예측 기계 학습 모델을 사용하여 전용 SQL 풀에서 데이터를 쉽게 보강하는 방법을 알아봅니다. 데이터 과학자가 만드는 모델은 이제 예측 분석을 위해 데이터 전문가가 쉽게 액세스할 수 있습니다. Azure Synapse Analytics의 데이터 전문가는 Azure Synapse SQL 풀에 배포하기 위해 Azure Machine Learning 모델 레지스트리에서 모델을 선택하고 예측을 시작하여 데이터를 보강할 수 있습니다.
이 자습서에서는 다음 방법을 알아봅니다.
- 예측 기계 학습 모델을 학습하고 Azure Machine Learning 모델 레지스트리에서 모델 등록
- SQL 채점 마법사를 사용하여 전용 SQL 풀에서 예측 시작
Azure 구독이 아직 없는 경우 시작하기 전에 체험 계정을 만듭니다.
필수 조건
- Azure Synapse Analytics 작업 영역(기본 스토리지로 구성된 Azure Data Lake Storage Gen2 스토리지 계정이 있음). 사용하는 Data Lake Storage Gen2 파일 시스템의 Storage Blob 데이터 기여자여야 합니다.
- Azure Synapse Analytics 작업 영역의 전용 SQL 풀입니다. 자세한 내용은 전용 SQL 풀 만들기를 참조하세요.
- Azure Machine Learning 연결된 서비스가 Azure Synapse Analytics 작업 영역에 있습니다. 자세한 내용은 Azure Synapse에서 Azure Machine Learning 연결된 서비스 만들기를 참조하세요.
Azure Portal에 로그인
Azure Portal에 로그인합니다.
Azure Machine Learning에서 모델 학습
시작하기 전에 sklearn 버전이 0.20.3인지 확인합니다.
Notebook에서 모든 셀을 실행하기 전에 컴퓨팅 인스턴스가 실행 중인지 확인합니다.
Azure Machine Learning 작업 영역으로 이동합니다.
Predict NYC Taxi Tips.ipynb을 다운로드합니다.
Azure Machine Learning Studio에서 Azure Machine Learning 작업 영역을 엽니다.
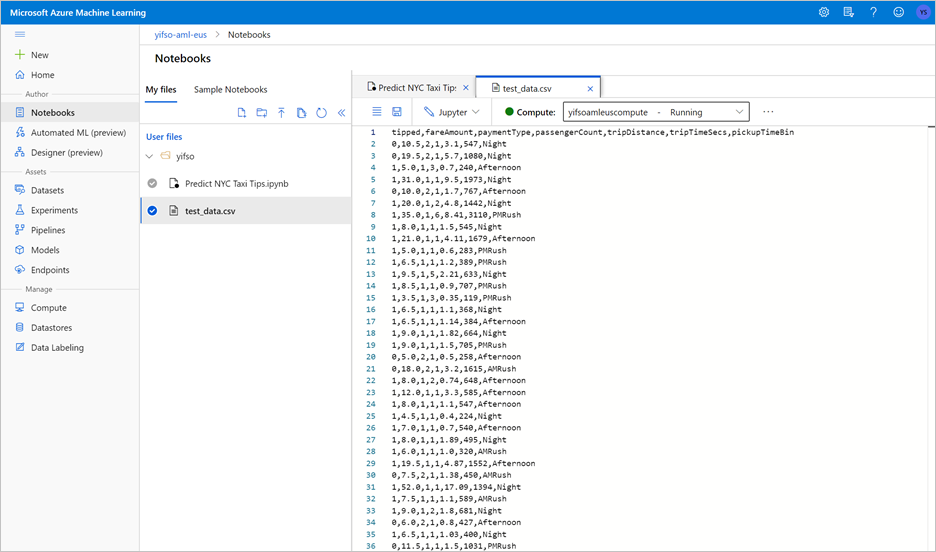
Notebooks>로 이동합니다. 그런 다음 다운로드한 NYC Taxi Tips.ipynb 예측 파일을 선택하고 업로드합니다.
전자 필기장을 업로드하고 연 후 모든 셀 실행을 선택합니다.
셀 중 하나가 실패하고 Azure에 인증하도록 요청할 수 있습니다. 셀 출력에서 이를 확인하고 링크를 따라 코드를 입력하여 브라우저에서 인증합니다. 그런 다음 Notebook을 다시 실행합니다.
Notebook은 ONNX 모델을 학습시키고 MLflow에 등록합니다. 모델로 이동하여 새 모델이 제대로 등록되어 있는지 확인합니다.
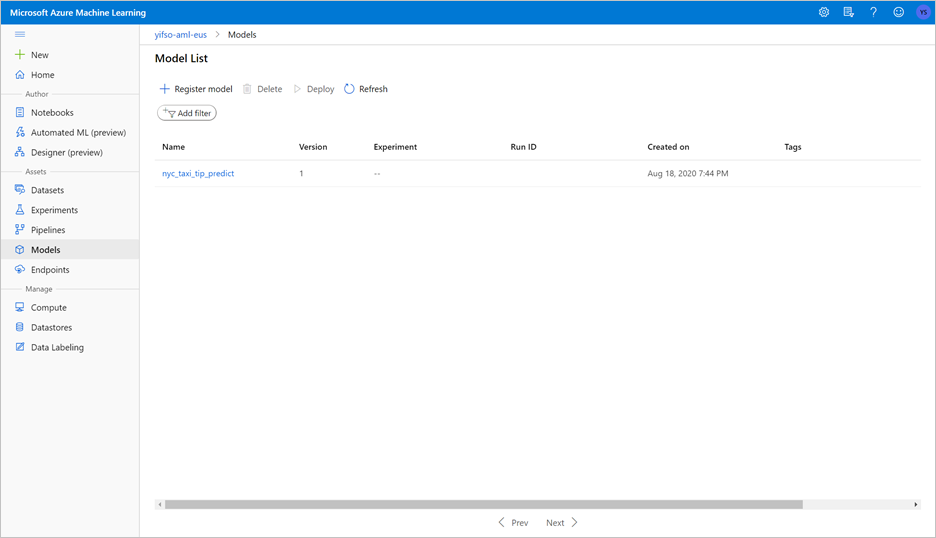
Notebook을 실행하면 테스트 데이터도 CSV 파일로 내보냅니다. CSV 파일을 로컬 시스템에 다운로드합니다. 나중에 CSV 파일을 전용 SQL 풀로 가져오고 데이터를 사용하여 모델을 테스트합니다.
CSV 파일은 Notebook 파일과 동일한 폴더에 만들어집니다. 즉시 표시되지 않으면 파일 탐색기에서 새로 고침 을 선택합니다.
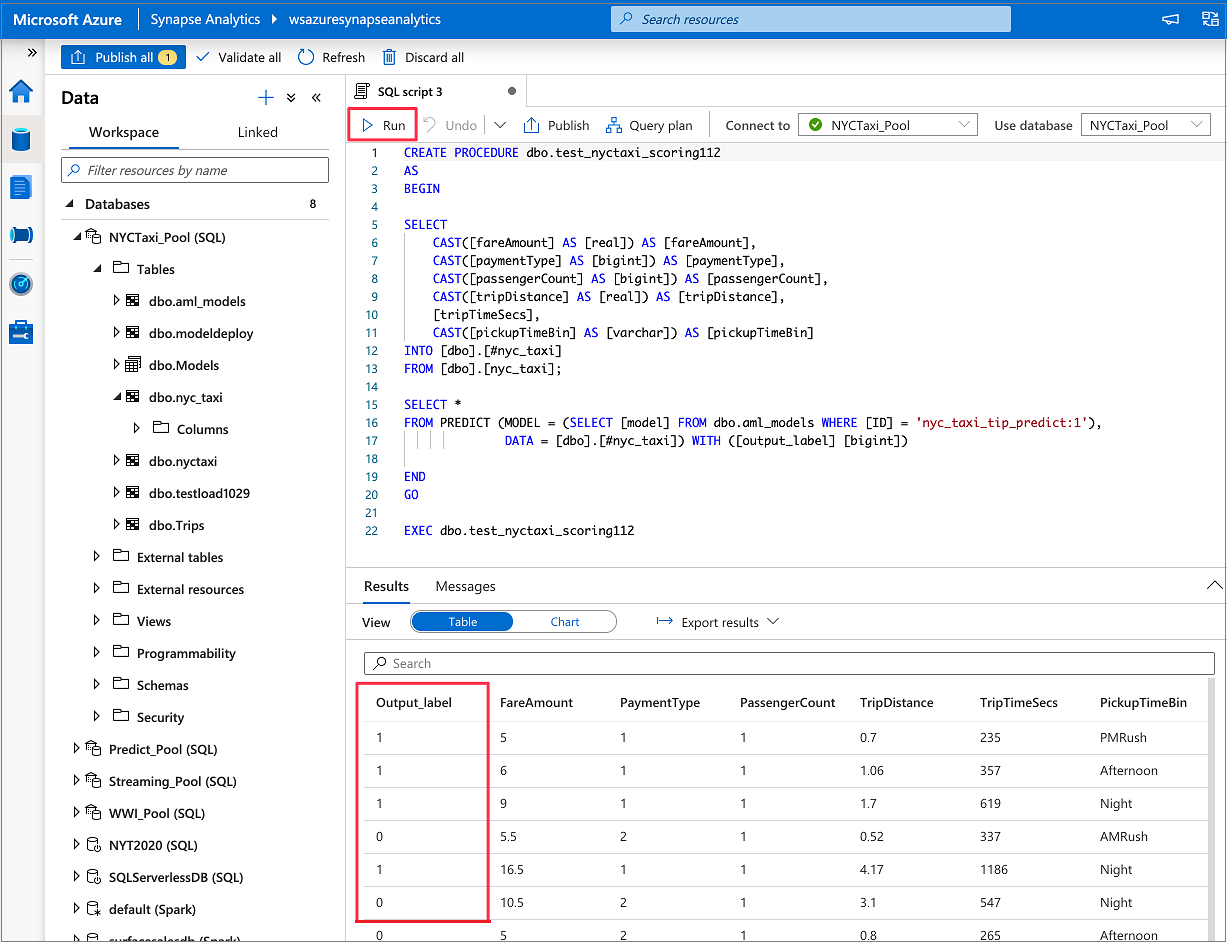
SQL 점수 매기기 마법사를 사용하여 예측 시작
Synapse Studio를 사용하여 Azure Synapse 작업 영역을 엽니다.
데이터> 연결된스토리지 계정> 이동합니다.
test_data.csv을 기본 저장소 계정에 업로드합니다.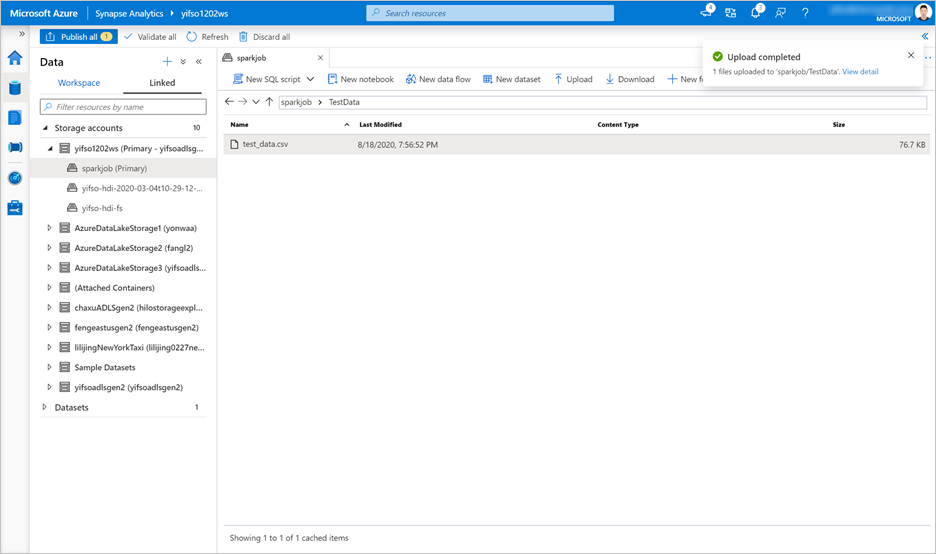
SQL 스크립트>로 이동합니다. 전용 SQL 풀에 로드
test_data.csv할 새 SQL 스크립트를 만듭니다.비고
이 스크립트를 실행하기 전에 파일 URL을 업데이트합니다.
IF NOT EXISTS (SELECT * FROM sys.objects WHERE NAME = 'nyc_taxi' AND TYPE = 'U') CREATE TABLE dbo.nyc_taxi ( tipped int, fareAmount float, paymentType int, passengerCount int, tripDistance float, tripTimeSecs bigint, pickupTimeBin nvarchar(30) ) WITH ( DISTRIBUTION = ROUND_ROBIN, CLUSTERED COLUMNSTORE INDEX ) GO COPY INTO dbo.nyc_taxi (tipped 1, fareAmount 2, paymentType 3, passengerCount 4, tripDistance 5, tripTimeSecs 6, pickupTimeBin 7) FROM '<URL to linked storage account>/test_data.csv' WITH ( FILE_TYPE = 'CSV', ROWTERMINATOR='0x0A', FIELDQUOTE = '"', FIELDTERMINATOR = ',', FIRSTROW = 2 ) GO SELECT TOP 100 * FROM nyc_taxi GO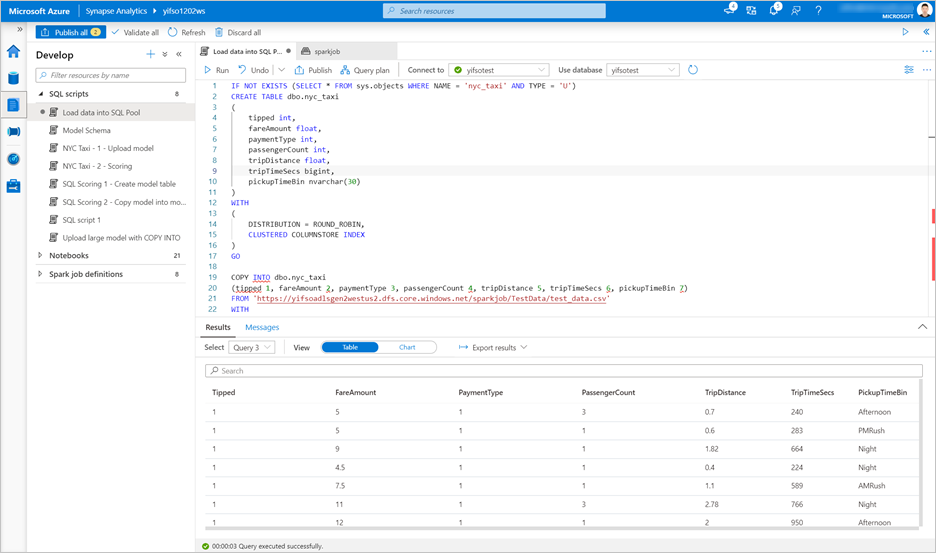
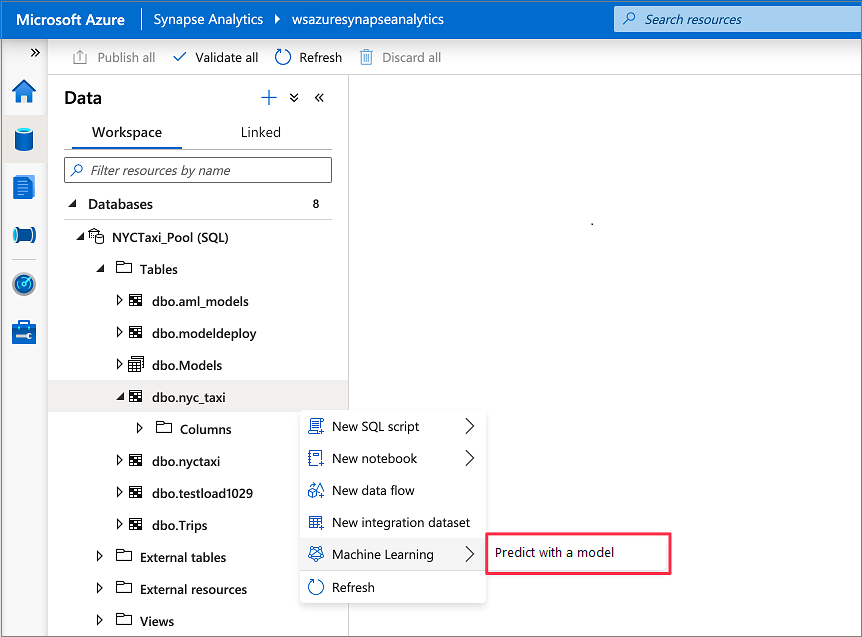
데이터>작업 영역으로 이동합니다. 전용 SQL 풀 테이블을 마우스 오른쪽 단추로 클릭하여 SQL 점수 매기기 마법사를 엽니다. Machine Learning>모델로 예측 선택
비고
Azure Machine Learning용으로 연결된 서비스가 만들어지지 않는 한 기계 학습 옵션이 표시되지 않습니다. (이 자습서의 시작 부분에 있는 필수 구성 요소를 참조하세요.)
드롭다운 상자에서 연결된 Azure Machine Learning 작업 영역을 선택합니다. 이 단계에서는 선택한 Azure Machine Learning 작업 영역의 모델 레지스트리에서 기계 학습 모델 목록을 로드합니다. 현재는 ONNX 모델만 지원되므로 이 단계에서는 ONNX 모델만 표시합니다.
방금 학습한 모델을 선택한 다음 계속을 선택합니다.
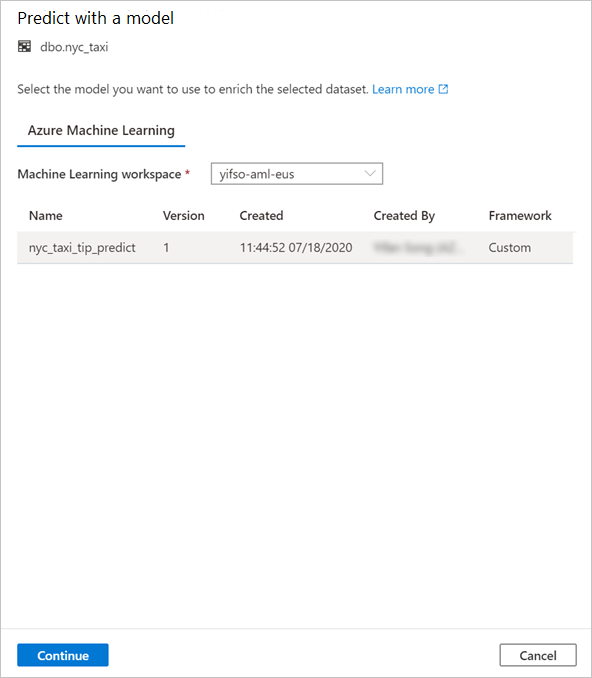
테이블 열을 모델 입력에 매핑하고 모델 출력을 지정합니다. 모델이 MLflow 형식으로 저장되고 모델 서명이 채워지면 이름 유사성에 따라 논리를 사용하여 매핑이 자동으로 수행됩니다. 인터페이스는 수동 매핑도 지원합니다.
를 선택합니다 계속.
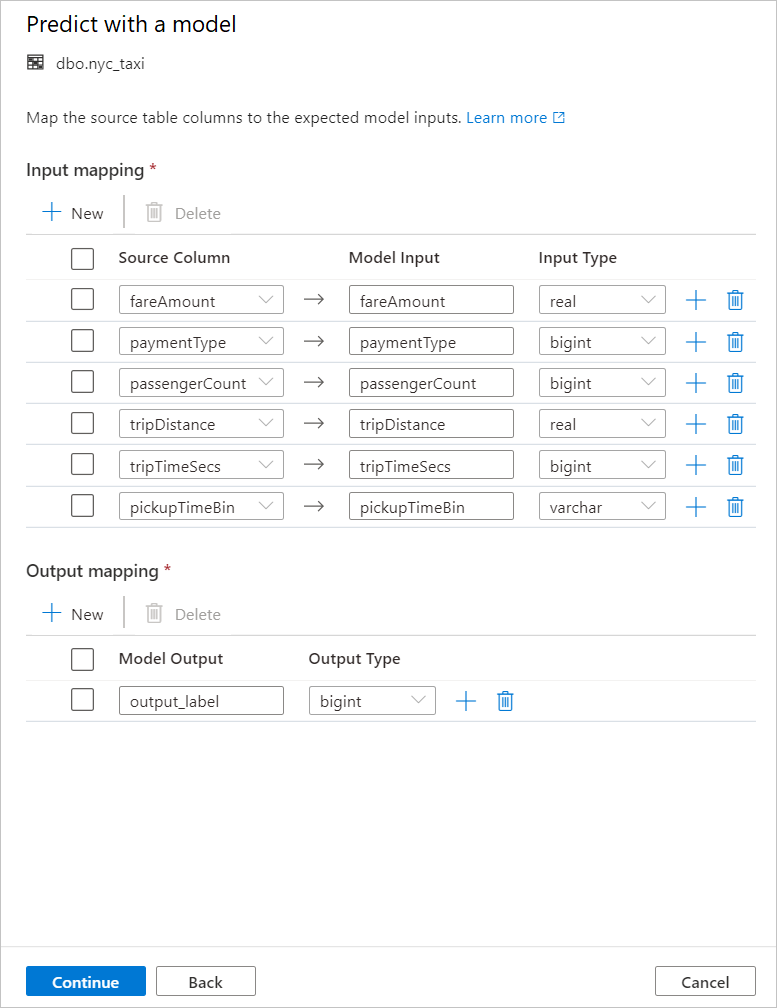
생성된 T-SQL 코드는 저장 프로시저 내에 래핑됩니다. 따라서 저장 프로시저 이름을 제공해야 합니다. 메타데이터(버전, 설명 및 기타 정보)를 포함한 모델 이진 파일은 Azure Machine Learning에서 전용 SQL 풀 테이블로 물리적으로 복사됩니다. 따라서 모델을 저장할 테이블을 지정해야 합니다.
기존 테이블 또는 새로 만들기 중 하나를 선택할 수 있습니다. 완료되면 모델 배포 + 스크립트 열기 를 선택하여 모델을 배포하고 T-SQL 예측 스크립트를 생성합니다.
스크립트가 생성되면 실행을 선택하여 채점을 실행하고 예측을 가져옵니다.