이 문서에서는 Apache Spark MLlib 를 사용하여 Azure 개방형 데이터 세트에서 간단한 예측 분석을 수행하는 기계 학습 애플리케이션을 만드는 방법을 알아봅니다. Spark는 기본 제공 기계 학습 라이브러리를 제공합니다. 이 예제에서는 로지스틱 회귀를 통해 분류 를 사용합니다.
SparkML 및 MLlib는 다음에 적합한 유틸리티를 포함하여 기계 학습 작업에 유용한 많은 유틸리티를 제공하는 핵심 Spark 라이브러리입니다.
- Classification
- Regression
- Clustering
- 토픽 모델링
- SVD(특이값 분해) 및 PCA(주성분 분석)
- 가설 검정 및 샘플 통계 계산
분류 및 로지스틱 회귀 이해
널리 사용되는 기계 학습 작업인 분류는 입력 데이터를 범주로 정렬하는 프로세스입니다. 제공하는 입력 데이터에 레이블 을 할당하는 방법을 파악하는 것은 분류 알고리즘의 작업입니다. 예를 들어 주식 정보를 입력으로 수락하고 주식을 판매해야 하는 주식과 보유해야 하는 주식의 두 가지 범주로 나누는 기계 학습 알고리즘을 생각할 수 있습니다.
로지스틱 회귀 는 분류에 사용할 수 있는 알고리즘입니다. Spark의 로지스틱 회귀 API는 이진 분류 또는 입력 데이터를 두 그룹 중 하나로 분류하는 데 유용합니다. 로지스틱 회귀에 대한 자세한 내용은 Wikipedia를 참조하세요.
요약하자면, 로지스틱 회귀 프로세스는 입력 벡터가 한 그룹 또는 다른 그룹에 속할 확률을 예측하는 데 사용할 수 있는 로지스틱 함수 를 생성합니다.
NYC 택시 데이터에 대한 예측 분석 예제
이 예제에서는 Spark를 사용하여 뉴욕의 택시 여정 팁 데이터에 대한 몇 가지 예측 분석을 수행합니다. 데이터는 Azure Open Datasets를 통해 사용할 수 있습니다. 데이터 세트의 이 하위 집합에는 각 여정, 시작 및 종료 시간 및 위치, 비용 및 기타 흥미로운 특성에 대한 정보를 포함하여 노란색 택시 여정에 대한 정보가 포함됩니다.
중요합니다
스토리지 위치에서 이 데이터를 끌어와야 하는 추가 요금이 발생할 수 있습니다.
다음 단계에서는 특정 여정에 팁이 포함되어 있는지 여부를 예측하는 모델을 개발합니다.
Apache Spark 기계 학습 모델 만들기
PySpark 커널을 사용하여 Notebook을 만듭니다. 지침은 전자 필기장 만들기를 참조하세요.
이 애플리케이션에 필요한 형식을 가져옵니다. 다음 코드를 복사하여 빈 셀에 붙여넣은 다음 Shift+Enter를 누릅니다. 또는 코드 왼쪽의 파란색 재생 아이콘을 사용하여 셀을 실행합니다.
import matplotlib.pyplot as plt from datetime import datetime from dateutil import parser from pyspark.sql.functions import unix_timestamp, date_format, col, when from pyspark.ml import Pipeline from pyspark.ml import PipelineModel from pyspark.ml.feature import RFormula from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorIndexer from pyspark.ml.classification import LogisticRegression from pyspark.mllib.evaluation import BinaryClassificationMetrics from pyspark.ml.evaluation import BinaryClassificationEvaluatorPySpark 커널로 인해 컨텍스트를 명시적으로 만들 필요가 없습니다. Spark 컨텍스트는 첫 번째 코드 셀을 실행할 때 자동으로 만들어집니다.
입력 데이터 프레임 생성
원시 데이터는 Parquet 형식이므로 Spark 컨텍스트를 사용하여 파일을 DataFrame으로 직접 메모리로 끌어올 수 있습니다. 다음 단계의 코드는 기본 옵션을 사용하지만 필요한 경우 데이터 형식 및 기타 스키마 특성의 매핑을 강제 적용할 수 있습니다.
다음 줄을 실행하여 코드를 새 셀에 붙여넣어 Spark DataFrame을 만듭니다. 이 단계에서는 Open Datasets API를 통해 데이터를 검색합니다. 이 모든 데이터를 끌어당기면 약 15억 개의 행이 생성됩니다.
서버리스 Apache Spark 풀의 크기에 따라 원시 데이터가 너무 크거나 작동하는 데 너무 많은 시간이 걸릴 수 있습니다. 이 데이터를 더 작은 값으로 필터링할 수 있습니다. 다음 코드 예제에서는 한 달의 데이터를 반환하는 필터를 사용하고
start_dateend_date적용합니다.from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())간단한 필터링의 단점은 통계적 관점에서 데이터에 편견을 도입할 수 있다는 것입니다. 또 다른 방법은 Spark에 기본 제공되는 샘플링을 사용하는 것입니다.
다음 코드는 이전 코드 다음에 적용되는 경우 데이터 세트를 약 2,000개의 행으로 줄입니다. 단순 필터 대신 또는 단순 필터와 함께 이 샘플링 단계를 사용할 수 있습니다.
# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234)이제 데이터를 보고 읽은 내용을 확인할 수 있습니다. 일반적으로 데이터 세트의 크기에 따라 전체 집합이 아닌 하위 집합으로 데이터를 검토하는 것이 좋습니다.
다음 코드는 데이터를 보는 두 가지 방법을 제공합니다. 첫 번째 방법은 기본입니다. 두 번째 방법은 데이터를 그래픽으로 시각화하는 기능과 함께 훨씬 더 풍부한 그리드 환경을 제공합니다.
#sampled_taxi_df.show(5) display(sampled_taxi_df)생성된 데이터 세트의 크기와 Notebook을 여러 번 실험하거나 실행해야 하는 필요성에 따라 작업 영역에서 로컬로 데이터 세트를 캐시할 수 있습니다. 명시적 캐싱을 수행하는 세 가지 방법이 있습니다.
- DataFrame을 로컬로 파일로 저장합니다.
- DataFrame을 임시 테이블 또는 뷰로 저장합니다.
- DataFrame을 영구 테이블로 저장합니다.
이러한 방법 중 처음 두 가지는 다음 코드 예제에 포함됩니다.
임시 테이블 또는 뷰를 만들면 데이터에 대한 액세스 경로가 다르지만 Spark 인스턴스 세션 기간 동안만 지속됩니다.
sampled_taxi_df.createOrReplaceTempView("nytaxi")
데이터 준비
원시 형식의 데이터는 모델에 직접 전달하는 데 적합하지 않은 경우가 많습니다. 모델에서 데이터를 사용할 수 있는 상태로 전환하려면 데이터에 대해 일련의 작업을 수행해야 합니다.
다음 코드에서는 네 가지 작업 클래스를 수행합니다.
- 필터링을 통해 이상값 또는 잘못된 값을 제거합니다.
- 필요하지 않은 열을 제거
- 모델이 보다 효과적으로 작동하도록 원시 데이터에서 파생된 새 열을 만듭니다. 이 작업을 기능화라고도 합니다.
- 라벨. 이진 분류를 수행하기 때문에(지정된 여정에 팁이 있는지 여부), 팁 금액을 0 또는 1 값으로 변환해야 합니다.
taxi_df = sampled_taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\
, 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\
, date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\
, date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\
, (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\
, (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped')
)\
.filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\
& (sampled_taxi_df.tipAmount >= 0) & (sampled_taxi_df.tipAmount <= 25)\
& (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\
& (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\
& (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 100)\
& (sampled_taxi_df.rateCodeId <= 5)
& (sampled_taxi_df.paymentType.isin({"1", "2"}))
)
그런 다음 데이터를 두 번째로 전달하여 최종 기능을 추가합니다.
taxi_featurised_df = taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'passengerCount'\
, 'tripDistance', 'weekdayString', 'pickupHour','tripTimeSecs','tipped'\
, when((taxi_df.pickupHour <= 6) | (taxi_df.pickupHour >= 20),"Night")\
.when((taxi_df.pickupHour >= 7) & (taxi_df.pickupHour <= 10), "AMRush")\
.when((taxi_df.pickupHour >= 11) & (taxi_df.pickupHour <= 15), "Afternoon")\
.when((taxi_df.pickupHour >= 16) & (taxi_df.pickupHour <= 19), "PMRush")\
.otherwise(0).alias('trafficTimeBins')
)\
.filter((taxi_df.tripTimeSecs >= 30) & (taxi_df.tripTimeSecs <= 7200))
로지스틱 회귀 모델 만들기
마지막 작업은 레이블이 지정된 데이터를 로지스틱 회귀를 통해 분석할 수 있는 형식으로 변환하는 것입니다. 로지스틱 회귀 알고리즘에 대한 입력은 레이블/기능 벡터 쌍 집합이어야 합니다. 여기서 기능 벡터는 입력 지점을 나타내는 숫자의 벡터입니다.
따라서 범주 열을 숫자로 변환해야 합니다. 특히 trafficTimeBins 열과 weekdayString 열을 정수 표현으로 변환해야 합니다. 변환을 수행하는 방법에는 여러 가지가 있습니다. 다음 예제에서는 일반적인 접근 방식을 사용합니다 OneHotEncoder .
# Because the sample uses an algorithm that works only with numeric features, convert them so they can be consumed
sI1 = StringIndexer(inputCol="trafficTimeBins", outputCol="trafficTimeBinsIndex")
en1 = OneHotEncoder(dropLast=False, inputCol="trafficTimeBinsIndex", outputCol="trafficTimeBinsVec")
sI2 = StringIndexer(inputCol="weekdayString", outputCol="weekdayIndex")
en2 = OneHotEncoder(dropLast=False, inputCol="weekdayIndex", outputCol="weekdayVec")
# Create a new DataFrame that has had the encodings applied
encoded_final_df = Pipeline(stages=[sI1, en1, sI2, en2]).fit(taxi_featurised_df).transform(taxi_featurised_df)
이 작업을 수행하면 모델을 학습하는 데 적합한 형식의 모든 열이 있는 새 DataFrame이 생성됩니다.
로지스틱 회귀 모델 학습
첫 번째 작업은 데이터 세트를 학습 집합과 테스트 또는 유효성 검사 집합으로 분할하는 것입니다. 여기서 분할은 임의입니다. 다른 분할 설정을 실험하여 모델에 영향을 주는지 확인합니다.
# Decide on the split between training and testing data from the DataFrame
trainingFraction = 0.7
testingFraction = (1-trainingFraction)
seed = 1234
# Split the DataFrame into test and training DataFrames
train_data_df, test_data_df = encoded_final_df.randomSplit([trainingFraction, testingFraction], seed=seed)
이제 두 개의 DataFrame이 있으므로 다음 작업은 모델 수식을 만들고 학습 DataFrame에 대해 실행하는 것입니다. 그런 다음 테스트 DataFrame에 대해 유효성을 검사할 수 있습니다. 모델 수식의 다양한 버전을 실험하여 다양한 조합의 영향을 확인합니다.
비고
모델을 저장하려면 Azure SQL Database 서버 리소스 범위에 Storage Blob 데이터 기여자 역할을 할당합니다. 세부 단계에 대해서는 Azure Portal을 사용하여 Azure 역할 할당을 참조하세요. 소유자 권한이 있는 멤버만 이 단계를 수행할 수 있습니다.
## Create a new logistic regression object for the model
logReg = LogisticRegression(maxIter=10, regParam=0.3, labelCol = 'tipped')
## The formula for the model
classFormula = RFormula(formula="tipped ~ pickupHour + weekdayVec + passengerCount + tripTimeSecs + tripDistance + fareAmount + paymentType+ trafficTimeBinsVec")
## Undertake training and create a logistic regression model
lrModel = Pipeline(stages=[classFormula, logReg]).fit(train_data_df)
## Saving the model is optional, but it's another form of inter-session cache
datestamp = datetime.now().strftime('%m-%d-%Y-%s')
fileName = "lrModel_" + datestamp
logRegDirfilename = fileName
lrModel.save(logRegDirfilename)
## Predict tip 1/0 (yes/no) on the test dataset; evaluation using area under ROC
predictions = lrModel.transform(test_data_df)
predictionAndLabels = predictions.select("label","prediction").rdd
metrics = BinaryClassificationMetrics(predictionAndLabels)
print("Area under ROC = %s" % metrics.areaUnderROC)
이 셀의 출력은 다음과 같습니다.
Area under ROC = 0.9779470729751403
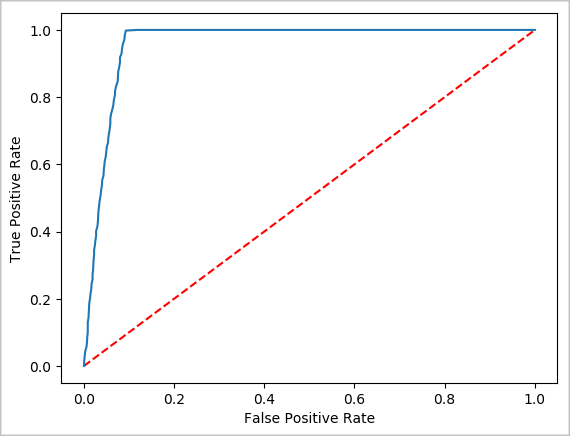
예측의 시각적 표현 만들기
이제 최종 시각화를 생성하여 이 테스트의 결과를 추론할 수 있습니다. ROC 곡선은 결과를 검토하는 한 가지 방법입니다.
## Plot the ROC curve; no need for pandas, because this uses the modelSummary object
modelSummary = lrModel.stages[-1].summary
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(modelSummary.roc.select('FPR').collect(),
modelSummary.roc.select('TPR').collect())
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
Spark 인스턴스 종료
애플리케이션 실행을 완료한 후 탭을 닫아서 Notebook을 종료하여 리소스를 해제합니다. 또는 전자 필기장 아래쪽의 상태 패널에서 세션 종료 를 선택합니다.