C++를 사용하면 동일한 범위에서 동일한 이름의 함수를 둘 이상 지정할 수 있습니다. 이러한 함수를 오버로드된 함수 또는 오버로드라고 합니다. 오버로드된 함수를 사용하면 인수의 형식과 수에 따라 함수에 대해 서로 다른 의미 체계를 제공할 수 있습니다.
예를 들어 인수를 print 사용하는 함수를 고려해 std::string 보세요. 이 함수는 형식 double의 인수를 사용하는 함수와는 매우 다른 작업을 수행할 수 있습니다. 오버로드를 사용하면 이름(예: print_string 또는 print_double.)을 사용할 필요가 없도록 합니다. 컴파일 시 컴파일러는 호출자가 전달한 인수의 형식 및 수에 따라 사용할 오버로드를 선택합니다. 호출 print(42.0)하면 함수가 void print(double d) 호출됩니다. 호출 print("hello world")하면 오버로드가 void print(std::string) 호출됩니다.
멤버 함수와 자유 함수를 모두 오버로드할 수 있습니다. 다음 표에서는 C++가 동일한 범위에서 이름이 같은 함수 그룹을 구분하는 데 사용하는 함수 선언 부분을 보여 줍니다.
오버로드 고려 사항
| 함수 선언 요소 | 오버로드에 사용하나요? |
|---|---|
| 함수 반환 형식 | 아니요 |
| 인수의 수 | 예 |
| 인수 형식 | 예 |
| 줄임표의 존재 여부 | 예 |
typedef 이름 사용 |
아니요 |
| 지정하지 않은 배열 범위 | 아니요 |
const 또는 volatile |
예, 전체 함수에 적용된 경우 |
참조 한정자(& 및 &&) |
예 |
예시
다음 예제에서는 함수 오버로드를 사용하는 방법을 보여 줍니다.
// function_overloading.cpp
// compile with: /EHsc
#include <iostream>
#include <math.h>
#include <string>
// Prototype three print functions.
int print(std::string s); // Print a string.
int print(double dvalue); // Print a double.
int print(double dvalue, int prec); // Print a double with a
// given precision.
using namespace std;
int main(int argc, char *argv[])
{
const double d = 893094.2987;
if (argc < 2)
{
// These calls to print invoke print( char *s ).
print("This program requires one argument.");
print("The argument specifies the number of");
print("digits precision for the second number");
print("printed.");
exit(0);
}
// Invoke print( double dvalue ).
print(d);
// Invoke print( double dvalue, int prec ).
print(d, atoi(argv[1]));
}
// Print a string.
int print(string s)
{
cout << s << endl;
return cout.good();
}
// Print a double in default precision.
int print(double dvalue)
{
cout << dvalue << endl;
return cout.good();
}
// Print a double in specified precision.
// Positive numbers for precision indicate how many digits
// precision after the decimal point to show. Negative
// numbers for precision indicate where to round the number
// to the left of the decimal point.
int print(double dvalue, int prec)
{
// Use table-lookup for rounding/truncation.
static const double rgPow10[] = {
10E-7, 10E-6, 10E-5, 10E-4, 10E-3, 10E-2, 10E-1,
10E0, 10E1, 10E2, 10E3, 10E4, 10E5, 10E6 };
const int iPowZero = 6;
// If precision out of range, just print the number.
if (prec < -6 || prec > 7)
{
return print(dvalue);
}
// Scale, truncate, then rescale.
dvalue = floor(dvalue / rgPow10[iPowZero - prec]) *
rgPow10[iPowZero - prec];
cout << dvalue << endl;
return cout.good();
}
앞의 코드는 파일 범위에서 함수의 오버로드를 print 보여 줍니다.
기본 인수는 함수 형식의 일부로 간주되지 않습니다. 따라서 오버로드된 함수를 선택하는 데 사용되지 않습니다. 해당 기본 인수에만 다른 두 개의 함수는 오버로드된 함수 대신 여러 정의로 간주됩니다.
오버로드된 연산자는 기본 인수를 제공할 수 없습니다.
인수 일치
컴파일러는 현재 범위의 함수 선언과 함수 호출에 제공된 인수 중에서 가장 일치하는 값을 기준으로 호출할 오버로드된 함수를 선택합니다. 적절한 함수를 찾으면 함수가 호출됩니다. 이 컨텍스트에서 "적합"은 다음 중 하나를 의미합니다.
정확히 일치하는 항목을 찾았습니다.
간단한 변환을 수행했습니다.
정수 계열 확장이 수행되었습니다.
원하는 인수 형식에 대한 표준 변환이 존재합니다.
원하는 인수 형식으로의 사용자 정의 변환(변환 연산자 또는 생성자)이 있습니다.
줄임표로 나타낸 인수를 찾았습니다.
컴파일러가 각 인수의 후보 함수 집합을 만듭니다. 후보 함수는 해당 위치의 실제 인수를 형식 인수의 형식으로 변환할 수 있는 함수입니다.
"가장 일치하는 함수" 집합이 각 인수에 대해 빌드되고 모든 집합에 공통된 함수가 선택됩니다. 공통된 함수가 2개 이상일 경우 오버로드가 모호해지고 오류를 생성합니다. 최종적으로 선택된 함수는 하나 이상의 인수에 대해 그룹의 다른 모든 함수보다 항상 더 나은 일치입니다. 명확한 승자가 없으면 함수 호출에서 컴파일러 오류가 생성됩니다.
다음과 같은 선언이 있습니다. 알아보기 쉽게 함수가 Variant 1, Variant 2 및 Variant 3으로 표시되었습니다.
Fraction &Add( Fraction &f, long l ); // Variant 1
Fraction &Add( long l, Fraction &f ); // Variant 2
Fraction &Add( Fraction &f, Fraction &f ); // Variant 3
Fraction F1, F2;
다음과 같은 문이 있습니다.
F1 = Add( F2, 23 );
위의 문에서는 두 집합을 빌드합니다.
집합 1: 형식의 첫 번째 인수가 있는 후보 함수 Fraction |
Set 2: 두 번째 인수를 형식으로 변환할 수 있는 후보 함수 int |
|---|---|
| 변형 1 | Variant 1(int 표준 변환을 사용하여 변환할 long 수 있습니다). |
| 변형 3 |
Set 2의 함수는 실제 매개 변수 형식에서 정식 매개 변수 형식으로 암시적으로 변환되는 함수입니다. 이러한 함수 중 하나에는 실제 매개 변수 형식을 해당 형식 매개 변수 형식으로 변환하는 가장 작은 "비용"이 있습니다.
두 집합의 공통된 함수는 변형 1입니다. 다음은 모호한 함수 호출의 예입니다.
F1 = Add( 3, 6 );
앞의 함수 호출에서 다음 집합을 빌드합니다.
집합 1: 형식의 첫 번째 인수가 있는 후보 함수 int |
집합 2: 형식의 두 번째 인수가 있는 후보 함수 int |
|---|---|
Variant 2(int 표준 변환을 사용하여 변환할 long 수 있습니다.) |
Variant 1(int 표준 변환을 사용하여 변환할 long 수 있습니다). |
이 두 집합의 교집합이 비어 있으므로 컴파일러는 오류 메시지를 생성합니다.
인수 일치의 경우 n개의 기본 인수가 있는 함수는 각각 인수 수가 다른 n+1 개별 함수로 처리됩니다.
줄임표(...)는 와일드카드 역할을 하며 실제 인수와 일치합니다. 오버로드된 함수 집합을 매우 주의하여 디자인하지 않으면 많은 모호한 집합이 발생할 수 있습니다.
참고 항목
오버로드된 함수의 모호성은 함수 호출이 발생할 때까지 확인할 수 없습니다. 이때 함수 호출의 각 인수에 대해 집합이 빌드되고 명확한 오버로드가 존재하는지 여부를 확인할 수 있습니다. 즉, 특정 함수 호출로 인해 모호성이 표시될 때까지 코드에 모호성을 유지할 수 있습니다.
인수 형식 차이
오버로드된 함수는 다른 이니셜라이저를 사용하는 인수 형식을 구분합니다. 따라서, 주어진 형식의 인수와 그 형식에 대한 참조는 오버로드 목적의 형식과 동일한 것으로 간주됩니다. 동일한 이니셜라이저를 사용하므로 동일한 것으로 간주됩니다. 예를 들어, max( double, double )는 max( double &, double & )와 동일한 것으로 간주됩니다. 이러한 두 함수를 선언하면 오류가 발생합니다.
같은 이유로, 오버로드를 위해 기본 형식과 const 다르게 수정되거나 volatile 수정되지 않은 형식의 함수 인수입니다.
그러나 함수 오버로드 메커니즘은 정규화된 참조와 const 기본 형식에 volatile 대한 참조를 구분할 수 있습니다. 다음과 같은 코드를 사용할 수 있습니다.
// argument_type_differences.cpp
// compile with: /EHsc /W3
// C4521 expected
#include <iostream>
using namespace std;
class Over {
public:
Over() { cout << "Over default constructor\n"; }
Over( Over &o ) { cout << "Over&\n"; }
Over( const Over &co ) { cout << "const Over&\n"; }
Over( volatile Over &vo ) { cout << "volatile Over&\n"; }
};
int main() {
Over o1; // Calls default constructor.
Over o2( o1 ); // Calls Over( Over& ).
const Over o3; // Calls default constructor.
Over o4( o3 ); // Calls Over( const Over& ).
volatile Over o5; // Calls default constructor.
Over o6( o5 ); // Calls Over( volatile Over& ).
}
출력
Over default constructor
Over&
Over default constructor
const Over&
Over default constructor
volatile Over&
또한 포인터 및 constvolatile 개체는 오버로드를 위해 기본 형식에 대한 포인터와 다른 것으로 간주됩니다.
인수 일치 및 변환
컴파일러가 실제 인수를 함수 선언의 인수와 일치시키려고 할 때 정확히 일치하는 항목이 없을 경우 표준 또는 사용자 정의 변환을 통해 올바른 형식을 가져오도록 할 수 있습니다. 변환 애플리케이션에는 다음의 규칙이 적용됩니다.
둘 이상의 사용자 정의 변환을 포함하는 변환 시퀀스는 고려되지 않습니다.
중간 변환을 제거하여 단축할 수 있는 변환 시퀀스는 고려되지 않습니다.
변환의 결과 시퀀스(있는 경우)를 가장 일치하는 시퀀스라고 합니다. 표준 변환(표준 변환에 설명)을 사용하여 형식 int 개체를 형식 unsigned long 으로 변환하는 방법에는 여러 가지가 있습니다.
에서
int다음으로longlongunsigned long변환합니다.에서
int.로unsigned long변환
첫 번째 시퀀스는 원하는 목표를 달성하지만 더 짧은 시퀀스가 존재하기 때문에 가장 일치하는 시퀀스는 아닙니다.
다음 표에서는 간단한 변환이라는 변환 그룹을 보여 줍니다. 사소한 변환은 컴파일러가 가장 적합한 일치 항목으로 선택하는 시퀀스에 제한적인 영향을 줍니다. 간단한 변환의 효과는 테이블 다음에 설명되어 있습니다.
사소한 변환
| 인수 형식 | 변환된 형식 |
|---|---|
type-name |
type-name& |
type-name& |
type-name |
type-name[] |
type-name* |
type-name(argument-list) |
(*type-name)(argument-list) |
type-name |
const type-name |
type-name |
volatile type-name |
type-name* |
const type-name* |
type-name* |
volatile type-name* |
변환이 시도되는 시퀀스는 다음과 같습니다.
정확한 일치. 함수가 호출되는 형식과 함수 프로토타입에서 선언된 형식 간 정확한 일치는 항상 가장 좋은 일치입니다. trivial 변환 시퀀스는 정확히 일치하는 항목으로 분류됩니다. 그러나 이러한 변환을 수행하지 않는 시퀀스는 변환하는 시퀀스보다 더 나은 것으로 간주됩니다.
포인터에서 포인터로(
consttotype-name*)로 이동합니다const type-name*.포인터에서 포인터로(
volatiletotype-name*)로 이동합니다volatile type-name*.참조에서 참조로(
consttotype-name&).const type-name&참조에서 참조로(
volatiletotype-name&).volatile type&
승격을 통한 일치. 정수 승격만 포함하는 정확한 일치 항목으로 분류되지 않은 시퀀스, 변환 순서
floatdouble및 간단한 변환은 승격을 사용하여 일치 항목으로 분류됩니다. 승격을 통한 일치는 정확한 일치만큼 양호하지는 않지만 표준 변환을 통한 일치에 비해 좋습니다.표준 변환을 통한 일치. 표준 변환과 trivial 변환만 포함 포함하는, 정확한 일치 또는 승격을 통한 일치로 분류되지 않은 시퀀스는 표준 변환을 통한 일치로 분류됩니다. 이 범주에는 다음 규칙이 적용됩니다.
포인터에서 파생 클래스로 변환하고 직접 또는 간접 기본 클래스에 대한 포인터로 변환하는
void *것이 변환하는const void *것이 좋습니다.파생 클래스에 대한 포인터에서 기본 클래스에 대한 포인터로 변환할 경우 기본 클래스가 직접 기본 클래스에 가까울수록 더 잘 일치합니다. 클래스 계층 구조가 다음 그림과 같이 있다고 가정합니다.

기본 변환을 보여 주는 그래프입니다.
D* 형식에서 C* 형식으로 변환하는 것이 D* 형식에서 B* 형식으로 변환하는 것보다 좋습니다. 마찬가지로 D* 형식에서 B* 형식으로 변환하는 것이 D* 형식에서 A* 형식으로 변환하는 것보다 좋습니다.
이 규칙은 참조 변환에 동일하게 적용됩니다.
D& 형식에서 C& 형식으로 변환하는 것이 D& 형식에서 B& 형식 등으로 변환하는 것보다 좋습니다.
이 규칙은 멤버 포인터 변환에 동일하게 적용됩니다.
T D::* 형식에서 T C::* 형식으로 변환하는 것이 T D::* 형식에서 T B::* 형식 등으로 변환하는 것보다 좋습니다. 여기서 T는 멤버 형식입니다.
앞의 규칙은 지정된 파생 경로에만 적용됩니다. 다음 그림에 표시된 그래프를 살펴보세요.
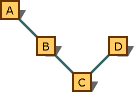
기본 변환을 보여 주는 다중 상속 그래프입니다.
C* 형식에서 B* 형식으로 변환하는 것이 C* 형식에서 A* 형식으로 변환하는 것보다 좋습니다. 이유는 이들이 동일한 경로에 있고 B*가 더 가깝기 때문입니다. 그러나 형식에서 형식 C* 으로의 변환은 형식 D*A*으로 변환하는 것이 바람직하지 않습니다. 변환이 다른 경로를 따르기 때문에 기본 설정이 없습니다.
사용자 정의 변환을 통한 일치. 이 시퀀스는 정확한 일치, 승격을 사용한 일치 또는 표준 변환을 사용하는 일치 항목으로 분류할 수 없습니다. 사용자 정의 변환과 일치 항목으로 분류하려면 시퀀스에 사용자 정의 변환, 표준 변환 또는 사소한 변환만 포함되어야 합니다. 사용자 정의 변환과의 일치는 줄임표(
...)를 사용한 일치보다 더 나은 일치로 간주되지만 표준 변환과의 일치만큼 일치하는 항목은 아닙니다.줄임표를 통한 일치. 선언에서 줄임표와 일치하는 모든 시퀀스는 줄임표를 통한 일치로 분류됩니다. 가장 약한 경기로 간주됩니다.
기본 승격 또는 변환이 존재하지 않는 경우 사용자 정의 변환이 적용됩니다. 이러한 변환은 일치하는 인수의 형식에 따라 선택됩니다. 다음 코드를 생각해 봅시다.
// argument_matching1.cpp
class UDC
{
public:
operator int()
{
return 0;
}
operator long();
};
void Print( int i )
{
}
UDC udc;
int main()
{
Print( udc );
}
클래스 UDC 에 사용할 수 있는 사용자 정의 변환은 형식 및 형식 intlong입니다. 따라서 컴파일러가 일치하는 개체 형식을 위한 변환을 고려합니다(UDC). 변환 int 이 존재하고 선택됩니다.
일치하는 인수를 처리하는 동안 인수 및 사용자 정의 변환 결과 모두에 표준 변환을 적용할 수 있습니다. 따라서 다음 코드가 작동합니다.
void LogToFile( long l );
...
UDC udc;
LogToFile( udc );
이 예제에서 컴파일러는 사용자 정의 변환operator long을 호출하여 형식udc으로 변환 long 합니다. 사용자 정의 형식 long 변환이 정의되지 않은 경우 컴파일러는 먼저 사용자 정의 UDC 변환을 사용하여 형식 int 을 형식 operator int 으로 변환합니다. 그런 다음 형식에서 형식 intlong 으로 표준 변환을 적용하여 선언의 인수와 일치합니다.
인수와 일치하기 위해 사용자 정의 변환이 필요한 경우 가장 일치하는 항목을 평가할 때 표준 변환이 사용되지 않습니다. 둘 이상의 후보 함수에 사용자 정의 변환이 필요한 경우에도 함수는 동일한 것으로 간주됩니다. 예시:
// argument_matching2.cpp
// C2668 expected
class UDC1
{
public:
UDC1( int ); // User-defined conversion from int.
};
class UDC2
{
public:
UDC2( long ); // User-defined conversion from long.
};
void Func( UDC1 );
void Func( UDC2 );
int main()
{
Func( 1 );
}
두 버전 Func 모두 형식을 클래스 형식 int 인수로 변환하려면 사용자 정의 변환이 필요합니다. 가능한 변환은 다음과 같습니다.
형식에서 형식
intUDC1으로 변환(사용자 정의 변환).형식에서 형식
intlong으로 변환한 다음 형식UDC2으로 변환합니다(2단계 변환).
두 번째 변환에는 표준 변환과 사용자 정의 변환이 모두 필요하지만 두 변환은 여전히 동일한 것으로 간주됩니다.
참고 항목
사용자 정의 변환은 초기화에 의한 생성 또는 변환에 의한 변환으로 간주됩니다. 컴파일러는 최상의 일치를 결정할 때 두 메서드를 동일하게 간주합니다.
인수 일치 및 this 포인터
클래스 멤버 함수는 로 선언되었는지 여부에 따라 다르게 처리됩니다 static.
static 함수에는 포인터를 제공하는 this 암시적 인수가 없으므로 일반 멤버 함수보다 인수가 적은 것으로 간주됩니다. 그렇지 않으면 동일하게 선언됩니다.
함수가 호출되는 개체 형식과 일치하기 위해 암시적 static 포인터가 필요하지 않은 this 멤버 함수입니다. 또는 오버로드된 연산자의 경우 연산자가 적용되는 개체와 일치하도록 첫 번째 인수가 필요합니다. 오버로드된 연산자에 대한 자세한 내용은 오버로드된 연산자를 참조 하세요.
오버로드된 함수의 다른 인수와 달리 컴파일러는 임시 개체를 도입하지 않으며 포인터 인수와 일치 this 하려고 할 때 변환을 시도하지 않습니다.
멤버 선택 연산자를 -> 사용하여 클래스 class_namethis 의 멤버 함수에 액세스하는 경우 포인터 인수에는 형식이 class_name * const있습니다. 멤버로 선언되거나 선언된 const 경우 형식은 각각 및 volatile그 형식입니다const class_name * const.volatile class_name * const
명시적 . 주소 연산자가 개체 이름 앞에 추가된다는 점을 제외하면 & 멤버 선택 연산자는 동일하게 작동합니다. 다음 예제에서는 그 작동 방식을 보여 줍니다.
// Expression encountered in code
obj.name
// How the compiler treats it
(&obj)->name
->*의 왼쪽 피연산자와 .*(멤버에 대한 포인터) 연산자는 인수 일치와 관련하여 . 및 ->(멤버 선택) 연산자와 동일한 방식으로 처리됩니다.
멤버 함수의 참조 한정자
참조 한정자를 사용하면 가리키는 개체가 rvalue인지 lvalue인지 여부에 따라 멤버 함수를 오버로드할 this 수 있습니다. 데이터에 대한 포인터 액세스를 제공하지 않도록 선택하는 시나리오에서 불필요한 복사 작업을 방지하려면 이 기능을 사용합니다. 예를 들어 클래스 C 는 생성자의 일부 데이터를 초기화하고 멤버 함수 get_data()에서 해당 데이터의 복사본을 반환한다고 가정합니다. 형식 C 의 개체가 소멸될 rvalue인 경우 컴파일러는 오버로드를 선택하여 get_data() && 데이터를 복사하는 대신 이동합니다.
#include <iostream>
#include <vector>
using namespace std;
class C
{
public:
C() {/*expensive initialization*/}
vector<unsigned> get_data() &
{
cout << "lvalue\n";
return _data;
}
vector<unsigned> get_data() &&
{
cout << "rvalue\n";
return std::move(_data);
}
private:
vector<unsigned> _data;
};
int main()
{
C c;
auto v = c.get_data(); // get a copy. prints "lvalue".
auto v2 = C().get_data(); // get the original. prints "rvalue"
return 0;
}
오버로드에 대한 제한 사항
여러 제한은 사용할 수 있는 오버로드된 함수 집합을 관리합니다.
오버로드된 함수 집합의 임의의 두 함수에는 서로 다른 인수 목록이 있어야 합니다.
반환 형식만을 기준으로 동일한 형식의 인수 목록이 있는 함수를 오버로드하는 것은 오류입니다.
Microsoft 전용
특히 지정된 메모리 모델 한정자에 따라 반환 형식에 따라 오버로드
operator new할 수 있습니다.Microsoft 전용 종료
멤버 함수는 하나만 오버로드할 수 없습니다. 하나는 다른 함수이고 다른 함수는
static오버로드되지 않기static때문입니다.typedef선언은 새 형식을 정의하지 않습니다. 기존 형식의 동의어를 소개합니다. 오버로드 메커니즘에는 영향을 주지 않습니다. 다음 코드를 생각해 봅시다.typedef char * PSTR; void Print( char *szToPrint ); void Print( PSTR szToPrint );위의 두 함수에는 동일한 인수 목록이 있습니다.
PSTR는 형식char *의 동의어입니다. 멤버 범위에서 이 코드를 사용하면 오류가 발생합니다.열거 형식은 고유한 형식이며 오버로드된 함수 사이를 구분하는 데 사용할 수 있습니다.
"array of" 및 "pointer to" 형식은 오버로드된 함수를 구분하기 위해 동일하지만 1차원 배열에 대해서만 동일한 것으로 간주됩니다. 이러한 오버로드된 함수는 충돌하고 오류 메시지를 생성합니다.
void Print( char *szToPrint ); void Print( char szToPrint[] );더 높은 차원 배열의 경우 두 번째 및 이후 차원은 형식의 일부로 간주됩니다. 오버로드된 함수를 구분하는 데 사용됩니다.
void Print( char szToPrint[] ); void Print( char szToPrint[][7] ); void Print( char szToPrint[][9][42] );
오버로드, 재정의 및 숨기기
동일한 범위에서 동일한 이름의 두 함수 선언은 동일한 함수 또는 두 개의 개별 오버로드된 함수를 참조할 수 있습니다. 선언의 인수 목록에 동일한 형식의 인수가 포함되어 있으면(이전 단원 참조) 함수 선언은 같은 함수를 참조하고, 그렇지 않으면 오버로드를 사용하여 선택된 서로 다른 두 함수를 참조합니다.
클래스 범위는 엄격하게 관찰됩니다. 기본 클래스에서 선언된 함수는 파생 클래스에서 선언된 함수와 동일한 범위에 있지 않습니다. 파생 클래스의 함수가 기본 클래스의 함수와 동일한 이름으로 virtual 선언되면 파생 클래스 함수는 기본 클래스 함수 를 재정의합니다 . 자세한 내용은 Virtual Functions를 참조 하세요.
기본 클래스 함수가 선언 virtual되지 않은 경우 파생 클래스 함수는 이를 숨깁니다 . 재정의와 숨기기는 모두 오버로드와 구별됩니다.
블록 범위는 엄격하게 관찰됩니다. 파일 범위에서 선언된 함수는 로컬로 선언된 함수와 동일한 범위에 있지 않습니다. 로컬로 선언된 함수의 이름이 파일 범위에서 선언된 함수의 이름과 같을 경우 로컬로 선언된 함수는 오버로드를 유발하는 대신 파일 범위의 함수를 숨깁니다. 예시:
// declaration_matching1.cpp
// compile with: /EHsc
#include <iostream>
using namespace std;
void func( int i )
{
cout << "Called file-scoped func : " << i << endl;
}
void func( char *sz )
{
cout << "Called locally declared func : " << sz << endl;
}
int main()
{
// Declare func local to main.
extern void func( char *sz );
func( 3 ); // C2664 Error. func( int ) is hidden.
func( "s" );
}
위의 코드에서는 func 함수의 두 정의를 보여 줍니다. 형식 char * 의 인수를 사용하는 정의는 문 때문에 로컬 main 입니다 extern . 따라서 형식 int 의 인수를 사용하는 정의는 숨겨지고 첫 번째 호출 func 은 오류입니다.
오버로드된 멤버 함수의 경우 함수의 버전마다 서로 다른 액세스 권한을 부여할 수 있습니다. 여전히 바깥쪽 클래스의 범위에 있는 것으로 간주되므로 오버로드된 함수입니다. 멤버 함수 Deposit가 오버로드되는 다음 코드를 살펴보겠습니다. 한 버전은 public이고 다른 버전은 private입니다.
이 샘플의 목적은 입금을 하려면 올바른 암호가 필요한 Account 클래스를 제공하는 것입니다. 오버로드를 사용하여 수행됩니다.
in Deposit 호출 Account::Deposit 은 프라이빗 멤버 함수를 호출합니다. 이 호출은 멤버 함수이며 클래스의 프라이빗 멤버에 액세스할 수 있기 때문에 Account::Deposit 정확합니다.
// declaration_matching2.cpp
class Account
{
public:
Account()
{
}
double Deposit( double dAmount, char *szPassword );
private:
double Deposit( double dAmount )
{
return 0.0;
}
int Validate( char *szPassword )
{
return 0;
}
};
int main()
{
// Allocate a new object of type Account.
Account *pAcct = new Account;
// Deposit $57.22. Error: calls a private function.
// pAcct->Deposit( 57.22 );
// Deposit $57.22 and supply a password. OK: calls a
// public function.
pAcct->Deposit( 52.77, "pswd" );
}
double Account::Deposit( double dAmount, char *szPassword )
{
if ( Validate( szPassword ) )
return Deposit( dAmount );
else
return 0.0;
}