Microsoft Spark 유틸리티 소개
MICROSOFT Spark 유틸리티(MSSparkUtils)는 일반적인 작업을 쉽게 수행할 수 있도록 도와주는 기본 제공 패키지입니다. MSSparkUtils를 사용하여 파일 시스템 작업을 하고, 환경 변수를 가져오고, Notebook을 서로 연결하고, 비밀을 사용할 수 있습니다. MSSparkUtils는 PySpark (Python), Scala, .NET Spark (C#) 및 R (Preview) Notebook 및 Synapse 파이프라인에서 사용할 수 있습니다.
필수 구성 요소
Azure Data Lake Storage Gen2에 대한 액세스 구성
Synapse Notebook은 Microsoft Entra 통과를 사용하여 ADLS Gen2 계정에 액세스합니다. ADLS Gen2 계정(또는 폴더)에 액세스하려면 Storage Blob 데이터 기여자여야 합니다.
Synapse 파이프라인은 작업 영역의 MSI(관리 서비스 ID)를 사용하여 스토리지 계정에 액세스합니다. 파이프라인 작업에서 MSSparkUtils를 사용하려면 ADLS Gen2 계정(또는 폴더)에 액세스하려면 작업 영역 ID가 Storage Blob 데이터 기여자여야 합니다.
다음 단계에 따라 Microsoft Entra ID 및 작업 영역 MSI가 ADLS Gen2 계정에 액세스할 수 있는지 확인합니다.
액세스하려는 Azure Portal 및 스토리지 계정을 엽니다. 액세스하려는 특정 컨테이너로 이동할 수 있습니다.
왼쪽 패널에서 액세스 제어(IAM) 를 선택합니다.
추가>를 선택하여 역할 할당 추가 페이지를 엽니다.
다음 역할을 할당합니다. 세부 단계에 대해서는 Azure Portal을 사용하여 Azure 역할 할당을 참조하세요.
설정 값 역할 Storage Blob 데이터 Contributor 다음에 대한 액세스 할당 USER 및 MANAGEDIDENTITY 멤버 Microsoft Entra 계정 및 작업 영역 ID 참고 항목
관리 ID 이름은 작업 영역 이름이기도 합니다.

저장을 선택합니다.
Synapse Spark를 사용하여 다음 URL을 통해 ADLS Gen2의 데이터에 액세스할 수 있습니다.
abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<path>
Azure Blob Storage에 대한 액세스 구성
Synapse는 SAS(공유 액세스 서명)를 사용하여 Azure Blob Storage에 액세스합니다. 코드에서 SAS 키를 노출하지 않으려면 Synapse 작업 영역에서 액세스하려는 Azure Blob Storage 계정에 연결된 새 서비스를 만드는 것이 좋습니다.
Azure Blob Storage 계정을 위한 새 연결된 서비스를 추가하려면 다음 단계를 수행합니다.
- Azure Synapse Studio를 엽니다.
- 왼쪽 패널에서 관리를 선택하고 외부 연결 아래에서 연결된 서비스를 선택합니다.
- 오른쪽의 새 연결된 서비스 패널에서 Azure Blob Storage를 검색합니다.
- 계속을 선택합니다.
- 연결된 서비스 이름에 액세스하고 구성하려면 Azure Blob Storage 계정을 선택합니다. 인증 방법에 계정 키를 사용하는 것이 좋습니다.
- 테스트 연결을 선택하여 설정이 올바른지 확인합니다.
- 먼저 만들기를 선택하고 모두 게시를 클릭하여 변경 내용을 저장합니다.
다음 URL을 통해 Synapse Spark를 사용하여 Azure Blob Storage의 데이터에 액세스할 수 있습니다.
wasb[s]://<container_name>@<storage_account_name>.blob.core.windows.net/<path>
코드 예제는 다음과 같습니다.
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
val blob_account_name = "" // replace with your blob name
val blob_container_name = "" //replace with your container name
val blob_relative_path = "/" //replace with your relative folder path
val linked_service_name = "" //replace with your linked service name
val blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
val wasbs_path = f"wasbs://$blob_container_name@$blob_account_name.blob.core.windows.net/$blob_relative_path"
spark.conf.set(f"fs.azure.sas.$blob_container_name.$blob_account_name.blob.core.windows.net",blob_sas_token)
var blob_account_name = ""; // replace with your blob name
var blob_container_name = ""; // replace with your container name
var blob_relative_path = ""; // replace with your relative folder path
var linked_service_name = ""; // replace with your linked service name
var blob_sas_token = Credentials.GetConnectionStringOrCreds(linked_service_name);
spark.Conf().Set($"fs.azure.sas.{blob_container_name}.{blob_account_name}.blob.core.windows.net", blob_sas_token);
var wasbs_path = $"wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}";
Console.WriteLine(wasbs_path);
# Azure storage access info
blob_account_name <- 'Your account name' # replace with your blob name
blob_container_name <- 'Your container name' # replace with your container name
blob_relative_path <- 'Your path' # replace with your relative folder path
linked_service_name <- 'Your linked service name' # replace with your linked service name
blob_sas_token <- mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
sparkR.session()
wasb_path <- sprintf('wasbs://%s@%s.blob.core.windows.net/%s',blob_container_name, blob_account_name, blob_relative_path)
sparkR.session(sprintf('fs.azure.sas.%s.%s.blob.core.windows.net',blob_container_name, blob_account_name), blob_sas_token)
print( paste('Remote blob path: ',wasb_path))
Azure Key Vault에 대한 액세스 구성
Azure Key Vault를 연결된 서비스로 추가하여 Synapse에서 자격 증명을 관리할 수 있습니다. 다음 단계에 따라 Azure Key Vault를 Synapse 연결된 서비스로 추가합니다.
왼쪽 패널에서 관리를 선택하고 외부 연결 아래에서 연결된 서비스를 선택합니다.
오른쪽의 새 연결된 서비스 패널에서 Azure Key Vault를 검색합니다.
연결된 서비스 이름에 액세스하고 구성하려면 Azure Key Vault 계정을 선택합니다.
테스트 연결을 선택하여 설정이 올바른지 확인합니다.
먼저 만들기를 선택하고 모두 게시를 클릭하여 변경 내용을 저장합니다.
Synapse Notebook은 Microsoft Entra 통과를 사용하여 Azure Key Vault에 액세스합니다. Synapse 파이프라인은 MSI(작업 영역 ID)를 사용하여 Azure Key Vault에 액세스합니다. Notebook 및 Synapse 파이프라인에서 코드가 작동하는지 확인하려면 Microsoft Entra 계정 및 작업 영역 ID 모두에 대한 비밀 액세스 권한을 부여하는 것이 좋습니다.
다음 단계에 따라 작업 영역 ID에 대한 비밀 액세스 권한을 부여합니다.
- 액세스하려는 Azure Portal 및 Azure Key Vault를 엽니다.
- 왼쪽 창에서 액세스 정책을 선택합니다.
- 액세스 정책 추가를 선택합니다.
- 키, 비밀 밀 인증서 관리를 구성 템플릿으로 선택합니다.
- 선택한 보안 주체에서 Microsoft Entra 계정 및 작업 영역 ID (작업 영역 이름과 동일)를 선택하거나 이미 할당되었는지 확인합니다.
- 선택 및 추가를 선택합니다.
- 저장 단추를 선택하여 변경 내용을 커밋합니다.
파일 시스템 유틸리티
mssparkutils.fs 에서는 ADLS Gen2(Azure Data Lake Storage Gen2) 및 Azure Blob Storage를 비롯한 다양한 파일 시스템을 사용하기 위한 유틸리티를 제공합니다. Azure Data Lake Storage Gen2 및 Azure Blob Storage에 대한 액세스를 적절하게 구성해야 합니다.
사용 가능한 메서드에 관한 개요를 가져오려면 다음 명령을 실행합니다.
from notebookutils import mssparkutils
mssparkutils.fs.help()
mssparkutils.fs.help()
using Microsoft.Spark.Extensions.Azure.Synapse.Analytics.Notebook.MSSparkUtils;
FS.Help()
library(notebookutils)
mssparkutils.fs.help()
결과:
mssparkutils.fs provides utilities for working with various FileSystems.
Below is overview about the available methods:
cp(from: String, to: String, recurse: Boolean = false): Boolean -> Copies a file or directory, possibly across FileSystems
mv(src: String, dest: String, create_path: Boolean = False, overwrite: Boolean = False): Boolean -> Moves a file or directory, possibly across FileSystems
ls(dir: String): Array -> Lists the contents of a directory
mkdirs(dir: String): Boolean -> Creates the given directory if it does not exist, also creating any necessary parent directories
put(file: String, contents: String, overwrite: Boolean = false): Boolean -> Writes the given String out to a file, encoded in UTF-8
head(file: String, maxBytes: int = 1024 * 100): String -> Returns up to the first 'maxBytes' bytes of the given file as a String encoded in UTF-8
append(file: String, content: String, createFileIfNotExists: Boolean): Boolean -> Append the content to a file
rm(dir: String, recurse: Boolean = false): Boolean -> Removes a file or directory
Use mssparkutils.fs.help("methodName") for more info about a method.
파일 나열
디렉터리의 콘텐츠를 나열합니다.
mssparkutils.fs.ls('Your directory path')
mssparkutils.fs.ls("Your directory path")
FS.Ls("Your directory path")
mssparkutils.fs.ls("Your directory path")
파일 속성 보기
파일 이름, 파일 경로, 파일 크기, 파일 수정 시간, 디렉터리인지 파일인지 여부 등의 파일 속성을 반환합니다.
files = mssparkutils.fs.ls('Your directory path')
for file in files:
print(file.name, file.isDir, file.isFile, file.path, file.size, file.modifyTime)
val files = mssparkutils.fs.ls("/")
files.foreach{
file => println(file.name,file.isDir,file.isFile,file.size,file.modifyTime)
}
var Files = FS.Ls("/");
foreach(var File in Files) {
Console.WriteLine(File.Name+" "+File.IsDir+" "+File.IsFile+" "+File.Size);
}
files <- mssparkutils.fs.ls("/")
for (file in files) {
writeLines(paste(file$name, file$isDir, file$isFile, file$size, file$modifyTime))
}
새 디렉터리 만들기
지정된 디렉터리가 없는 경우 해당 디렉터리와 필요한 부모 디렉터리를 만듭니다.
mssparkutils.fs.mkdirs('new directory name')
mssparkutils.fs.mkdirs("new directory name")
FS.Mkdirs("new directory name")
mssparkutils.fs.mkdirs("new directory name")
파일 복사
파일 또는 디렉터리를 복사합니다. 파일 시스템에서 복사를 지원합니다.
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)# Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
FS.Cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)
성능 복사 파일
이 메서드는 파일, 특히 대량의 데이터를 더 빠르게 복사하거나 이동하는 방법을 제공합니다.
mssparkutils.fs.fastcp('source file or directory', 'destination file or directory', True) # Set the third parameter as True to copy all files and directories recursively
참고 항목
이 메서드는 Apache Spark 3.3용 Azure Synapse 런타임 및 Apache Spark 3.4용 Azure Synapse 런타임에서만 지원합니다.
파일 콘텐츠 미리 보기
지정된 파일의 첫 번째 'maxBytes' 바이트를 UTF-8로 인코딩된 문자열로 반환합니다.
mssparkutils.fs.head('file path', maxBytes to read)
mssparkutils.fs.head("file path", maxBytes to read)
FS.Head("file path", maxBytes to read)
mssparkutils.fs.head('file path', maxBytes to read)
파일 이동
파일 또는 디렉터리를 이동합니다. 파일 시스템 간 이동을 지원합니다.
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
mssparkutils.fs.mv("source file or directory", "destination directory", true) // Set the last parameter as True to firstly create the parent directory if it does not exist
FS.Mv("source file or directory", "destination directory", true)
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
파일 쓰기
지정된 문자열을 UTF-8으로 인코딩된 파일에 씁니다.
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
FS.Put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
파일에 콘텐츠 추가
지정된 문자열을 UTF-8으로 인코딩된 파일에 추가합니다.
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path","content to append",true) // Set the last parameter as True to create the file if it does not exist
FS.Append("file path", "content to append", true) // Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
참고 항목
mssparkutils.fs.append()원mssparkutils.fs.put()자성 보장이 부족하여 동일한 파일에 대한 동시 쓰기를 지원하지 않습니다.- 루프에서
mssparkutils.fs.appendAPI를for사용하여 동일한 파일에 쓰는 경우 되풀이 쓰기 사이에 약 0.5s~1s 문을 추가하는sleep것이 좋습니다.mssparkutils.fs.append이는 API의 내부flush작업이 비동기적이므로 짧은 지연이 데이터 무결성을 보장하는 데 도움이 되므로
파일 또는 디렉터리 삭제
파일 또는 디렉터리를 제거합니다.
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
FS.Rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
Notebook 유틸리티
지원되지 않습니다.
MSSparkUtils Notebook 유틸리티를 사용하여 Notebook을 실행하거나 값이 있는 Notebook을 종료할 수 있습니다. 사용 가능한 메서드에 관한 개요를 가져오려면 다음 명령을 실행합니다.
mssparkutils.notebook.help()
결과 가져오기:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
참고 항목
Notebook 유틸리티는 Apache Spark SJD(작업 정의)에 적용되지 않습니다.
Notebook 참조
Notebook을 참조하고 종료 값을 반환합니다. Notebook 또는 파이프라인에서 중첩 함수 호출을 실행할 수 있습니다. 참조 중인 Notebook은 Notebook이 이 함수를 호출하는 Spark 풀에서 실행됩니다.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
예시:
mssparkutils.notebook.run("folder/Sample1", 90, {"input": 20 })
실행이 완료된 후 셀 출력에 ‘Notebook 실행 보기: Notebook 이름’이라는 스냅샷 링크가 표시됩니다. 링크를 클릭하여 이 특정 실행에 대한 스냅샷을 확인할 수 있습니다.

참조는 여러 Notebook을 병렬로 실행합니다.
mssparkutils.notebook.runMultiple() 메서드를 사용하면 여러 Notebook을 병렬로 실행하거나 미리 정의된 토폴로지 구조로 실행할 수 있습니다. API는 Spark 세션 내에서 다중 스레드 구현 메커니즘을 사용하고 있습니다. 즉, 참조 Notebook 실행에서 컴퓨팅 리소스를 공유합니다.
mssparkutils.notebook.runMultiple()로 다음을 수행할 수 있습니다.
각 Notebook이 완료되는 것을 기다리지 않고 동시에 여러 Notebook을 실행합니다.
간단한 JSON 형식을 사용하여 Notebook에 대한 종속성 및 실행 순서를 지정합니다.
Spark 컴퓨팅 리소스 사용을 최적화하고 Synapse 프로젝트의 비용을 절감합니다.
출력에서 각 Notebook 실행 레코드의 스냅샷을 보고 Notebook 작업을 편리하게 디버그/모니터링합니다.
각 임원 활동의 종료 값을 가져와 다운스트림 작업에 사용합니다.
mssparkutils.notebook.help("runMultiple")를 실행하여 예제 및 자세한 사용량을 찾을 수도 있습니다.
다음은 이 방법을 사용하여 Notebook 목록을 병렬로 실행하는 간단한 예제입니다.
mssparkutils.notebook.runMultiple(["NotebookSimple", "NotebookSimple2"])
루트 Notebook의 실행 결과는 다음과 같습니다.

다음은 토폴로지 구조 mssparkutils.notebook.runMultiple()를 사용하여 Notebook을 실행하는 예제입니다. 이 메서드를 사용하여 코드 환경을 통해 Notebook을 쉽게 오케스트레이션할 수 있습니다.
# run multiple notebooks with parameters
DAG = {
"activities": [
{
"name": "NotebookSimple", # activity name, must be unique
"path": "NotebookSimple", # notebook path
"timeoutPerCellInSeconds": 90, # max timeout for each cell, default to 90 seconds
"args": {"p1": "changed value", "p2": 100}, # notebook parameters
},
{
"name": "NotebookSimple2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 2", "p2": 200}
},
{
"name": "NotebookSimple2.2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 3", "p2": 300},
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["NotebookSimple"] # list of activity names that this activity depends on
}
]
}
mssparkutils.notebook.runMultiple(DAG)
참고 항목
- 이 메서드는 Apache Spark 3.3용 Azure Synapse 런타임 및 Apache Spark 3.4용 Azure Synapse 런타임에서만 지원합니다.
- 여러 Notebook 실행의 병렬 처리 수준은 Spark 세션의 사용 가능한 총 컴퓨팅 리소스로 제한됩니다.
Notebook 편집
값이 있는 Notebook을 종료합니다. Notebook 또는 파이프라인에서 중첩 함수 호출을 실행할 수 있습니다.
Notebook에서 exit() 함수를 대화형으로 호출하면 Azure Synapse는 예외를 발생시키고 하위 시퀀스 셀 실행을 건너뛰며 Spark 세션을 활성 상태로 유지합니다.
Synapse 파이프라인에서 함수를
exit()호출하는 Notebook을 오케스트레이션하는 경우 Azure Synapse는 종료 값을 반환하고 파이프라인 실행을 완료하며 Spark 세션을 중지합니다.참조되는 Notebook에서 함수를 호출
exit()하면 Azure Synapse는 참조되는 Notebook의 추가 실행을 중지하고 함수를 호출run()하는 Notebook에서 다음 셀을 계속 실행합니다. 예를 들어 Notebook1에는 세 개의 셀이 있으며 두 번째 셀에서 함수를 호출exit()합니다. Notebook2에는 세 번째 셀에 5개의 셀과 호출run(notebook1)이 있습니다. Notebook2를 실행하면 함수를 누르면exit()Notebook1이 두 번째 셀에서 중지됩니다. Notebook2는 네 번째 셀과 다섯 번째 셀을 계속 실행합니다.
mssparkutils.notebook.exit("value string")
예시:
Sample1 Notebook은 다음 두 개의 셀을 사용하여 폴더 아래를 찾습니다.
- 셀 1은 기본값이 10으로 설정된 입력 매개 변수를 정의합니다.
- 셀 2는 입력을 종료 값으로 사용하여 Notebook을 종료합니다.
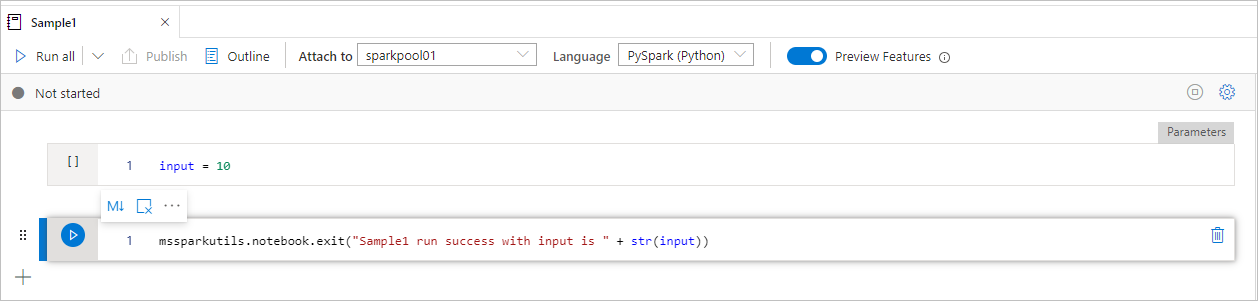
기본값을 사용하여 다른 Notebook에서 Sample1을 실행할 수 있습니다.
exitVal = mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
결과:
Sample1 run success with input is 10
다른 Notebook에서 Sample1을 실행하고 입력 값을 20으로 설정할 수 있습니다.
exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print (exitVal)
결과:
Sample1 run success with input is 20
MSSparkUtils Notebook 유틸리티를 사용하여 Notebook을 실행하거나 값이 있는 Notebook을 종료할 수 있습니다. 사용 가능한 메서드에 관한 개요를 가져오려면 다음 명령을 실행합니다.
mssparkutils.notebook.help()
결과 가져오기:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Notebook 참조
Notebook을 참조하고 종료 값을 반환합니다. Notebook 또는 파이프라인에서 중첩 함수 호출을 실행할 수 있습니다. 참조 중인 Notebook은 Notebook이 이 함수를 호출하는 Spark 풀에서 실행됩니다.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
예시:
mssparkutils.notebook.run("folder/Sample1", 90, Map("input" -> 20))
실행이 완료된 후 셀 출력에 ‘Notebook 실행 보기: Notebook 이름’이라는 스냅샷 링크가 표시됩니다. 링크를 클릭하여 이 특정 실행에 대한 스냅샷을 확인할 수 있습니다.
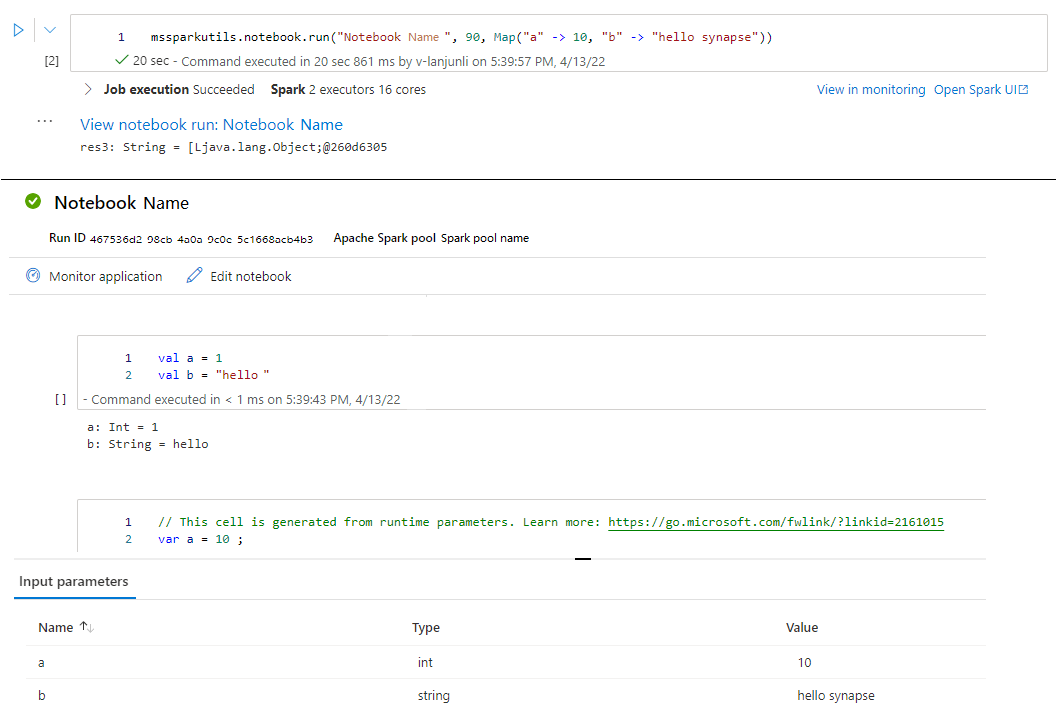
Notebook 편집
값이 있는 Notebook을 종료합니다. Notebook 또는 파이프라인에서 중첩 함수 호출을 실행할 수 있습니다.
함수를
exit()Notebook을 대화형으로 호출하면 Azure Synapse에서 예외를 throw하고, 하위 시퀀스 셀 실행을 건너뛰고, Spark 세션을 활성 상태로 유지합니다.Synapse 파이프라인에서 함수를
exit()호출하는 Notebook을 오케스트레이션하는 경우 Azure Synapse는 종료 값을 반환하고 파이프라인 실행을 완료하며 Spark 세션을 중지합니다.참조되는 Notebook에서 함수를 호출
exit()하면 Azure Synapse는 참조되는 Notebook의 추가 실행을 중지하고 함수를 호출run()하는 Notebook에서 다음 셀을 계속 실행합니다. 예를 들어 Notebook1에는 세 개의 셀이 있으며 두 번째 셀에서 함수를 호출exit()합니다. Notebook2에는 세 번째 셀에 5개의 셀과 호출run(notebook1)이 있습니다. Notebook2를 실행하면 함수를 누르면exit()Notebook1이 두 번째 셀에서 중지됩니다. Notebook2는 네 번째 셀과 다섯 번째 셀을 계속 실행합니다.
mssparkutils.notebook.exit("value string")
예시:
Sample1 Notebook은 mssparkutils/folder/ 아래에 다음 두 개의 셀을 찾습니다.
- 셀 1은 기본값이 10으로 설정된 입력 매개 변수를 정의합니다.
- 셀 2는 입력을 종료 값으로 사용하여 Notebook을 종료합니다.
기본값을 사용하여 다른 Notebook에서 Sample1을 실행할 수 있습니다.
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1")
print(exitVal)
결과:
exitVal: String = Sample1 run success with input is 10
Sample1 run success with input is 10
다른 Notebook에서 Sample1을 실행하고 입력 값을 20으로 설정할 수 있습니다.
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print(exitVal)
결과:
exitVal: String = Sample1 run success with input is 20
Sample1 run success with input is 20
MSSparkUtils Notebook 유틸리티를 사용하여 Notebook을 실행하거나 값이 있는 Notebook을 종료할 수 있습니다. 사용 가능한 메서드에 관한 개요를 가져오려면 다음 명령을 실행합니다.
mssparkutils.notebook.help()
결과 가져오기:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Notebook 참조
Notebook을 참조하고 종료 값을 반환합니다. Notebook 또는 파이프라인에서 중첩 함수 호출을 실행할 수 있습니다. 참조 중인 Notebook은 Notebook이 이 함수를 호출하는 Spark 풀에서 실행됩니다.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
예시:
mssparkutils.notebook.run("folder/Sample1", 90, list("input": 20))
실행이 완료된 후 셀 출력에 ‘Notebook 실행 보기: Notebook 이름’이라는 스냅샷 링크가 표시됩니다. 링크를 클릭하여 이 특정 실행에 대한 스냅샷을 확인할 수 있습니다.
Notebook 편집
값이 있는 Notebook을 종료합니다. Notebook 또는 파이프라인에서 중첩 함수 호출을 실행할 수 있습니다.
함수를
exit()Notebook을 대화형으로 호출하면 Azure Synapse에서 예외를 throw하고, 하위 시퀀스 셀 실행을 건너뛰고, Spark 세션을 활성 상태로 유지합니다.Synapse 파이프라인에서 함수를
exit()호출하는 Notebook을 오케스트레이션하는 경우 Azure Synapse는 종료 값을 반환하고 파이프라인 실행을 완료하며 Spark 세션을 중지합니다.참조되는 Notebook에서 함수를 호출
exit()하면 Azure Synapse는 참조되는 Notebook의 추가 실행을 중지하고 함수를 호출run()하는 Notebook에서 다음 셀을 계속 실행합니다. 예를 들어 Notebook1에는 세 개의 셀이 있으며 두 번째 셀에서 함수를 호출exit()합니다. Notebook2에는 세 번째 셀에 5개의 셀과 호출run(notebook1)이 있습니다. Notebook2를 실행하면 함수를 누르면exit()Notebook1이 두 번째 셀에서 중지됩니다. Notebook2는 네 번째 셀과 다섯 번째 셀을 계속 실행합니다.
mssparkutils.notebook.exit("value string")
예시:
Sample1 Notebook은 다음 두 개의 셀을 사용하여 폴더 아래를 찾습니다.
- 셀 1은 기본값이 10으로 설정된 입력 매개 변수를 정의합니다.
- 셀 2는 입력을 종료 값으로 사용하여 Notebook을 종료합니다.
기본값을 사용하여 다른 Notebook에서 Sample1을 실행할 수 있습니다.
exitVal <- mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
결과:
Sample1 run success with input is 10
다른 Notebook에서 Sample1을 실행하고 입력 값을 20으로 설정할 수 있습니다.
exitVal <- mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, list("input": 20))
print (exitVal)
결과:
Sample1 run success with input is 20
자격 증명 유틸리티
MSSparkUtils 자격 증명 유틸리티를 사용하여 연결된 서비스의 액세스 토큰을 가져오고 Azure Key Vault에서 비밀을 관리할 수 있습니다.
사용 가능한 메서드에 관한 개요를 가져오려면 다음 명령을 실행합니다.
mssparkutils.credentials.help()
mssparkutils.credentials.help()
Not supported.
mssparkutils.credentials.help()
결과 가져오기:
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
참고 항목
현재 getSecretWithLS(linkedService, secret)는 C#에서 지원되지 않습니다.
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
토큰 가져오기
지정된 대상 그룹 이름(선택 사항)에 대한 Microsoft Entra 토큰을 반환합니다. 다음 표에서는 사용 가능한 모든 대상 그룹 형식을 나열합니다.
| 대상 형식 | API 호출에 사용되는 문자열 리터럴 |
|---|---|
| Azure Storage | Storage |
| Azure Key Vault | Vault |
| Azure Management | AzureManagement |
| Azure SQL Data Warehouse(전용 및 서버리스) | DW |
| Azure Synapse | Synapse |
| Azure Data Lake Storage | DataLakeStore |
| Azure Data Factory | ADF |
| Azure Data Explorer | AzureDataExplorer |
| Azure Database for MySQL | AzureOSSDB |
| Azure Database for MariaDB | AzureOSSDB |
| Azure Database for PostgreSQL | AzureOSSDB |
mssparkutils.credentials.getToken('audience Key')
mssparkutils.credentials.getToken("audience Key")
Credentials.GetToken("audience Key")
mssparkutils.credentials.getToken('audience Key')
토큰 유효성 검사
토큰이 만료되지 않은 경우 true를 반환합니다.
mssparkutils.credentials.isValidToken('your token')
mssparkutils.credentials.isValidToken("your token")
Credentials.IsValidToken("your token")
mssparkutils.credentials.isValidToken('your token')
연결된 서비스에 대한 연결 문자열 또는 자격 증명 가져오기
연결된 서비스에 대한 연결 문자열 또는 자격 증명을 반환합니다.
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
mssparkutils.credentials.getConnectionStringOrCreds("linked service name")
Credentials.GetConnectionStringOrCreds("linked service name")
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
작업 영역 ID를 사용하여 비밀 가져오기
작업 영역 ID를 사용하여 지정된 Azure Key Vault 이름, 비밀 이름 및 연결된 서비스 이름에 대한 Azure Key Vault 비밀을 반환합니다. Azure Key Vault에 대한 액세스를 적절하게 구성해야 합니다.
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
mssparkutils.credentials.getSecret("azure key vault name","secret name","linked service name")
Credentials.GetSecret("azure key vault name","secret name","linked service name")
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
사용자 자격 증명을 사용하여 비밀 얻기
사용자 자격 증명을 사용하여 지정된 Azure Key Vault 이름, 비밀 이름 및 연결된 서비스 이름에 대한 Azure Key Vault 비밀을 반환합니다.
mssparkutils.credentials.getSecret('azure key vault name','secret name')
mssparkutils.credentials.getSecret("azure key vault name","secret name")
Credentials.GetSecret("azure key vault name","secret name")
mssparkutils.credentials.getSecret('azure key vault name','secret name')
작업 영역 ID를 사용하여 비밀 배치
작업 영역 ID를 사용하여 지정된 Azure Key Vault 이름, 비밀 이름, 연결된 서비스 이름을 위한 Azure Key Vault 비밀을 넣습니다. Azure Key Vault에 대한 액세스를 적절하게 구성해야 합니다.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
작업 영역 ID를 사용하여 비밀 배치
작업 영역 ID를 사용하여 지정된 Azure Key Vault 이름, 비밀 이름, 연결된 서비스 이름을 위한 Azure Key Vault 비밀을 넣습니다. Azure Key Vault에 대한 액세스를 적절하게 구성해야 합니다.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value","linked service name")
작업 영역 ID를 사용하여 비밀 배치
작업 영역 ID를 사용하여 지정된 Azure Key Vault 이름, 비밀 이름, 연결된 서비스 이름을 위한 Azure Key Vault 비밀을 넣습니다. Azure Key Vault에 대한 액세스를 적절하게 구성해야 합니다.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
사용자 자격 증명을 사용하여 비밀 입력
사용자 자격 증명을 사용하여 지정된 Azure Key Vault 이름, 비밀 이름 및 연결된 서비스 이름에 대한 Azure Key Vault 비밀을 넣습니다.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
사용자 자격 증명을 사용하여 비밀 입력
사용자 자격 증명을 사용하여 지정된 Azure Key Vault 이름, 비밀 이름 및 연결된 서비스 이름에 대한 Azure Key Vault 비밀을 넣습니다.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
사용자 자격 증명을 사용하여 비밀 입력
사용자 자격 증명을 사용하여 지정된 Azure Key Vault 이름, 비밀 이름 및 연결된 서비스 이름에 대한 Azure Key Vault 비밀을 넣습니다.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value")
환경 유틸리티
사용 가능한 메서드에 관한 개요를 가져오려면 다음 명령을 실행합니다.
mssparkutils.env.help()
mssparkutils.env.help()
mssparkutils.env.help()
Env.Help()
결과 가져오기:
getUserName(): returns user name
getUserId(): returns unique user id
getJobId(): returns job id
getWorkspaceName(): returns workspace name
getPoolName(): returns Spark pool name
getClusterId(): returns cluster id
사용자 이름 가져오기
현재 사용자 이름을 반환합니다.
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
Env.GetUserName()
사용자 ID 가져오기
현재 사용자 ID를 반환합니다.
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
Env.GetUserId()
작업 ID 가져오기
작업 ID를 반환합니다.
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
Env.GetJobId()
작업 영역 이름 가져오기
작업 영역 이름을 반환합니다.
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
Env.GetWorkspaceName()
풀 이름 가져오기
Spark 풀 이름을 반환합니다.
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
Env.GetPoolName()
클러스터 ID 가져오기
현재 클러스터 ID를 반환합니다.
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
Env.GetClusterId()
런타임 컨텍스트
Mssparkutils 런타임 유틸리티는 3개의 런타임 속성을 노출하고, Mssparkutils 런타임 컨텍스트를 사용하여 아래와 같이 나열된 속성을 가져올 수 있습니다.
- Notebookname - 현재 Notebook의 이름은 항상 대화형 모드와 파이프라인 모드 둘 다에 대한 값을 반환합니다.
- Pipelinejobid - 파이프라인 실행 ID는 파이프라인 모드에서 값을 반환하고 대화형 모드에서 빈 문자열을 반환합니다.
- Activityrunid - Notebook 활동 실행 ID는 파이프라인 모드에서 값을 반환하고 대화형 모드에서 빈 문자열을 반환합니다.
현재 런타임 컨텍스트는 Python 및 Scala를 모두 지원합니다.
mssparkutils.runtime.context
ctx <- mssparkutils.runtime.context()
for (key in ls(ctx)) {
writeLines(paste(key, ctx[[key]], sep = "\t"))
}
%%spark
mssparkutils.runtime.context
세션 관리
대화형 세션 중지
중지 단추를 수동으로 클릭하는 대신 코드에서 API를 호출하여 대화형 세션을 중지하는 것이 더 편리한 경우도 있습니다. 이러한 경우 코드를 통해 대화형 세션 중지를 지원하는 API mssparkutils.session.stop()을 제공하며 Scala 및 Python에서 사용할 수 있습니다.
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop() API는 백그라운드에서 현재 대화형 세션을 비동기적으로 중지하고, Spark 세션을 중지하고, 세션이 차지하는 리소스를 해제하여 동일한 풀의 다른 세션에서 사용할 수 있도록 합니다.
참고 항목
코드에서 Scala의 sys.exit 또는 Python의 sys.exit()와 같은 기본 제공 API를 호출하지 않는 것이 좋습니다. 이러한 API는 인터프리터 프로세스를 종료하여 Spark 세션이 활성 상태로 유지되고 리소스가 해제되지 않기 때문입니다.
패키지 종속성
Notebook 또는 작업을 로컬로 개발하고 컴파일/IDE 힌트에 대한 관련 패키지를 참조해야 하는 경우 다음 패키지를 사용할 수 있습니다.