데이터 수집은 다운스트림 애플리케이션에서 사용할 수 있도록 파일, 데이터베이스, API 또는 클라우드 서비스와 같은 다양한 원본에서 데이터를 수집, 읽기 및 준비하는 프로세스입니다. 실제로 이 프로세스는 ETL(Extract-Transform-Load) 워크플로를 따릅니다.
- PDF, Word 문서, 오디오 파일 또는 웹 API 등 원본 원본에서 데이터를 추출합니다.
- 서식 정리, 청크 분할, 보강 또는 변환을 통해 데이터를 변환합니다.
- 검색 및 분석을 위해 데이터베이스, 벡터 저장소 또는 AI 모델과 같은 대상에 데이터를 로드합니다.
AI 및 기계 학습 시나리오, 특히 검색 강화 생성(RAG)의 경우 데이터 수집 프로세스는 단순히 데이터를 한 형식에서 다른 형식으로 변환하는 것 이상의 의미가 있습니다. 지능형 애플리케이션에 데이터를 사용할 수 있도록 만드는 것입니다. 즉, 구조와 의미를 보존하는 방식으로 문서를 나타내고, 관리 가능한 청크로 분할하고, 메타데이터 또는 포함으로 보강하고, 빠르고 정확하게 검색할 수 있도록 저장합니다.
AI 애플리케이션에서 데이터 수집이 중요한 이유
직원이 회사의 방대한 문서 컬렉션에서 정보를 찾을 수 있도록 RAG 기반 챗봇을 빌드하고 있다고 상상해 보세요. 이러한 문서에는 PDF, Word 파일, PowerPoint 프레젠테이션 및 여러 시스템에 분산된 웹 페이지가 포함될 수 있습니다.
챗봇은 정확하고 상황에 맞는 답변을 제공하기 위해 수천 개의 문서를 이해하고 검색해야 합니다. 그러나 원시 문서는 AI 시스템에 적합하지 않습니다. 의미를 유지하면서 검색 및 복구할 수 있는 형식으로 변환해야 합니다.
데이터 수집이 중요한 위치입니다. 다양한 파일 형식에서 텍스트를 추출하고, 큰 문서를 AI 모델 제한에 맞는 더 작은 청크로 분할하고, 메타데이터로 콘텐츠를 보강하고, 의미 체계 검색을 위한 포함을 생성하고, 모든 것을 빠르게 검색할 수 있는 방식으로 저장해야 합니다. 각 단계에서는 원래의 의미와 컨텍스트를 유지하는 방법을 신중하게 고려해야 합니다.
Microsoft.Extensions.DataIngestion 라이브러리
Microsoft.Extensions.DataIngestion 패키지는📦 데이터 수집을 위한 기본 .NET 구성 요소를 제공합니다. 이를 통해 개발자는 AI 및 기계 학습 워크플로, 특히 RAG(Retrieval-Augmented Generation) 시나리오에 대한 문서를 읽고, 처리하고, 준비할 수 있습니다.
이러한 구성 요소를 사용하면 애플리케이션 요구 사항에 맞게 조정된 강력하고 유연하며 지능적인 데이터 수집 파이프라인을 만들 수 있습니다.
- 통합 문서 표현: 대용량 언어 모델에서 잘 작동하는 일관된 형식으로 파일 형식(예: PDF, 이미지 또는 Microsoft Word)을 나타냅니다.
- 유연한 데이터 수집: 여러 기본 제공 판독기를 사용하여 클라우드 서비스와 로컬 원본 모두에서 문서를 읽어 어디서나 데이터를 쉽게 가져올 수 있습니다.
- 기본 제공 AI 향상된 기능: 요약, 감정 분석, 키워드 추출 및 분류를 사용하여 자동으로 콘텐츠를 보강하여 지능형 워크플로를 위해 데이터를 준비합니다.
- 사용자 지정 가능한 청크 전략: 검색 및 분석 요구 사항에 맞게 최적화할 수 있도록 토큰 기반, 섹션 기반 또는 의미 체계 인식 방법을 사용하여 문서를 청크로 분할합니다.
- 프로덕션 준비 스토리지: 처리된 청크를 인기 있는 벡터 데이터베이스 및 문서 저장소에 저장하고, 포함 생성을 지원하여 파이프라인을 실제 시나리오에 대비할 수 있도록 합니다.
- 엔드 투 엔드 파이프라인 구성: API를 사용하여 리더, 프로세서, 청커 및 라이터를 연결해 상용구를 줄이고 전체 워크플로를 쉽게 빌드, 커스터마이즈 및 확장할 수 있습니다.
- 성능 및 확장성: 확장 가능한 데이터 처리를 위해 설계된 이러한 구성 요소는 대량의 데이터를 효율적으로 처리할 수 있으므로 엔터프라이즈급 애플리케이션에 적합합니다.
이러한 모든 구성 요소는 기본적으로 열려 있으며 확장할 수 있습니다. 사용자 지정 논리 및 새 커넥터를 추가하고 새로운 AI 시나리오를 지원하도록 시스템을 확장할 수 있습니다. .NET 개발자는 문서가 표현, 처리 및 저장되는 방식을 표준화하여 모든 프로젝트에 대해 "휠을 재창조"하지 않고도 안정적이고 확장 가능하며 유지 관리 가능한 데이터 파이프라인을 빌드할 수 있습니다.
안정적인 기초를 기반으로 구축
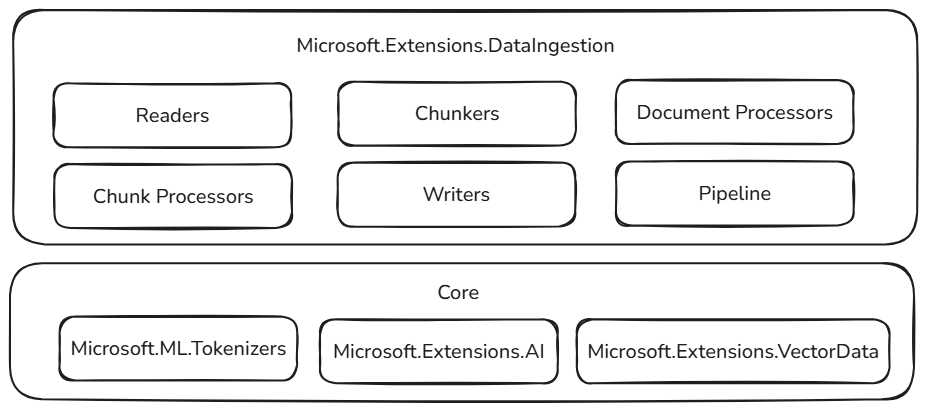
이러한 데이터 수집 구성 요소는 .NET 에코시스템에서 입증되고 확장 가능한 구성 요소를 기반으로 구축되어 안정성, 상호 운용성 및 기존 AI 워크플로와의 원활한 통합을 보장합니다.
- Microsoft.ML.Tokenizers: Tokenizer는 토큰을 기반으로 문서를 청크하기 위한 기초를 제공합니다. 이렇게 하면 콘텐츠를 정확하게 분할할 수 있으며, 이는 대규모 언어 모델에 대한 데이터를 준비하고 검색 전략을 최적화하는 데 필수적입니다.
- Microsoft.Extensions.AI: 이 라이브러리 집합은 큰 언어 모델을 사용하여 보강 변환을 지원합니다. 요약, 감정 분석, 키워드 추출 및 포함 생성과 같은 기능을 사용하면 지능형 인사이트를 사용하여 데이터를 쉽게 향상시킬 수 있습니다.
- Microsoft.Extensions.VectorData: 이 라이브러리 집합은 Qdrant, Azure SQL, CosmosDB, MongoDB, ElasticSearch 등을 비롯한 다양한 벡터 저장소에 처리된 청크를 저장하기 위한 일관된 인터페이스를 제공합니다. 이렇게 하면 데이터 파이프라인이 프로덕션에 사용할 준비가 되어 있고 여러 스토리지 백 엔드에서 확장할 수 있습니다.
친숙한 패턴 및 도구 외에도 이러한 추상화는 이미 확장 가능한 구성 요소를 기반으로 합니다. 플러그 인 기능과 상호 운용성이 가장 중요하므로 나머지 .NET AI 에코시스템이 증가함에 따라 데이터 수집 구성 요소의 기능도 증가합니다. 이 접근 방식을 통해 개발자는 새로운 커넥터, 보강 및 스토리지 옵션을 쉽게 통합하여 파이프라인을 미래 대비하고 진화하는 AI 시나리오에 적응할 수 있도록 할 수 있습니다.
데이터 수집 구성 요소
Microsoft.Extensions.DataIngestion 라이브러리는 전체 데이터 처리 파이프라인을 만들기 위해 함께 작동하는 여러 주요 구성 요소를 중심으로 빌드됩니다. 이 섹션에서는 각 구성 요소와 구성 요소의 맞춤 방법을 살펴봅니다.
문서 및 문서 리더기
라이브러리의 기초에는 IngestionDocument 중요한 정보를 잃지 않고 파일 형식을 나타내는 통합된 방법을 제공하는 형식이 있습니다.
IngestionDocument 은 Markdown 중심이므로 큰 언어 모델은 Markdown 서식 지정에 가장 적합합니다.
추상화는 IngestionDocumentReader 로컬 파일 또는 스트림에 관계없이 다양한 원본에서 문서 로드를 처리합니다. 몇 가지 판독기를 사용할 수 있습니다.
향후 더 많은 판독기( LlamaParse 및 Azure Document Intelligence 포함)가 추가될 예정입니다.
이 디자인은 동일한 일관된 API를 사용하여 여러 원본의 문서로 작업할 수 있으므로 코드를 보다 유지 관리하기 능동적이고 유연하게 만들 수 있습니다.
문서 처리
문서 프로세서는 문서 수준에서 변환을 적용하여 콘텐츠를 향상시키고 준비합니다. 라이브러리는 큰 언어 모델을 사용하여 문서 내 이미지에 대한 설명이 포함된 대체 텍스트를 생성하는 기본 제공 프로세서로 클래스를 제공합니다 ImageAlternativeTextEnricher .
청크와 청킹 전략
문서를 로드한 후에는 일반적으로 청크라고 불리는 작은 조각으로 나누어야 합니다. 청크는 AI 시스템에서 효율적으로 처리, 저장 및 검색할 수 있는 문서의 하위 섹션을 나타냅니다. 이 청크 분할 프로세스는 가장 관련성이 큰 정보를 신속하게 찾아야 하는 검색 보강된 생성 시나리오에 필수적입니다.
라이브러리는 다양한 사용 사례에 맞게 몇 가지 청크 전략을 제공합니다.
- 헤더 기반 청크로 헤더를 기준으로 분할합니다.
- 코드 섹션 기반 청크는 섹션(예: 페이지)을 기준으로 분할합니다.
- 완전한 생각을 보존하기 위한 의미론적 청크화입니다.
이러한 청크 전략은 Microsoft.ML.Tokenizers 라이브러리를 기반으로 하여 텍스트를 큰 언어 모델에서 잘 작동하는 적절한 크기의 조각으로 지능적으로 분할합니다. 올바른 청크 분할 전략은 문서 유형 및 정보를 검색하는 방법에 따라 달라집니다.
Tokenizer tokenizer = TiktokenTokenizer.CreateForModel("gpt-4");
IngestionChunkerOptions options = new(tokenizer)
{
MaxTokensPerChunk = 2000,
OverlapTokens = 0
};
IngestionChunker<string> chunker = new HeaderChunker(options);
청크 처리 및 강화
문서가 청크로 분할된 후 프로세서를 적용하여 콘텐츠를 향상시키고 보강할 수 있습니다. 청크 프로세서는 개별 조각에서 작동하며 다음을 수행할 수 있습니다.
- 자동 요약(), 감정 분석() 및 키워드 추출(
SummaryEnricherSentimentEnricher)을 포함한KeywordEnricher - 미리 정의된 범주()를 기반으로 하는 자동화된 콘텐츠 분류에 대한
ClassificationEnricher입니다.
이러한 프로세서는 Microsoft.Extensions.AI.Abstractions 를 사용하여 지능형 콘텐츠 변환을 위해 큰 언어 모델을 활용하여 청크를 다운스트림 AI 애플리케이션에 더 유용하게 만듭니다.
문서 작성기 및 스토리지
IngestionChunkWriter<T> 는 나중에 검색할 수 있는 처리된 청크를 데이터 저장소에 저장합니다. 라이브러리는 Microsoft.Extensions.AI 및 Microsoft.Extensions.VectorData.Abstractions를 사용하여 Microsoft.Extensions.VectorData에서 지원하는 모든 벡터 저장소에 청크 저장을 지원하는 클래스를 제공합니다 VectorStoreWriter<T> .
벡터 저장소에는 Qdrant, SQL Server, CosmosDB, MongoDB, ElasticSearch 등의 인기 있는 옵션이 포함됩니다. 또한 작성기는 Microsoft.Extensions.AI 사용하여 청크에 대한 포함을 자동으로 생성하여 의미 체계 검색 및 검색 시나리오에 대비할 수 있습니다.
OpenAIClient openAIClient = new(
new ApiKeyCredential(Environment.GetEnvironmentVariable("GITHUB_TOKEN")!),
new OpenAIClientOptions { Endpoint = new Uri("https://models.github.ai/inference") });
IEmbeddingGenerator<string, Embedding<float>> embeddingGenerator =
openAIClient.GetEmbeddingClient("text-embedding-3-small").AsIEmbeddingGenerator();
using SqliteVectorStore vectorStore = new(
"Data Source=vectors.db;Pooling=false",
new()
{
EmbeddingGenerator = embeddingGenerator
});
// The writer requires the embedding dimension count to be specified.
// For OpenAI's `text-embedding-3-small`, the dimension count is 1536.
using VectorStoreWriter<string> writer = new(vectorStore, dimensionCount: 1536);
문서 처리 파이프라인
IngestionPipeline<T> API를 사용하면 다양한 데이터 수집 구성 요소를 전체 워크플로에 연결할 수 있습니다. 다음을 결합할 수 있습니다.
- 리더를 사용하여 다양한 소스에서 문서를 로드합니다.
- 문서 콘텐츠를 변환하고 보강하는 프로세서입니다.
- 문서를 관리 가능한 조각으로 분할하는 도구인 청커입니다.
- 선택한 데이터 저장소에 최종 결과를 저장할 기록기입니다.
이 파이프라인 접근 방식은 상용구 코드를 줄이고 복잡한 데이터 수집 워크플로를 쉽게 빌드, 테스트 및 유지 관리할 수 있도록 합니다.
using IngestionPipeline<string> pipeline = new(reader, chunker, writer, loggerFactory: loggerFactory)
{
DocumentProcessors = { imageAlternativeTextEnricher },
ChunkProcessors = { summaryEnricher }
};
await foreach (var result in pipeline.ProcessAsync(new DirectoryInfo("."), searchPattern: "*.md"))
{
Console.WriteLine($"Completed processing '{result.DocumentId}'. Succeeded: '{result.Succeeded}'.");
}
단일 문서 처리 실패가 전반적인 파이프라인이 실패하지 않아야 합니다. 따라서 IngestionPipeline<T>.ProcessAsync를 반환하여 IAsyncEnumerable<IngestionResult> 부분적인 성공을 구현합니다. 호출자는 실패한 문서를 다시 시도하거나 첫 번째 오류를 중지하여 오류를 처리할 책임이 있습니다.
GitHub에서 Microsoft와 공동 작업
이 콘텐츠의 원본은 GitHub에서 찾을 수 있으며, 여기서 문제와 끌어오기 요청을 만들고 검토할 수도 있습니다. 자세한 내용은 참여자 가이드를 참조하세요.
.NET