계를 래핑합니다.