쿼리 가속을 통해 애플리케이션 및 분석 프레임워크에서 지정된 작업을 수행하는 데 필요한 데이터만 검색하여 데이터 처리를 현저하게 최적화할 수 있습니다. 이렇게 하면 저장된 데이터에 대한 중요한 인사이트를 얻는 데 필요한 시간 및 처리 능력이 줄어듭니다.
개요
쿼리 가속은 필터링 조건자 및 열 프로젝션을 허용합니다. 이를 통해 애플리케이션은 디스크에서 데이터를 읽을 때 행과 열을 필터링할 수 있습니다. 조건자의 조건을 충족하는 데이터만 네트워크를 통해 애플리케이션으로 전송됩니다. 이렇게 하면 네트워크 대기 시간과 컴퓨팅 비용이 줄어듭니다.
SQL을 사용하여 쿼리 가속 요청에서 행 필터 조건자 및 열 프로젝션을 지정할 수 있습니다. 요청은 하나의 파일만 처리합니다. 따라서 join 및 group by 집계와 같은 SQL의 고급 관계형 기능은 지원되지 않습니다. 쿼리 가속은 CSV 및 JSON 형식의 데이터를 각 요청에 대한 입력으로 지원합니다.
쿼리 가속 기능은 Data Lake Storage(계층적 네임스페이스를 사용하도록 설정된 스토리지 계정)로 제한되지 않습니다. 쿼리 가속은 계층 구조 네임스페이스를 사용하도록 설정하지 않는 스토리지 계정의 Blob과 호환됩니다. 즉, 스토리지 계정에 Blob으로 이미 저장한 데이터를 처리할 때 네트워크 대기 시간과 컴퓨팅 비용을 동일하게 줄일 수 있습니다.
클라이언트 애플리케이션에서 쿼리 가속을 사용하는 방법의 예는 Azure Data Lake Storage 쿼리 가속을 사용하여 데이터 필터링을 참조하세요.
데이터 흐름
다음 다이어그램에서는 일반적인 애플리케이션에서 쿼리 가속을 사용하여 데이터를 처리하는 방법을 보여 줍니다.
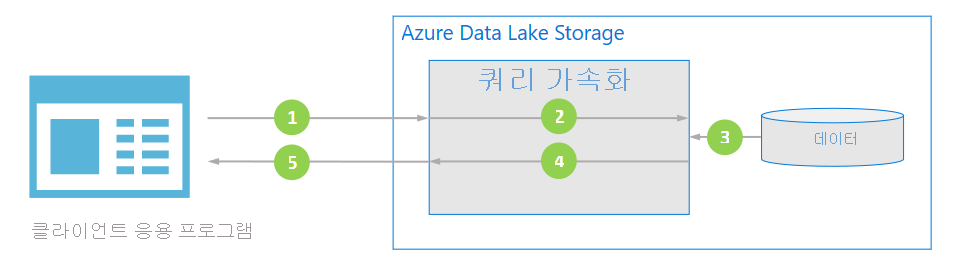
클라이언트 애플리케이션은 조건자 및 열 프로젝션을 지정하여 파일 데이터를 요청합니다.
쿼리 가속은 지정된 SQL 쿼리를 구문 분석하고 작업을 배포하여 데이터를 구문 분석 및 필터링합니다.
프로세서는 디스크에서 데이터를 읽고 해당 형식을 사용하여 데이터를 구문 분석한 다음 지정된 조건자와 열 프로젝션을 적용하여 데이터를 필터링합니다.
쿼리 가속은 분할 응답을 결합하여 클라이언트 애플리케이션으로 다시 스트리밍합니다.
클라이언트 애플리케이션이 스트리밍된 응답을 받아서 구문 분석합니다. 애플리케이션은 다른 데이터를 필터링할 필요가 없으며 원하는 계산 또는 변환을 직접 적용할 수 있습니다.
저렴한 비용으로 성능 향상
쿼리 가속은 애플리케이션에서 전송 및 처리하는 데이터의 양을 줄여 성능을 최적화합니다.
집계된 값을 계산하기 위해 애플리케이션은 일반적으로 파일의 모든 데이터를 검색한 다음 데이터를 로컬로 처리하고 필터링합니다. 분석 워크로드에 대한 입력/출력 패턴을 분석하면 애플리케이션은 일반적으로 지정된 계산을 수행하기 위해 읽은 데이터의 20%만 필요합니다. 이 통계는 파티션 정리와 같은 기술을 적용한 후에도 마찬가지입니다. 즉, 해당 데이터의 80%는 네트워크를 통해 불필요하게 전송되고, 구문 분석되고, 애플리케이션에 의해 필터링된다는 것을 의미합니다. 불필요한 데이터를 제거하도록 설계된 이 패턴은 상당한 컴퓨팅 비용이 발생합니다.
Azure는 처리량과 대기 시간 측면에서 업계 최고의 네트워크를 제공하지만 해당 네트워크를 통해 불필요하게 데이터를 전송하는 것은 여전히 애플리케이션 성능에 큰 영향을 미칩니다. 스토리지 요청 중 원치 않는 데이터를 필터링하면 쿼리 가속을 통해 이 비용을 제거할 수 있습니다.
또한 불필요한 데이터를 구문 분석하고 필터링하는 데 필요한 CPU 부하로 인해 애플리케이션이 작업을 수행하는 데 더 많은 수의 VM을 프로비저닝해야 합니다. 이 컴퓨팅 부하를 쿼리 가속으로 전송하면 애플리케이션에서 상당한 비용 절감을 실현할 수 있습니다.
쿼리 가속의 혜택을 볼 수 있는 애플리케이션
쿼리 가속은 분산 분석 프레임워크 및 데이터 처리 애플리케이션을 위해 설계되었습니다.
Apache Spark 및 Apache Hive와 같은 분산 분석 프레임워크는 프레임워크 내에 스토리지 추상화 계층을 포함합니다. 이러한 엔진에는 사용자 쿼리에 대한 최적의 쿼리 계획을 결정할 때 기본 I/O 서비스 기능에 대한 지식을 통합할 수 있는 쿼리 최적화 프로그램도 포함됩니다. 이러한 프레임워크는 쿼리 가속을 통합하기 시작하고 있습니다. 따라서 이러한 프레임워크의 사용자는 쿼리를 변경하지 않고도 쿼리 대기 시간이 향상되고 총 소유 비용이 낮아질 수 있습니다.
또한 쿼리 가속은 데이터 처리 애플리케이션을 위해 설계되었습니다. 이러한 유형의 애플리케이션은 일반적으로 분석 인사이트로 직접 연결되지 않을 수 있는 대규모 데이터 변환을 수행하므로 항상 설정된 분산 분석 프레임워크를 사용하지는 않습니다. 이러한 애플리케이션은 종종 기본 스토리지 서비스와 더 직접적인 관계가 있으므로 쿼리 가속 등의 기능에서 직접 혜택을 볼 수 있습니다.
애플리케이션이 쿼리 가속을 통합할 수 있는 방법의 예는 Azure Data Lake Storage 쿼리 가속을 사용하여 데이터 필터링을 참조하세요.
가격 책정
Azure Data Lake Storage 서비스 내에서 증가된 컴퓨팅 부하로 인해 쿼리 가속 사용에 대한 가격 모델은 일반 Azure Data Lake Storage 트랜잭션 모델과 다릅니다. 쿼리 가속은 검사되는 데이터의 양과 호출자에게 반환되는 데이터의 양에 대한 비용을 청구합니다. 자세한 내용은 Azure Data Lake Storage 가격 책정을 참조하세요.
청구 모델이 변경되었음에도 불구하고 쿼리 가속의 가격 책정 모델은 훨씬 더 비싼 VM 비용이 감소함에 따라 워크로드의 총 소유 비용을 낮추도록 설계되었습니다.