펜싱 디바이스를 사용하여 SUSE에서 고가용성 설정
이 문서에서는 펜싱 디바이스를 사용하여 SUSE 운영 체제의 HANA 대규모 인스턴스에서 HA(고가용성)를 설정하는 단계를 안내합니다.
참고
이 가이드는 Microsoft HANA 대규모 인스턴스 환경에서 설정을 성공적으로 테스트하여 작성하였습니다. HANA 대규모 인스턴스에 대한 Microsoft 서비스 관리 팀은 운영 체제를 지원하지 않습니다. 운영 체제 레이어의 문제 해결 또는 설명은 SUSE에 문의하세요.
Microsoft 서비스 관리 팀은 펜싱 디바이스를 설정하고 완벽하게 지원합니다. 펜싱 디바이스 문제를 해결하는 데 도움이 될 수 있습니다.
사전 요구 사항
SUSE 클러스터링을 사용하여 고가용성을 설정하려면 다음을 수행해야 합니다.
- HANA 대규모 인스턴스를 프로비저닝합니다.
- 최신 패치를 사용하여 운영 체제를 설치하고 등록합니다.
- SMT 서버에 HANA 대규모 인스턴스 서버를 연결하여 패치 및 패키지를 가져옵니다.
- 네트워크 시간 프로토콜(NTP 시간 서버)을 설정합니다.
- HA 설정에 관한 SUSE 설명서의 최신 버전을 읽고 이해합니다.
설정 정보
이 가이드에서 사용하는 설정은 다음과 같습니다.
- 운영 체제: SAP용 SLES 12 SP1
- HANA 대규모 인스턴스: 2xS192(4개 소켓, 2TB)
- HANA 버전: HANA 2.0 SP1
- 서버 이름: sapprdhdb95(노드 1) 및 sapprdhdb96(노드 2)
- 펜싱 디바이스: iSCSI 기반
- HANA 대규모 인스턴스 노드 중 하나의 NTP
HANA 시스템 복제를 사용하여 HANA Large Instances를 설정하는 경우, Microsoft 서비스 관리 팀에 펜싱 디바이스 설정을 요청해야 합니다. 프로비저닝 시 이 작업을 수행합니다.
HANA Large Instances가 이미 프로비전된 기존 고객의 경우에도 펜싱 디바이스를 설정할 수 있습니다. 서비스 요청 양식(SRF)에서 Microsoft 서비스 관리 팀에 다음 정보를 제공합니다. 기술 계정 관리자 또는 Microsoft의 HANA Large Instance 온보딩 담당자를 통해 SRF 양식을 받을 수 있습니다.
- 서버 이름 및 서버 IP 주소(예: myhanaserver1 및 10.35.0.1)
- 위치(예: 미국 동부)
- 고객 이름(예: Microsoft)
- HANA SID(시스템 식별자)(예: H11)
펜싱 디바이스가 구성되면 Microsoft 서비스 관리 팀에서 iSCSI 스토리지의 SBD 이름과 IP 주소를 제공합니다. 이 정보를 사용하여 펜싱 설정을 구성할 수 있습니다.
다음 섹션의 단계에 따라 펜싱 디바이스를 사용하여 HA를 설정합니다.
SBD 디바이스 식별
참고
이 섹션은 기존 고객에게만 해당됩니다. 새 고객인 경우, Microsoft 서비스 관리 팀에서 SBD 디바이스 이름을 제공하므로 이 섹션을 건너뜁니다.
/etc/iscsi/initiatorname.isci를 다음으로 수정
iqn.1996-04.de.suse:01:<Tenant><Location><SID><NodeNumber>Microsoft 서비스 관리에서 이 문자열을 제공합니다. 노드 둘 다에서 파일을 수정합니다. 노드 번호는 노드마다 다릅니다.
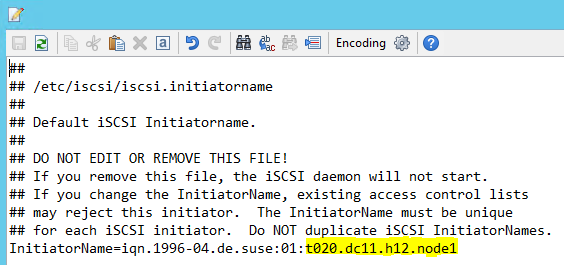
node.session.timeo.replacement_timeout=5및node.startup = automatic을 설정하여 /etc/iscsi/iscsid.conf를 수정합니다. 노드 둘 다에서 파일을 수정합니다.두 노드에서 다음 검색을 실행합니다.
iscsiadm -m discovery -t st -p <IP address provided by Service Management>:3260결과에는 4개의 세션이 표시됩니다.
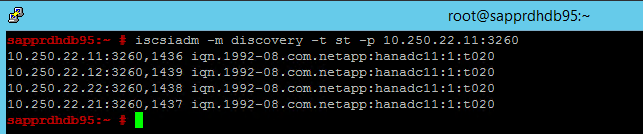
두 노드에서 다음 명령을 실행하여 iSCSI 디바이스에 로그인합니다.
iscsiadm -m node -l결과에는 4개의 세션이 표시됩니다.

다음 명령을 사용하여 rescan-scsi-bus.sh 다시 검사 스크립트를 실행합니다. 이 스크립트는 사용자를 위해 생성된 새 디스크를 표시합니다. 두 노드에서 모두 실행합니다.
rescan-scsi-bus.sh0보다 더 큰 LUN 번호(예: 1, 2 등)가 표시됩니다.
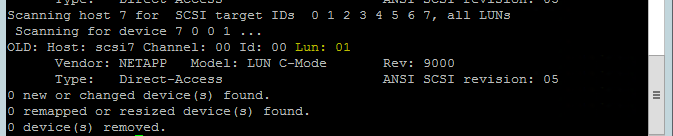
디바이스 이름을 얻으려면 두 노드에서 다음 명령을 실행합니다.
fdisk –l결과에서 크기가 178MiB인 디바이스를 선택합니다.

SBD 디바이스 초기화
다음 명령을 사용하여 두 노드에서 SBD 디바이스를 초기화합니다.
sbd -d <SBD Device Name> create
두 노드에서 다음 명령을 사용하여 디바이스에 기록된 내용을 확인합니다.
sbd -d <SBD Device Name> dump
SUSE HA 클러스터 구성
다음 명령을 사용하여 ha_sles 및 SAPHanaSR-doc 패턴이 두 노드에 모두 설치되어 있는지 확인합니다. 설치되지 않은 경우 설치합니다.
zypper in -t pattern ha_sles zypper in SAPHanaSR SAPHanaSR-doc
ha-cluster-init명령 또는 yast2 마법사를 사용하여 클러스터를 설정합니다. 이 예제에서는 yast2 마법사를 사용합니다. 주 노드에 대해서만 이 단계를 수행합니다.yast2High>고가용성>클러스터로 이동합니다.
hawk 패키지 설치에 대한 대화 상자에서 halk2 패키지가 이미 설치되어 있으므로 취소를 선택합니다.
계속하는 방법에 대한 대화 상자에서 계속을 선택합니다.
예상 값은 배포된 노드 수입니다(이 경우 2). 다음을 선택합니다.
노드 이름을 추가한 다음 제안된 파일 추가를 선택합니다.
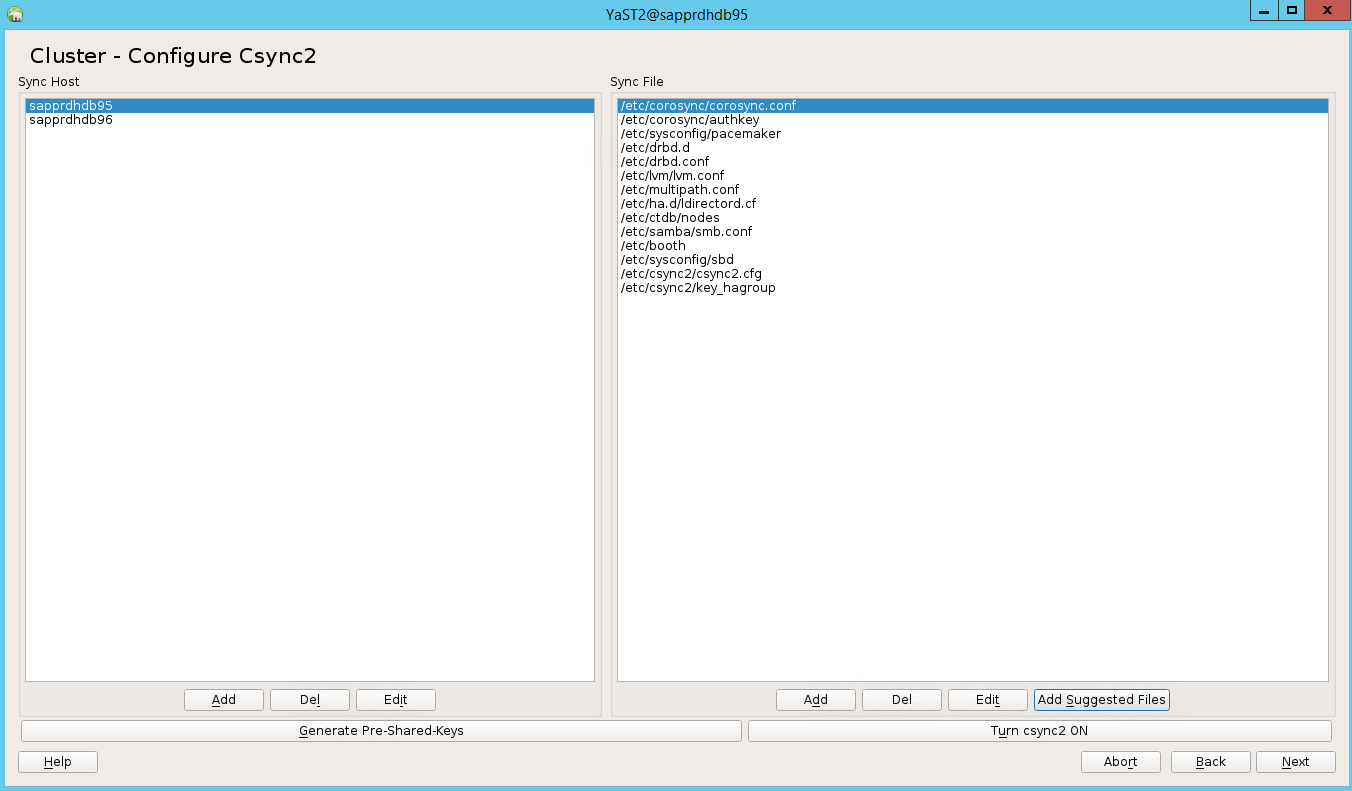
csync2 켜기를 선택합니다.
미리 공유한 키를 선택합니다.
표시되는 팝업 메시지에서 확인을 선택합니다.
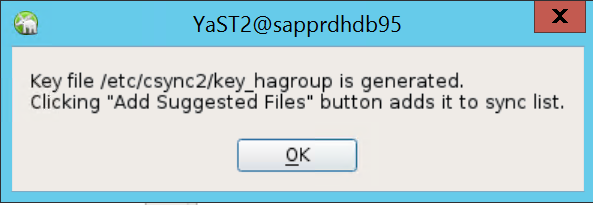
IP 주소 및 Csync2의 미리 공유한 키를 사용하여 인증을 수행합니다. 키 파일이
csync2 -k /etc/csync2/key_hagroup과 함께 자동으로 생성됩니다.key_hagroup 파일을 만든 후 클러스터의 모든 멤버에 수동으로 복사합니다. node1에서 node2로 파일을 복사해야 합니다. 다음을 선택합니다.
기본 옵션에서 부팅이 해제되었습니다. 부팅 시 pacemaker 서비스가 시작되도록 켜기로 변경합니다. 설정 요구 사항에 따라 선택할 수 있습니다.
다음을 선택하면 클러스터 구성이 완료됩니다.
Softdog Watchdog을 설정합니다.
두 노드에서 모두 다음 줄을 /etc/init.d/boot.local에 추가합니다.
modprobe softdog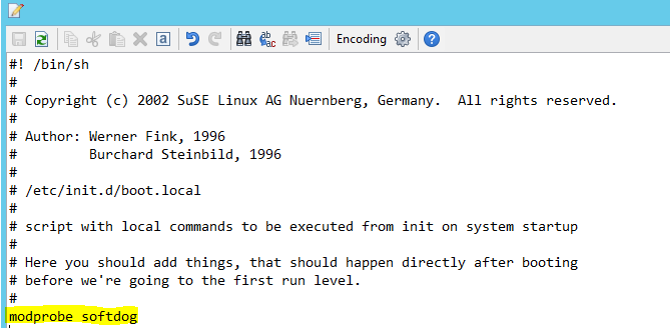
다음 명령을 사용하여 두 노드에서/etc/sysconfig/sbd 파일을 업데이트합니다.
SBD_DEVICE="<SBD Device Name>"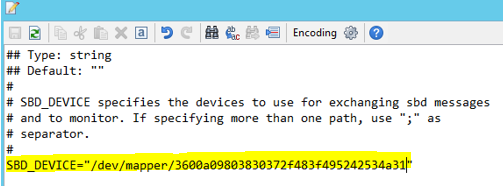
두 노드에서 다음 명령을 실행하여 커널 모듈을 로드합니다.
modprobe softdog
다음 명령을 사용하여 softdog가 두 노드에서 실행 중인지 확인합니다.
lsmod | grep dog
다음 명령을 사용하여 두 노드에서 SBD 디바이스를 초기화합니다.
/usr/share/sbd/sbd.sh start
다음 명령을 사용하여 두 노드에서 SBD 디먼을 테스트합니다.
sbd -d <SBD Device Name> list결과는 두 노드에서 구성 후 두 항목을 표시합니다.

노드 중 한 개에 다음 테스트 메시지를 보냅니다.
sbd -d <SBD Device Name> message <node2> <message>두 번째 노드(node2)에서 다음 명령을 사용하여 메시지 상태를 확인합니다.
sbd -d <SBD Device Name> list
SBD 구성을 채택하려면 두 노드에서 다음과 같이 /etc/sysconfig/sbd 파일을 업데이트합니다.
SBD_DEVICE=" <SBD Device Name>" SBD_WATCHDOG="yes" SBD_PACEMAKER="yes" SBD_STARTMODE="clean" SBD_OPTS=""다음 명령을 사용하여 주 노드(node1)에서 Pacemaker 서비스를 시작합니다.
systemctl start pacemaker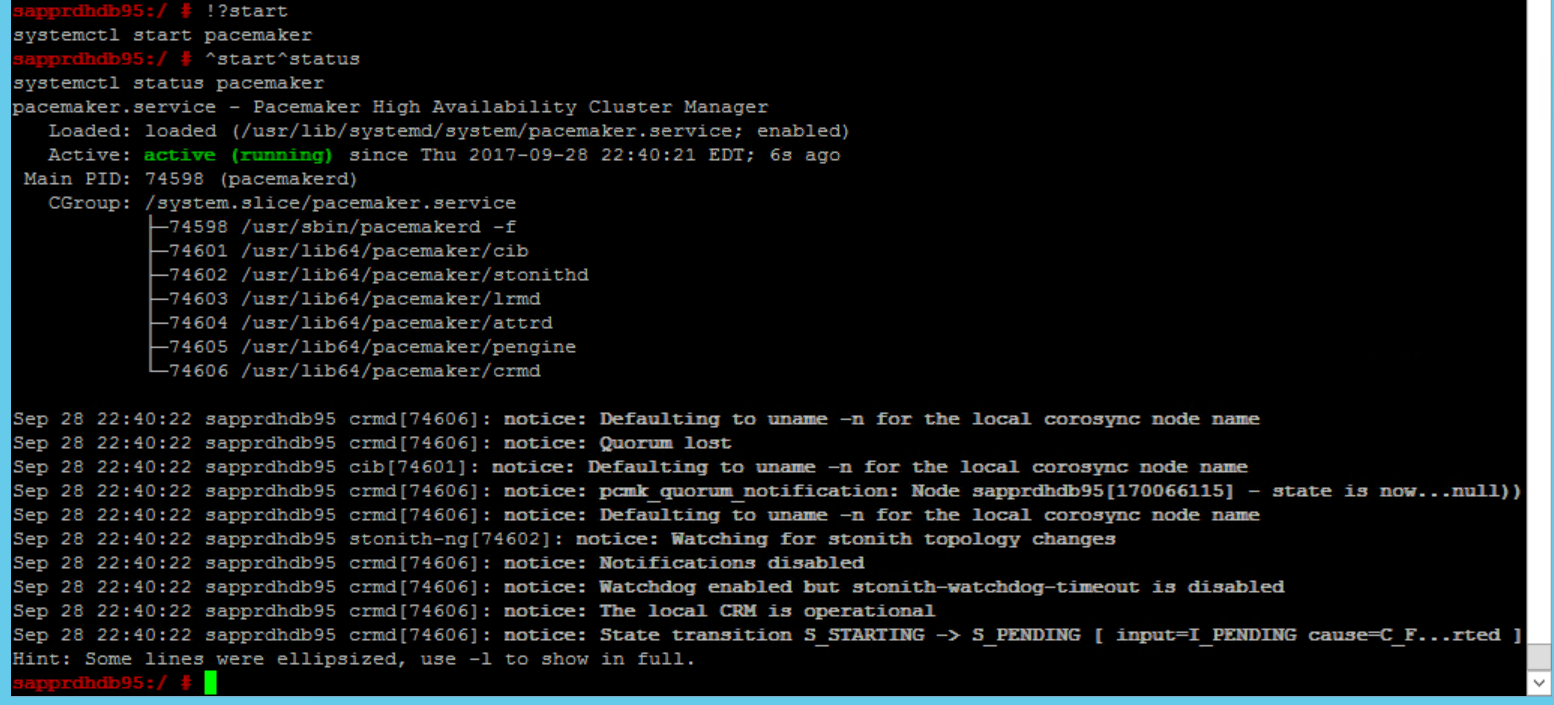
Pacemaker 서비스가 실패하는 경우 이 문서의 뒷부분의 시나리오 5: Pacemaker 서비스 실패 섹션을 참조하세요.
클러스터에 노드 조인
다음 명령을 노드 2에서 실행하여 해당 노드를 클러스터에 조인합니다.
ha-cluster-join
클러스터를 조인하는 동안 오류가 발생하는 경우 시나리오 이 문서 뒷부분의 시나리오 6: 노드 2가 클러스터에 조인할 수 없는 경우 섹션을 참조하세요.
클러스터 유효성 검사
다음 명령을 사용하여 두 노드에서 클러스터를 확인하고 및 처음 시작합니다(옵션).
systemctl status pacemaker systemctl start pacemaker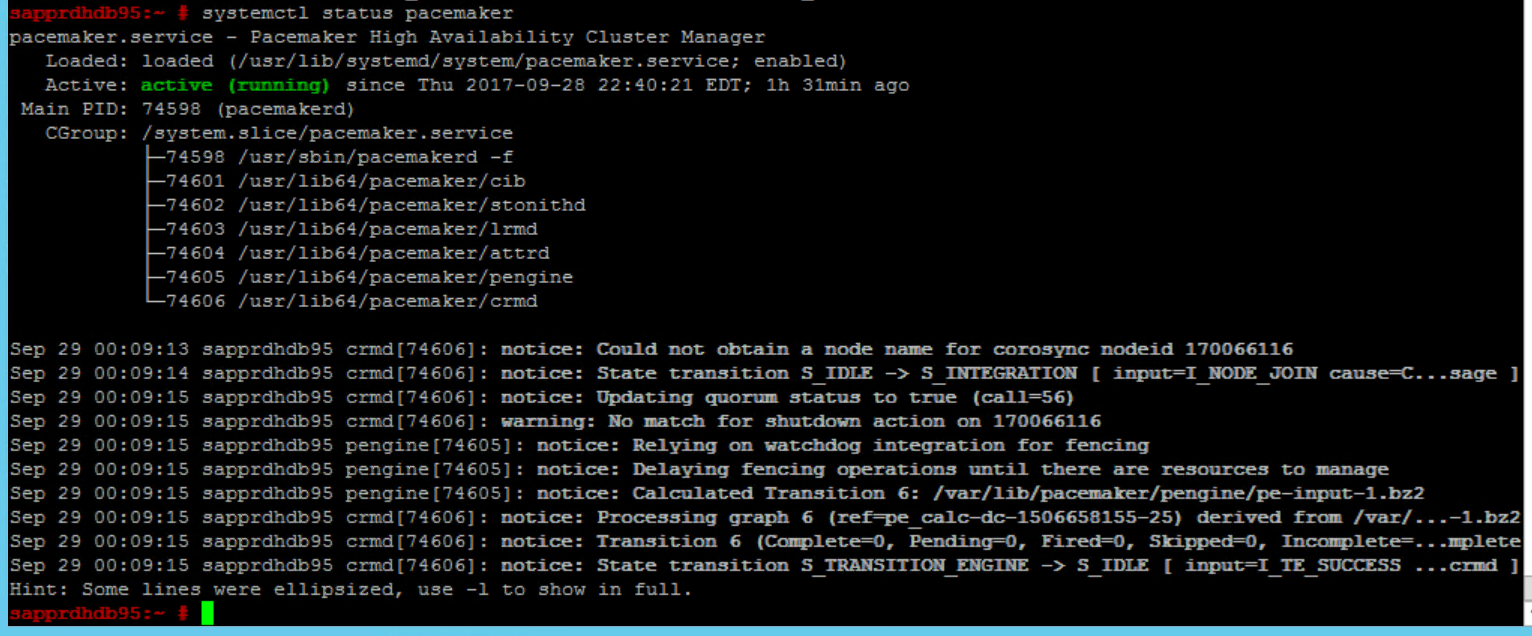
다음 명령을 실행하여 두 노드가 모두 온라인 상태가 되도록 합니다. 이 작업은 클러스터의 임의 노드에서 실행할 수 있습니다.
crm_mon
hawk에 로그인하여 클러스터 상태(
https://\<node IP>:7630)를 확인할 수도 있습니다. 기본 사용자는 hacluster이며 암호는 linux입니다. 필요한 경우passwd명령을 사용하여 암호를 변경할 수 있습니다.
클러스터 속성 및 리소스 구성
이 섹션에서는 클러스터 리소스를 구성하는 단계를 설명합니다. 이 예제에서는 다음 리소스를 설정합니다. SUSE HA 가이드를 참조하여 나머지(필요한 경우)를 구성할 수 있습니다.
- 클러스터 부트스트랩
- 펜싱 디바이스
- 가상 IP 주소
주 노드에서만 구성을 수행합니다.
클러스터 부트스트랩 파일을 만들고 다음 텍스트를 추가하여 구성합니다.
sapprdhdb95:~ # vi crm-bs.txt # enter the following to crm-bs.txt property $id="cib-bootstrap-options" \ no-quorum-policy="ignore" \ stonith-enabled="true" \ stonith-action="reboot" \ stonith-timeout="150s" rsc_defaults $id="rsc-options" \ resource-stickiness="1000" \ migration-threshold="5000" op_defaults $id="op-options" \ timeout="600"다음 명령을 사용하여 클러스터에 구성을 추가합니다.
crm configure load update crm-bs.txt
리소스를 추가하고, 파일을 만들고, 다음과 같이 텍스트를 추가하여 펜싱 디바이스를 구성합니다.
# vi crm-sbd.txt # enter the following to crm-sbd.txt primitive stonith-sbd stonith:external/sbd \ params pcmk_delay_max="15"다음 명령을 사용하여 클러스터에 구성을 추가합니다.
crm configure load update crm-sbd.txt파일을 만들고 다음 텍스트를 추가하여 리소스에 대한 가상 IP 주소를 추가합니다.
# vi crm-vip.txt primitive rsc_ip_HA1_HDB10 ocf:heartbeat:IPaddr2 \ operations $id="rsc_ip_HA1_HDB10-operations" \ op monitor interval="10s" timeout="20s" \ params ip="10.35.0.197"다음 명령을 사용하여 클러스터에 구성을 추가합니다.
crm configure load update crm-vip.txtcrm_mon명령을 사용하여 리소스의 유효성을 검사합니다.결과에는 두 개의 리소스가 표시됩니다.

또한 https://<노드 IP 주소>:7630/cib/live/state에서 상태를 확인할 수 있습니다.
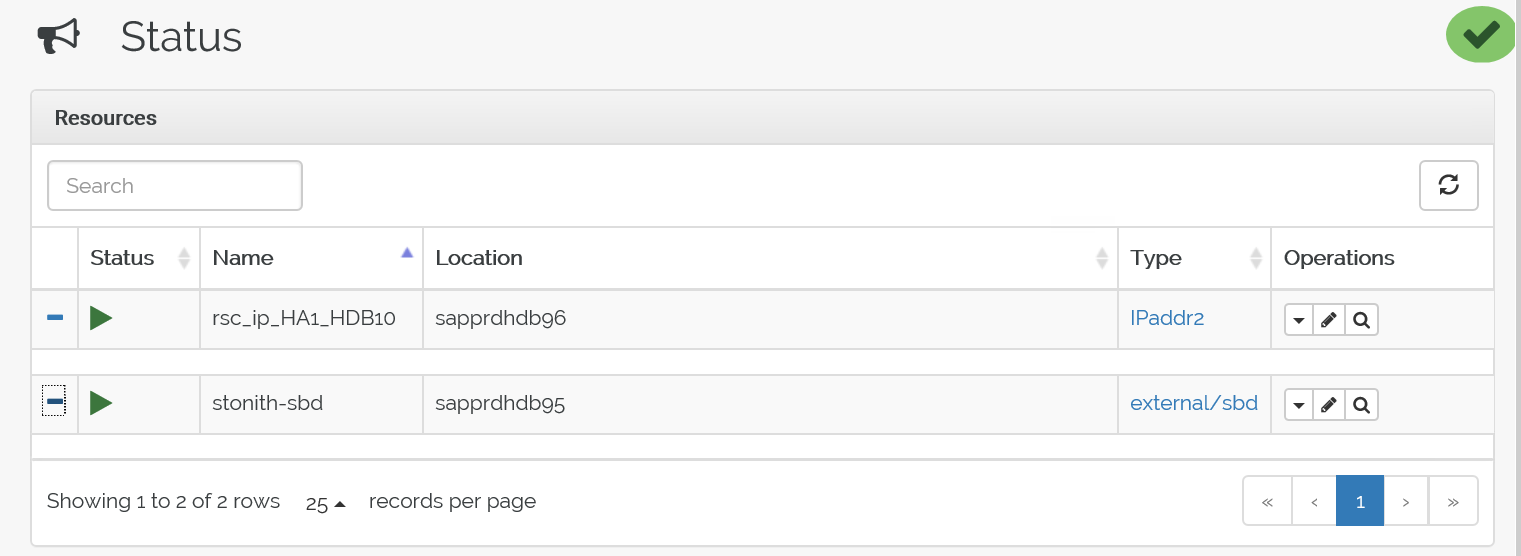
장애 조치(failover) 프로세스 테스트
장애 조치(failover) 프로세스를 테스트하려면 다음 명령을 사용하여 노드 1에서 Pacemaker 서비스를 중지합니다.
Service pacemaker stop리소스가 node2로 장애 조치(failover)됩니다.
이제 노드 2에서 Pacemaker 서비스를 중단하고 리소스를 노드 1에 대해 장애 조치합니다.
장애 조치 전 상태는 다음과 같습니다.
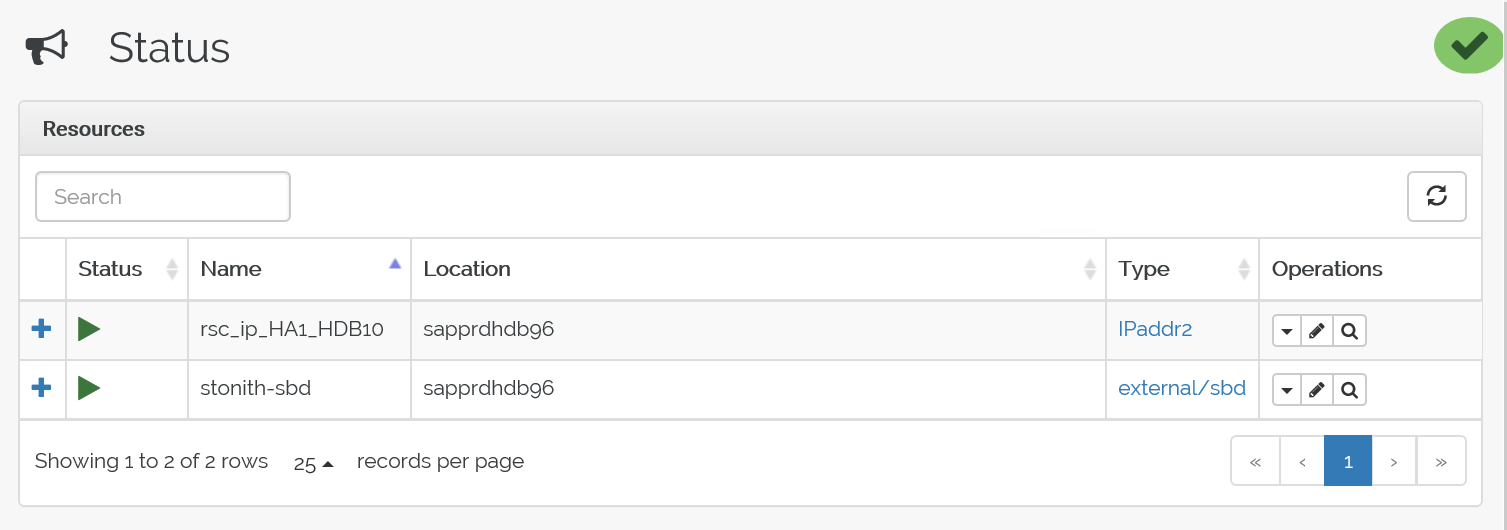
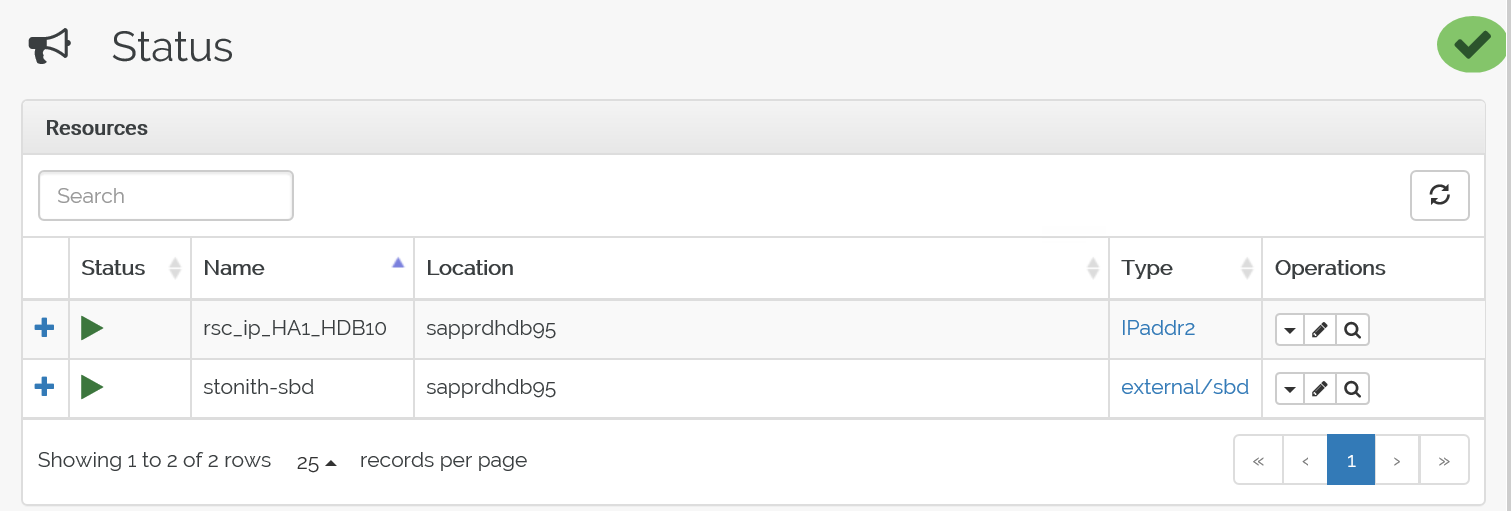
장애 조치 후 상태는 다음과 같습니다.

문제 해결
이 섹션에서는 설치 중에 발생할 수 있는 오류 시나리오에 대해 설명합니다.
시나리오 1: 클러스터 노드가 온라인이 아닌 경우
노드 중 하나라도 클러스터 관리자에서 온라인으로 표시되지 않으면 이 프로시저를 시도하여 온라인으로 전환할 수 있습니다.
다음 명령을 사용하여 iSCSI 서비스를 시작합니다.
service iscsid start다음 명령을 사용하여 해당 iSCSI 노드에 로그인합니다.
iscsiadm -m node -l예상 출력은 다음과 같습니다.
sapprdhdb45:~ # iscsiadm -m node -l Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] (multiple) Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] successful.
시나리오 2: yast2가 그래픽 보기에 표시되지 않는 경우
yast2 그래픽 화면이 이 문서의 고가용성 클러스터를 설정하는 데 사용됩니다. 표시된 대로 yast2가 그래픽 창에서 열리지 않고 Qt 오류가 throw되는 경우 다음 단계를 수행하여 필요한 패키지를 설치합니다. 그래픽 창과 함께 열리면 이 단계를 건너뛸 수 있습니다.
Qt 오류의 예는 다음과 같습니다.

예상되는 출력의 예는 다음과 같습니다.
“루트” 사용자로 로그인해야 하며 SMT 설정 프로그램을 다운로드하거나 패키지를 설치해야 합니다.
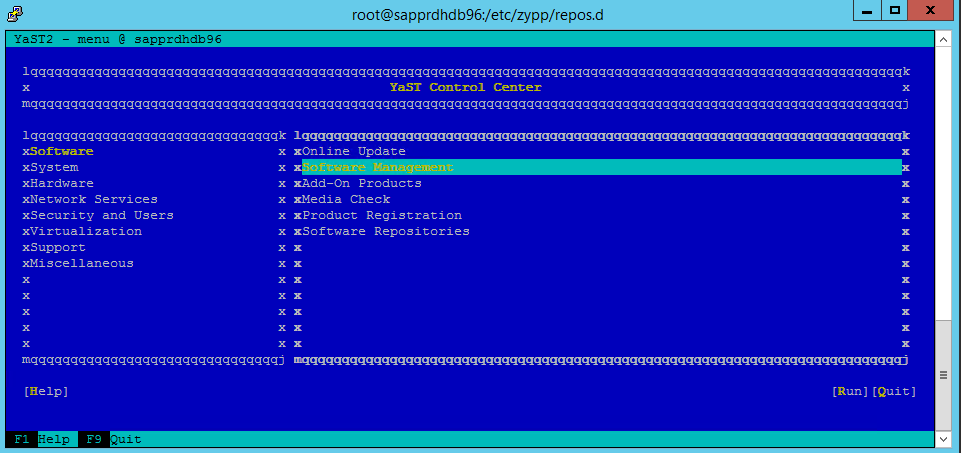
yast>소프트웨어>소프트웨어 관리>종속성으로 이동한 다음 권장 패키지 설치를 선택합니다.
참고
두 노드에서 yast2 그래픽 보기에 액세스할 수 있도록 두 노드에서 모두 이 단계를 수행합니다.
다음 스크린샷에서는 예상되는 화면을 보여 줍니다.
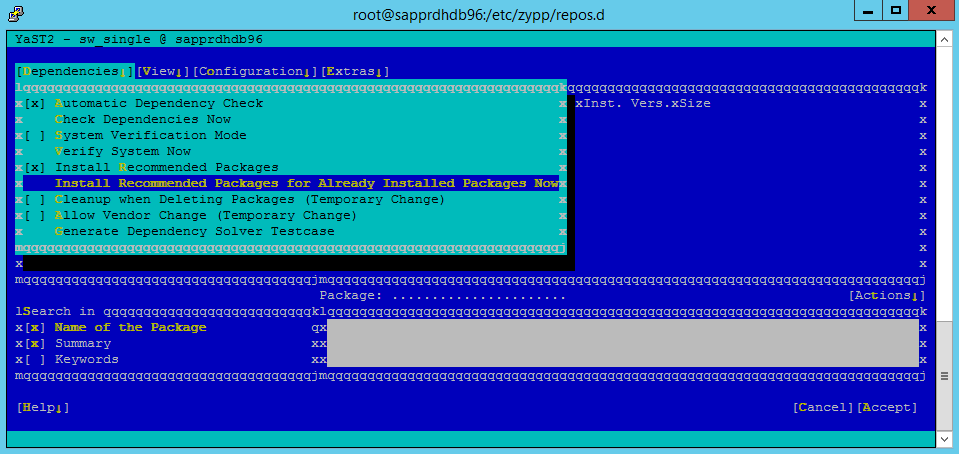
종속성 아래에서 권장 패키지 설치를 선택합니다.
변경 내용을 검토하고 확인을 선택합니다.
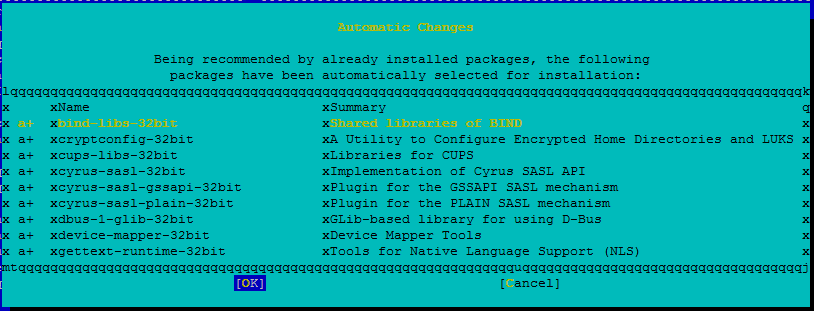
패키지 설치가 진행됩니다.
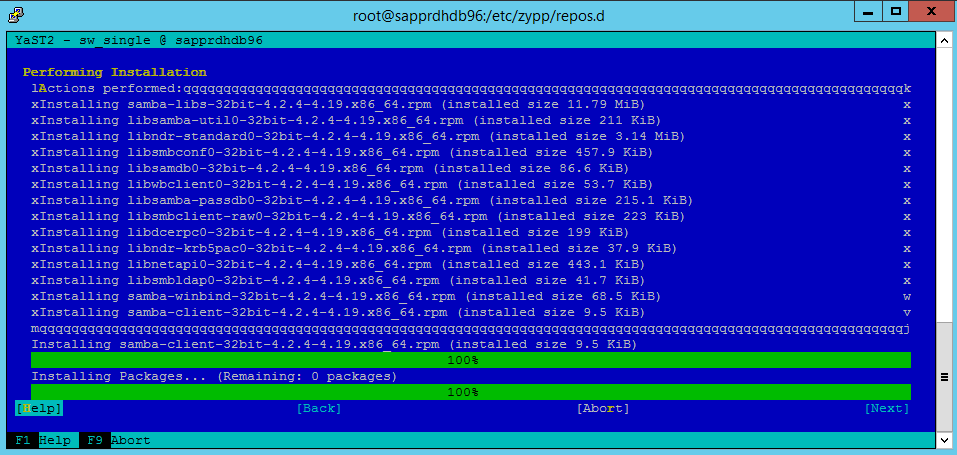
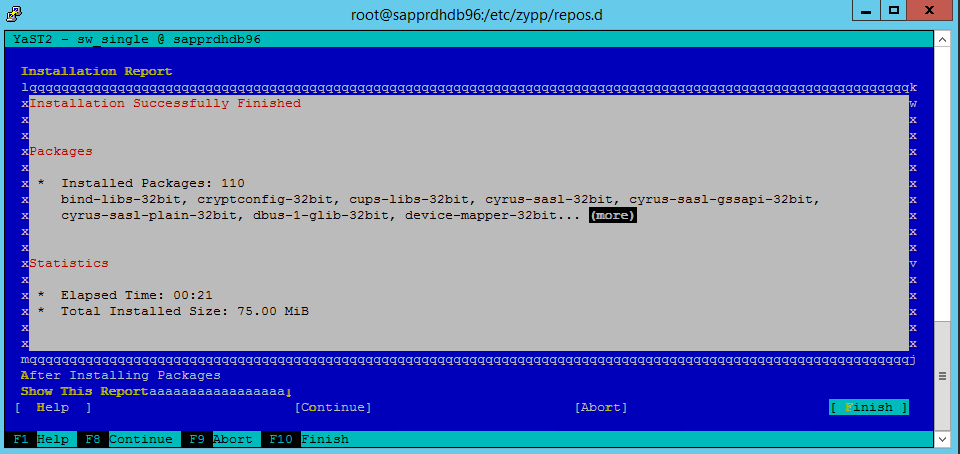
다음을 선택합니다.
설치 완료 화면이 나타나면 마침을 선택합니다.
다음 명령을 사용하여 libqt4 패키지 및 libyui-qt 패키지를 설치합니다.
zypper -n install libqt4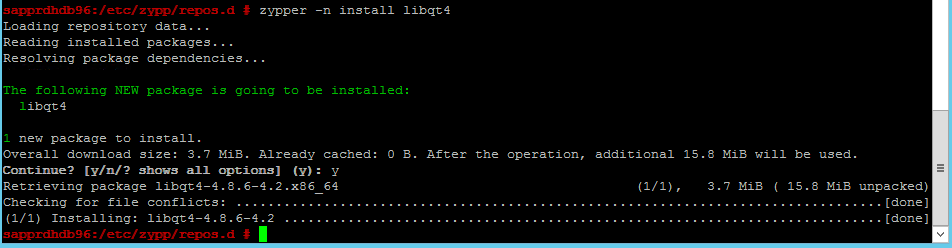
zypper -n install libyui-qt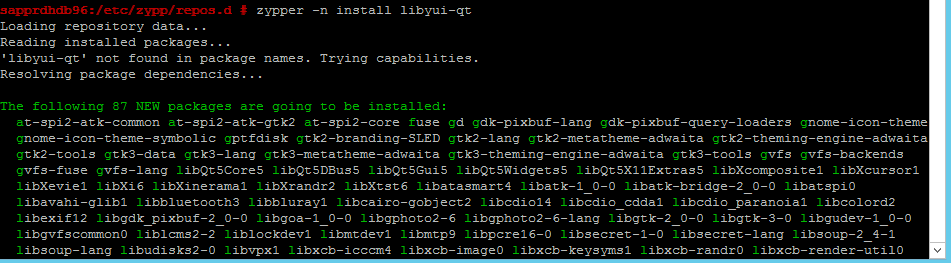

이제 Yast2에서 그래픽 보기를 열 수 있습니다.
시나리오 3: yast2에 고가용성 옵션이 표시되지 않습니다.
고가용성 옵션이 yast2 제어 센터에 표시되도록 하려면 다른 패키지를 설치해야 합니다.
Yast2>소프트웨어>소프트웨어 관리로 이동합니다. 그런 다음 소프트웨어>온라인 업데이트를 선택합니다.
다음 항목에 대한 패턴을 선택합니다. 수락을 선택합니다.
- SAP HANA 서버 베이스
- C/C++ 컴파일러 및 도구
- 고가용성
- SAP 애플리케이션 서버 베이스
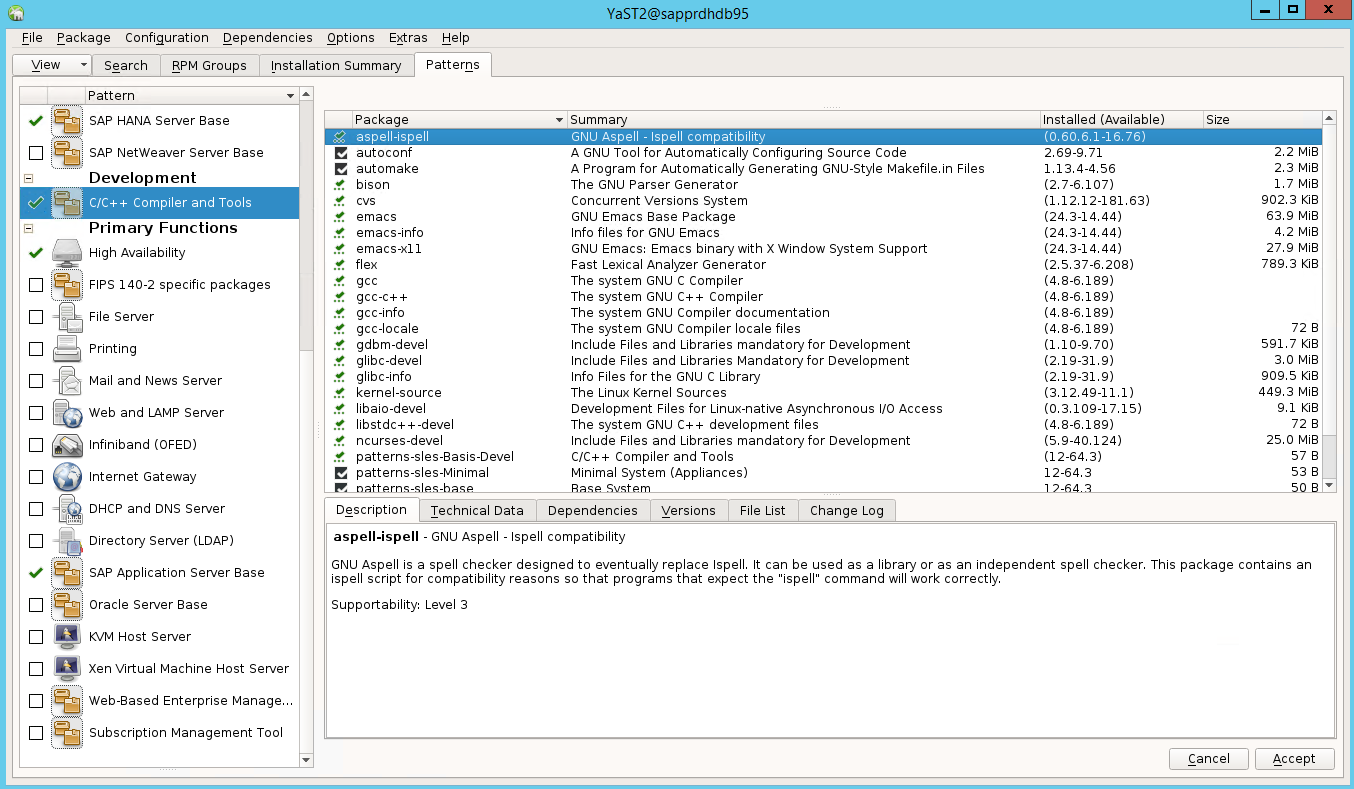
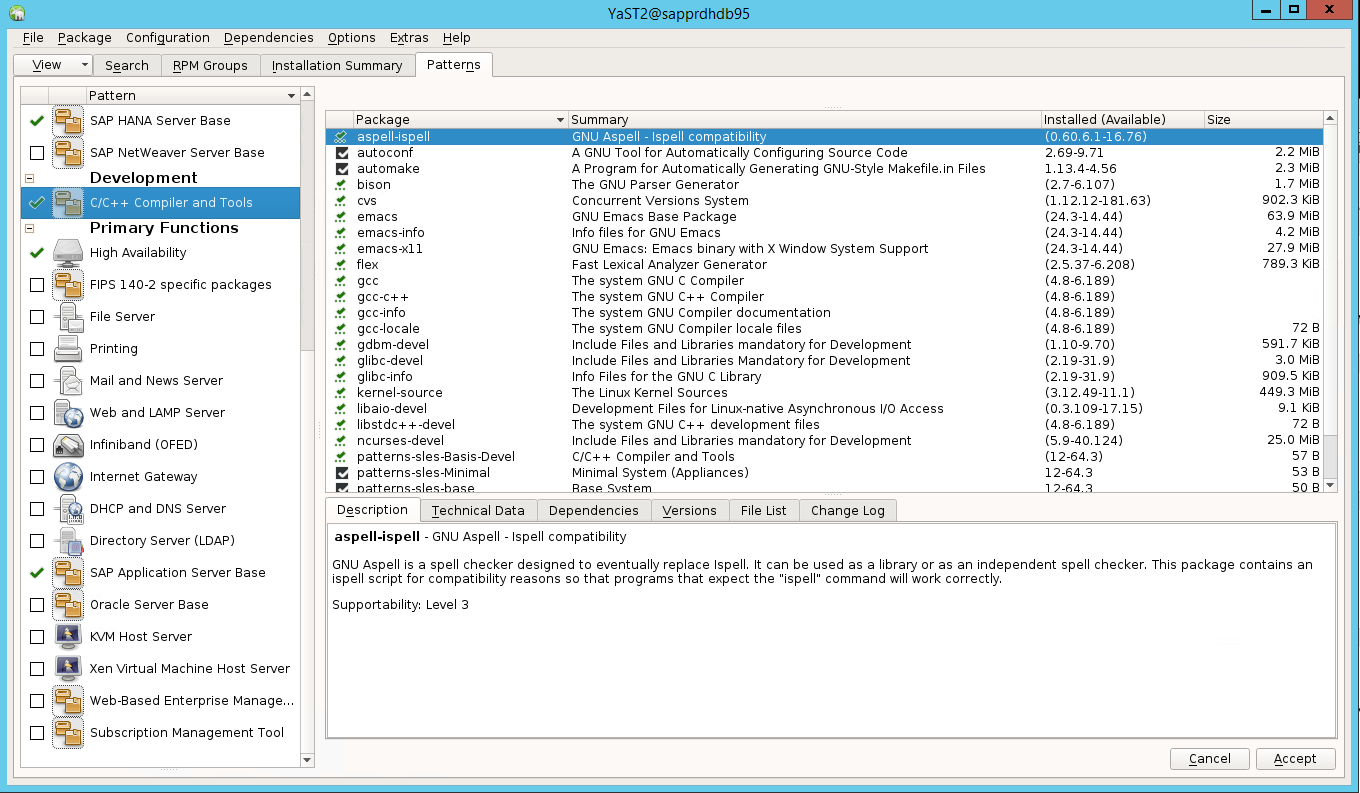
종속성을 해결하기 위해 변경된 패키지 목록에서 계속을 선택합니다.
설치 수행 상태 페이지에서 다음을 선택합니다.
설치가 완료되면 설치 보고서가 나타납니다. 마침을 선택합니다.
시나리오 4: HANA 설치가 실패하고 gcc 어셈블리 오류가 발생하는 경우
HANA 설치에 실패하면 다음 오류가 발생할 수 있습니다.
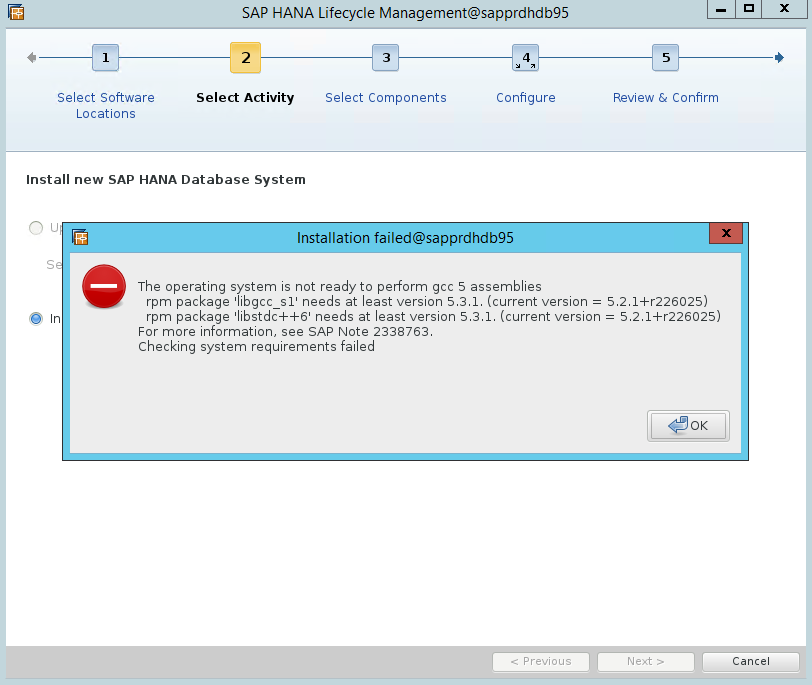
이 문제를 해결하려면 다음 스크린샷과 같이 libgcc_sl 라이브러리 및 libstdc++6 라이브러리를 설치합니다.
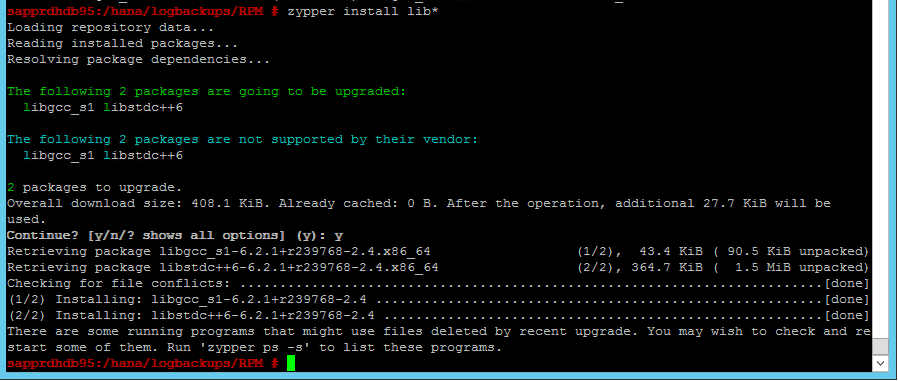
시나리오 5: Pacemaker 서비스 실패
Pacemaker 서비스를 시작할 수 없는 경우 다음 정보가 나타납니다.
sapprdhdb95:/ # systemctl start pacemaker
A dependency job for pacemaker.service failed. See 'journalctl -xn' for details.
sapprdhdb95:/ # journalctl -xn
-- Logs begin at Thu 2017-09-28 09:28:14 EDT, end at Thu 2017-09-28 21:48:27 EDT. --
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration map
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration ser
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster closed pr
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster quorum se
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync profile loading s
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [MAIN ] Corosync Cluster Engine exiting normally
Sep 28 21:48:27 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager
-- Subject: Unit pacemaker.service has failed
-- Defined-By: systemd
-- Support: https://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit pacemaker.service has failed.
--
-- The result is dependency.
sapprdhdb95:/ # tail -f /var/log/messages
2017-09-28T18:44:29.675814-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.676023-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster closed process group service v1.01
2017-09-28T18:44:29.725885-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.726069-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster quorum service v0.1
2017-09-28T18:44:29.726164-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync profile loading service
2017-09-28T18:44:29.776349-04:00 sapprdhdb95 corosync[57600]: [MAIN ] Corosync Cluster Engine exiting normally
2017-09-28T18:44:29.778177-04:00 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager.
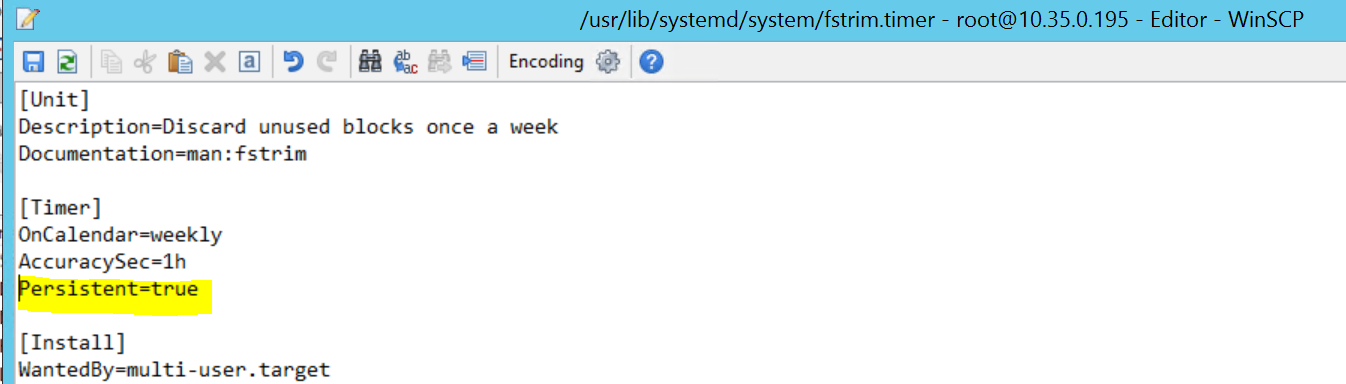
2017-09-28T18:44:40.141030-04:00 sapprdhdb95 systemd[1]: [/usr/lib/systemd/system/fstrim.timer:8] Unknown lvalue 'Persistent' in section 'Timer'
2017-09-28T18:45:01.275038-04:00 sapprdhdb95 cron[57995]: pam_unix(crond:session): session opened for user root by (uid=0)
2017-09-28T18:45:01.308066-04:00 sapprdhdb95 CRON[57995]: pam_unix(crond:session): session closed for user root
문제를 해결하려면 /usr/lib/systemd/system/fstrim.timer 파일에서 다음 줄을 삭제합니다.
Persistent=true
시나리오 6: 노드 2가 클러스터에 조인할 수 없는 경우
ha-cluster-join 명령을 통해 노드 2를 기존 클러스터에 조인하는 데 문제가 있는 경우 다음 오류가 나타납니다.
ERROR: Can’t retrieve SSH keys from <Primary Node>
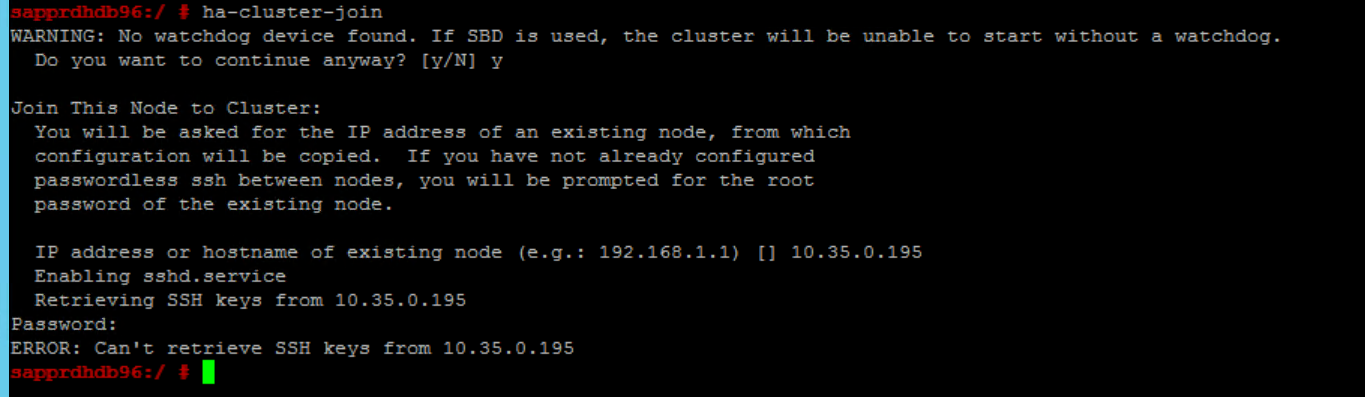
이 문제를 해결하려면 다음을 수행합니다.
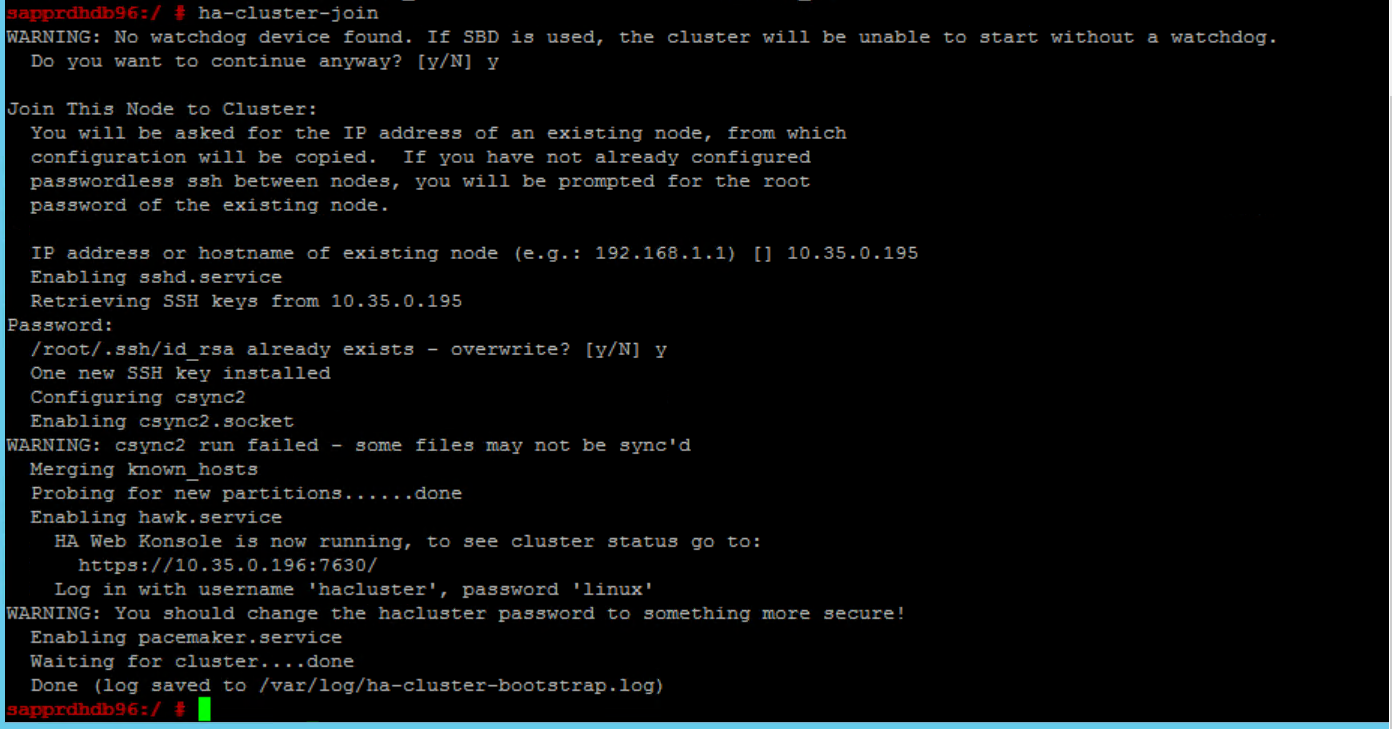
두 노드에서 모두 다음 명령을 실행합니다.
ssh-keygen -q -f /root/.ssh/id_rsa -C 'Cluster Internal' -N '' cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys

노드 2가 클러스터에 추가되어 있는지 확인합니다.
다음 단계
다음 문서에서 SUSE HA 설정에 관한 추가 정보를 찾을 수 있습니다.
- SAP HANA SR 성능 최적화된 시나리오(SUSE 웹 사이트)
- 펜싱 및 펜싱 디바이스(SUSE 웹 사이트)
- SAP HANA용 Pacemaker 클러스터 사용 준비 - 1부: 기본 사항(SAP 블로그)
- SAP HANA용 Pacemaker 클러스터 사용 준비 - 2부: 두 노드에서 실패(SAP 블로그)
- OS 백업 및 복원