클라우드 및 Azure IoT Edge 모두 사용할 수 있는 Azure Stream Analytics 가장 일반적으로 발생하는 두 가지 변칙인 임시 및 영구를 모니터링하는 데 사용할 수 있는 기본 제공 기계 학습 기반 변칙 검색 기능을 제공합니다. AnomalyDetection_SpikeAndDip 및 AnomalyDetection_ChangePoint 함수를 사용하여 Stream Analytics 작업에서 직접 변칙 검색을 수행할 수 있습니다.
기계 학습 모델은 균일하게 샘플링된 시계열을 가정합니다. 시계열이 균일하지 않은 경우, 이상 탐지를 호출하기 전에 텀블링 윈도우를 사용한 집계 단계를 삽입합니다.
기계 학습 작업은 현재 계절성 추세 또는 다변량 상관 관계를 지원하지 않습니다.
Azure Stream Analytics에서 기계 학습을 사용한 이상 탐지
다음 비디오에서는 Azure Stream Analytics 기계 학습 함수를 사용하여 실시간으로 변칙을 검색하는 방법을 보여 줍니다.
모델의 동작 방식
일반적으로 슬라이딩 윈도우에서 더 많은 데이터를 사용하여 모델의 정확도가 향상됩니다. 지정된 슬라이딩 윈도우의 데이터는 해당 시간 프레임에 대한 일반 값 범위의 일부로 처리됩니다. 모델은 현재 이벤트가 비정상적인지 확인하기 위해 슬라이딩 윈도우의 이벤트 기록만 고려합니다. 슬라이딩 윈도우가 이동하면 이전 값이 모델의 학습에서 제거됩니다.
함수는 지금까지 본 내용에 따라 특정 정상을 설정하여 작동합니다. 이상값은 신뢰 수준 내에서 설정된 정상과 비교하여 식별됩니다. 창 크기는 정상 동작에 대해 모델을 학습시키는 데 필요한 최소 이벤트를 기반으로 하여 변칙이 발생할 때 이를 인식할 수 있도록 해야 합니다.
이전 이벤트의 개수와 비교해야 하므로 모델의 응답 시간은 기록 크기에 따라 증가합니다. 성능을 향상시키려면 필요한 수의 이벤트만 포함합니다.
시계열의 간격은 모델이 특정 시점에 이벤트를 수신하지 않을 때 발생할 수 있습니다. Stream Analytics는 대체 논리를 사용하여 이 상황을 처리합니다. 기록 크기와 동일한 슬라이딩 윈도우의 기간은 이벤트가 도착할 것으로 예상되는 평균 속도를 계산하는 데 사용됩니다.
anomaly 생성기를 사용하여 다양한 변칙 패턴이 포함된 데이터를 IoT Hub에 공급할 수 있습니다. 이러한 변칙 검색 함수를 사용하여 이 IoT Hub 읽고 변칙을 검색하여 Azure Stream Analytics 작업을 설정할 수 있습니다.
급등 및 급락
시계열 이벤트 스트림의 임시 변칙을 급증 및 급락이라고 합니다. Machine Learning 기반 연산자 AnomalyDetection_SpikeAndDip 사용하여 급증 및 급락을 모니터링할 수 있습니다.
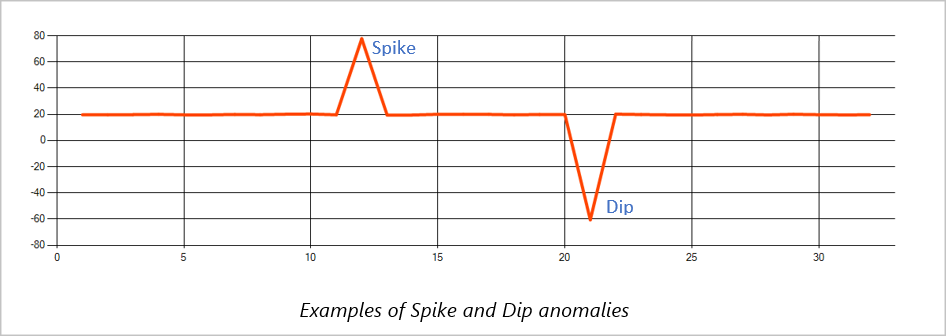
동일한 슬라이딩 윈도우에서 두 번째 스파이크가 첫 번째 스파이크보다 작으면 지정된 신뢰 수준 내의 첫 번째 스파이크에 대한 점수에 비해 더 작은 스파이크에 대한 계산 점수가 충분히 중요하지 않을 수 있습니다. 모델의 신뢰도 수준을 줄이면 이러한 변칙을 검색할 수 있습니다. 그러나 경고가 너무 많기 시작하면 더 높은 신뢰 구간을 사용합니다.
다음 예제 쿼리에서는 120개의 이벤트 기록이 있는 2분 슬라이딩 윈도우에서 초당 1개의 이벤트의 균일한 입력 속도를 가정합니다. 최종 SELECT 문은 신뢰도 수준이 95%점수 및 변칙 상태를 추출하고 출력합니다.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
변경 지점
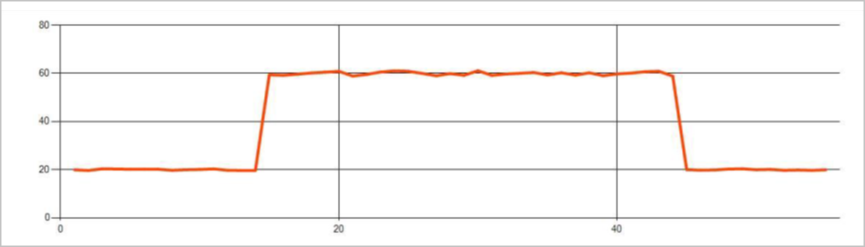
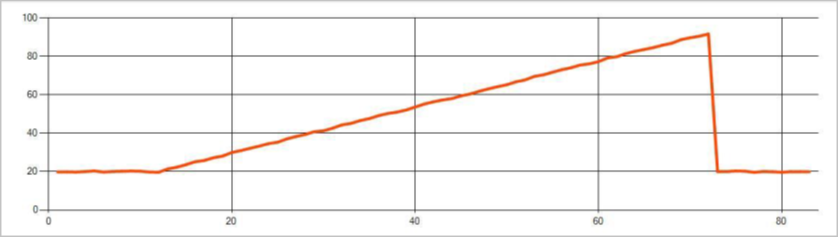
시계열 이벤트 스트림의 영구 변칙은 수준 변경 및 추세와 같은 이벤트 스트림의 값 분포에 있는 변경 내용입니다. Stream Analytics에서 Machine Learning 기반 AnomalyDetection_ChangePoint 연산자는 이러한 변칙을 검색합니다.
지속적인 변화는 급증과 급락보다 훨씬 오래 지속되며 치명적인 사건을 나타낼 수 있습니다. 영구적 변경 내용은 일반적으로 육안으로는 표시되지 않지만 AnomalyDetection_ChangePoint 연산자는 이를 감지할 수 있습니다.
다음 이미지는 수준 변경의 예입니다.
다음 이미지는 추세 변경의 예입니다.
다음 예제 쿼리에서는 기록 크기가 1,200개인 20분 슬라이딩 윈도우에서 초당 1개 이벤트의 균일한 입력 속도를 가정합니다. 최종 SELECT 문은 신뢰도 수준이 80%점수 및 변칙 상태를 추출하고 출력합니다.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
성능 특징
이러한 모델의 성능은 기록 크기, 창 기간, 이벤트 로드 및 함수 수준 분할이 사용되는지 여부에 따라 달라집니다. 이 섹션에서는 이러한 구성에 대해 설명하고 초당 1K, 5K 및 10K 이벤트의 수집 속도를 유지하는 방법에 대한 샘플을 제공합니다.
- 기록 크기 - 이러한 모델은 기록 크기로 선형으로 수행됩니다. 기록 크기가 길수록 모델이 새 이벤트의 점수를 매기는 데 걸리는 시간이 길어질 수 있습니다. 모델은 새 이벤트를 기록 버퍼의 과거 이벤트 각각과 비교합니다.
- 윈도우 기간 - 윈도우 기간은 기록 크기에 지정된 만큼의 이벤트를 수신하는 데 걸리는 시간을 반영해야 합니다. 기간에 해당 개수의 이벤트가 없을 경우 Azure Stream Analytics에서 누락된 값을 대체합니다. 따라서 CPU 사용량은 기록 크기의 함수입니다.
- 이벤트 로드 - 이벤트 로드가 클수록 모델이 수행하는 작업이 많을수록 CPU 사용량에 영향을 줍니다. 비즈니스 로직상 더 많은 입력 파티션을 사용하는 것이 적절하다면, 작업을 매우 병렬화하여 확장할 수 있습니다.
-
함수 수준 분할 - 변칙 검색 함수 호출 내에서
PARTITION BY수행하는 데 사용합니다. 이러한 유형의 분할은 작업이 동시에 여러 모델의 상태를 유지해야 하므로 오버헤드를 추가합니다. 디바이스 수준 분할과 같은 시나리오에서 함수 수준 분할을 사용합니다.
관계
기록 크기, 창 기간 및 총 이벤트 로드는 다음과 같은 방식으로 관련됩니다.
windowDuration (in ms) = 1000 * historySize / (초당 총 입력 이벤트 수 / 입력 파티션 수)
deviceId로 함수를 분할할 때 변칙 검색 함수 호출에 "PARTITION BY deviceId"를 추가합니다.
관찰
다음 표에서는 분할되지 않은 사례에 대한 단일 노드(6 SU)에 대한 처리량 관찰을 보여 줍니다.
| 기록 크기(이벤트) | 창 지속 시간 (ms) | 초당 총 입력 이벤트 수 |
|---|---|---|
| 60 | 55 | 2,200 |
| 600 | 728 | 1,650 |
| 6,000 | 10,910 | 1,100 |
다음 표에서는 분할된 사례에 대한 단일 노드(6 SU)에 대한 처리량 관찰을 보여 줍니다.
| 기록 크기(이벤트) | 창 지속 시간 (ms) | 초당 총 입력 이벤트 수 | 장치 수 |
|---|---|---|---|
| 60 | 1,091 | 1,100 | 10 |
| 600 | 10,910 | 1,100 | 10 |
| 6,000 | 218,182 | <550 | 10 |
| 60 | 21,819 | 550 | 100 |
| 600 | 218,182 | 550 | 100 |
| 6,000 | 2,181,819 | <550 | 100 |
샘플 코드는 Azure 샘플의 Streaming At Scale 리포지토리에서 분할되지 않은 구성을 실행할 수 있습니다. 이 코드는 함수 수준 분할 없이 Stream Analytics 작업을 만듭니다. 이 작업은 Event Hubs를 입력 및 출력으로 사용합니다. 테스트 클라이언트는 입력 부하를 생성합니다. 각 입력 이벤트는 1KB JSON 문서입니다. 이벤트는 JSON 데이터를 보내는 IoT 디바이스를 시뮬레이션합니다(최대 1K 디바이스). 기록 크기, 창 기간 및 총 이벤트 로드는 두 개의 입력 파티션에 따라 다릅니다.
메모
보다 정확한 추정을 위해 시나리오에 맞게 샘플을 사용자 지정합니다.
병목 상태 식별
파이프라인에서 병목 상태를 식별하려면 Azure Stream Analytics 작업에서 메트릭 창을 사용합니다. 처리량 및 "워터마크 지연" 또는 백로그된 이벤트에 대한 입력/출력 이벤트를 검토하여 작업이 입력 속도를 유지하는지 확인합니다. Event Hubs 메트릭의 경우 제한된 요청을 찾고 그에 따라 임계값 단위를 조정합니다. Azure Cosmos DB 메트릭의 경우 처리량에서 Max에서 파티션 키 범위당 사용된 RU/s를 검토하여 파티션 키 범위가 균일하게 사용되는지 확인합니다. Azure SQL DB의 경우 Log IO 및 CPU 모니터링합니다.
데모 비디오
다음 단계
- Azure Stream Analytics 소개
Azure Stream Analytics 사용 시작하기 - Azure Stream Analytics 작업 크기 조정
- Azure Stream Analytics 쿼리 언어 참조
- Azure Stream Analytics 관리 REST API 참조