메트릭 및 차원을 사용하여 Stream Analytics 작업 성능 분석
Azure Stream Analytics 작업의 상태를 이해하려면 작업의 메트릭 및 차원을 사용하는 방법을 아는 것이 중요합니다. Azure Portal, Visual Studio Code Stream Analytics 확장 또는 SDK를 사용하여 관심 있는 메트릭 및 차원을 가져올 수 있습니다.
이 문서에서는 Stream Analytics 작업 메트릭 및 차원을 사용하여 Azure Portal을 통해 작업의 성능을 분석하는 방법을 보여줍니다.
워터마크 지연 및 백로그된 입력 이벤트는 Stream Analytics 작업의 성능을 결정하는 주요 메트릭입니다. 작업의 워터마크 지연이 지속적으로 증가하고 입력 이벤트가 백로그되면 작업이 입력 이벤트의 속도를 따라가지 못하고 적시에 출력을 생성할 수 없습니다.
여러 예제를 살펴보면서 워터마크 지연 메트릭 데이터를 시작점으로 사용하여 작업의 성능을 분석해 보겠습니다.
특정 파티션에 대한 입력이 없으면 작업 워터마크 지연이 증가합니다.
처리하기가 처치 곤란 병렬 작업의 워터마크 지연이 꾸준히 증가하는 경우 메트릭으로 이동합니다. 그런 후 다음 단계에서 근본 원인이 입력 원본의 일부 파티션에 데이터가 부족한지 확인합니다.
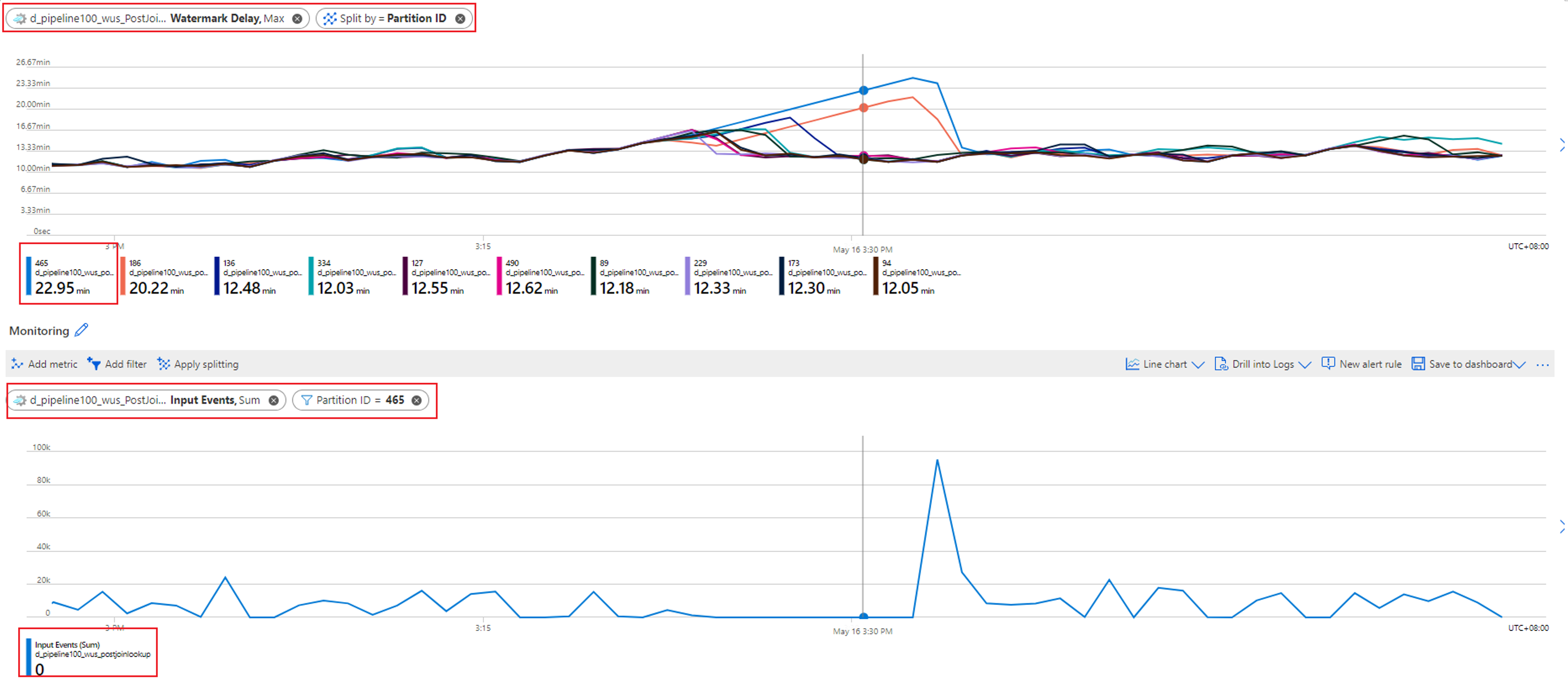
워터마크 지연이 증가하는 파티션을 확인합니다. 워터마크 지연 메트릭을 선택하고 파티션 ID 차원으로 분할합니다. 다음 예에서 파티션(465)에는 상위 워터마크 지연이 있습니다.

이 파티션에 대한 입력 데이터가 누락되었는지 확인합니다. 입력 이벤트 메트릭을 선택하고 이 특정 파티션 ID로 필터링합니다.


어떤 추가 작업을 취할 수 있나요?
이 파티션으로 유입되는 입력 이벤트가 없기 때문에 이 파티션에 대한 워터마크 지연이 증가하고 있습니다. 작업의 지연 도착에 대한 허용 시간이 몇 시간이고 입력 데이터가 파티션으로 전달되지 않는 경우 지연 도착 시간에 도달할 때까지 해당 파티션의 워터마크 지연이 계속 증가할 것으로 예상됩니다.
예를 들어 지연 도착 시간이 6시간이고 입력 데이터가 입력 파티션 1로 흐르지 않는 경우 출력 파티션 1의 워터마크 지연은 6시간에 도달할 때까지 증가합니다. 입력 원본이 예상대로 데이터를 생성하는지 확인할 수 있습니다.
입력 데이터 기울이기로 인해 상위 워터마크 지연이 발생함
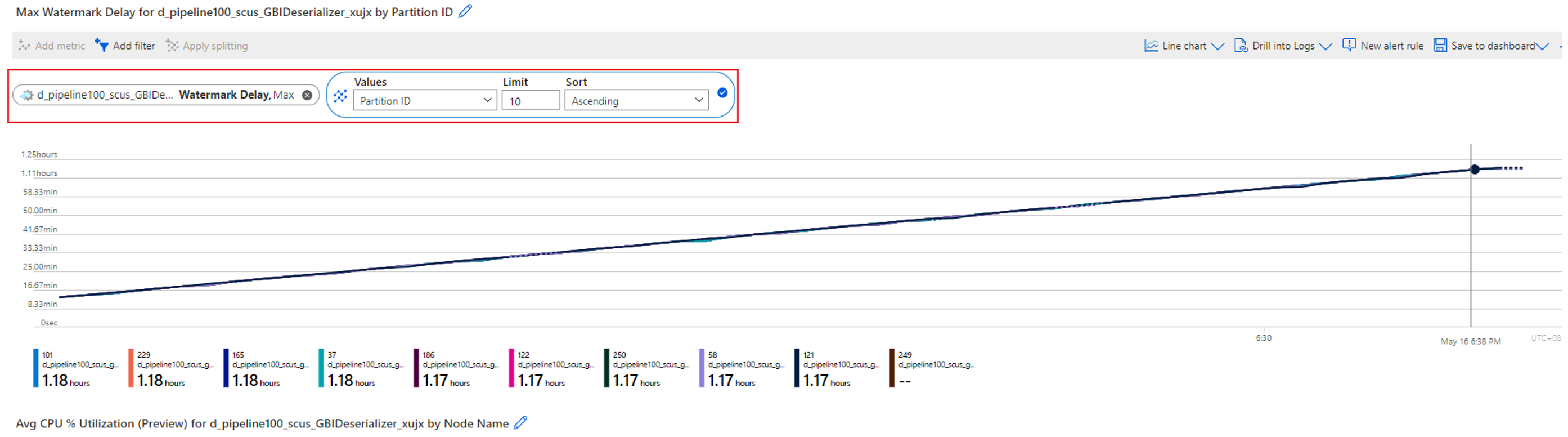
앞의 경우에서 언급했듯이 처리하기가 처치 곤란 병렬 작업에 상위 워터마크 지연이 있는 경우 가장 먼저 해야 할 일은 워터마크 지연 메트릭을 파티션 ID 차원으로 분할하는 것입니다. 그런 다음 모든 파티션에 상위 워터마크 지연이 있는지 또는 일부만 지연되는지 식별할 수 있습니다.
다음 예에서 파티션 0과 1은 다른 8개 파티션보다 워터마크 대기 시간이 더 깁니다(약 20~30초). 다른 파티션의 워터마크 지연은 항상 약 8~10초로 일정합니다.

파티션 ID로 분할된 입력 이벤트 메트릭을 사용하여 이러한 모든 파티션에 대한 입력 데이터가 어떻게 보이는지 확인해 보겠습니다.

어떤 추가 작업을 취할 수 있나요?
예에서 볼 수 있듯이 상위 워터마크 지연이 있는 파티션(0 및 1)은 다른 파티션보다 훨씬 더 많은 입력 데이터를 수신하고 있습니다. 이를 데이터 기울이기라고 합니다. 다음 스크린샷과 같이 데이터 기울이기가 있는 파티션을 처리하는 스트리밍 노드는 다른 노드보다 더 많은 CPU 및 메모리 리소스를 소비해야 합니다.

데이터 기울이기가 더 높은 파티션을 처리하는 스트리밍 노드는 CPU 및/또는 SU(스트리밍 단위) 사용률이 더 높습니다. 이 활용은 작업의 성능에 영향을 미치고 워터마크 지연을 증가시킵니다. 이를 완화하려면 입력 데이터를 더 균등하게 다시 분할해야 합니다.
물리적 작업 다이어그램을 사용하여 이 문제를 디버그할 수도 있습니다. 물리적 작업 다이어그램: 고르지 않은 분산 입력 이벤트 식별(데이터 기울이기)을 참조하세요.
오버로드된 CPU 또는 메모리는 워터마크 지연을 증가시킵니다.
처리하기가 처치 곤란 병렬 작업에 워터마크 지연이 증가하면 하나 또는 여러 파티션뿐만 아니라 모든 파티션에서 발생할 수 있습니다. 작업이 이 사례에 속하는지 어떻게 확인하나요?
워터마크 지연 메트릭을 파티션 ID로 분할합니다. 예시:
입력 이벤트 메트릭을 파티션 ID로 분할하여 각 파티션의 입력 데이터에 데이터 기울이기가 있는지 확인합니다.
CPU 및 SU 사용률을 확인하여 모든 스트리밍 노드의 사용률이 너무 높은지 확인합니다.
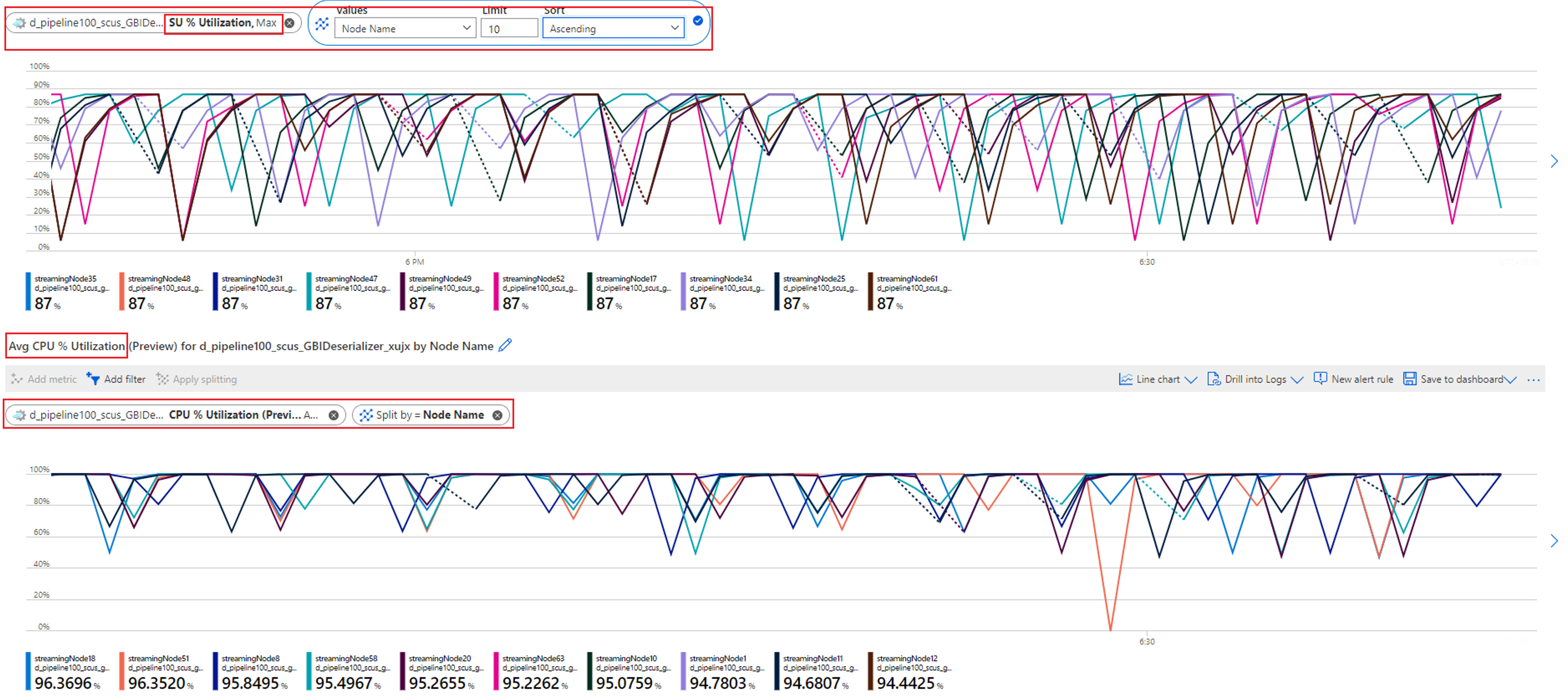
모든 스트리밍 노드에서 CPU 및 SU 사용률이 매우 높으면(80% 이상) 이 작업에 각 스트리밍 노드 내에서 처리되는 데이터 양이 많다는 결론을 내릴 수 있습니다.
입력 이벤트 메트릭을 확인하여 하나의 스트리밍 노드에 할당된 파티션 수를 추가로 확인할 수 있습니다. 노드 이름 차원을 사용하여 스트리밍 노드 ID로 필터링하고 파티션 ID로 분할합니다.
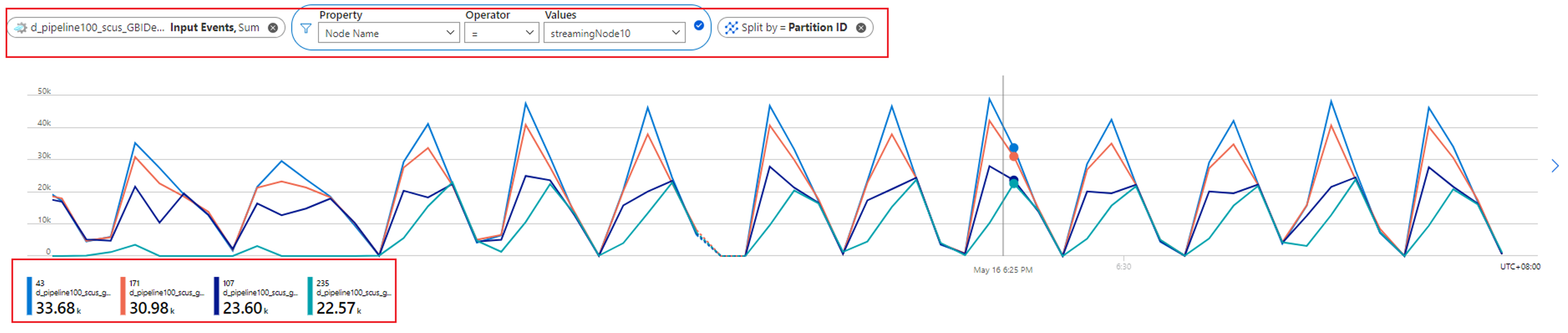
앞의 스크린샷은 스트리밍 노드 리소스의 약 90~100%를 차지하는 하나의 스트리밍 노드에 4개의 파티션이 할당되어 있음을 보여 줍니다. 유사한 방법을 사용하여 나머지 스트리밍 노드도 4개의 파티션에서 데이터를 처리하고 있는지 확인할 수 있습니다.



어떤 추가 작업을 취할 수 있나요?
각 스트리밍 노드의 입력 데이터를 줄이기 위해 각 스트리밍 노드의 파티션 수를 줄일 수 있습니다. 이를 달성하기 위해 각 스트리밍 노드가 두 파티션의 데이터를 처리하도록 SU를 두 배로 늘릴 수 있습니다. 또는 각 스트리밍 노드가 한 파티션의 데이터를 처리하도록 SU를 4배로 늘릴 수 있습니다. SU 할당과 스트리밍 노드 수 간의 관계에 대한 자세한 내용은 스트리밍 단위 이해 및 조정을 참조하세요.
한 스트리밍 노드가 한 파티션의 데이터를 처리할 때 워터마크 지연이 계속 증가하는 경우 어떻게 해야 하나요? 더 많은 파티션으로 입력을 다시 분할하여 각 파티션의 데이터 양을 줄입니다. 자세한 내용은 재분할을 사용하여 Azure Stream Analytics 작업 최적화를 참조하세요.
물리적 작업 다이어그램을 사용하여 이 문제를 디버그할 수도 있습니다. 물리적 작업 다이어그램: 오버로드된 CPU 또는 메모리의 원인 식별을 참조하세요.