팁
Microsoft Fabric Data Warehouse는 데이터 레이크 기반의 엔터프라이즈 규모 관계형 웨어하우스로, 미래 대비 아키텍처, 기본 제공 AI 및 새로운 기능을 제공합니다. 데이터 웨어하우징이 처음이라면, Fabric Data Warehouse부터 시작하세요. 기존
OPENROWSET(BULK...) 함수를 사용하여 Azure Storage의 파일에 액세스할 수 있습니다.
OPENROWSET 함수는 원격 데이터 소스의 콘텐츠(예: 파일)를 읽고 이 콘텐츠를 일련의 행으로 반환합니다. 서버리스 SQL 풀 리소스 내에서 OPENROWSET 함수를 호출하고 BULK 옵션을 지정하여 OPENROWSET 대량 행 집합 공급자에 액세스합니다.
OPENROWSET 함수는 쿼리의 FROM 절에서 테이블 이름 OPENROWSET인 것처럼 참조될 수 있습니다. 이 함수는 파일의 데이터를 읽어서 행 세트로 반환할 수 있는 기본 제공 BULK 공급자를 통해 대량 작업을 지원합니다.
참고
OPENROWSET 함수는 전용 SQL 풀에서 지원되지 않습니다.
데이터 원본
Synapse SQL의 OPENROWSET 함수는 데이터 원본에서 파일 콘텐츠를 읽습니다. 데이터 소스는 Azure 스토리지 계정이며 OPENROWSET 함수에서 명시적으로 참조되거나 읽으려는 파일의 URL에서 동적으로 유추될 수 있습니다.
OPENROWSET 함수는 파일을 포함하는 데이터 소스를 지정하는 DATA_SOURCE 매개 변수를 선택적으로 포함할 수 있습니다.
OPENROWSET가 없는DATA_SOURCE는BULK옵션으로 지정된 URL 위치에서 파일의 콘텐츠를 직접 읽는 데 사용할 수 있습니다.SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
이 방법을 활용하면 사전 구성을 하지 않고도 파일 콘텐츠를 쉽고 빠르게 읽을 수 있습니다. 이 옵션을 사용하면 기본 인증 옵션을 사용하여 스토리지에 액세스할 수 있습니다(Microsoft Entra 로그인의 경우 Microsoft Entra 통과, SQL 로그인의 경우 SAS 토큰).
OPENROWSET가 있는DATA_SOURCE는 지정된 스토리지 계정의 파일에 액세스하는 데 사용할 수 있습니다.SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]이 옵션을 사용하면 데이터 소스에서 스토리지 계정의 위치를 구성하고 스토리지에 액세스하는 데 사용해야 하는 인증 방법을 지정할 수 있습니다.
중요
OPENROWSET가 있는DATA_SOURCE는 스토리지 파일에 쉽고 빠르게 액세스하는 방법을 제공하지만 제한된 인증 옵션을 제공합니다. 예를 들어 Microsoft Entra 주체는 Microsoft Entra ID 또는 공개적으로 사용 가능한 파일을 통해서만 파일에 액세스할 수 있습니다. 더 강력한 인증 옵션이 필요하면DATA_SOURCE옵션을 사용하고 스토리지에 액세스하는 데 사용할 자격 증명을 정의하십시오.
보안
데이터베이스 사용자가 ADMINISTER BULK OPERATIONS 함수를 사용하려면 OPENROWSET 권한이 있어야 합니다.
또한 스토리지 관리자는 유효한 SAS 토큰을 제공하거나 Microsoft Entra 주체가 스토리지 파일에 액세스하도록 설정하여 사용자가 파일에 액세스할 수 있도록 해야 합니다. 스토리지 액세스 제어에 대한 자세한 내용은 이 문서를 참조하세요.
OPENROWSET는 다음 규칙을 사용하여 스토리지 인증 방법을 결정합니다.
-
OPENROWSET가 없는DATA_SOURCE에서 인증 메커니즘은 호출자 유형에 따라 달라집니다.- 모든 사용자는
OPENROWSET없이DATA_SOURCE를 사용하여 Azure 스토리지에서 공개적으로 사용 가능한 파일을 읽을 수 있습니다. - Azure 스토리지에서 Microsoft Entra 사용자가 기본 파일에 액세스할 수 있도록 허용된 경우(예: 호출자에게 Azure 스토리지에 대한 권한이 있는 경우) Microsoft Entra 로그인은 자체
Storage Reader를 사용하여 보호된 파일에 액세스할 수 있습니다. - SQL 로그인도
OPENROWSET없이DATA_SOURCE를 사용하여 공개적으로 사용 가능한 파일, SAS 토큰으로 보호된 파일 또는 Synapse 작업 영역의 관리 ID에 액세스할 수 있습니다. 스토리지 파일에 대한 액세스를 허용하려면 서버 범위 자격 증명을 만들어야 합니다.
- 모든 사용자는
-
OPENROWSET가 있는DATA_SOURCE에서 인증 메커니즘은 참조된 데이터 원본에 할당된 데이터베이스 범위 자격 증명에 정의됩니다. 이 옵션을 사용하면 공개적으로 사용 가능한 스토리지에 액세스하거나 SAS 토큰, 작업 영역의 관리 ID 또는 호출자의 Microsoft Entra ID(호출자가 Microsoft Entra 주체인 경우)를 사용하여 스토리지에 액세스할 수 있습니다.DATA_SOURCE가 공용이 아닌 Azure 스토리지를 참조하는 경우에는 데이터베이스 범위 자격 증명을 만들어서DATA SOURCE에서 참조하여 스토리지 파일에 대한 액세스를 허용해야 합니다.
호출자에게 자격 증명에 대한 REFERENCES 권한이 있어야 이 권한을 사용하여 스토리지를 인증할 수 있습니다.
구문
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
인수
쿼리할 대상 데이터를 포함하고 있는 입력 파일에 대해 세 가지 옵션을 선택할 수 있습니다. 유효한 값은 다음과 같습니다.
'CSV' - 행/열 구분 기호로 구분된 텍스트 파일을 포함합니다. 모든 문자를 필드 구분 기호로 사용할 수 있습니다. TSV: FIELDTERMINATOR = tab을 예로 들 수 있습니다.
'PARQUET' - Parquet 형식의 이진 파일입니다.
'DELTA' - Delta Lake(미리 보기) 형식으로 구성된 Parquet 파일 세트입니다.
공백이 포함된 값은 유효하지 않습니다. 예를 들어 'CSV '는 유효한 값이 아닙니다.
'unstructured_data_path'
데이터의 경로를 설정하는 unstructured_data_path는 절대 또는 상대 경로일 수 있습니다.
-
\<prefix>://\<storage_account_path>/\<storage_path>형식의 절대 경로를 사용하면 사용자가 파일을 직접 읽을 수 있습니다. -
<storage_path>형식의 상대 경로는DATA_SOURCE매개 변수와 함께 사용해야 하며 <에 정의된 >storage_account_pathEXTERNAL DATA SOURCE위치 내의 파일 패턴을 설명합니다.
아래에서 특정 외부 데이터 원본에 연결할 관련 <스토리지 계정 경로> 값을 찾을 수 있습니다.
| 외부 데이터 원본 | 접두사 | 스토리지 계정 경로 |
|---|---|---|
| Azure Blob Storage | http[s] | <storage_account>.blob.core.windows.net/path/file |
| Azure Blob Storage | wasb[s] | <container>@<storage_account>.blob.core.windows.net/path/file |
| Azure 데이터 레이크 Store Gen1 | http[s] | <storage_account>.azuredatalakestore.net/webhdfs/v1 |
| Azure 데이터 레이크 Store Gen2 | http[s] | <storage_account>.dfs.core.windows.net/path/file |
| Azure 데이터 레이크 Store Gen2 | abfs[s] | < >file_system@<account_name.dfs.core.windows.net/path/file> |
<저장_경로>
읽으려는 폴더 또는 파일을 가리키는 스토리지 내의 경로입니다. 경로가 컨테이너 또는 폴더를 가리키는 경우 해당 컨테이너 또는 폴더에서 모든 파일을 읽습니다. 하위 폴더의 파일은 포함되지 않습니다.
와일드카드 문자를 사용하여 여러 파일 또는 폴더를 대상으로 지정할 수 있습니다. 여러 비연속 와일드카드 문자를 사용할 수 있습니다.
다음은 /csv/population으로 시작하는 모든 폴더에서 population으로 시작하는 모든 csv 파일을 읽는 예제입니다.
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
unstructured_data_path를 폴더로 지정하면 서버리스 SQL 풀 쿼리가 해당 폴더에서 파일을 검색합니다.
다음 예제와 같이 /*를 경로 끝에 지정하여 서버리스 SQL 풀에서 폴더를 트래버스하도록 지시할 수 있습니다. https://sqlondemandstorage.blob.core.windows.net/csv/population/**
참고
Hadoop 및 PolyBase와 달리 /**를 경로 끝에 지정하지 않으면 서버리스 SQL 풀에서 하위 폴더를 반환하지 않습니다. Hadoop 및 PolyBase와 마찬가지로 파일 이름이 밑줄(_) 또는 마침표(.)로 시작하는 파일을 반환하지 않습니다.
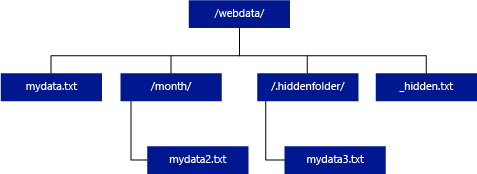
아래 예제에서 unstructured_data_path=https://mystorageaccount.dfs.core.windows.net/webdata/인 경우 서버리스 SQL 풀 쿼리는 mydata.txt에서 행을 반환합니다. mydata2.txt 및 mydata3.txt는 하위 폴더에 있으므로 반환되지 않습니다.
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
WITH 절을 사용하여 파일에서 읽을 열을 지정할 수 있습니다.
CSV 데이터 파일의 경우 모든 열을 읽으려면 열 이름과 해당 데이터 형식을 입력합니다. 열의 하위 세트를 원하는 경우 서수를 사용하여 원본 데이터 파일에서 서수를 기준으로 열을 선택합니다. 열은 서수 지정을 기준으로 바인딩됩니다. HEADER_ROW = TRUE를 사용하는 경우 열 바인딩은 서수 위치 대신 열 이름으로 수행됩니다.
팁
CSV 파일에서도 WITH 절을 생략할 수 있습니다. 데이터 형식은 파일 콘텐츠에서 자동으로 유추됩니다. HEADER_ROW 인수를 사용하여 헤더 행에서 열 이름을 읽을 때 헤더 행의 존재 여부를 지정할 수 있습니다. 자세한 내용은 자동 스키마 검색을 참조하세요.
Parquet 또는 Delta Lake 파일의 경우 원본 데이터 파일의 열 이름과 일치하는 열 이름을 입력합니다. 열은 이름으로 바인딩되고 대/소문자를 구분합니다. WITH 절을 생략하면 Parquet 파일의 모든 열이 반환됩니다.
중요
Parquet 및 Delta Lake 파일의 열 이름은 대/소문자를 구분합니다. 파일에서 열 이름 대/소문자 구분과 다른 대/소문자의 열 이름을 지정하면 해당 열에 대해
NULL값이 반환됩니다.
column_name은 출력 열의 이름입니다. 제공되는 경우 이 이름은 원본 파일의 열 이름과 JSON 경로에 제공된 열 이름(있는 경우)을 재정의합니다. json_path가 제공되지 않으면 '$.column_name'으로 자동 추가됩니다. 동작에 대한 json_path 인수를 확인합니다.
column_type은 출력 열의 데이터 형식입니다. 여기서 암시적 데이터 형식 변환이 수행됩니다.
column_ordinal은 원본 파일에 있는 열의 서수입니다. Parquet 파일은 이름을 기준으로 바인딩되므로 이 인수가 무시됩니다. 다음 예제에서는 CSV 파일의 두 번째 열만 반환합니다.
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = 열 또는 중첩 속성에 대한 JSON 경로 식. 기본 경로 모드는 lax입니다.
참고
strict 모드에서는 제공된 경로가 존재하지 않으면 쿼리가 실패하고 오류가 발생합니다. lax 모드에서는 쿼리가 성공하고 JSON 경로 식이 NULL로 계산됩니다.
<일괄 옵션>
FIELDTERMINATOR ='field_terminator'
사용할 필드 종결자를 지정합니다. 기본 필드 종결자는 쉼표(",")입니다.
ROWTERMINATOR ='row_terminator'`
사용할 행 종결자를 지정합니다. 행 종결자를 지정하지 않으면 기본 종결자 중 하나가 사용됩니다. PARSER_VERSION = '1.0'의 기본 종결자는 \r\n, \n 및 \r입니다. PARSER_VERSION = '2.0'의 기본 종결자는 \r\n 및 \n입니다.
참고
PARSER_VERSION=‘1.0’을 사용하고 \n(줄 바꿈)을 행 종결자로 지정하면 \r(캐리지 리턴) 문자가 접두사로 자동 지정되므로 \r\n이 행 종결자가 됩니다.
ESCAPE_CHAR = 'char'
자체 및 파일의 모든 구분 기호 값을 이스케이프하는 데 사용되는 파일의 문자를 지정합니다. 이스케이프 문자 뒤에 자체 또는 구분 기호 값 이외의 값이 있으면 값을 읽을 때 이스케이프 문자가 삭제됩니다.
ESCAPECHAR 매개 변수는 FIELDQUOTE가 사용하도록 설정되었는지 여부에 관계없이 적용됩니다. 따옴표로 묶은 문자를 이스케이프하는 데 사용되지 않습니다. 따옴표 문자는 다른 따옴표 문자로 이스케이프해야 합니다. 따옴표로 묶은 문자는 값이 따옴표 문자로 캡슐화된 경우에만 열 값 내에 나타날 수 있습니다.
FIRSTROW = 'first_row' # 첫 번째 행
로드할 첫 번째 행의 번호를 지정합니다. 기본값은 1이며, 지정한 데이터 파일의 첫 번째 행을 가리킵니다. 행 번호는 행 종결자를 계산하여 결정됩니다. FIRSTROW는 1부터 시작합니다.
FIELDQUOTE = 'field_quote'
CSV 파일에 따옴표 문자로 사용될 문자를 지정합니다. 지정하지 않으면 따옴표 문자(")가 사용됩니다.
DATA_COMPRESSION = '데이터 압축 방법'
압축 방법을 지정합니다. PARSER_VERSION='1.0'에서만 지원됩니다. 다음 압축 방법이 지원됩니다.
- GZIP
PARSER_VERSION = 'parser_version'
파일을 읽을 때 사용할 파서 버전을 지정합니다. 현재 지원되는 CSV 파서 버전은 1.0 및 2.0입니다.
- PARSER_VERSION = '1.0'
- PARSER_VERSION = '2.0'
CSV 파서 버전 1.0이 기본값이며 기능이 풍부합니다. 버전 2.0은 성능을 위해 빌드되었으며 일부 옵션과 인코딩은 지원하지 않습니다.
CSV 파서 버전 1.0 세부 정보:
- HEADER_ROW와 같은 옵션은 지원되지 않습니다.
- 기본 종결자는 \r\n, \n, \r입니다.
- \n(줄 바꿈)을 행 종결자로 지정하면 \r(캐리지 리턴) 문자가 접두사로 자동 지정되므로 \r\n이 행 종결자가 됩니다.
CSV 파서 버전 2.0 세부 정보:
- 일부 데이터 유형은 지원되지 않습니다.
- 최대 문자 열 길이는 8000입니다.
- 최대 행 크기 제한은 8MB입니다.
- DATA_COMPRESSION과 같은 옵션은 지원되지 않습니다.
- 따옴표로 묶인 빈 문자열("")은 빈 문자열로 해석됩니다.
- DATEFORMAT SET 옵션은 적용되지 않습니다.
- DATE 데이터 유형에 지원되는 형식: YYYY-MM-DD
- TIME 데이터 유형에 지원되는 형식: HH:MM:SS[.fractional seconds]
- DATETIME2 데이터 유형에 지원되는 형식: YYYY-MM-DD HH:MM:SS[.fractional seconds]
- 기본 종결자는 \r\n, \n입니다.
HEADER_ROW = { 참 | 거짓 }
CSV 파일에 헤더 행이 포함되는지 여부를 지정합니다. 기본값은 PARSER_VERSION='2.0'에서 지원되는 FALSE.입니다. TRUE이면 FIRSTROW 인수에 따라 첫 번째 행에서 열 이름을 읽습니다. WITH를 사용하여 TRUE와 스키마를 지정한 경우 열 이름 바인딩은 서수 위치가 아닌 열 이름으로 수행됩니다.
DATAFILETYPE = { 'char' | 'widechar' }
인코딩 지정: char는 UTF8에 사용되고, widechar는 UTF16 파일에 사용됩니다.
CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' }
데이터 파일에서 데이터의 코드 페이지를 지정합니다. 기본값은 65001(UTF-8 인코딩)입니다. 이 옵션에 대한 자세한 내용을 여기를 클릭하세요.
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}'
이 옵션은 쿼리를 실행하는 동안 파일 수정 검사를 사용하지 않도록 설정하고 쿼리가 실행되는 동안 업데이트되는 파일을 읽습니다. 이 옵션은 쿼리가 실행되는 동안 추가되는 추가 전용 파일을 읽어야 하는 경우에 유용합니다. 추가 가능한 파일에서 기존 내용은 업데이트되지 않고 새 행만 추가됩니다. 따라서 업데이트 가능한 파일에 비해 결과가 잘못될 가능성이 최소화됩니다. 이 옵션을 사용하면 오류를 처리하지 않고 자주 추가되는 파일을 읽을 수 있습니다. 추가 가능한 CSV 파일 쿼리 섹션에서 자세한 내용을 확인하세요.
거부 옵션
참고
거부된 행 기능은 공개 미리 보기에 있습니다. 거부된 행 기능은 구분된 텍스트 파일 및 PARSER_VERSION 1.0에서 작동합니다.
서비스가 외부 데이터 원본에서 검색하는 더티 레코드를 처리하는 방법을 결정하는 거부 매개 변수를 지정할 수 있습니다. 실제 데이터 형식이 외부 테이블의 열 정의와 일치하지 않는 경우 데이터 레코드는 '더티'로 간주됩니다.
거부 옵션을 지정하거나 변경하지 않으면 서비스는 기본값을 사용합니다. 서비스는 거부 옵션을 사용하여 실제 쿼리가 실패하기 전에 거부할 수 있는 행 수를 결정합니다. 이 쿼리는 거부된 임계값이 초과될 때까지 (부분) 결과를 반환합니다. 그런 다음, 적절한 오류 메시지와 함께 실패합니다.
MAXERRORS = reject_value
쿼리가 실패하기 전에 거부할 수 있는 행 수를 지정합니다. MAXERRORS는 0에서 2,147,483,647 사이의 정수여야 합니다.
ERRORFILE_DATA_SOURCE = 데이터 원본
거부된 행과 해당 오류 파일을 작성해야 하는 데이터 원본을 지정합니다.
ERRORFILE_LOCATION = 디렉터리 위치
거부된 행과 해당 오류 파일을 기록해야 하는 DATA_SOURCE 또는 ERROR_FILE_DATASOURCE(지정된 경우) 내의 디렉터리를 지정합니다. 지정된 경로가 존재하지 않으면 서비스에서 사용자를 대신하여 경로를 만듭니다. "rejectedrows"라는 이름의 하위 디렉터리가 생성됩니다. "" 문자는 위치 매개 변수에 명시적으로 명명되지 않는 한, 다른 데이터 처리를 위해 디렉터리를 이스케이프합니다. 이 디렉터리 내에는 로드 제출 시간을 기준으로 YearMonthDay_HourMinuteSecond_StatementID 형식에 따라 생성된 폴더가 있습니다(예: 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891). 명령문 ID를 사용하여 폴더를 생성한 쿼리와 폴더를 연관시킬 수 있습니다. 이 폴더에는 error.json 파일과 데이터 파일의 두 파일이 작성됩니다.
error.json 파일에는 거부된 행과 관련된 오류가 발생한 json 배열이 포함되어 있습니다. 오류를 나타내는 각 요소에는 다음 특성이 포함됩니다.
| attribute | 설명 |
|---|---|
| Error | 행이 거부된 이유입니다. |
| 행 | 파일에서 행 서수를 거부했습니다. |
| 열 | 거부된 열 서수. |
| 값 | 거부된 열 값입니다. 값이 100자보다 크면 처음 100자만 표시됩니다. |
| 파일 | 해당 행이 속한 파일의 경로입니다. |
분리된 텍스트에 대한 빠른 구문 분석
사용할 수 있는 두 가지 분리된 텍스트 구문 파서 버전이 있습니다. CSV 파서 버전 1.0은 기본값이고 기능이 풍부하지만, 파서 버전 2.0은 성능을 위해 빌드되었습니다. 향상된 파서 2.0 성능은 고급 구문 분석 기술 및 다중 스레딩에서 제공됩니다. 파일 크기가 커질수록 속도 차이도 커집니다.
자동 스키마 검색
WITH 절을 생략하여 스키마를 인식하거나 지정하지 않고도 CSV 및 Parquet 파일을 모두 쉽게 쿼리할 수 있습니다. 열 이름 및 데이터 형식은 파일에서 유추됩니다.
Parquet 파일에는 읽을 열 메타데이터가 포함되어 있으며, 형식 매핑은 Parquet에 대한 형식 매핑에서 확인할 수 있습니다. 샘플은 스키마를 지정하지 않고 Parquet 파일 읽기를 확인하세요.
CSV 파일의 경우 열 이름은 헤더 행에서 읽을 수 있습니다. HEADER_ROW 인수를 사용하여 헤더 행이 있는지 여부를 지정할 수 있습니다. HEADER_ROW = FALSE일 경우 사용되는 일반 열 이름: C1, C2... Cn의 제네릭 열 이름이 사용됩니다. 여기서 n은 파일의 열 수입니다. 데이터 형식은 처음 100개의 데이터 행에서 유추됩니다. 샘플은 스키마를 지정하지 않고 CSV 파일 읽기를 확인하세요.
한 번에 파일 수를 읽는 경우 스토리지에서 가져오는 첫 번째 파일 서비스에서 스키마가 유추됩니다. 이는 스키마를 정의하기 위해 서비스에서 사용하는 파일에 이러한 열이 포함되지 않았기 때문에 예상되는 일부 열이 생략되었음을 의미할 수 있습니다. 이 경우 OPENROWSET WITH 절을 사용합니다.
중요
정보가 부족하여 적절한 데이터 형식을 유추할 수 없고 더 큰 데이터 형식이 대신 사용되는 경우가 있습니다. 이는 성능 오버헤드를 발생시키며, 특히 varchar(8000)로 유추되는 문자 열에 중요합니다. 최적의 성능을 위해 유추된 데이터 형식을 확인하고 적절한 데이터 형식을 사용합니다.
Parquet에 대한 형식 매핑
Parquet 및 Delta Lake 파일에는 모든 열에 대한 형식 설명이 포함되어 있습니다. 다음 테이블에서는 Parquet 형식이 SQL 네이티브 형식에 매핑되는 방법을 설명합니다.
| Parquet 형식 | Parquet 논리 형식(주석) | SQL 데이터 형식 |
|---|---|---|
| BOOLEAN | bit | |
| 바이너리/바이트_배열 | varbinary | |
| DOUBLE | float | |
| FLOAT | real | |
| INT32 | int | |
| INT64 | bigint | |
| INT96 | datetime2 | |
| FIXED_LEN_BYTE_ARRAY | binary | |
| BINARY | UTF8 | varchar *(UTF8 데이터 정렬) |
| BINARY | STRING | varchar *(UTF8 데이터 정렬) |
| BINARY | ENUM | varchar *(UTF8 데이터 정렬) |
| FIXED_LEN_BYTE_ARRAY | UUID | uniqueidentifier |
| BINARY | DECIMAL | decimal |
| BINARY | JSON | varchar(8000) *(UTF8 데이터 정렬) |
| BINARY | BSON | 지원되지 않음 |
| FIXED_LEN_BYTE_ARRAY | DECIMAL | decimal |
| BYTE_ARRAY | INTERVAL | 지원되지 않음 |
| INT32 | INT(8, 참) | smallint |
| INT32 | INT(16, true) | smallint |
| INT32 | INT(32, true) | int |
| INT32 | INT(8, false) | tinyint |
| INT32 | INT(16, false) | int |
| INT32 | INT(32, 거짓) | bigint |
| INT32 | DATE | date |
| INT32 | DECIMAL | decimal |
| INT32 | TIME(MILLIS) | time |
| INT64 | INT(64, true) | bigint |
| INT64 | INT(64, false) | decimal(20,0) |
| INT64 | DECIMAL | decimal |
| INT64 | TIME(MICROS) | time |
| INT64 | TIME(NANOS) | 지원되지 않음 |
| INT64 | TIMESTAMP(utc로 정규화됨)(MILLIS/MICROS) | datetime2 |
| INT64 | TIMESTAMP(utc로 정규화되지 않음)(MILLIS/MICROS) | bigint - 날짜/시간 값으로 변환하기 전에 표준 시간대 오프셋을 사용하여 bigint 값을 명시적으로 조정해야 합니다. |
| INT64 | TIMESTAMP(NANOS) | 지원되지 않음 |
| 복합 형식 | 명단 등록 | varchar(8000), JSON으로 직렬화됨 |
| 복합 형식 | MAP | varchar(8000), JSON으로 직렬화됨 |
예제
스키마를 지정하지 않고 CSV 파일 읽기
다음 예제에서는 열 이름 및 데이터 형식을 지정하지 않고 헤더 행이 포함된 CSV 파일을 읽습니다.
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
다음 예제에서는 열 이름 및 데이터 형식을 지정하지 않고 헤더 행이 포함되지 않은 CSV 파일을 읽습니다.
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
스키마를 지정하지 않고 Parquet 파일 읽기
다음 예제는 열 이름 및 데이터 형식을 지정하지 않고 Parquet 형식의 인구 조사 데이터 세트에서 첫 번째 행의 모든 열을 반환합니다.
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
스키마를 지정하지 않고 Delta Lake 파일 읽기
다음 예제는 열 이름 및 데이터 형식을 지정하지 않고 Delta Lake 형식의 인구 조사 데이터 세트에서 첫 번째 행의 모든 열을 반환합니다.
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
CSV 파일에서 특정 열 읽기
다음 예제는 population*.csv 파일에서 서수가 1과 4인 2개 열만 반환합니다. 다음과 같이 파일에 헤더 행이 없기 때문에 첫 번째 줄에서 읽기를 시작합니다.
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
Parquet 파일에서 특정 열 읽기
다음 예제에서는 인구 조사 데이터 세트에서 첫 번째 행의 2개 열만 Parquet 형식으로 반환합니다.
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
JSON 경로를 사용하여 열 지정
다음 예제에서는 WITH 절에서 JSON 경로 식을 사용하는 방법을 보여 주고 strict 및 lax 경로 모드의 차이점을 보여 줍니다.
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
BULK 경로에 여러 파일/폴더 지정
다음 예는 BULK 매개 변수에서 여러 파일/폴더 경로를 사용하는 방법을 보여 줍니다.
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
다음 단계
더 많은 샘플을 보려면 쿼리 데이터 스토리지 빠른 시작을 참조하여 OPENROWSET를 사용해 CSV, PARQUET, DELTA LAKE 및 JSON 파일 형식을 읽는 방법을 알아보세요. 최적의 성능을 얻으려면 모범 사례를 확인하세요.
CETAS를 사용하여 쿼리 결과를 Azure Storage에 저장하는 방법도 알아볼 수 있습니다.