저장소 공간 다이렉트를 실행하는 Azure Virtual Machines를 다른 지역에 복제
이 문서에서는 스토리지 공간을 직접 실행하는 Azure Virtual Machines의 재해 복구를 사용하도록 설정하는 방법을 설명합니다.
참고 항목
스토리지 공간 다이렉트 클러스터에는 크래시 일관성 복구 지점만 지원됩니다.
S2D(스토리지 공간 다이렉트)는 Azure에서 게스트 클러스터를 만드는 방법을 제공하는 소프트웨어 정의 스토리지입니다. Microsoft Azure의 게스트 클러스터는 IaaS 가상 머신으로 구성된 장애 조치(failover) 클러스터입니다. 이를 통해 호스트된 가상 머신 워크로드가 게스트 클러스터 전체에서 장애 조치(failover)될 수 있으므로 단일 Azure Virtual Machines가 제공할 수 있는 것보다 애플리케이션에 대해 더 높은 가용성 SLA를 달성할 수 있습니다. 이는 가상 머신이 SQL 또는 스케일 아웃 파일 서버와 같은 중요한 애플리케이션을 호스팅하는 시나리오에 유용합니다.
스토리지 공간 다이렉트를 사용한 재해 복구
일반적인 시나리오에서는 스케일 아웃 파일 서버와 같은 애플리케이션의 복원력을 높이기 위해 Azure에 가상 머신 게스트 클러스터가 있을 수 있습니다. 이렇게 하면 애플리케이션의 고가용성을 높일 수 있지만 모든 지역 수준 장애에 대해 Site Recovery를 사용하여 이러한 애플리케이션을 보호할 수 있습니다. Site Recovery는 데이터를 한 지역에서 다른 Azure 지역으로 복제하고 장애 조치 시 재해 복구 지역에 클러스터를 제공합니다.
다음 다이어그램은 스토리지 공간을 직접 사용하는 2노드 Azure Virtual Machines 장애 조치(failover) 클러스터를 보여 줍니다.
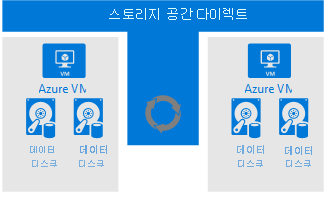
- Windows 장애 조치 클러스터에 두 개의 Azure 가상 머신이 있으며, 각 가상 머신에는 둘 이상의 데이터 디스크가 있습니다.
- S2D는 데이터 디스크의 데이터를 동기화하고 스토리지 풀로 동기화된 스토리지를 제공합니다.
- 스토리지 풀은 장애 조치 클러스터에 CSV(클러스터 공유 볼륨)로 제공됩니다.
- 장애 조치 클러스터에서 데이터 드라이브에 CSV를 사용합니다.
재해 복구 고려 사항
- 클러스터에 대해 클라우드 감시를 설정하는 경우 재해 복구 지역에서 감시를 계속 유지합니다.
- 가상 머신을 원본 지역과 다른 재해 복구 지역의 서브넷으로 장애 조치(failover)하려는 경우 장애 조치 후에 클러스터 IP 주소를 변경해야 합니다. 클러스터의 IP를 변경하려면 Site Recovery 복구 계획 스크립트를 사용해야 합니다.
S2D 클러스터에 대한 Site Recovery 사용
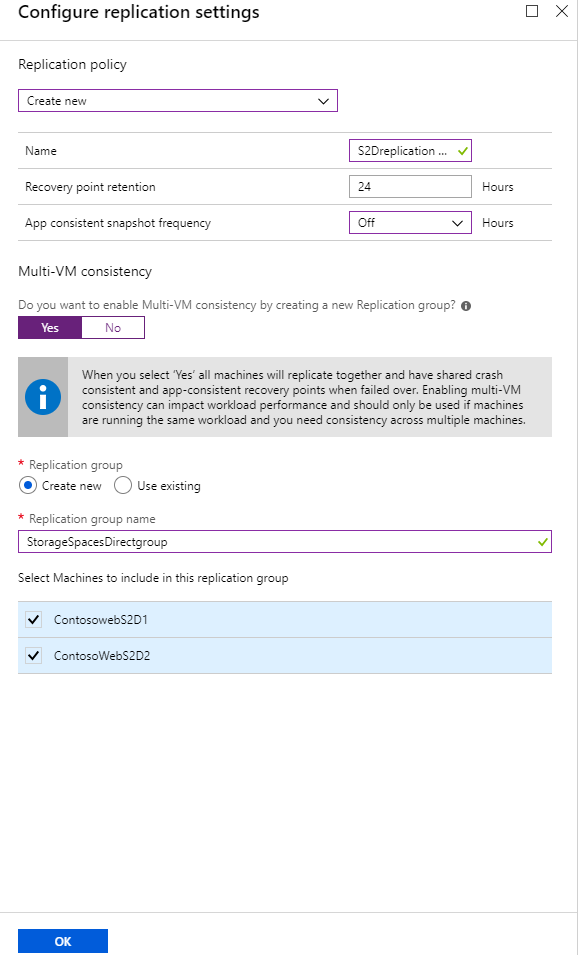
Recovery Services 자격 증명 모음 내에서 +복제 선택
클러스터의 모든 노드를 선택하고 다중 VM 일관성 그룹의 멤버로 만듭니다.
애플리케이션 일관성이 해제*된 복제 정책을 선택합니다(크래시 일관성 지원만 사용 가능).
복제를 사용하도록 설정합니다.
복제된 항목으로 이동합니다. 그러면 두 가상 머신 상태가 모두 표시됩니다.
두 가상 머신이 모두 보호되고 있으며 다중 VM 일관성 그룹의 멤버로도 표시됩니다.

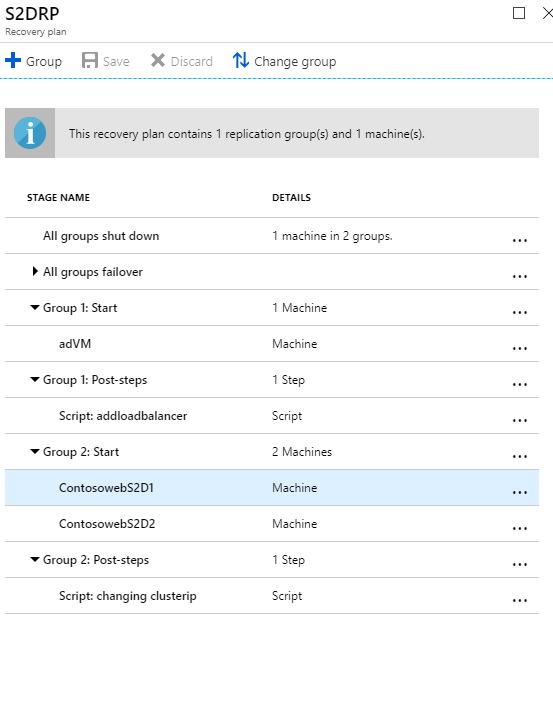
복구 계획 만들기
복구 계획은 장애 조치(failover) 시에 다중 계층 애플리케이션에서 여러 계층의 시퀀싱을 지원합니다. 시퀀싱은 애플리케이션의 일관성을 유지하는 데 도움이 됩니다. 다중 계층 웹 애플리케이션에 대한 복구 계획을 생성할 때는 Site Recovery를 사용하여 복구 계획 만들기에서 설명하는 단계를 수행합니다.
장애 조치 그룹에 가상 머신 추가
- 가상 머신을 추가하여 복구 계획을 만듭니다.
- 가상 머신을 그룹화하려면 사용자 지정을 선택합니다. 기본적으로 모든 가상 머신은
Group 1의 일부입니다.
복구 계획에 스크립트 추가
애플리케이션이 제대로 작동하려면 장애 조치(failover) 후에 또는 테스트 장애 조치(failover) 중에 Azure 가상 머신에서 일부 작업을 수행해야 할 수 있습니다. 일부 장애 조치(failover) 사후 작업은 자동화할 수 있습니다. 예를 들어 여기서는 부하 분산 장치를 연결하고 클러스터 IP를 변경합니다.
가상 머신의 장애 조치
Site Recovery 복구 계획을 사용하여 가상 머신의 두 노드를 모두 장애 조치(failover)해야 합니다.
테스트 장애 조치(failover) 실행
- Azure Portal에서 Recovery Services 자격 증명 모음을 선택합니다.
- 만든 복구 계획을 선택합니다.
- 테스트 장애 조치를 선택합니다.
- 테스트 장애 조치(failover) 프로세스를 시작하려면 복구 지점과 Azure 가상 네트워크를 선택합니다.
- 보조 환경이 가동 중인 경우 유효성 검사를 수행할 수 있습니다.
- 유효성 검사가 완료되면 장애 조치(failover) 환경을 정리하기 위해 테스트 장애 조치(failover) 정리를 선택합니다.
자세한 내용은 Site Recovery에서 Azure로 테스트 장애 조치(failover)를 참조하세요.
장애 조치(Failover) 실행
- Azure Portal에서 Recovery Services 자격 증명 모음을 선택합니다.
- SAP 애플리케이션용으로 생성한 복구 계획을 선택합니다.
- 장애 조치(failover)를 선택합니다.
- 복구 지점을 선택하여 장애 조치(failover) 프로세스를 시작합니다.
자세한 내용은 Site Recovery에서 장애 조치(failover)를 참조하세요.
다음 단계
- 장애 복구 실행에 대해 자세히 알아봅니다.