복제본 및 인스턴스
이 문서에서는 상태 저장 서비스의 복제본과 상태 비저장 서비스의 인스턴스 수명 주기에 대한 개요를 제공합니다.
상태 비저장 서비스의 인스턴스
상태 비저장 서비스의 인스턴스는 클러스터의 한 노드에서 실행되는 서비스 논리의 사본입니다. 파티션 내 인스턴스는 해당 InstanceId로 고유하게 식별됩니다. 다음 다이어그램에서 인스턴스 수명 주기가 모델링됩니다.
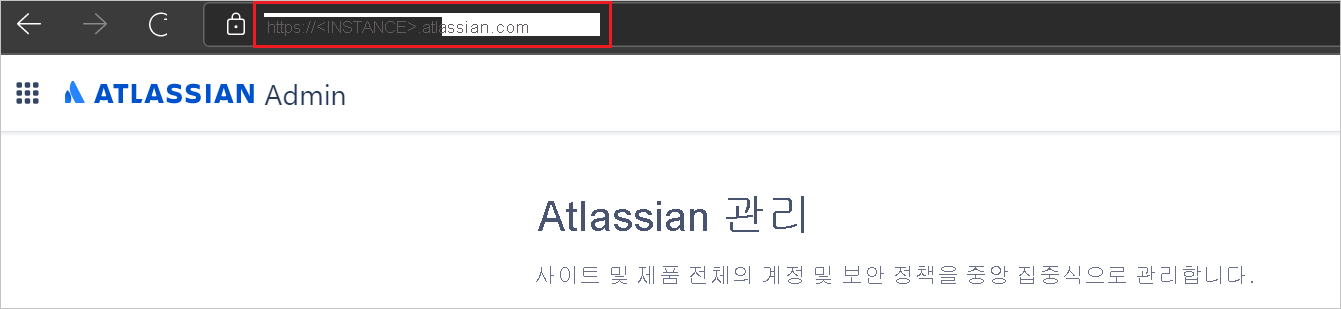
InBuild(IB), 빌드 중
클러스터 리소스 관리자가 인스턴스 배치를 결정하면 해당 인스턴스가 이 수명 주기 상태가 됩니다. 노드에서 인스턴스가 시작됩니다. 애플리케이션 호스트가 시작되고, 인스턴스가 생성된 후 열립니다. 시작이 완료되면 인스턴스가 준비됨 상태로 전환됩니다.
이 인스턴스에 대한 애플리케이션 호스트 또는 노드가 충돌할 경우 삭제됨 상태로 전환됩니다.
Ready(RD), 준비됨
준비됨 상태에서는 인스턴스가 노드에서 시작되어 실행 중입니다. 이 인스턴스가 신뢰할 수 있는 서비스라면 RunAsync가 호출되었습니다.
이 인스턴스에 대한 애플리케이션 호스트 또는 노드가 충돌할 경우 삭제됨 상태로 전환됩니다.
Closing(CL), 닫는 중
닫는 중 상태에서는 Azure Service Fabric이 이 노드에서의 인스턴스 종료를 처리 중입니다. 이 종료는 애플리케이션 업그레이드, 부하 분산, 서비스 삭제 등, 여러 가지 원인으로 야기될 수 있습니다. 종료가 완료되면 삭제됨 상태로 전환됩니다.
Dropped(DD), 삭제됨
삭제됨 상태에서는 인스턴스가 더 이상 노드에서 실행되지 않습니다. 이 시점에서 Service Fabric은 해당 인스턴스에 대한 메타데이터를 유지 관리합니다(결과적으로는 역시 삭제됨).
참고 항목
어느 상태에서나 Remove-ServiceFabricReplica의 ForceRemove 옵션을 사용하여 삭제됨 상태로 전환할 수 있습니다.
상태 저장 서비스 복제본
상태 저장 서비스의 복제본은 클러스터의 한 노드에서 실행되는 서비스 논리의 사본입니다. 또한 복제본은 해당 서비스의 상태 사본을 유지 관리합니다. 상태 저장 복제본의 수명 주기와 동작을 설명하는 데는 다음과 같은 두 가지 개념이 관련되어 있습니다.
- 복제본 수명 주기
- 복제본 역할
다음 논의에서는 지속형 상태 저장 서비스에 대해 설명합니다. 휘발성(또는 메모리 내) 상태 저장 서비스의 경우 다운된 상태와 삭제된 상태는 동일합니다.
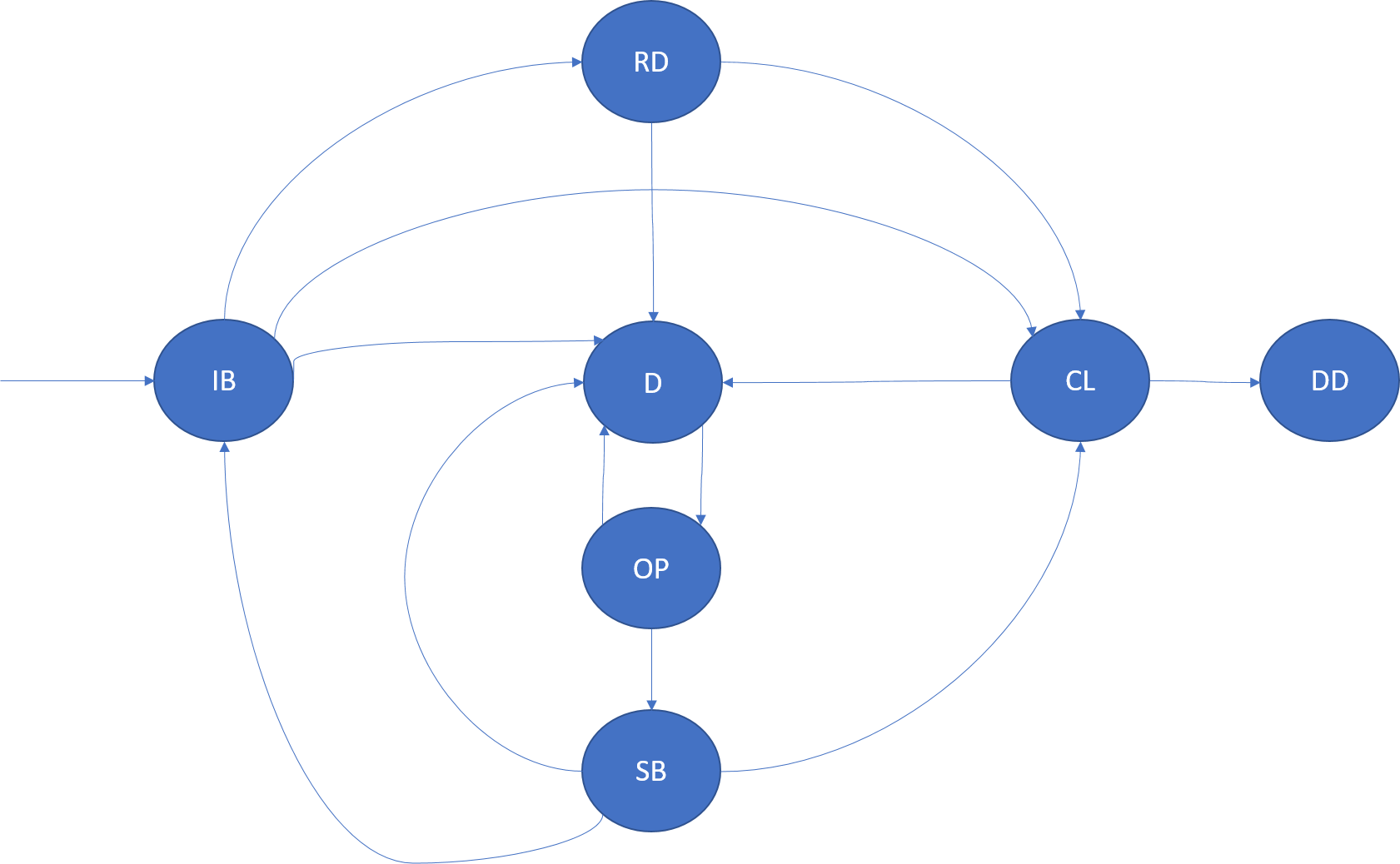
InBuild(IB), 빌드 중
InBuild 복제본은 복제본 세트에 조인하기 위해 만들어지거나 준비 중인 복제본입니다. 복제본 역할에 따라 IB에는 서로 다른 의미 체계가 있습니다.
InBuild 복제본에 대한 애플리케이션 호스트 또는 노드가 충돌할 때 다운 상태로 전환됩니다.
주 InBuild 복제본: 주 InBuild는 파티션에 대한 최초 복제본입니다. 이 복제본은 보통 파티션을 만드는 중에 발생합니다. 파티션의 모든 복제본을 다시 시작하거나 버릴 때도 기본 InBuild 복제본이 부상합니다.
IdleSecondary InBuild 복제본: 클러스터 리소스 관리자가 만든 새 복제본이거나 다운되어 세트에 다시 추가해야 하는 기존 복제본입니다. 이러한 복제본은 복제본 세트에 ActiveSecondary로 조인하고 작업의 쿼럼 승인에 참여하기 전에 주 복제본에 의해 시드 또는 빌드됩니다.
ActiveSecondary InBuild 복제본: 이 상태는 일부 쿼리에서 확인됩니다. 이것은 복제본 세트가 변경되지 않으나 복제본을 빌드해야 하는 상황에서 최적입니다. 복제본 자체는 일반 상태 시스템 전환을 따릅니다(복제본 역할의 섹션에서 설명).
Ready(RD), 준비됨
준비됨 복제본은 작업의 복제 및 쿼럼 승인에 참여하는 복제본입니다. 준비됨 상태는 주 및 활성 보조 복제본에 적용할 수 있습니다.
준비됨 복제본에 대한 애플리케이션 호스트 또는 노드가 충돌할 때 다운 상태로 전환됩니다.
Closing(CL), 닫는 중
다음과 같은 시나리오에서 복제본이 닫는 중 상태가 됩니다.
복제본에 대한 코드 종료: Service Fabric이 복제본에 대해 실행 중인 코드를 종료해야 할 수 있습니다. 여러 가지 이유로 종료해야 할 수 있습니다. 예를 들어 애플리케이션, 패브릭 또는 인프라 업그레이드나 복제본에서 보고된 오류 때문에 종료가 발생할 수 있습니다. 복제본 닫기가 완료되면 복제본이 다운 상태로 전환됩니다. 디스크에 저장된 복제본과 관련한 지속형 상태는 정리되지 않습니다.
클러스터에서 복제본 제거: Service Fabric이 지속형 상태를 제거하고 복제본에 대해 실행 중인 코드를 종료해야 할 수 있습니다. 이 종료는 여러 가지 이유로(예: 부하 분산) 발생할 수 있습니다.
Dropped(DD), 삭제됨
삭제됨 상태에서는 인스턴스가 더 이상 노드에서 실행되지 않습니다. 노드에 남은 상태도 없습니다. 이 시점에서 Service Fabric은 해당 인스턴스에 대한 메타데이터를 유지 관리합니다(결과적으로는 역시 삭제됨).
Down(D), 다운
다운 상태에서는 복제본 코드가 실행되지 않지만 해당 노드에 해당 복제본의 지속형 상태가 유지됩니다. 노드 다운, 복제본 코드 충돌, 애플리케이션 업그레이드, 복제본 오류 등, 여러 사유로 복제본이 다운될 수 있습니다.
다운 복제본은 노드에서 업그레이드가 완료된 경우 등, 필요에 따라 Service Fabric에서 열립니다.
다운 상태에서 복제본 역할은 관련이 없습니다.
Opening(OP), 여는 중
Service Fabric이 복제본을 다시 불러와야 할 경우 다운 복제본이 여는 중 상태가 됩니다. 예를 들어 애플리케이션에 대한 코드 업그레이드가 노드에서 완료된 후에 이 상태가 될 수 있습니다.
여는 중 복제본에 대한 애플리케이션 호스트 또는 노드가 충돌할 때 다운 상태로 전환됩니다.
여는 중 상태에서 복제본 역할은 관련이 없습니다.
StandBy(SB), 대기
StandBy 복제본은 다운되었다가 열린 지속형 서비스의 복제본입니다. 이 복제본은 복제본 세트에 다른 복제본을 추가해야 할 때 Service Fabric에서 사용할 수 있습니다(복제본이 이미 상태의 일부이며 빌드 프로세스가 더 빠르기 때문). StandByReplicaKeepDuration이 만료된 후 대기 복제본을 버립니다.
대기 복제본에 대한 애플리케이션 호스트 또는 노드가 충돌할 때 다운 상태로 전환됩니다.
대기 상태에서 복제본 역할은 관련이 없습니다.
참고 항목
다운되거나 삭제되지 않은 모든 복제본을 가동된다고 간주합니다.
참고 항목
어느 상태에서나 Remove-ServiceFabricReplica의 ForceRemove 옵션을 사용하여 삭제됨 상태로 전환할 수 있습니다.
복제본 역할
복제본의 역할은 복제본 세트에서의 기능을 결정합니다.
- Primary(P): 복제본 세트에서 읽기 및 쓰기 작업의 수행을 담당하는 하나의 주 복제본이 있습니다.
- ActiveSecondary(S): 주 데이터베이스에서 상태 업데이트를 수신하여 적용하고 승인을 다시 전송하는 복제본입니다. 복제본 세트에 여러 활성 보조 복제본이 있습니다. 이러한 활성 보조 복제본의 수는 서비스가 처리할 수 있는 오류 수를 결정합니다.
- IdleSecondary (I): 이러한 복제본은 주 복제본에 의해 작성됩니다. 먼저 주 복제본에서 상태를 수신해야 활성 보조 복제본으로 승격될 수 있습니다.
- None(N): 이 복제본은 복제본 세트에서 역할이 없습니다.
- Unknown(U): 복제본이 Service Fabric에서 ChangeRole API 호출을 수신하기 전의 최초 역할입니다.
다음 다이어그램은 복제본 역할 전환과, 발생할 수 있는 몇 가지 시나리오 예제를 설명합니다.
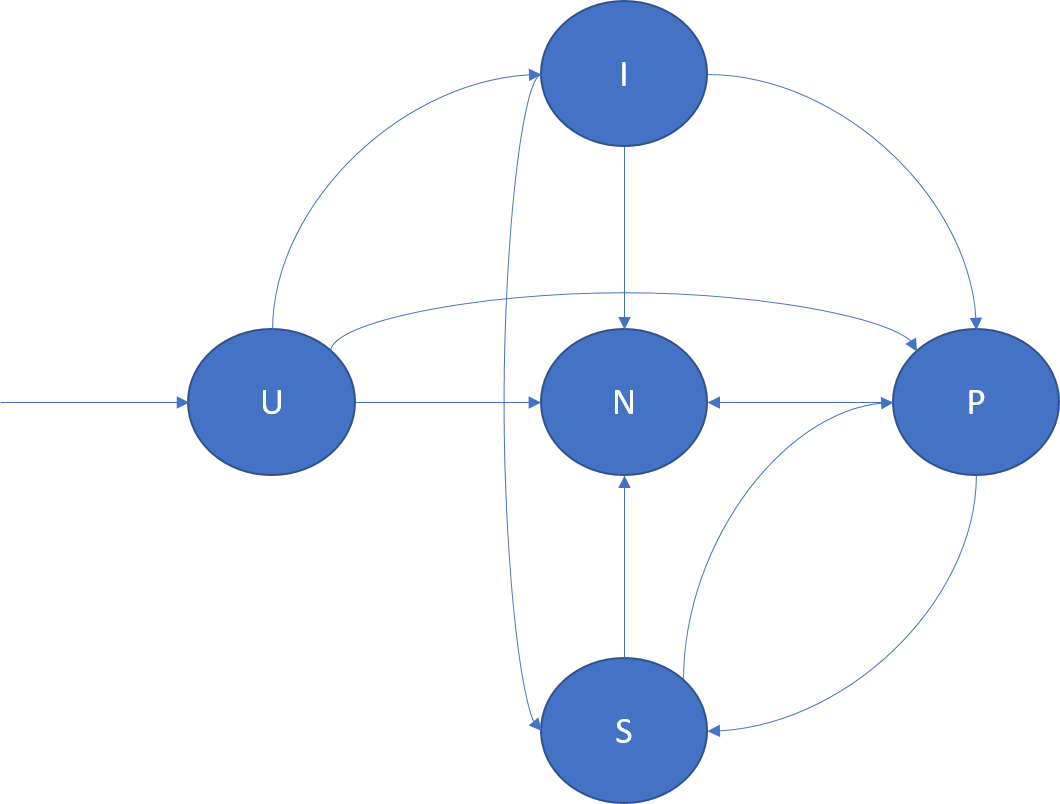
- U -> P: 새 주 복제본 만들기
- U -> I: 새 유휴 복제본 만들기
- U -> N: 대기 복제본 삭제
- I -> S: 유휴 보조 복제본을 활성 보조로 승격하여 해당 승인을 쿼럼에 참여
- I -> P: 유휴 보조 복제본을 주 복제본으로 승격. 이것은 유휴 보조가 주 복제본을 정확하게 대체할 때 특수한 재구성에서 발생할 수 있습니다.
- I -> N: 유휴 보조 복제본 삭제
- S -> P: 활성 보조 복제본을 주 복제본으로 승격. 이것은 주 복제본의 장애 조치나, 클러스터 리소스 관리자가 주 복제본 이동을 시작했을 때 발생할 수 있습니다. 예를 들어 애플리케이션 업그레이드 또는 부하 분산의 결과로 발생할 수 있습니다.
- S -> N: 활성 보조 복제본 삭제
- P -> S: 주 복제본 수준 내리기. 이것은 클러스터 리소스 관리자가 주 복제본 이동을 시작했을 때 발생할 수 있습니다. 예를 들어 애플리케이션 업그레이드 또는 부하 분산의 결과로 발생할 수 있습니다.
- P -> N: 주 복제본 삭제
참고 항목
Reliable Actors 및 Reliable Services와 같은 높은 수준의 프로그래밍 모델은 개발자로부터 복제본 역할의 개념을 숨깁니다. 작업자의 경우 역할의 개념은 필요하지 않습니다. 서비스의 경우 대부분의 시나리오에서 크게 간소화됩니다.
다음 단계
Service Fabric 개념에 대한 자세한 내용은 다음 문서를 참조하세요.