Parquet 형식으로 Event Hubs에서 데이터 캡처
이 문서에서는 코드 없는 편집기를 사용하여 Parquet 형식으로 Azure Data Lake Storage Gen2 계정에서 Event Hubs의 스트리밍 데이터를 자동으로 캡처하는 방법을 설명합니다.
필수 조건
이벤트 허브가 있는 Azure Event Hubs 네임스페이스 및 캡처된 데이터를 저장할 컨테이너가 있는 Azure Data Lake Storage Gen2 계정. 이러한 리소스는 공개적으로 액세스할 수 있어야 하며 방화벽 뒤에 있거나 Azure Virtual Network에서 보호될 수 없습니다.
이벤트 허브가 없는 경우 빠른 시작: 이벤트 허브 만들기의 지침에 따라 이벤트 허브를 만듭니다.
Data Lake Storage Gen2 계정이 없는 경우 스토리지 계정 만들기의 지침에 따라 계정을 만듭니다.
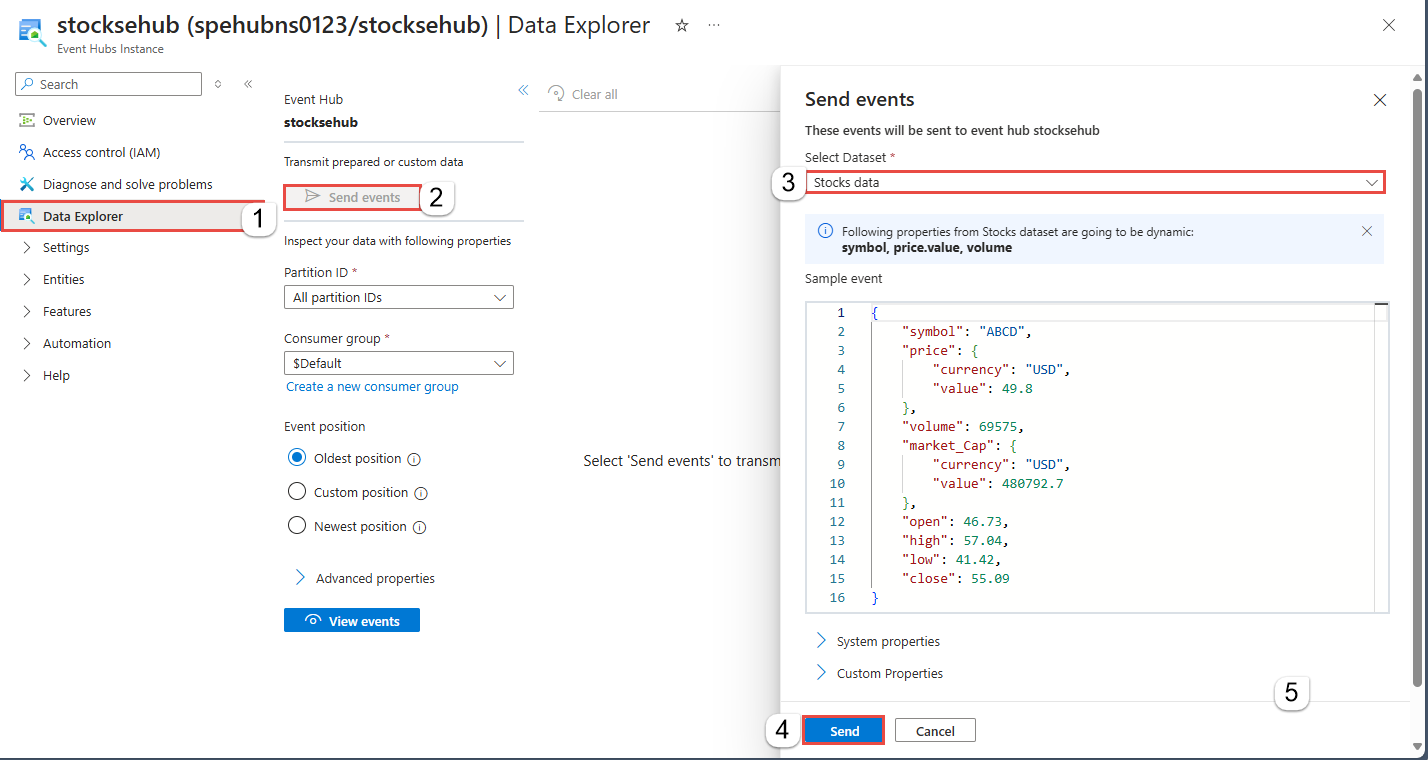
Event Hubs의 데이터는 JSON, CSV 또는 Avro 형식으로 직렬화되어야 합니다. 테스트 목적으로 왼쪽 메뉴에서 데이터 생성(미리 보기)을 선택하고 데이터 세트에서 데이터 보유를 선택한 다음 보내기를 선택합니다.

데이터를 캡처하도록 작업 구성
다음 단계를 사용하여 Azure Data Lake Storage Gen2에서 데이터를 캡처하도록 Stream Analytics 작업을 구성합니다.
Azure Portal에서 이벤트 허브로 이동합니다.
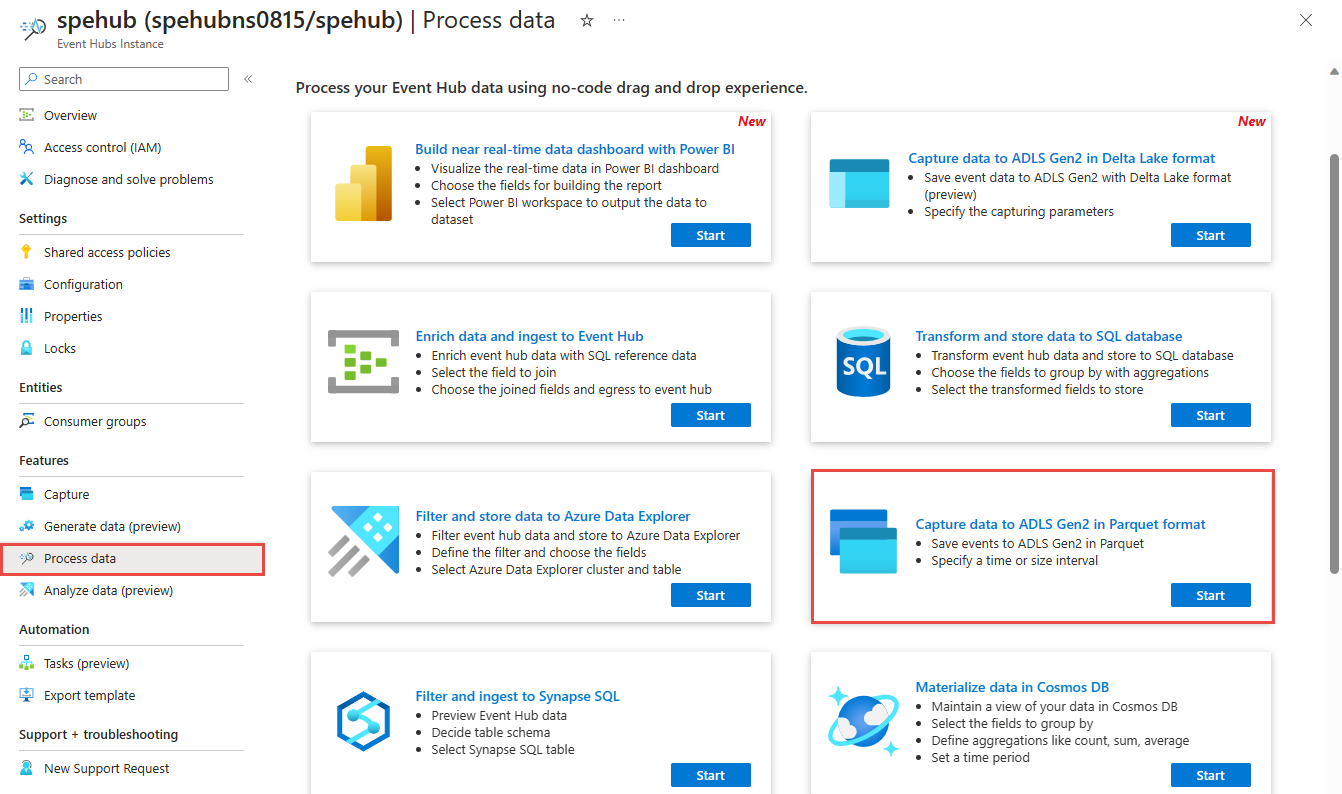
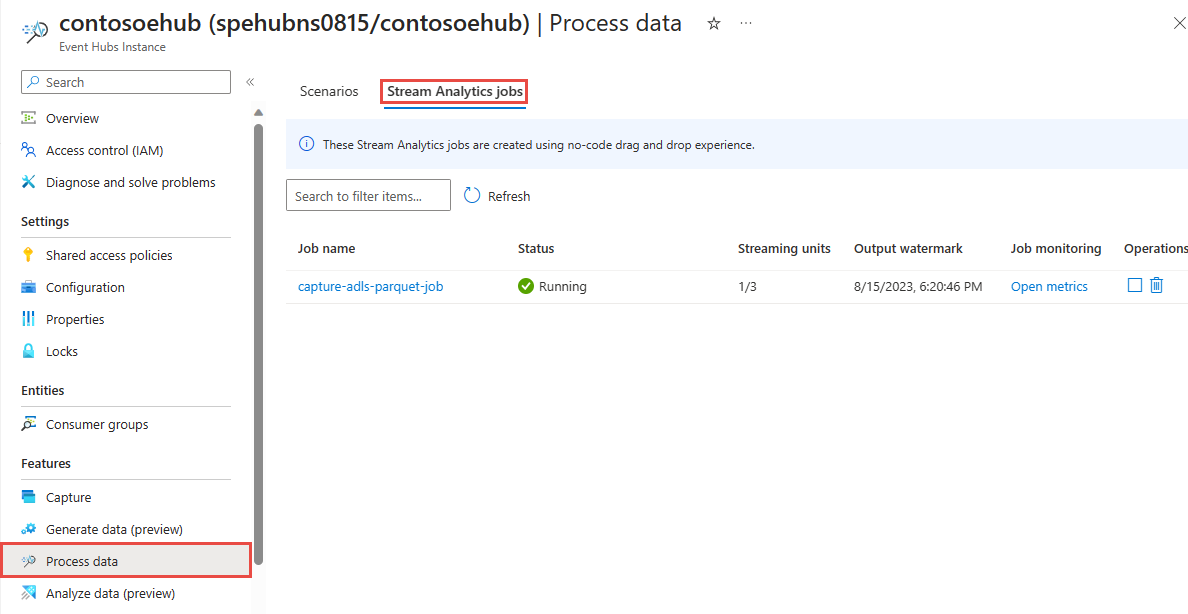
왼쪽 메뉴의 기능 아래에서 데이터 처리를 선택합니다. 그런 다음 Parquet 형식으로 ADLS Gen2에 데이터 캡처 카드에서 시작을 선택합니다.
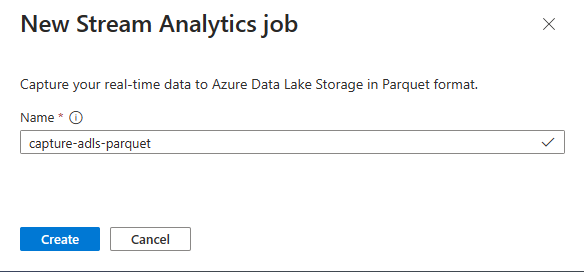
Stream Analytics 작업의 이름을 입력한 다음 만들기를 선택합니다.
Event Hubs에서 데이터의 Serialization 형식 및 작업이 Event Hubs에 연결하는 데 사용할 인증 방법을 지정합니다. 그런 다음 연결을 선택합니다.
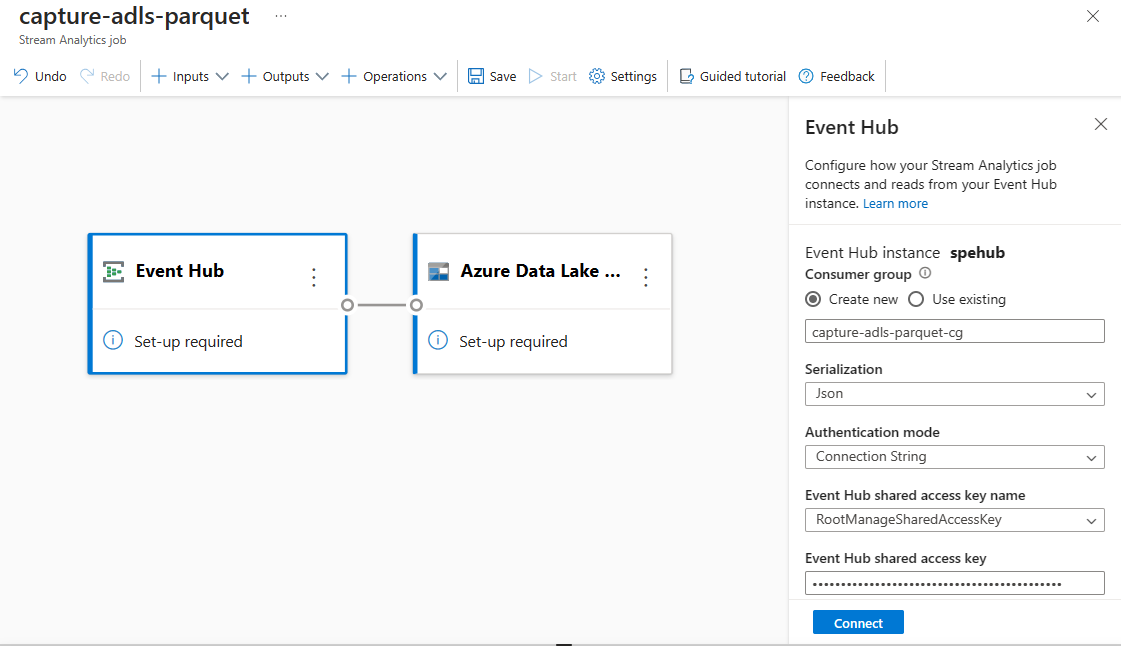
연결이 성공적으로 설정되면 다음이 표시됩니다.
입력 데이터에 나타나는 필드입니다. 필드 추가를 선택하거나 필요에 따라 필드 옆에 있는 세 개의 점 기호를 선택하여 해당 이름을 제거, 이름 바꾸기 또는 변경할 수 있습니다.
다이어그램 뷰 아래 데이터 미리 보기 테이블에 있는 들어오는 데이터의 라이브 샘플. 주기적으로 새로 고칩니다. 스트리밍 미리 보기 일시 중지를 선택하여 샘플 입력의 정적 뷰를 볼 수 있습니다.
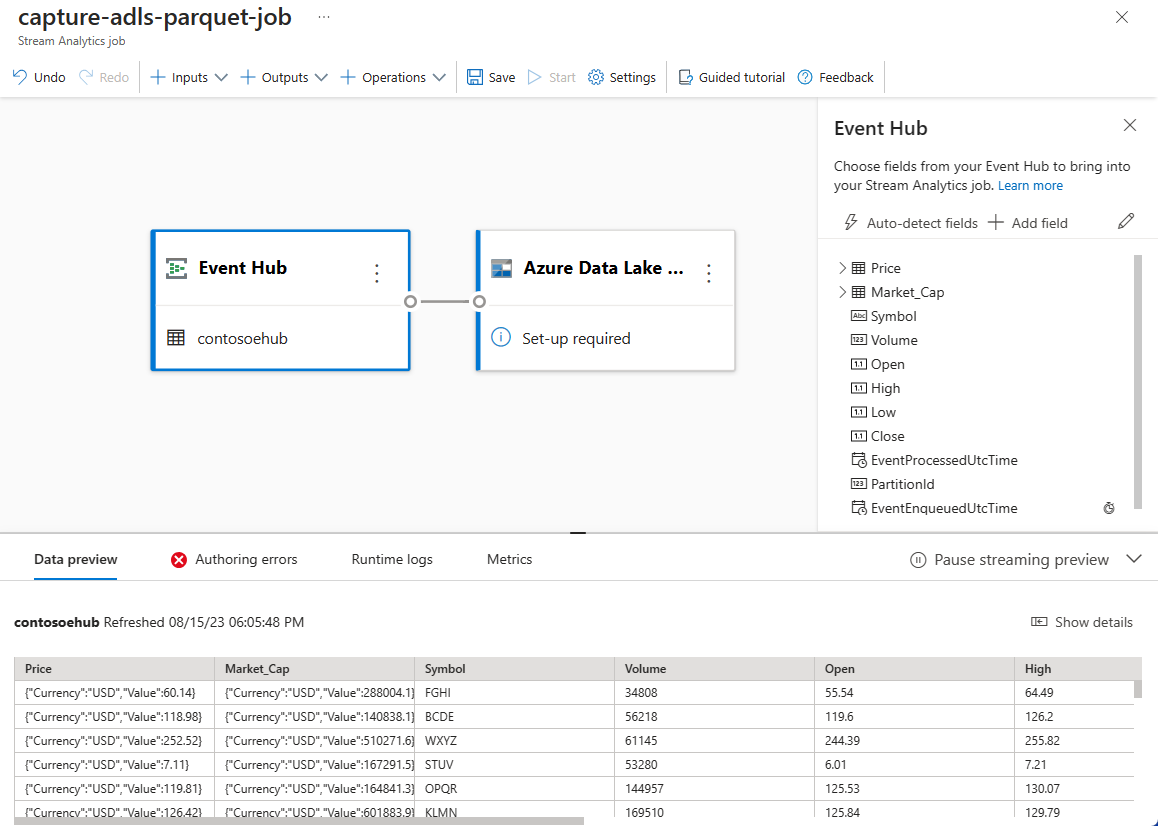
Azure Data Lake Storage Gen2 타일을 선택하여 구성을 편집합니다.
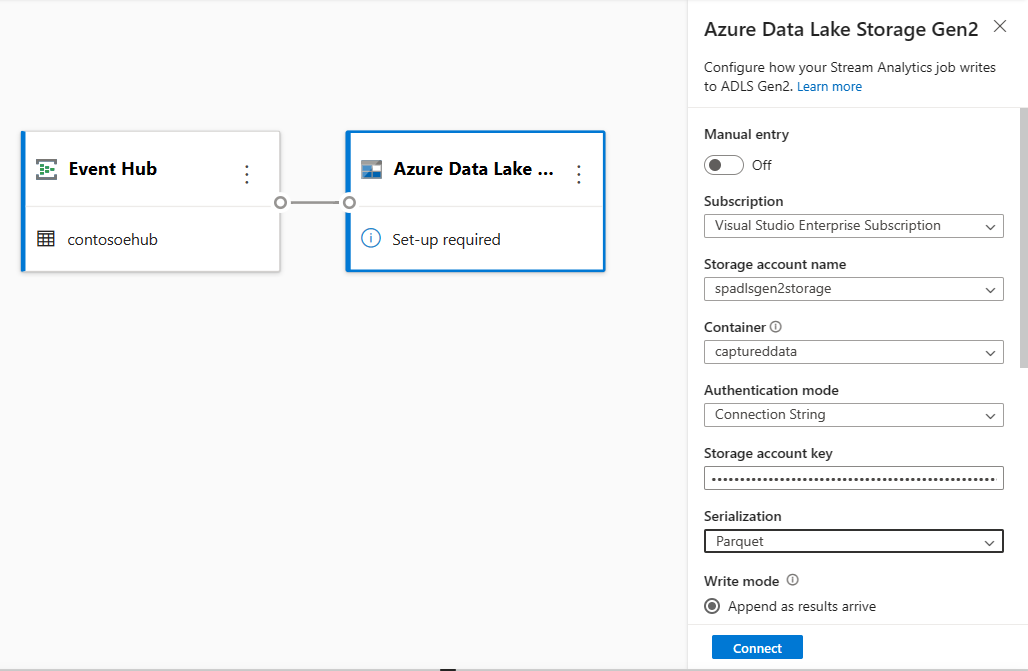
Azure Data Lake Storage Gen2 구성 페이지에서 다음 단계를 수행합니다.
드롭다운 메뉴에서 구독, 스토리지 계정 이름 및 컨테이너를 선택합니다.
구독을 선택하면 인증 방법 및 스토리지 계정 키가 자동으로 채워집니다.
Serialization 형식으로 Parquet을 선택합니다.
스트리밍 Blob의 경우 디렉터리 경로 패턴은 동적 값이어야 합니다. 날짜는
{date}로 참조되는 Blob 파일 경로의 일부여야 합니다. 사용자 지정 경로 패턴에 대한 자세한 내용은 Azure Stream Analytics 사용자 지정 Blob 출력 분할을 참조하세요.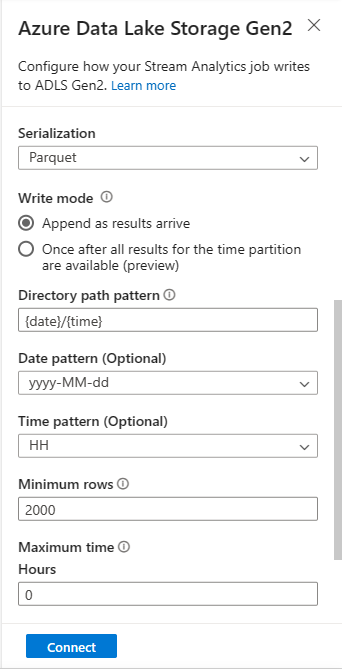
연결을 선택합니다
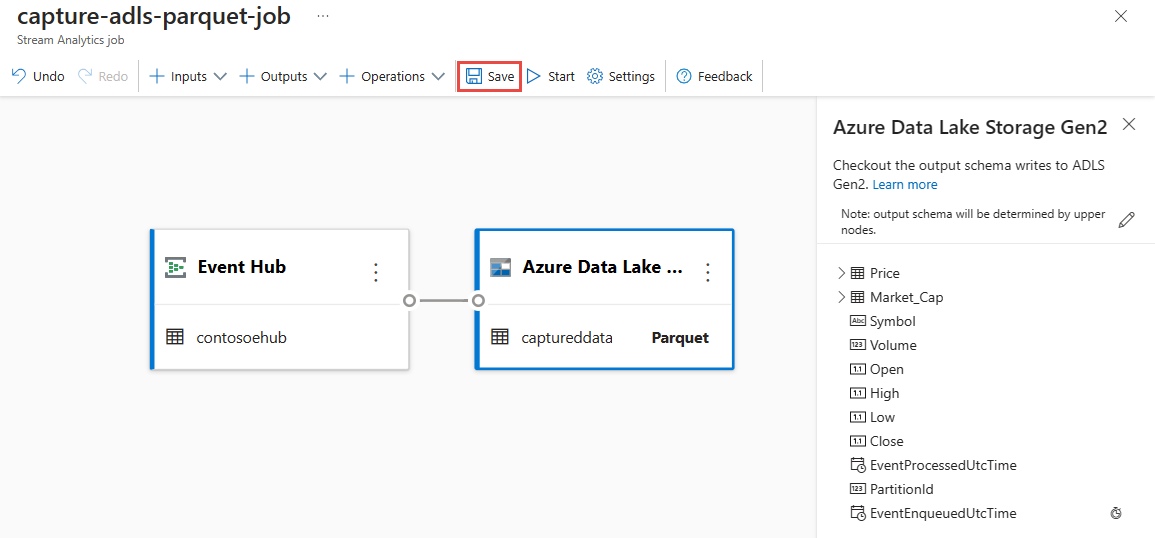
연결이 설정되면 출력 데이터에 있는 필드가 표시됩니다.
명령 모음에서 저장을 선택하여 구성을 저장합니다.
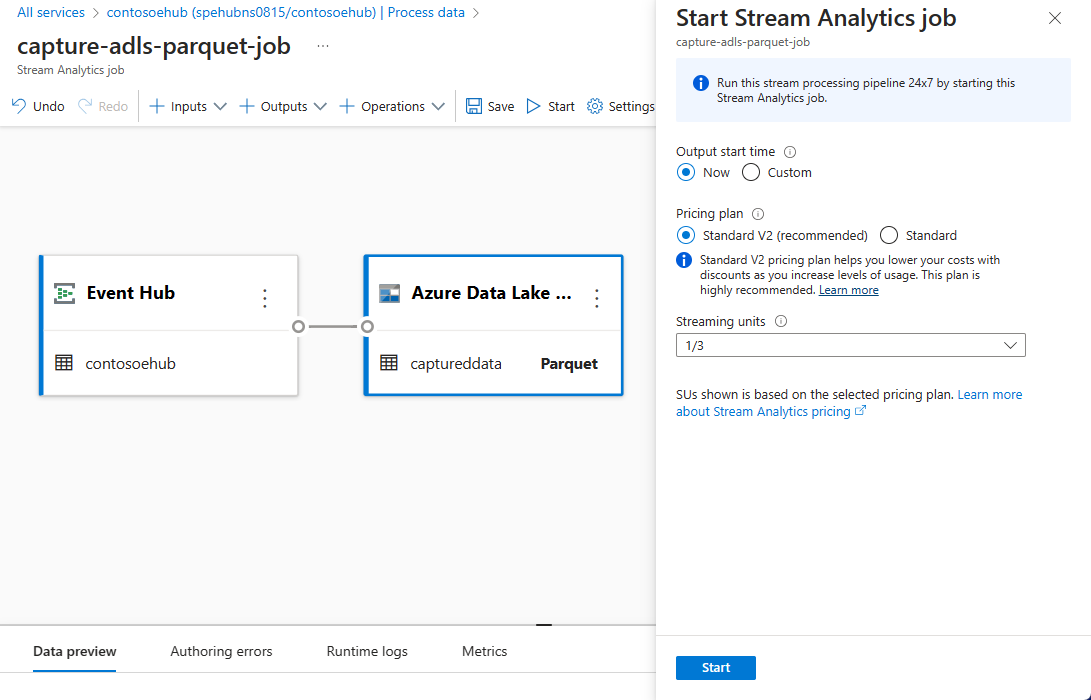
명령 모음에서 시작을 선택하여 스트리밍 흐름을 시작하여 데이터를 캡처합니다. 그런 다음 Stream Analytics 시작 작업 창에서 다음을 수행합니다.
출력 시작 시간을 선택합니다.
가격 책정 플랜을 선택합니다.
작업을 실행할 SU(스트리밍 단위) 수를 선택합니다. SU는 Stream Analytics 작업을 실행하도록 할당된 컴퓨팅 리소스를 나타냅니다. 자세한 내용은 Azure Stream Analytics의 스트리밍 단위를 참조하세요.
이벤트 허브에 대한 데이터 처리 페이지의 Stream Analytics 작업 탭에 Stream Analytics 작업이 표시됩니다.







출력 확인
이벤트 허브에 대한 Event Hubs 인스턴스 페이지에서 데이터 생성을 선택하고 데이터 세트에서 데이터 보유를 선택한 다음 보내기를 선택하여 일부 샘플 데이터를 이벤트 허브로 보냅니다.
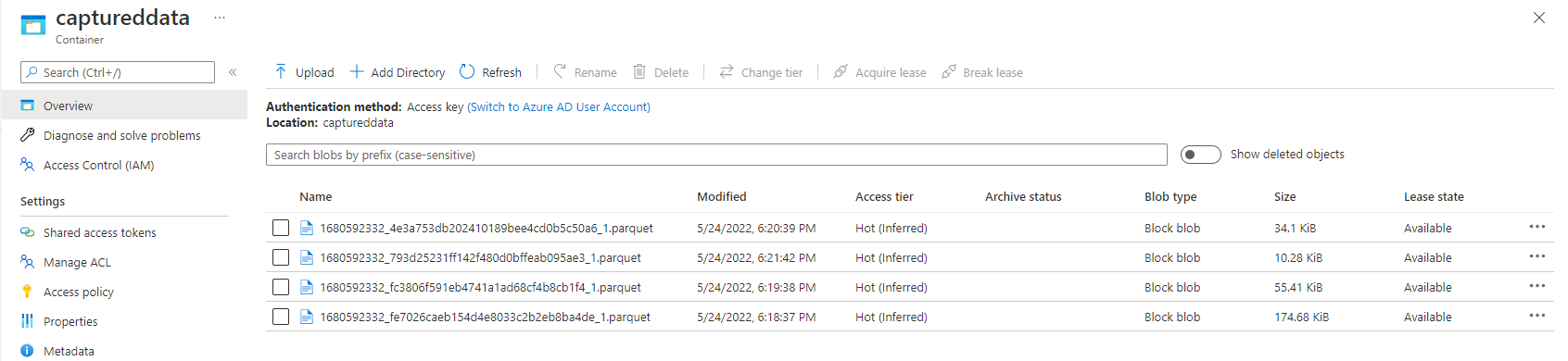
Parquet 파일이 Azure Data Lake Storage 컨테이너에 생성되었는지 확인합니다.
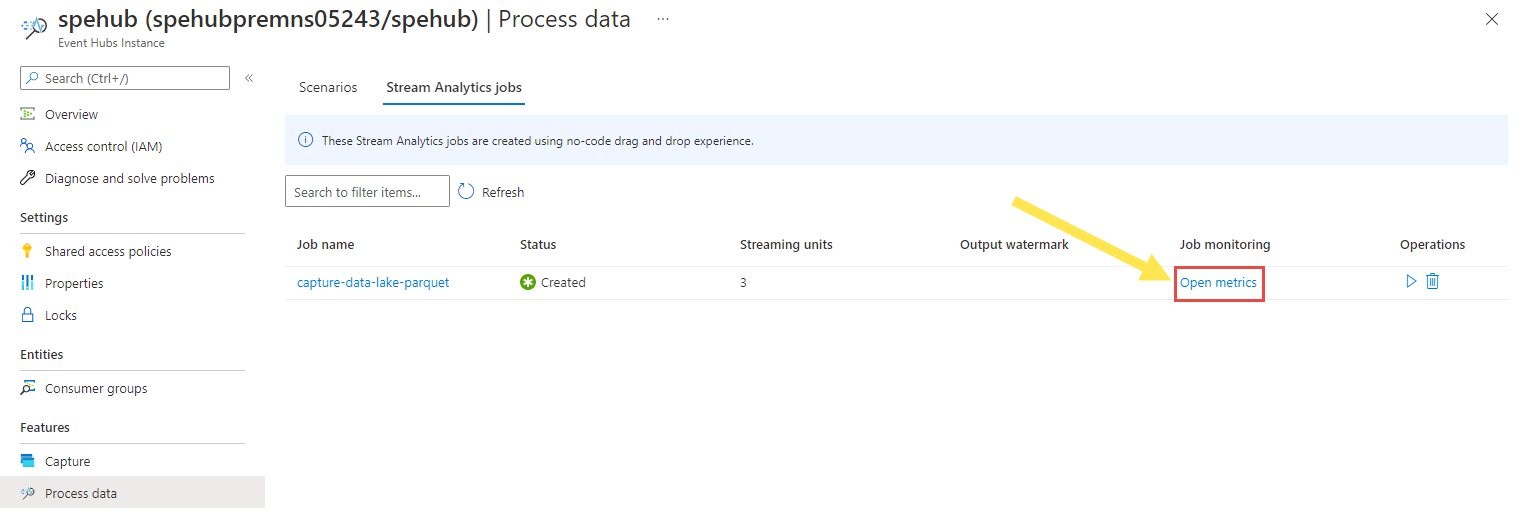
왼쪽 메뉴에서 데이터 처리를 선택합니다. Stream Analytics 작업 탭으로 전환합니다. 메트릭 열기를 선택하여 모니터링합니다.
입력 및 출력 이벤트를 보여 주는 메트릭의 예제 스크린샷은 다음과 같습니다.



다음 단계
이제 Stream Analytics 코드 없는 편집기를 사용하여 Event Hubs 데이터를 Parquet 형식으로 Azure Data Lake Storage Gen2에 캡처하는 작업을 만드는 방법을 배웠습니다. 다음으로 Azure Stream Analytics 및 직접 만든 작업을 모니터링하는 방법에 관해 자세히 알아봅니다.