이 문서에서는 C++ 가속 대규모 병렬 처리(C++ AMP)를 사용하여 GPU(그래픽 처리 장치)를 활용하는 애플리케이션을 디버그하는 방법을 보여 줍니다. 큰 정수 배열을 합산하는 병렬 감소 프로그램을 사용합니다. 이 단계별 설명에서는 다음 작업을 설명합니다.
- GPU 디버거를 시작합니다.
- GPU 스레드 창에서 GPU 스레드 검사
- 병렬 스택 창을 사용하여 여러 GPU 스레드의 호출 스택을 동시에 관찰합니다.
- 병렬 조사식 창을 사용하여 여러 스레드에서 단일 식의 값을 동시에 검사합니다.
- GPU 스레드 플래그 지정, 동결, 해동 및 그룹화
- 코드의 특정 위치에 대한 타일의 모든 스레드를 실행합니다.
사전 요구 사항
이 연습을 시작하기 전에 다음을 수행합니다.
메모
C++ AMP 헤더는 Visual Studio 2022 버전 17.0부터 더 이상 사용되지 않습니다.
AMP 헤더를 포함하면 빌드 오류가 생성됩니다. 경고를 무음으로 표시하기 위해 AMP 헤더를 포함하기 전에 정의 _SILENCE_AMP_DEPRECATION_WARNINGS 합니다.
- C++ AMP 개요를 읽습니다.
- 텍스트 편집기에서 줄 번호가 표시되는지 확인합니다. 자세한 내용은 방법: 편집기에서 줄 번호 표시를 참조하세요.
- 소프트웨어 에뮬레이터에서 디버깅을 지원하려면 Windows 8 또는 Windows Server 2012 이상을 실행하고 있는지 확인합니다.
메모
컴퓨터는 다음 지침에서 Visual Studio 사용자 인터페이스 요소 중 일부에 대해 다른 이름 또는 위치를 표시할 수 있습니다. 이러한 요소는 사용하는 Visual Studio 버전 및 설정에 따라 결정됩니다. 자세한 내용은 IDE 개인 설정을 참조하세요.
샘플 프로젝트를 만들려면
프로젝트를 만드는 지침은 사용 중인 Visual Studio 버전에 따라 달라집니다. 이 페이지의 목차 위에 올바른 설명서 버전이 선택되어 있는지 확인합니다.
Visual Studio에서 샘플 프로젝트를 만들려면
메뉴 모음에서 파일>새로 만들기>프로젝트를 선택하여 새 프로젝트 만들기 대화 상자를 엽니다.
대화 상자 맨 위에서 언어를 C++로 설정하고, 플랫폼을 Windows로 설정하고, 프로젝트 형식을 콘솔로 설정합니다.
필터링된 프로젝트 형식 목록에서 콘솔 앱을 선택한 후 다음을 선택합니다. 다음 페이지에서 이름 상자에 입력
AMPMapReduce하여 프로젝트의 이름을 지정하고 다른 이름을 원하는 경우 프로젝트 위치를 지정합니다.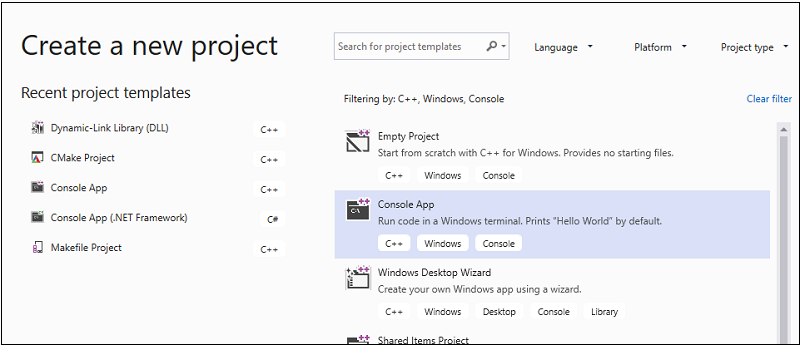
만들기 단추를 선택하여 클라이언트 프로젝트를 만듭니다.
다음:
AMPMapReduce.cpp 열고 해당 콘텐츠를 다음 코드로 바꿉다.
// AMPMapReduce.cpp defines the entry point for the program. // The program performs a parallel-sum reduction that computes the sum of an array of integers. #include <stdio.h> #include <tchar.h> #include <amp.h> const int BLOCK_DIM = 32; using namespace concurrency; void sum_kernel_tiled(tiled_index<BLOCK_DIM> t_idx, array<int, 1> &A, int stride_size) restrict(amp) { tile_static int localA[BLOCK_DIM]; index<1> globalIdx = t_idx.global * stride_size; index<1> localIdx = t_idx.local; localA[localIdx[0]] = A[globalIdx]; t_idx.barrier.wait(); // Aggregate all elements in one tile into the first element. for (int i = BLOCK_DIM / 2; i > 0; i /= 2) { if (localIdx[0] < i) { localA[localIdx[0]] += localA[localIdx[0] + i]; } t_idx.barrier.wait(); } if (localIdx[0] == 0) { A[globalIdx] = localA[0]; } } int size_after_padding(int n) { // The extent might have to be slightly bigger than num_stride to // be evenly divisible by BLOCK_DIM. You can do this by padding with zeros. // The calculation to do this is BLOCK_DIM * ceil(n / BLOCK_DIM) return ((n - 1) / BLOCK_DIM + 1) * BLOCK_DIM; } int reduction_sum_gpu_kernel(array<int, 1> input) { int len = input.extent[0]; //Tree-based reduction control that uses the CPU. for (int stride_size = 1; stride_size < len; stride_size *= BLOCK_DIM) { // Number of useful values in the array, given the current // stride size. int num_strides = len / stride_size; extent<1> e(size_after_padding(num_strides)); // The sum kernel that uses the GPU. parallel_for_each(extent<1>(e).tile<BLOCK_DIM>(), [&input, stride_size] (tiled_index<BLOCK_DIM> idx) restrict(amp) { sum_kernel_tiled(idx, input, stride_size); }); } array_view<int, 1> output = input.section(extent<1>(1)); return output[0]; } int cpu_sum(const std::vector<int> &arr) { int sum = 0; for (size_t i = 0; i < arr.size(); i++) { sum += arr[i]; } return sum; } std::vector<int> rand_vector(unsigned int size) { srand(2011); std::vector<int> vec(size); for (size_t i = 0; i < size; i++) { vec[i] = rand(); } return vec; } array<int, 1> vector_to_array(const std::vector<int> &vec) { array<int, 1> arr(vec.size()); copy(vec.begin(), vec.end(), arr); return arr; } int _tmain(int argc, _TCHAR* argv[]) { std::vector<int> vec = rand_vector(10000); array<int, 1> arr = vector_to_array(vec); int expected = cpu_sum(vec); int actual = reduction_sum_gpu_kernel(arr); bool passed = (expected == actual); if (!passed) { printf("Actual (GPU): %d, Expected (CPU): %d", actual, expected); } printf("sum: %s\n", passed ? "Passed!" : "Failed!"); getchar(); return 0; }메뉴 모음에서 파일>모두 저장을 차례로 선택합니다.
솔루션 탐색기 AMPMapReduce의 바로 가기 메뉴를 열고 속성을 선택합니다.
속성 페이지 대화 상자에서 구성 속성 아래의 C/C++>를 선택합니다.
미리 컴파일된 헤더 속성에서 미리 컴파일된 헤더 사용 안 함을 선택한 다음 확인 버튼을 선택합니다.
메뉴 모음에서 빌드>솔루션 빌드를 선택합니다.
CPU 코드 디버깅
이 절차에서는 로컬 Windows 디버거를 사용하여 이 애플리케이션의 CPU 코드가 올바른지 확인합니다. 특히 흥미로운 이 애플리케이션의 CPU 코드 세그먼트는 함수의 forreduction_sum_gpu_kernel 루프입니다. GPU에서 실행되는 트리 기반 병렬 감소를 제어합니다.
CPU 코드를 디버그하려면
솔루션 탐색기 AMPMapReduce의 바로 가기 메뉴를 열고 속성을 선택합니다.
속성 페이지 대화 상자의 구성 속성 아래에서 디버깅을 선택합니다. 디버거 시작 목록에서 로컬 Windows 디버거가 선택되어 있는지 확인합니다.
코드 편집기로 돌아갑니다.
다음 그림에 표시된 코드 줄에 중단점을 설정합니다(약 67줄 70줄).

CPU 중단점메뉴 모음에서 디버그>디버깅 시작을 차례로 선택합니다.
로컬 창에서 줄 70의 중단점에 도달할 때까지
stride_size값이 어떻게 변하는지 관찰합니다.메뉴 모음에서 디버그>디버깅 중지를 차례로 선택합니다.
GPU 코드 디버깅
이 섹션에서는 함수에 포함된 코드인 GPU 코드를 디버그하는 sum_kernel_tiled 방법을 보여줍니다. GPU 코드는 각 "블록"에 대한 정수의 합계를 병렬로 계산합니다.
GPU 코드를 디버그하려면
솔루션 탐색기 AMPMapReduce의 바로 가기 메뉴를 열고 속성을 선택합니다.
속성 페이지 대화 상자의 구성 속성 아래에서 디버깅을 선택합니다.
실행할 디버거 목록에서 로컬 Windows 디버거를 선택합니다.
디버거 유형 목록에서 자동이 선택되어 있는지 확인합니다.
자동 이 기본값입니다. Windows 10 이전 버전에서는 GPU만이 자동 대신 필수 값입니다.
확인 단추를 선택합니다.
다음 그림과 같이 줄 30에서 중단점을 설정합니다.

GPU 중단점메뉴 모음에서 디버그>디버깅 시작을 차례로 선택합니다. 67줄과 70줄에 있는 CPU 코드의 중단점은 GPU 디버깅 중에 실행되지 않습니다. 이러한 코드 줄은 CPU에서 실행되기 때문입니다.
GPU 스레드 창을 사용하려면
메뉴 모음에서 디버그>>를 선택하여 GPU 스레드 창을 여십시오.
표시되는 GPU 스레드 창에서 GPU 스레드의 상태를 검사할 수 있습니다.
Visual Studio 아래쪽에 GPU 스레드 창을 도킹합니다. 스레드 스위치 확장 단추를 선택하여 타일 및 스레드 텍스트 상자를 표시합니다. 다음 그림과 같이 GPU 스레드 창에는 활성 및 차단된 GPU 스레드의 총 수가 표시됩니다.

GPU 스레드 창이 계산에 313개 타일이 할당됩니다. 각 타일에는 32개의 스레드가 포함됩니다. 로컬 GPU 디버깅은 소프트웨어 에뮬레이터에서 발생하므로 4개의 활성 GPU 스레드가 있습니다. 네 스레드는 동시에 명령을 실행한 다음 다음 명령으로 함께 이동합니다.
GPU 스레드 창에는 4개의 GPU 스레드가 활성 상태이고 약 21행에 정의된 tile_barrier::wait 구문에서 28개의 GPU 스레드가 차단되어 있습니다. 모든 32개의 GPU 스레드는 첫 번째 타일
tile[0]에 속합니다. 화살표는 현재 스레드를 포함하는 행을 가리킵니다. 다른 스레드로 전환하려면 다음 방법 중 하나를 사용합니다.GPU 스레드 창에서 전환할 스레드의 행을 찾아 바로 가기 메뉴를 열고 스레드로 전환을 선택합니다. 행이 둘 이상의 스레드를 나타내는 경우 스레드 좌표에 따라 첫 번째 스레드로 전환됩니다.
해당 텍스트 상자에 스레드의 타일 및 스레드 값을 입력한 다음 스레드 전환 단추를 선택합니다.
호출 스택 창에는 현재 GPU 스레드의 호출 스택이 표시됩니다.
병렬 스택 창을 사용하려면
병렬 스택 창을 열려면 메뉴 모음에서 디버그>>을 선택하세요.
병렬 스택 창을 사용하여 여러 GPU 스레드의 스택 프레임을 동시에 검사할 수 있습니다.
Visual Studio 아래쪽에 병렬 스택 창을 도킹합니다.
왼쪽 위 모서리의 목록에서 스레드가 선택되어 있는지 확인합니다. 다음 그림에서 병렬 스택 창은 GPU 스레드 창에서 확인한 GPU 스레드의 호출 스택 중심 보기를 보여줍니다.

병렬 스택 창32개의 스레드가
_kernel_stub에서 람다 문으로, 그리고parallel_for_each함수 호출을 거쳐 병렬 감소가 발생하는sum_kernel_tiled함수로 이동했습니다. 32개 스레드 중 28개가tile_barrier::wait문까지 진행되었으며, 22라인에서 차단되어 있습니다. 나머지 4개의 스레드는 30라인의sum_kernel_tiled함수에서 활성화되어 있습니다.GPU 스레드의 속성을 검사할 수 있습니다. 병렬 스택 창의 풍부한 데이터 설명에 있는 GPU 스레드 창에서 사용할 수 있습니다 . 이를 보려면
sum_kernel_tiled의 스택 프레임에 마우스로 포인터를 가리킵니다. 다음 그림에서는 DataTip을 보여 줍니다.
GPU 스레드 데이터팁병렬 스택 창에 대한 자세한 내용은 병렬 스택 창 사용을 참조 하세요.
병렬 워치 창을 사용하려면
Parallel Watch 창을 열려면 메뉴 모음에서 디버그>Windows>Parallel Watch>Parallel Watch 1을 선택하세요.
병렬 감시 창을 사용하여 여러 스레드에서 식의 값을 검사할 수 있습니다.
Visual Studio 아래쪽에 병렬 조사 1 창을 도킹합니다. 병렬 관측 창의 테이블에는 32개의 행이 있습니다. 각각은 GPU 스레드 창과 병렬 스택 창 모두에 나타나는 GPU 스레드에 해당합니다 . 이제 모든 32개의 GPU 스레드에서 검사할 값을 가진 식을 입력할 수 있습니다.
조사식 추가 열 머리글을 선택하고
localIdx를 입력한 다음 Enter 키를 누릅니다.조사식 추가 열 머리글을 다시 선택하고, 입력한 다음,
globalIdx키를 누릅니다.조사식 추가 열 머리글을 다시 선택하고, 입력한 다음,
localA[localIdx[0]]키를 누릅니다.해당 열 머리글을 선택하여 지정된 식을 기준으로 정렬할 수 있습니다.
localA[localIdx[0]] 열 머리글을 선택하여 열을 정렬합니다. 다음 그림에서는 localA[localIdx[0]]를 기준으로 정렬한 결과를 보여 줍니다.

정렬 결과Excel 단추를 선택한 다음 Excel에서 열기를 선택하여 병렬 조사식 창의 콘텐츠를 Excel로 내보낼 수 있습니다. 개발 컴퓨터에 Excel이 설치되어 있는 경우 단추가 콘텐츠가 포함된 Excel 워크시트를 엽니다.
Parallel Watch 창의 오른쪽 위 모서리에는 부울 논리식을 사용하여 콘텐츠를 걸러내는 데 사용할 수 있는 필터 제어 기능이 있습니다. 필터 컨트롤 텍스트 상자에 입력
localA[localIdx[0]] > 20000한 다음 Enter 키를 선택합니다.이제 이 창에는 값이
localA[localIdx[0]]20000보다 큰 스레드만 포함됩니다. 콘텐츠는 여전히 이전에 선택한 정렬 작업을 기반으로localA[localIdx[0]]열에 따라 정렬됩니다.
GPU 스레드 플래그 지정
GPU 스레드 창, 병렬 조사 창, 또는 병렬 스택 창의 DataTip에서 GPU 스레드에 플래그를 지정하여 특정 GPU 스레드를 표시할 수 있습니다. GPU 스레드 창의 행에 둘 이상의 스레드가 포함된 경우 해당 행에 플래그를 지정하여 행에 포함된 모든 스레드에 플래그를 지정합니다.
GPU 스레드에 플래그를 지정하려면
병렬 조사식 1 창에서 [스레드] 열 머리글을 선택하여 타일 인덱스 및 스레드 인덱스별로 정렬합니다.
메뉴 모음에서 디버그>계속을 선택하세요. 그러면 활성 상태였던 4개의 스레드가 다음 배리어로 진행됩니다(AMPMapReduce.cpp의 32줄에 정의됨).
현재 활성 상태인 네 개의 스레드가 포함된 행의 왼쪽에 있는 플래그 기호를 선택합니다.
다음 그림에서는 GPU 스레드 창에 있는 4개의 활성 플래그가 지정된 스레드를 보여 줍니다 .

GPU 스레드 창의 활성 스레드병렬 조사식 창과 병렬 스택 창의 DataTip은 모두 플래그가 지정된 스레드를 나타냅니다.
플래그가 지정된 네 개의 스레드에 초점을 맞추려면 플래그가 지정된 스레드만 표시하도록 선택할 수 있습니다. GPU 스레드
, 병렬 관찰 , 병렬 스택 창에서 보이는 내용이 제한됩니다. 플래그가 지정된 항목만 표시 단추를 창이나 디버그 위치 도구 모음에서 선택합니다. 다음 그림은 디버그 위치 도구 모음의 플래그가 지정된 항목만 표시 단추를 보여 줍니다.

플래그된 항목만 표시 버튼이제 GPU 스레드, 병렬 조사식 및 병렬 스택 창에 플래그가 지정된 스레드만 표시됩니다.
GPU 스레드 동결 및 해동
GPU 스레드 창 또는 병렬 관찰창에서 GPU 스레드를 중단(일시 중단)하고 재개(다시 시작)할 수 있습니다. CPU 스레드를 동일한 방식으로 동결 및 해동할 수 있습니다. 자세한 내용은 방법: 스레드 창 사용을 참조 하세요.
GPU 스레드를 동결하고 해동하려면
플래그가 지정된 전용 표시 단추를 선택하여 모든 스레드를 표시합니다.
메뉴 모음에서 계속 디버그>를 선택합니다.
활성 행의 바로 가기 메뉴를 연 다음 고정을 선택합니다.
GPU 스레드 창의 다음 그림은 네 개의 스레드가 모두 동작 중지 상태임을 보여 줍니다.

GPU 스레드 창의 정지된 스레드마찬가지로 병렬 감시 창에는 네 개의 스레드가 모두 고정되어 있음을 보여 줍니다.
메뉴 모음에서 디버그 및 >을 선택하여, 4개의 GPU 스레드가 줄 22의 장벽을 넘고 30번째 줄의 중단점에 도달할 수 있도록 하십시오. GPU 스레드 창에는 이전에 고정된 4개의 스레드가 여전히 고정되어 있으면서도 활성 상태로 유지됩니다.
메뉴 모음에서 디버그, 계속을 선택합니다.
병렬 감시 창에서 개별 또는 여러 GPU 스레드를 활성화할 수도 있습니다.
GPU 스레드를 그룹화하려면
GPU 스레드 창의 스레드 중 하나를 우클릭하여 바로 가기 메뉴에서 그룹화 기준, 주소를 선택합니다.
GPU 스레드 창의 스레드는 주소별로 그룹화됩니다. 주소는 각 스레드 그룹이 있는 디스어셈블리의 명령에 해당합니다. 24개의 스레드는 tile_barrier::wait 메서드가 실행되는 줄 22에 있습니다. 12개의 스레드는 32번째 줄의 배리어에 대한 지침에 있습니다. 이러한 스레드 중 4개는 플래그가 지정됩니다. 8개의 스레드가 줄 30의 중단점에 있습니다. 이러한 스레드 중 4개는 멈춰 있습니다. 다음 그림에서는 GPU 스레드 창의 그룹화된 스레드를 보여 줍니다 .

GPU 스레드 창의 그룹화된 스레드병렬 조사 윈도우의 데이터 표에서 바로 가기 메뉴를 열어 그룹화 작업을 수행할 수도 있습니다. Group By를 선택한 다음 스레드를 그룹화할 방법에 해당하는 메뉴 항목을 선택합니다.
코드에서 특정 위치에 모든 스레드 실행
지정된 타일의 모든 스레드를 커서가 있는 줄까지 현재 타일을 커서까지 실행을 사용하여 실행합니다.
커서로 표시된 위치에 모든 스레드를 실행하려면
고정 스레드의 바로 가기 메뉴에서 Thaw를 선택합니다.
코드 편집기에서 커서를 줄 30에 넣습니다.
코드 편집기 바로 가기 메뉴에서 커서에 현재 타일 실행을 선택합니다.
이전에 21줄의 장벽에서 차단된 24개의 스레드가 32줄로 진행되었습니다. GPU 스레드 창에 표시됩니다.
참고하십시오
C++ AMP 개요
GPU 코드 디버깅
방법: GPU 스레드 창 사용
방법: 병렬 검사 창 사용
동시성 시각화 도우미를 사용하여 C++ AMP 코드 분석