Synapse SQL 풀에서 복제된 테이블을 사용하기 위한 디자인 지침
이 문서는 Synapse SQL 풀 스키마로 복제 테이블을 디자인하기 위한 권장 사항을 제공합니다. 이러한 권장 사항을 사용하여 데이터 이동 및 쿼리 복잡성을 줄여서 쿼리 성능을 향상시킵니다.
필수 조건
이 문서에서는 사용자가 SQL 풀의 데이터 배포 및 데이터 이동 개념에 익숙하다고 가정합니다. 자세한 내용은 아키텍처 문서를 참조하세요.
테이블 디자인의 일환으로 데이터 및 데이터가 쿼리되는 방식에 대해 최대한 많이 이해하는 것이 좋습니다. 예를 들어 다음 질문을 고려합니다.
- 테이블이 얼마나 큰가요?
- 테이블을 얼마나 자주 새로 고치나요?
- SQL 풀에 팩트 및 차원 테이블이 있나요?
복제 테이블이란?
복제 테이블에는 각 Compute 노드에서 액세스할 수 있는 테이블의 전체 복사본이 있습니다. 테이블을 복제하면 조인 또는 집계 전에 컴퓨팅 노드 간에 데이터를 전송하지 않아도 됩니다. 테이블에 여러 복사본이 있으므로 복제 테이블은 테이블 크기가 2GB 미만으로 압축되어 있을 때 가장 효과적입니다. 2GB는 하드 제한이 아닙니다. 데이터가 정적이고 변경되지 않는 경우 더 큰 테이블을 복제할 수 있습니다.
다음은 각 Compute 노드에서 액세스할 수 있는 복제 테이블을 보여주는 다이어그램입니다. SQL 풀에서 복제 테이블은 각 컴퓨팅 노드의 배포 데이터베이스로 완벽하게 복사됩니다.

복제 테이블은 별모양 스키마의 차원 테이블에 효과적입니다. 일반적으로 차원 테이블은 차원 테이블과 다르게 배포되는 팩트 테이블에 조인됩니다. 차원은 대개 여러 복사본을 저장하고 유지 관리하기에 적당한 크기입니다. 차원에는 고객 이름 및 주소, 제품 세부 정보와 같이 느리게 변하는 설명 데이터가 저장됩니다. 느리게 변하는 데이터의 특성으로 인해 복제 테이블을 유지 관리하는 경우가 줄어듭니다.
복제 테이블 사용을 고려하는 것이 좋은 경우:
- 행의 수에 관계없이 디스크의 테이블 크기가 2GB미만입니다. 테이블 크기를 알아보려면 DBCC PDW_SHOWSPACEUSED 명령을 사용하세요.
DBCC PDW_SHOWSPACEUSED('ReplTableCandidate'). - 복제 테이블이 아니면 데이터 이동이 필요한 조인에 사용됩니다. 라운드 로빈 테이블로의 해시 분산 테이블과 같이 동일한 열에 배포되지 않은 테이블을 조인하는 경우 쿼리를 완료하려면 데이터 이동이 필요합니다. 테이블 중 하나가 작은 경우 복제된 테이블을 고려합니다. 대부분의 경우 라운드 로빈 테이블 대신 복제 테이블을 사용하는 것이 좋습니다. 쿼리 계획에서 데이터 이동 작업을 보려면 sys.dm_pdw_request_steps를 사용합니다. BroadcastMoveOperation은 복제된 테이블을 사용하여 제거할 수 있는 일반적인 데이터 이동 작업입니다.
복제 테이블이 최상의 쿼리 성능을 얻을 수 없는 경우:
- 테이블에 삽입, 업데이트 및 삭제 작업이 빈번합니다. DML(데이터 조작 언어) 작업에는 복제 테이블 다시 빌드가 필요합니다. 다시 빌드가 빈번하면 성능을 저하시킬 수 있습니다.
- SQL 풀이 크기 조정되는 경우가 많습니다. SQL 풀의 크기를 조정하면 복제된 테이블을 다시 빌드하는 컴퓨팅 노드 수가 변경됩니다.
- 테이블에는 다수의 열이 있지만 데이터 작업은 대개 작은 수의 열에만 액세스합니다. 이 시나리오에서는 전체 테이블을 복제하는 대신 테이블을 분산한 다음, 자주 액세스하는 열의 인덱스를 만드는 것이 보다 효과적일 수 있습니다. 쿼리에 데이터 이동이 필요하면 SQL 풀은 요청된 열의 데이터만 이동합니다.
팁
인덱싱 및 복제된 테이블에 대한 자세한 지침은 Azure Synapse Analytics의 전용 SQL 풀(이전의 SQL DW) 참고 자료를 참조하세요.
단순 쿼리 조건자로 복제 테이블 사용
테이블 분산 또는 복제를 선택하기 전에 테이블에 실행할 쿼리 유형에 대해 생각해보세요. 가능하면,
- 같음 또는 같지 않음과 같은 단순 쿼리 조건자를 사용한 쿼리에는 복제 테이블을 사용합니다.
- LIKE 또는 NOT LIKE와 같은 복잡한 쿼리 조건자를 사용한 쿼리에는 분산 테이블을 사용합니다.
CPU를 많이 사용하는 쿼리는 모든 Compute 노드에 작업이 분산되면 성능이 가장 좋아집니다. 예를 들어 테이블의 각 행에서 계산을 실행하는 쿼리는 복제 테이블에 비해 분산 테이블에서 성능이 더 높습니다. 복제 테이블은 각 Compute 노드에 전체가 저장되므로 복제 테이블에 대해 CPU를 많이 사용하는 쿼리는 각 Compute 노드의 전체 테이블에 대해 실행됩니다. 추가 계산은 쿼리 성능을 저하시킬 수 있습니다.
예를 들어 이 쿼리에는 복잡한 조건자가 있습니다. 이 쿼리는 데이터가 복제 테이블이 아니라 분산 테이블에 있을 때 실행 속도가 빨라집니다. 이 예에서 데이터는 라운드 로빈 분산 테이블일 수 있습니다.
SELECT EnglishProductName
FROM DimProduct
WHERE EnglishDescription LIKE '%frame%comfortable%';
기존의 라운드 로빈 테이블을 복제 테이블로 변환
라운드 로빈 테이블이 이미 있는 경우 이 문서에 설명된 조건을 충족한다면 복제 테이블로 변환하는 것이 좋습니다. 복제 테이블은 데이터 이동의 필요성을 없애기 때문에 라운드 로빈 테이블보다 성능을 향상시킵니다. 라운드 로빈 테이블은 조인을 위해 데이터 이동이 항상 필요합니다.
이 예제는 CTAS를 사용하여 DimSalesTerritory 테이블을 복제 테이블로 변경합니다. 이 예제는 DimSalesTerritory가 해시 분산이거나 라운드 로빈이거나 상관없이 작동합니다.
CREATE TABLE [dbo].[DimSalesTerritory_REPLICATE]
WITH
(
HEAP,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory]
OPTION (LABEL = 'CTAS : DimSalesTerritory_REPLICATE')
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[DimSalesTerritory_REPLICATE] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
라운드 로빈 대비 복제에 대한 쿼리 성능 예제
복제 테이블은 각각의 Compute 노드에 전체 테이블이 이미 존재하기 때문에 조인을 위해 데이터를 이동할 필요가 없습니다. 차원 테이블이 라운드 로빈 분산이면 조인은 각각의 Compute 노드에 차원 테이블 전체를 복사합니다. 데이터를 이동하려면 쿼리 계획에 BroadcastMoveOperation이라는 작업이 포함됩니다. 이런 유형의 데이터 이동 작업은 쿼리 성능을 저하시키며 복제 테이블을 사용하면 필요가 없어집니다. 쿼리 계획 단계를 보려면 sys.dm_pdw_request_steps 시스템 카탈로그 보기를 사용합니다.
예를 들어 AdventureWorks 스키마에 대한 다음 쿼리에서 FactInternetSales 테이블은 해시 분산입니다. DimDate 및 DimSalesTerritory 테이블은 작은 차원 테이블입니다. 이 쿼리는 회계 연도 2004년에 대한 북아메리카 지역의 총 매출을 반환합니다.
SELECT [TotalSalesAmount] = SUM(SalesAmount)
FROM dbo.FactInternetSales s
INNER JOIN dbo.DimDate d
ON d.DateKey = s.OrderDateKey
INNER JOIN dbo.DimSalesTerritory t
ON t.SalesTerritoryKey = s.SalesTerritoryKey
WHERE d.FiscalYear = 2004
AND t.SalesTerritoryGroup = 'North America'
DimDate 및 DimSalesTerritory를 라운드 로빈 테이블로 다시 만들었습니다. 그에 따라 쿼리에 다수의 브로드캐스트 이동 작업이 포함된 다음과 같은 쿼리 계획이 표시되었습니다.
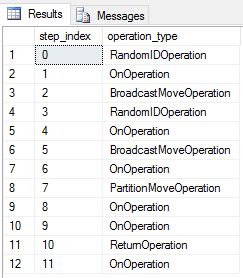
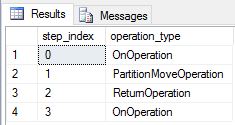
DimDate 및 DimSalesTerritory를 복제 테이블로 다시 만들고 쿼리를 다시 실행했습니다. 결과 쿼리 계획은 훨씬 더 짧으며 브로드캐스트 이동이 하나도 없습니다.
복제 테이블 수정에 대한 성능 고려 사항
SQL 풀은 테이블의 마스터 버전을 유지하여 복제 테이블을 구현합니다. 마스터 버전을 각 컴퓨팅 노드에 있는 첫 번째 배포 데이터베이스에 복사합니다. 변경 사항이 있는 경우 마스터 버전이 먼저 업데이트된 다음 각 컴퓨팅 노드의 테이블이 다시 작성됩니다. 복제 테이블의 다시 빌드에는 각 Compute 노드로 테이블을 복사한 다음, 인덱스를 빌드하는 것이 포함됩니다. 예를 들어 DW2000c의 복제된 테이블에는 5개의 데이터 복사본이 있습니다. 각 Compute 노드의 마스터 복사본 및 전체 복사본입니다. 모든 데이터는 배포 데이터베이스에 저장됩니다. SQL 풀은 더 빠른 데이터 수정 문 및 유연한 크기 조정 작업을 지원하기 위해 이 모델을 사용합니다.
비동기 다시 빌드는 다음 이후에 복제된 테이블에 대한 첫 번째 쿼리에 의해 트리거됩니다.
- 데이터가 로드되었거나 수정된 후
- Synapse SQL 인스턴스가 다른 수준으로 확장됩니다.
- 테이블 정의가 업데이트된 후
다시 빌드가 필요하지 않은 경우:
- 작업 일시 중지 후
- 작업 일시 다시 시작 후
다시 빌드는 데이터가 수정된 직후 발생하지 않습니다. 대신 쿼리가 테이블에서 처음 선택하면 다시 빌드가 트리거됩니다. 데이터가 각 Compute 노드에 비동기적으로 복사되는 동안 다시 작성을 트리거한 쿼리가 테이블의 마스터 버전에서 즉시 읽습니다. 데이터 복사가 완료될 때까지 후속 쿼리는 테이블의 마스터 버전을 계속 사용합니다. 또 다른 다시 작성을 수행하는 복제된 테이블에 대해 어떠한 동작이 발생하는 경우 데이터 복사는 무효화되고 다음 select 문은 데이터의 다시 복사를 트리거합니다.
신중하게 인덱스 사용
표준 인덱싱 작업은 복제 테이블에 적용됩니다. SQL 풀은 다시 빌드의 일환으로 각 복제 테이블 인덱스를 다시 빌드합니다. 인덱스는 해당 성능이 인덱스를 다시 빌드하는 비용보다 높은 경우에만 사용합니다.
Batch 데이터 로드
복제 테이블로 데이터를 로드하는 경우 로드를 함께 일괄 처리하여 다시 빌드를 최소화하는 것이 좋습니다. select 문을 실행하기 전에 일괄 처리된 모든 로드를 수행합니다.
예를 들어 다음 부하 패턴은 4개의 원본에서 데이터를 로드하고 4개의 다시 빌드를 호출합니다.
- 원본 1에서 로드.
- Select 문이 다시 빌드 1을 호출.
- 원본 2에서 로드.
- Select 문이 다시 빌드 2를 호출.
- 원본 3에서 로드.
- Select 문이 다시 빌드 3을 호출.
- 원본 4에서 로드.
- Select 문이 다시 빌드 4를 호출.
예를 들어 다음 부하 패턴은 4개의 원본에서 데이터를 로드하지만 다시 빌드를 1개만 호출합니다.
- 원본 1에서 로드.
- 원본 2에서 로드.
- 원본 3에서 로드.
- 원본 4에서 로드.
- Select 문이 다시 빌드를 호출.
일괄 처리 로드 후 복제 테이블 다시 빌드
일관적인 쿼리 실행 시간을 보장하려면 일괄 처리 로드 후 복제된 테이블을 강제로 빌드하는 것이 좋습니다. 그렇지 않으면 첫 번째 쿼리에서 쿼리를 완료하기 위해 계속 데이터를 이동합니다.
'복제된 테이블 캐시 빌드' 작업은 최대 두 개의 작업을 동시에 실행할 수 있습니다. 예를 들어, 5개의 테이블에 대한 캐시를 다시 빌드하려고 시도하는 경우 시스템은 staticrc20(수정할 수 없음)을 활용하여 동시에 2개의 테이블을 빌드합니다. 따라서 노드 전체에서 캐시를 다시 빌드하는 속도가 느려지고 전체 시간이 늘어날 수 있으므로 2GB를 초과하는 대용량 복제 테이블은 사용하지 않는 것이 좋습니다.
다음 쿼리는 sys.pdw_replicated_table_cache_state DMV를 사용하여 수정되었지만 다시 빌드되지 않은 복제 테이블을 나열합니다.
SELECT SchemaName = SCHEMA_NAME(t.schema_id)
, [ReplicatedTable] = t.[name]
, [RebuildStatement] = 'SELECT TOP 1 * FROM ' + '[' + SCHEMA_NAME(t.schema_id) + '].[' + t.[name] +']'
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p
ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady'
AND p.[distribution_policy_desc] = 'REPLICATE'
다시 빌드를 트리거하려면 이전 출력의 각 테이블에서 다음 명령문을 실행합니다.
SELECT TOP 1 * FROM [ReplicatedTable]
참고 항목
캐시되지 않은 복제본(replica)ted 테이블의 통계를 다시 작성하려는 경우 캐시를 트리거하기 전에 통계를 업데이트해야 합니다. 통계를 업데이트하면 캐시가 무효화되므로 시퀀스가 중요합니다.
예: 먼저 UPDATE STATISTICS캐시를 다시 빌드합니다. 다음 예제에서 올바른 샘플은 통계를 업데이트한 다음 캐시의 다시 빌드를 트리거합니다.
-- Incorrect sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
SELECT TOP 1 * FROM [ReplicatedTable]
UPDATE STATISTICS [ReplicatedTable]
END
-- Correct sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
UPDATE STATISTICS [ReplicatedTable]
SELECT TOP 1 * FROM [ReplicatedTable]
END
다시 빌드 프로세스를 모니터링하려면 sys.dm_pdw_exec_requests를 사용할 수 있습니다. 여기서 command는 'BuildReplicatedTableCache'로 시작됩니다. 예시:
-- Monitor Build Replicated Cache
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE command like 'BuildReplicatedTableCache%'
팁
테이블 크기 쿼리를 사용하면 복제된 배포 정책이 있는 테이블과 2GB보다 큰 테이블을 확인할 수 있습니다.
다음 단계
복제 테이블을 만들려면 다음 문 중 하나를 사용합니다.
분산 테이블에 대한 개요는 분산 테이블을 참조하세요.