팁
이 콘텐츠는 eBook, Architect Modern Web Applications with ASP.NET Core 및 Azure에서 발췌한 것이며, .NET 문서에서 제공되거나 오프라인에서도 읽을 수 있는 PDF(무료 다운로드 가능)로 제공됩니다.

"데이터는 귀중한 자산이며 시스템 자체보다 더 오래 지속됩니다."
팀 Berners-Lee
데이터 액세스는 거의 모든 소프트웨어 애플리케이션에서 중요한 부분입니다. ASP.NET Core는 Entity Framework Core(및 Entity Framework 6)를 비롯한 다양한 데이터 액세스 옵션을 지원하며, 모든 .NET 데이터 액세스 프레임워크에서 작동할 수 있습니다. 어떤 데이터 액세스 프레임워크를 선택할 것인지는 애플리케이션 요구 사항에 따라 다릅니다. ApplicationCore 및 UI 프로젝트에서 이러한 옵션을 추상화하고, 인프라에서 구현 세부 사항을 캡슐화하면 느슨하게 결합된 테스트 가능 소프트웨어를 만드는 데 도움이 됩니다.
Entity Framework Core(관계형 데이터베이스용)
관계형 데이터와 함께 작동해야 하는 새 ASP.NET Core 애플리케이션을 작성하는 경우 애플리케이션이 Entity Framework Core(EF Core)를 통해 데이터에 액세스하는 것이 좋습니다. EF Core는 .NET 개발자가 데이터 원본에서 개체를 유지할 수 있게 해주는 개체 관계형 매퍼(O/RM)입니다. EF Core를 사용하면 개발자들이 일반적으로 작성해야 하는 데이터 액세스 코드가 대부분 필요하지 않게 됩니다. ASP.NET Core와 마찬가지로, EF Core는 모듈식 플랫폼 간 애플리케이션을 지원하도록 처음부터 다시 작성되었습니다. 애플리케이션에 NuGet 패키지로 추가하고, 앱 시작 과정에서 구성하고, 필요할 때마다 종속성 주입을 통해 요청할 수 있습니다.
EF Core를 SQL Server 데이터베이스와 함께 사용하려면 다음 dotnet CLI 명령을 실행합니다.
dotnet add package Microsoft.EntityFrameworkCore.SqlServer
테스트를 목적으로 InMemory 데이터 원본에 대한 지원을 추가하려면:
dotnet add package Microsoft.EntityFrameworkCore.InMemory
DbContext
EF Core를 사용하려면 DbContext의 서브클래스가 필요합니다. 이 클래스는 애플리케이션에서 작업할 엔터티 컬렉션을 나타내는 속성을 보유합니다. eShopOnWeb 샘플에는 항목, 브랜드 및 형식에 대한 컬렉션을 사용하는 CatalogContext가 포함되어 있습니다.
public class CatalogContext : DbContext
{
public CatalogContext(DbContextOptions<CatalogContext> options) : base(options)
{
}
public DbSet<CatalogItem> CatalogItems { get; set; }
public DbSet<CatalogBrand> CatalogBrands { get; set; }
public DbSet<CatalogType> CatalogTypes { get; set; }
}
DbContext에는 DbContextOptions를 수락하는 생성자가 하나 있어야 하며, 이 인수를 base DbContext 생성자에 전달해야 합니다. 애플리케이션에 DbContext가 하나만 있는 경우 DbContextOptions 인스턴스를 전달할 수 있지만, 둘 이상 있는 경우에는 제네릭 DbContextOptions<T> 형식을 사용하여 DbContext 형식을 제네릭 매개 변수로 전달해야 합니다.
EF Core 구성
ASP.NET Core 애플리케이션에서는 일반적으로 애플리케이션의 다른 종속성을 사용하여 Program.cs에서 EF Core를 구성합니다. EF Core는 여러 유용한 확장 메서드를 지원하는 DbContextOptionsBuilder를 사용하여 구성을 간소화합니다. 구성에 연결 문자열이 정의된 SQL Server 데이터베이스를 사용하도록 CatalogContext를 구성하려면 다음 코드를 추가합니다.
builder.Services.AddDbContext<CatalogContext>(
options => options.UseSqlServer(
builder.Configuration.GetConnectionString("DefaultConnection")));
메모리 내 데이터베이스를 사용하려면:
builder.Services.AddDbContext<CatalogContext>(options =>
options.UseInMemoryDatabase());
EF Core를 설치하고, DbContext 자식 형식을 만들고, 해당 형식을 애플리케이션 서비스에 추가하고 나면 EF Core를 사용할 준비가 된 것입니다. DbContext 형식의 인스턴스를 필요로 하는 모든 서비스에서 이 인스턴스를 요청할 수 있으며, 마치 컬렉션에 있는 것처럼 LINQ를 사용하여 지속형 엔터티 작업을 시작할 수 있습니다. EF Core는 LINQ 식을 SQL 쿼리로 변환하여 데이터를 저장하고 검색하는 작업을 수행합니다.
그림 8-1처럼 로거를 구성하고 그 수준을 정보 이상으로 설정하면 EF Core가 실행하는 쿼리를 볼 수 있습니다.
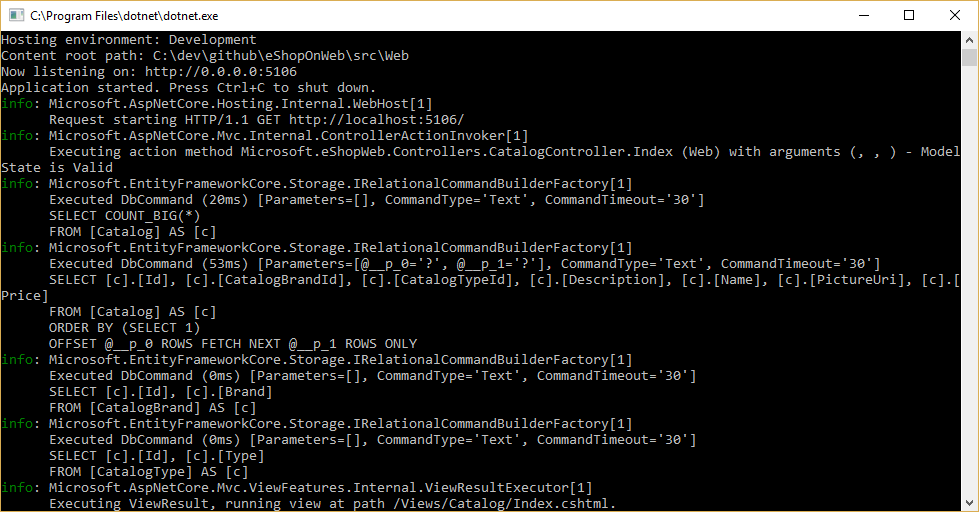
그림 8-1. EF Core 쿼리를 콘솔에 로깅
데이터 가져오기 및 저장
EF Core에서 데이터를 검색하려면 적절한 속성에 액세스한 후 LINQ를 사용하여 결과를 필터링합니다. LINQ를 사용하여 프로젝션을 수행하고, 그 결과를 한 형식에서 다른 형식으로 변환할 수도 있습니다. 다음 예제는 이름순으로 정렬되고, Enabled 속성을 기준으로 필터링되며, SelectListItem 형식에 투영되는 CatalogBrands를 검색합니다.
var brandItems = await _context.CatalogBrands
.Where(b => b.Enabled)
.OrderBy(b => b.Name)
.Select(b => new SelectListItem {
Value = b.Id, Text = b.Name })
.ToListAsync();
위의 예제에서 쿼리가 즉시 실행되도록 ToListAsync에 대한 호출을 추가하는 것이 중요합니다. 그렇지 않으면 명령문에서 IQueryable<SelectListItem>을 brandItems에 할당하므로 열거될 때까지 실행되지 않습니다. 메서드에서 IQueryable 결과를 반환하는 데 따른 장단점이 있습니다. 쿼리 EF Core가 추가 수정이 가능하도록 작성되지만, 쿼리에 EF Core가 변환할 수 없는 연산이 추가되면 런타임에만 발생하는 오류가 발생할 수 있습니다. 일반적으로 데이터 액세스를 수행하는 메서드에 필터를 전달하고 메모리 내 컬렉션(예: List<T>)을 반환하는 것이 안전합니다.
EF Core는 지속성 저장소에서 가져오는 엔터티의 변경 내용을 추적합니다. 추적된 엔터티의 변경 내용을 저장하려면 엔터티를 가져올 때 사용한 것과 동일한 DbContext 인스턴스가 되도록 DbContext에서 SaveChangesAsync 메서드를 호출하면 됩니다. 엔터티 추가 및 제거는 적절한 DbSet 속성에서 직접 수행하며, 마찬가지로 SaveChangesAsync를 호출하여 데이터베이스 명령을 실행합니다. 다음 예제에서는 지속성 저장소에서 엔터티를 추가, 업데이트 및 제거하는 방법을 보여줍니다.
// create
var newBrand = new CatalogBrand() { Brand = "Acme" };
_context.Add(newBrand);
await _context.SaveChangesAsync();
// read and update
var existingBrand = _context.CatalogBrands.Find(1);
existingBrand.Brand = "Updated Brand";
await _context.SaveChangesAsync();
// read and delete (alternate Find syntax)
var brandToDelete = _context.Find<CatalogBrand>(2);
_context.CatalogBrands.Remove(brandToDelete);
await _context.SaveChangesAsync();
EF Core는 엔터티를 가져오고 저장하기 위한 동기 및 비동기 메서드를 모두 지원합니다. 웹 애플리케이션에서는 데이터 액세스 작업이 끝나기를 기다리는 동안 웹 서버 스레드가 차단되지 않도록 비동기 메서드에 async/await 패턴을 사용하는 것이 좋습니다.
자세한 내용은 버퍼링 및 스트리밍을 참조하세요.
관련 데이터 가져오기
EF Core는 엔터티를 검색할 때 엔터티와 함께 데이터베이스에 직접 저장되는 모든 속성을 채웁니다. 관련 엔터티 목록 같은 탐색 속성은 채워지지 않으며 값이 Null로 설정될 수 있습니다. 이 프로세스는 EF Core가 데이터를 필요 이상으로 가져오지 않게 하므로, 요청을 신속하게 처리하고 효율적인 방식으로 응답을 반환해야 하는 웹 애플리케이션에서 매우 중요합니다. 즉시 로드를 사용하여 엔터티와의 관계를 포함하려면 다음과 같이 쿼리에서 Include 확장 메서드를 사용하여 속성을 지정합니다.
// .Include requires using Microsoft.EntityFrameworkCore
var brandsWithItems = await _context.CatalogBrands
.Include(b => b.Items)
.ToListAsync();
여러 관계를 포함할 수 있으며, ThenInclude를 사용하여 하위 관계를 포함할 수도 있습니다. EF Core는 엔터티의 결과 집합을 검색하는 단일 쿼리를 실행합니다. 또는 다음과 같이 마침표('.')로 구분된 문자열을 .Include() 확장 메서드에 전달하여 탐색 속성을 포함할 수 있습니다.
.Include("Items.Products")
사양은 필터링 논리를 캡슐화할 뿐 아니라 채울 속성을 포함하여 반환될 데이터의 모양을 지정할 수 있습니다. eShopOnWeb 샘플에는 사양 내에서 즉시 로드 정보를 캡슐화하는 방법을 보여주는 몇 가지 사양이 포함됩니다. 여기에서 사양을 쿼리의 일부로 사용하는 방법을 확인할 수 있습니다.
// Includes all expression-based includes
query = specification.Includes.Aggregate(query,
(current, include) => current.Include(include));
// Include any string-based include statements
query = specification.IncludeStrings.Aggregate(query,
(current, include) => current.Include(include));
관련 데이터를 로드하는 또 다른 옵션은 명시적 로드를 사용하는 것입니다. 명시적 로드를 사용하면 이미 검색된 엔터티에 추가 데이터를 로드할 수 있습니다. 이 방법은 데이터베이스에 대한 별도의 요청이 개입되므로 요청당 데이터베이스 왕복 횟수를 최소화해야 하는 웹 애플리케이션에는 사용하지 않는 것이 좋습니다.
지연 로드는 애플리케이션에서 참조하는 관련 데이터를 자동으로 로드하는 기능입니다. EF Core는 버전 2.1에서 지연 로드에 대한 지원이 추가되었습니다. 지연 로드는 기본적으로 사용하지 않도록 설정되어 있으며 Microsoft.EntityFrameworkCore.Proxies를 설치해야 합니다. 명시적 로드와 마찬가지로 지연 로드는 각 웹 요청 내에서 수행되는 추가 데이터베이스 쿼리에서 사용되기 때문에 일반적으로 웹 애플리케이션에 대해 사용하지 않도록 설정되어 있습니다. 아쉽게도 지연 로드에서 발생하는 오버헤드는 대기 시간이 짧고 테스트에 사용되는 데이터 세트가 작은 경우 개발 시기에 종종 간과됩니다. 단, 더 많은 사용자, 더 많은 데이터 및 더 긴 대기 시간의 프로덕션에서는 추가 데이터베이스 요청으로 인해 웹 애플리케이션의 성능이 저하되어 지연 로드를 과도하게 사용하게 됩니다.
실제 데이터베이스 쿼리를 검사하면서 애플리케이션을 테스트하는 것이 좋습니다. 특정 상황에서 EF Core는 애플리케이션에 최적인 것보다 더 많은 쿼리를 생성하거나 더 많은 비용이 드는 쿼리를 생성할 수 있습니다. 이러한 문제 중 하나는 카티시안 폭발로 알려져 있습니다. EF Core 팀은 런타임 동작을 조정하는 여러 방법 중 하나로 AsSplitQuery 메서드를 제공합니다.
데이터 캡슐화
EF Core는 모델이 적절하게 상태를 캡슐화할 수 있도록 여러 기능을 지원합니다. 도메인 모델의 일반적인 문제는 컬렉션 탐색 속성을 공개적으로 액세스 가능한 목록 형식으로 노출한다는 점입니다. 이 문제로 인해 협력자가 이 컬렉션 형식의 콘텐츠를 조작하여 컬렉션과 관련한 중요한 비즈니스 규칙을 무시할 수 있고 이에 따라 개체가 잘못된 상태가 될 수 있습니다. 이 문제의 해결 방법은 이 예제와 같이 관련 컬렉션에 대해 읽기 전용 액세스만을 노출하고 명시적으로 클라이언트가 이를 조작할 수 있는 방법을 정의하는 메서드를 제공하는 것입니다.
public class Basket : BaseEntity
{
public string BuyerId { get; set; }
private readonly List<BasketItem> _items = new List<BasketItem>();
public IReadOnlyCollection<BasketItem> Items => _items.AsReadOnly();
public void AddItem(int catalogItemId, decimal unitPrice, int quantity = 1)
{
var existingItem = Items.FirstOrDefault(i => i.CatalogItemId == catalogItemId);
if (existingItem == null)
{
_items.Add(new BasketItem()
{
CatalogItemId = catalogItemId,
Quantity = quantity,
UnitPrice = unitPrice
});
}
else existingItem.Quantity += quantity;
}
}
이 엔터티 형식은 퍼블릭 List 또는 ICollection 속성을 공개하지 않지만 대신 기본 목록 형식을 래핑하는 IReadOnlyCollection 형식을 공개합니다. 이 패턴을 사용하면 다음과 같이 지원 필드를 사용하도록 Entity Framework Core를 지정할 수 있습니다.
private void ConfigureBasket(EntityTypeBuilder<Basket> builder)
{
var navigation = builder.Metadata.FindNavigation(nameof(Basket.Items));
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
}
도메인 모델을 개선하는 다른 방법은 ID가 없고 속성으로만 구별되는 형식의 값 개체를 사용하는 것입니다. 이러한 형식을 엔터티 속성으로 사용하면 논리가 속한 값 개체에 특정되도록 유지할 수 있고, 동일한 개념을 사용하는 여러 엔터티 간에 중복 논리를 방지할 수 있습니다. Entity Framework Core에서는 다음과 같이 형식을 소유된 엔터티로 구성하여 소유하는 엔터티와 동일한 테이블에서 값 개체를 유지할 수 있습니다.
private void ConfigureOrder(EntityTypeBuilder<Order> builder)
{
builder.OwnsOne(o => o.ShipToAddress);
}
다음 예제에서 ShipToAddress 속성은 Address 형식입니다.
Address는 Street 및 City와 같은 여러 속성을 포함한 값 개체입니다. EF Core는 Order 개체를 Address 속성당 하나의 열을 포함한 해당 테이블에 매핑하여 각 열 이름의 접두사를 속성의 이름으로 지정합니다. 이 예제에서 Order 테이블에는 ShipToAddress_Street 및 ShipToAddress_City와 같은 열이 포함됩니다. 원하는 경우 별도의 테이블에 소유된 형식을 저장할 수도 있습니다.
EF Core에서 소유 엔터티 지원에 대해 자세히 알아보세요.
복원력 있는 연결
SQL 데이터베이스 같은 외부 리소스를 사용할 수 없는 경우가 있습니다. 일시적으로 사용할 수 없는 경우 예외가 발생하지 않도록 하기 위해 애플리케이션에서 재시도 논리를 사용할 수 있습니다. 이 기술을 보통 연결 복원력이라고 부릅니다. 최대 다시 시도 횟수에 도달할 때까지 대기 시간이 기하급수적으로 증가하면서 다시 시도하는 지수 백오프를 사용하여 다시 시도 기술을 구현할 수 있습니다. 이 기술에서는 클라우드 리소스가 어떤 이유로든 짧은 기간 일시적으로 사용할 수 없게 되어 일부 요청이 실패할 수 있다는 점을 받아들입니다.
Azure SQL DB의 경우, Entity Framework Core는 이미 내부 데이터베이스 연결 복원력과 다시 시도 논리를 제공합니다. 그러나 복원력 있는 EF 코어 연결을 원할 경우 각 DbContext 연결에 대한 Entity Framework 실행 전략을 사용해야 합니다.
예를 들어, EF 코어 연결 수준의 다음 코드는 연결이 실패할 경우 다시 시도되는 복원력 있는 SQL 연결을 할 수 있습니다.
builder.Services.AddDbContext<OrderingContext>(options =>
{
options.UseSqlServer(builder.Configuration["ConnectionString"],
sqlServerOptionsAction: sqlOptions =>
{
sqlOptions.EnableRetryOnFailure(
maxRetryCount: 5,
maxRetryDelay: TimeSpan.FromSeconds(30),
errorNumbersToAdd: null);
}
);
});
BeginTransaction 및 여러 DbContexts를 사용한 실행 전략 및 명시적 트랜잭션
EF Core 연결에서 다시 시도를 사용하도록 설정되면 EF Core를 사용하여 수행하는 각 작업이 자체적으로 다시 시도할 수 있는 작업이 됩니다. 일시적인 오류가 발생할 경우 SaveChangesAsync에 대한 각 쿼리와 각 호출이 하나의 단위로 다시 시도됩니다.
그러나 코드가 BeginTransaction을 사용하여 트랜잭션을 시작한 경우, 하나의 단위로 처리해야 하는 자신만의 작업 그룹을 정의하게 됩니다. 오류가 발생하면 트랜잭션 내부의 모든 항목이 롤백되어야 합니다. EF 실행 전략(다시 시도 정책)을 사용할 때 해당 트랜잭션을 실행하려고 시도하고 여러 DbContexts의 여러 SaveChangesAsync를 포함하면 다음과 같은 예외가 표시됩니다.
System.InvalidOperationException: 구성된 실행 전략 SqlServerRetryingExecutionStrategy는 사용자가 시작한 트랜잭션을 지원하지 않습니다.
DbContext.Database.CreateExecutionStrategy()에서 반환된 실행 전략을 사용하여 다시 시도가 가능한 단위로 트랜잭션의 모든 작업을 실행합니다.
해결책은 실행해야 하는 모든 것을 나타내는 대리자를 사용하여 EF 실행 전략을 수동으로 호출하는 것입니다. 일시적인 오류가 발생하면, 실행 전략에서 대리자를 다시 호출합니다. 다음 코드는 이 방식을 구현하는 방법을 보여줍니다.
// Use of an EF Core resiliency strategy when using multiple DbContexts
// within an explicit transaction
// See:
// https://learn.microsoft.com/ef/core/miscellaneous/connection-resiliency
var strategy = _catalogContext.Database.CreateExecutionStrategy();
await strategy.ExecuteAsync(async () =>
{
// Achieving atomicity between original Catalog database operation and the
// IntegrationEventLog thanks to a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
// Save to EventLog only if product price changed
if (raiseProductPriceChangedEvent)
{
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
}
});
첫 번째 DbContext는 _catalogContext이며 두 번째 DbContext는 _integrationEventLogService 개체 내에 있습니다. 마지막으로, 커밋 작업은 EF 실행 전략을 사용하여 여러 DbContexts를 수행합니다.
참조 - Entity Framework Core
- EF Core 문서https://learn.microsoft.com/ef/
- EF Core: 관련 데이터https://learn.microsoft.com/ef/core/querying/related-data
- ASPNET 애플리케이션에서 엔터티 지연 로드 방지https://ardalis.com/avoid-lazy-loading-entities-in-asp-net-applications
EF Core 또는 마이크로 ORM
EF Core는 지속성 관리에 매우 유용하고 대부분 애플리케이션 개발자의 데이터베이스 세부 정보를 캡슐화하지만, 유일한 방법은 아닙니다. 또 다른 인기 있는 오픈 소스는 마이크로 ORM이라고도 하는 Dapper입니다. 마이크로 ORM은 개체를 데이터 구조에 매핑하는 데 사용되며 기능이 약간 적은 도구입니다. Dapper의 디자인 목표는 데이터를 검색하고 업데이트하는 데 사용되는 기본 쿼리를 완전히 캡슐화하는 것이 아니라 성능에 집중하는 것입니다. Dapper는 개발자의 SQL을 추상화하지 않으므로 "금속에 가깝고" 개발자가 특정 데이터 액세스 작업에 사용할 정확한 쿼리를 작성할 수 있습니다.
EF Core에는 Dapper과 구별되지만 성능 오버헤드를 제공하는 두 가지 중요한 기능이 있습니다. 첫 번째는 LINQ 식에서 SQL로의 변환입니다. 이러한 변환은 캐시되지만, 그럼에도 불구하고 처음으로 수행할 때 오버헤드가 있습니다. 두 번째는 엔터티 변경 내용 추적(효율적인 update 문을 생성할 수 있도록)입니다. 특정 쿼리의 경우 AsNoTracking 확장명을 사용하여 이 동작을 해제할 수 있습니다. 또한 EF 코어는 일반적으로 매우 효율적이고 어떤 경우에도 성능의 관점에서 완벽하게 허용되는 SQL 쿼리를 생성하지만, 실행할 정확한 쿼리를 세부적으로 제어해야 하는 경우 EF Core를 사용하여 사용자 지정 SQL을 전달(또는 저장 프로시저를 실행)할 수 있습니다. 이 경우 Dapper는 여전히 EF Core보다 성능이 우수하지만 차이는 아주 미미합니다. 다양한 데이터 액세스 방법에 대한 현재 성능 벤치마크 데이터는 Dapper 사이트에서 찾을 수 있습니다.
Dapper 구문이 EF Core에서 어떻게 달라지는지 살펴보려면 항목의 목록 검색에 사용되는 다음 두 동일한 메서드 버전을 고려해 보세요.
// EF Core
private readonly CatalogContext _context;
public async Task<IEnumerable<CatalogType>> GetCatalogTypes()
{
return await _context.CatalogTypes.ToListAsync();
}
// Dapper
private readonly SqlConnection _conn;
public async Task<IEnumerable<CatalogType>> GetCatalogTypesWithDapper()
{
return await _conn.QueryAsync<CatalogType>("SELECT * FROM CatalogType");
}
Dapper를 사용하여 좀 더 복잡한 개체 그래프를 작성해야 하는 경우 관련 쿼리를 직접 작성해야 합니다(EF Core에서 Include를 추가하는 것과는 달리). 이 기능은 개별 행을 여러 매핑된 개체에 매핑할 수 있는 다중 매핑이라는 기능을 비롯한 다양한 구문을 통해 지원됩니다. 예를 들어 속성은 Owner, 형식은 User인 Post라는 클래스가 있다고 할 때, 다음 SQL은 모든 필요한 데이터를 반환합니다.
select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id
반환된 각 행에는 User 및 Post 데이터가 포함됩니다. User 데이터는 Owner 속성을 통해 Post 데이터에 연결되어야 하므로 다음 함수가 사용됩니다.
(post, user) => { post.Owner = user; return post; }
연결된 사용자 데이터로 Owner 속성이 채워진 게시물 컬렉션을 반환하는 전체 코드 목록은 다음과 같습니다.
var sql = @"select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id";
var data = connection.Query<Post, User, Post>(sql,
(post, user) => { post.Owner = user; return post;});
Dapper는 캡슐화가 덜 이루어지므로 개발자는 데이터가 저장되는 방식, 데이터를 효과적으로 쿼리하는 방법, 데이터를 가져오는 더 많은 코드를 작성하는 방법을 잘 알아야 합니다. 모델이 바뀌면 단순히 새 마이그레이션을 만들고(EF Core의 또 다른 기능) DbContext의 한 장소에 매핑 정보를 업데이트하는 대신, 영향을 받는 모든 쿼리를 업데이트해야 합니다. 이러한 쿼리는 컴파일 시간을 보장하지 않으므로 모델 또는 데이터베이스 변경에 대한 응답으로 런타임에 중단될 수 있으며, 오류를 신속하게 감지하기가 더 어려워질 수 있습니다. 이러한 단점을 대가로, Dapper는 매우 빠른 성능을 제공합니다.
EF Core는 대부분의 애플리케이션에서, 그리고 애플리케이션의 대부분에서 납득할 만한 성능을 제공합니다. 따라서 개발자 생산성 이점이 성능 오버헤드보다 클 가능성이 높습니다. 캐싱으로 이점을 얻을 수 있는 쿼리의 경우 실제 쿼리가 실행되는 시간은 극히 일부에 불과할 수 있으며, 무시해도 될 정도로 쿼리 성능 차이가 비교적 작을 수 있습니다.
SQL 또는 NoSQL
전통적으로 SQL Server 같은 관계형 데이터베이스가 영구 데이터 스토리지 시장을 지배해 왔지만, 유일한 솔루션은 아닙니다. MongoDB 같은 NoSQL 데이터베이스는 개체를 저장하는 다른 접근 방식을 제공합니다. 개체를 테이블 및 행에 매핑하는 대신, 전체 개체 그래프를 직렬화하고 결과를 저장하는 또 다른 옵션이 있습니다. 이 방법의 이점은 적어도 처음에는 간단하고 성능이 우수하다는 점입니다. 개체를 관계가 있는 여러 테이블로 분해하고 데이터베이스에서 개체가 마지막으로 검색된 이후에 변경되었을 수 있는 행을 업데이트하는 것보다 키를 사용하여 직렬화된 단일 개체를 저장하는 방법이 더 간단합니다. 마찬가지로, 관계형 데이터베이스에서 동일한 개체를 완전히 작성하는 데 필요한 복잡한 조인 또는 여러 데이터베이스 쿼리보다는 키 기반 저장소에서 단일 개체를 가져와서 역직렬화하는 방법이 훨씬 쉽고 빠릅니다. 또한 잠금이나 트랜잭션 또는 고정된 스키마가 없으면 여러 머신에서 NoSQL 데이터베이스를 확장할 수 있으므로 대규모 데이터 세트를 지원할 수 있습니다.
반면, NoSQL 데이터베이스는(일반적으로 그 이름처럼) 고유한 단점이 있습니다. 관계형 데이터베이스는 정규화를 사용하여 일관성을 유지하고 데이터 중복을 방지합니다. 이 방법으로 데이터베이스의 전체 크기를 줄이고 즉시 전체 데이터베이스에서 공유 데이터 업데이트를 사용할 수 있습니다. 관계형 데이터베이스에서 주소 테이블은 ID별로 국가 테이블을 참조할 수 있으며, 이를 통해 국가/지역의 이름이 변경되면 주소 레코드 자체를 업데이트할 필요 없이 업데이트의 이점을 누릴 수 있습니다. 그러나 NoSQL 데이터베이스에는 주소 및 주소와 연결된 국가는 여러 저장된 개체의 일부로 직렬화될 수 있습니다. 국가/지역 이름을 업데이트하려면 단일 행이 아닌 모든 개체를 업데이트해야 합니다. 관계형 데이터베이스는 외래 키 같은 규칙을 적용하여 관계 무결성을 보장할 수도 있습니다. 일반적으로 NoSQL 데이터베이스는 데이터에 대한 이러한 제약 조건을 제공하지 않습니다.
처리해야 하는 또 다른 복잡성 NoSQL 데이터베이스는 버전 관리입니다. 개체의 속성이 변경되면 저장된 이전 버전에서 개체를 역직렬화할 수 없을 수도 있습니다. 따라서 직렬화된(이전) 개체 버전을 갖고 있는 모든 기존 개체를 새 스키마에 맞게 업데이트해야 합니다. 이 방법은 스키마 변경 시 가끔 업데이트 스크립트나 매핑 업데이트가 필요한 관계형 데이터베이스와 개념적 차이는 없습니다. 그러나 NoSQL 방식에서는 데이터 중복 때문에 수정해야 하는 항목 수가 훨씬 많은 경우가 종종 있습니다.
NoSQL 데이터베이스에서는 개체의 여러 버전을 저장할 수 있으며, 무언가 고정된 스키마 관계형 데이터베이스는 일반적으로 지원하지 않습니다. 그러나 이 경우 애플리케이션 코드에서 개체의 이전 버전이 존재하여 복잡성이 추가되는지 고려해야 합니다.
NoSQL 데이터베이스는 일반적으로 ACID를 적용하지 않습니다. 즉, 관계형 데이터베이스보다 성능과 확장성이 더 좋습니다. 정규화된 테이블 구조의 스토리지에 적합하지 않은 매우 큰 데이터 세트 및 개체에 적합합니다. 각 데이터베이스를 적합하게 사용한다면 단일 애플리케이션으로 관계형 데이터베이스와 NoSQL 데이터베이스의 장점을 모두 취하지 못할 이유가 없습니다.
Azure Cosmos DB (애저 코스모스 DB)
Azure Cosmos DB는 완전히 관리되는 NoSQL 데이터베이스 서비스로 스키마 없는 클라우드 기반 데이터 스토리지를 제공합니다. Azure Cosmos DB는 신속하고 예측 가능한 성능, 고가용성, 탄력적인 크기 조정, 글로벌 배포를 위해 설계되었습니다. NoSQL 데이터베이스임에도 불구하고, 개발자가 풍부하고 친숙한 SQL 쿼리 기능을 JSON 데이터에 사용할 수 있습니다. Azure Cosmos DB의 모든 리소스는 JSON 문서로 저장됩니다. 리소스는 메타데이터를 포함하고 있는 항목 및 항목 컬렉션인 피드로 관리됩니다. 그림 8-2는 여러 Azure Cosmos DB 리소스 간의 관계를 보여줍니다.
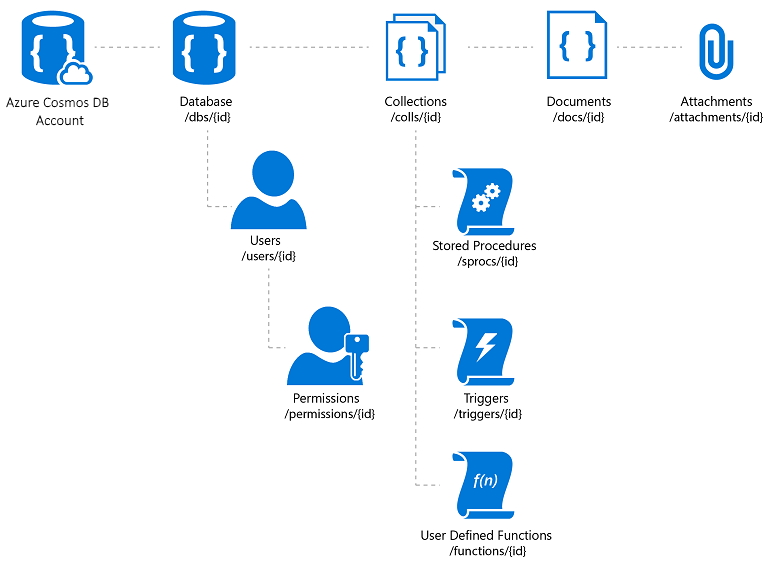
그림 8-2. Azure Cosmos DB 리소스 조직입니다.
Azure Cosmos DB 쿼리 언어는 JSON 문서를 쿼리하는 단순하지만 강력한 인터페이스입니다. 이 언어는 ANSI SQL 문법의 하위 집합을 지원하고 JavaScript 개체, 배열, 개체 생성 및 함수 호출을 긴밀하게 통합합니다.
참조 – Azure Cosmos DB
- Azure Cosmos DB 소개 https://learn.microsoft.com/azure/cosmos-db/introduction
다른 지속성 옵션
관계형 스토리지 및 NoSQL 스토리지 옵션 외에 ASP.NET Core 애플리케이션은 Azure Storage를 사용하여 다양한 데이터 형식과 파일을 클라우드 기반의 스케일링 가능한 방식으로 저장할 수 있습니다. Azure Storage는 대규모로 확장할 수 있으므로 처음에는 적은 양의 데이터를 저장하는 것으로 시작하고, 이후에 애플리케이션에 필요하면 수백 테라바이트를 저장하도록 강화할 수 있습니다. Azure Storage는 다음과 같은 네 가지 데이터를 지원합니다.
구조화되지 않은 텍스트 또는 이진 스토리지를 위한 Blob Storage로 개체 스토리지라고도 합니다.
행 키를 통해 액세스할 수 있는 구조화된 데이터 세트를 위한 Table Storage.
신뢰할 수 있는 큐 기반 메시지를 위한 Queue Storage.
Azure 가상 머신과 온-프레미스 애플리케이션 간의 공유 파일 액세스를 위한 File Storage.
참조 – Azure Storage
캐싱
웹 애플리케이션에서 각 웹 요청을 최대한 짧은 시간 내에 완료해야 합니다. 이 기능을 얻는 한 가지 방법은 서버가 요청을 완료하기 위해 만들어야 하는 외부 호출의 수를 제한하는 것입니다. 캐싱에는 서버(또는 데이터 원본보다 쉽게 쿼리할 수 있는 또 다른 데이터 저장소)에 데이터 복사본을 저장하는 작업이 포함됩니다. 웹 애플리케이션, 특히 SPA가 아닌 기존 웹 애플리케이션은 모든 요청에서 전체 사용자 인터페이스를 빌드해야 합니다. 이 방법에서는 사용자 요청 간에 많은 수의 같은 데이터베이스 쿼리를 반복해야 하는 경우가 자주 있습니다. 대부분의 경우 이 데이터가 변경되는 일은 거의 없으므로 데이터베이스에서 이 데이터를 지속적으로 요청할 이유가 없습니다. ASP.NET Core는 전체 페이지를 캐싱하기 위한 응답 캐싱, 그리고 보다 세부적인 캐싱 동작을 지원하는 데이터 캐싱을 지원합니다.
캐싱을 구현할 때 문제 격리를 염두에 두어야 합니다. 데이터 액세스 논리 또는 사용자 인터페이스에 캐싱 논리를 구현하지 마세요. 그 대신, 캐싱을 자체 클래스에서 캡슐화하고 구성을 사용하여 해당 동작을 관리하세요. 이 방법을 통해 개방/폐쇄 및 단일 책임 원칙을 준수하며, 애플리케이션의 성장에 따라 애플리케이션에서 캐싱을 사용하는 방법을 좀 더 간편하게 관리할 수 있습니다.
ASP.NET Core 응답 캐싱
ASP.NET Core는 두 가지 수준의 응답 캐시를 지원합니다. 첫 번째 수준은 서버의 어떤 항목도 캐시하지 않지만, 클라이언트와 프록시 서버에 응답을 캐시하라고 지시하는 HTTP 헤더를 추가합니다. 이 기능은 개별 컨트롤러 또는 작업에 ResponseCache 특성을 추가하여 구현됩니다.
[ResponseCache(Duration = 60)]
public IActionResult Contact()
{
ViewData["Message"] = "Your contact page.";
return View();
}
이전 예제에서는 응답에 다음 헤더가 추가되어 클라이언트가 최대 60초 동안 결과를 캐시하도록 지시합니다.
Cache-Control: public,max-age=60
서버측 메모리 내 캐싱을 애플리케이션에 추가하려면 Microsoft.AspNetCore.ResponseCaching NuGet 패키지를 참조한 다음, 응답 캐싱 미들웨어를 추가해야 합니다. 이 미들웨어는 앱을 시작하는 동안 서비스 및 미들웨어를 사용하여 구성됩니다.
builder.Services.AddResponseCaching();
// other code omitted, including building the app
app.UseResponseCaching();
응답 캐싱 미들웨어는 사용자 지정할 수 있는 조건 집합에 따라 자동으로 응답을 캐싱합니다. 기본적으로 GET 또는 HEAD 메서드를 통해 요청된 200(확인) 응답만 캐시됩니다. 또한 요청에는 캐시 컨트롤: 공용 헤더가 포함된 응답이 있어야 하고, 권한 부여 또는 Set-Cookie에 대한 헤더를 포함할 수 없습니다. 응답 캐싱 미들웨어에서 사용하는 캐싱 조건 전체 목록을 참조하세요.
데이터 캐싱
전체 웹 응답 캐싱 대신(또는 외에도) 개별 데이터 쿼리의 결과를 캐싱할 수 있습니다. 이 기능의 경우 웹 서버에서 메모리 내 캐싱을 사용하거나 분산된 캐시를 사용할 수 있습니다. 이 섹션에서는 메모리 내 캐싱을 구현하는 방법을 보여줍니다.
다음 코드를 사용하여 메모리(또는 분산) 캐싱에 대한 지원을 추가합니다.
builder.Services.AddMemoryCache();
builder.Services.AddMvc();
Microsoft.Extensions.Caching.Memory NuGet 패키지도 추가해야 합니다.
서비스를 추가한 후에는 캐시에 액세스해야 할 때마다 종속성 주입을 통해 IMemoryCache를 요청합니다. 이 예제에는 CachedCatalogService가 기본 ICatalogService 구현에 대한 액세스를 제어하는(또는 동작을 추가하는) CatalogService 대안 구현을 제공하여 프록시(또는 Decorator) 디자인 패턴을 사용합니다.
public class CachedCatalogService : ICatalogService
{
private readonly IMemoryCache _cache;
private readonly CatalogService _catalogService;
private static readonly string _brandsKey = "brands";
private static readonly string _typesKey = "types";
private static readonly TimeSpan _defaultCacheDuration = TimeSpan.FromSeconds(30);
public CachedCatalogService(
IMemoryCache cache,
CatalogService catalogService)
{
_cache = cache;
_catalogService = catalogService;
}
public async Task<IEnumerable<SelectListItem>> GetBrands()
{
return await _cache.GetOrCreateAsync(_brandsKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetBrands();
});
}
public async Task<Catalog> GetCatalogItems(int pageIndex, int itemsPage, int? brandID, int? typeId)
{
string cacheKey = $"items-{pageIndex}-{itemsPage}-{brandID}-{typeId}";
return await _cache.GetOrCreateAsync(cacheKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetCatalogItems(pageIndex, itemsPage, brandID, typeId);
});
}
public async Task<IEnumerable<SelectListItem>> GetTypes()
{
return await _cache.GetOrCreateAsync(_typesKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetTypes();
});
}
}
서비스의 캐시된 버전을 사용하지만 서비스가 여전히 생성자에 필요한 CatalogService 인스턴스를 가져올 수 있도록 애플리케이션을 구성하려면 Program.cs에 다음 줄을 추가합니다.
builder.Services.AddMemoryCache();
builder.Services.AddScoped<ICatalogService, CachedCatalogService>();
builder.Services.AddScoped<CatalogService>();
이 코드에서 카탈로그 데이터를 가져오는 데이터베이스 호출은 요청마다 만들어지는 것이 아니라 분당 한 번만 만들어집니다. 사이트의 트래픽에 따라, 이는 데이터베이스에 대해 이루어지는 쿼리 수, 현재 이 서비스에서 노출하는 세 쿼리에 의존하는 홈페이지의 평균 페이지 로드 시간에 큰 영향을 미칠 수 있습니다.
캐싱이 구현될 때 발생하는 문제는 부실 데이터, 즉 원본에서는 변경되었지만 캐시에는 오래된 버전이 남아 있는 데이터입니다. 이 문제를 완화하는 간단한 방법은 캐시 기간을 짧게 하는 것입니다. 사용량이 많은 애플리케이션의 경우 데이터가 캐시되는 길이를 연장해서 얻을 수 있는 이점이 제한적이기 때문입니다. 예를 들어 단일 데이터베이스 쿼리를 만들고 초당 10회 요청되는 페이지를 고려해 보세요. 이 페이지가 1분 동안 캐시되면 분당 데이터베이스 쿼리 수가 600에서 1로 99.8% 감소합니다. 그 대신 캐시 기간을 1시간으로 하면 전체 감소율이 99.997%가 되겠지만, 부실 데이터 가능성 및 잠재적 연령이 엄청나게 증가합니다.
또 다른 방법은 캐시에 포함된 데이터가 업데이트될 때 선제적으로 캐시 항목을 제거하는 것입니다. 키를 알고 있으면 개별 항목을 제거할 수 있습니다.
_cache.Remove(cacheKey);
애플리케이션이 캐시하는 항목을 업데이트하기 위한 기능을 노출하는 경우 업데이트를 수행하는 코드에서 해당 캐시 항목을 제거할 수 있습니다. 경우에 따라 특정 데이터 집합에 종속된 여러 항목이 있을 수 있습니다. 이 경우 CancellationChangeToken을 사용하여 캐시 항목 간의 종속성을 만드는 것이 유용할 수 있습니다. CancellationChangeToken을 사용하면 토큰을 취소하여 여러 캐시 항목을 한꺼번에 만료할 수 있습니다.
// configure CancellationToken and add entry to cache
var cts = new CancellationTokenSource();
_cache.Set("cts", cts);
_cache.Set(cacheKey, itemToCache, new CancellationChangeToken(cts.Token));
// elsewhere, expire the cache by cancelling the token\
_cache.Get<CancellationTokenSource>("cts").Cancel();
캐싱은 반복해서 데이터베이스에서 동일한 값을 요청하는 웹 페이지의 성능을 크게 향상시킬 수 있습니다. 캐싱을 적용하기 전에 데이터 액세스 및 페이지 성능을 측정하고, 개선이 필요한 경우에만 캐싱을 적용해야 합니다. 캐싱은 웹 서버 메모리 리소스를 사용하고 애플리케이션의 복잡성을 증가시키므로 이 기술을 조급하게 활용하지 않는 것이 중요합니다.
Blazor WebAssembly 앱으로 데이터 가져오기
Blazor 서버를 사용하는 앱을 빌드하는 경우 이 장에서 지금까지 설명한 대로 Entity Framework 및 기타 직접 데이터 액세스 기술을 사용할 수 있습니다. 그러나 다른 SPA 프레임워크처럼 BlazorWebAssembly 앱을 빌드하는 경우 다른 데이터 액세스 전략이 필요합니다. 일반적으로 해당 애플리케이션은 데이터에 액세스하고 웹 API 엔드포인트를 통해 서버와 상호 작용합니다.
수행 중인 데이터 또는 작업이 중요한 경우 이전 장에서 보안 관련 섹션을 검토하고 무단 액세스로부터 API를 보호해야 합니다.
BlazorAdmin 프로젝트의 Blazor에서 WebAssembly 앱의 예를 찾을 수 있습니다. 이 프로젝트는 eShopOnWeb 웹 프로젝트 내에 호스트되며 Administrators 그룹의 사용자가 저장소의 항목을 관리하는 데 사용할 수 있습니다. 그림 8-3에서 애플리케이션의 스크린샷을 볼 수 있습니다.
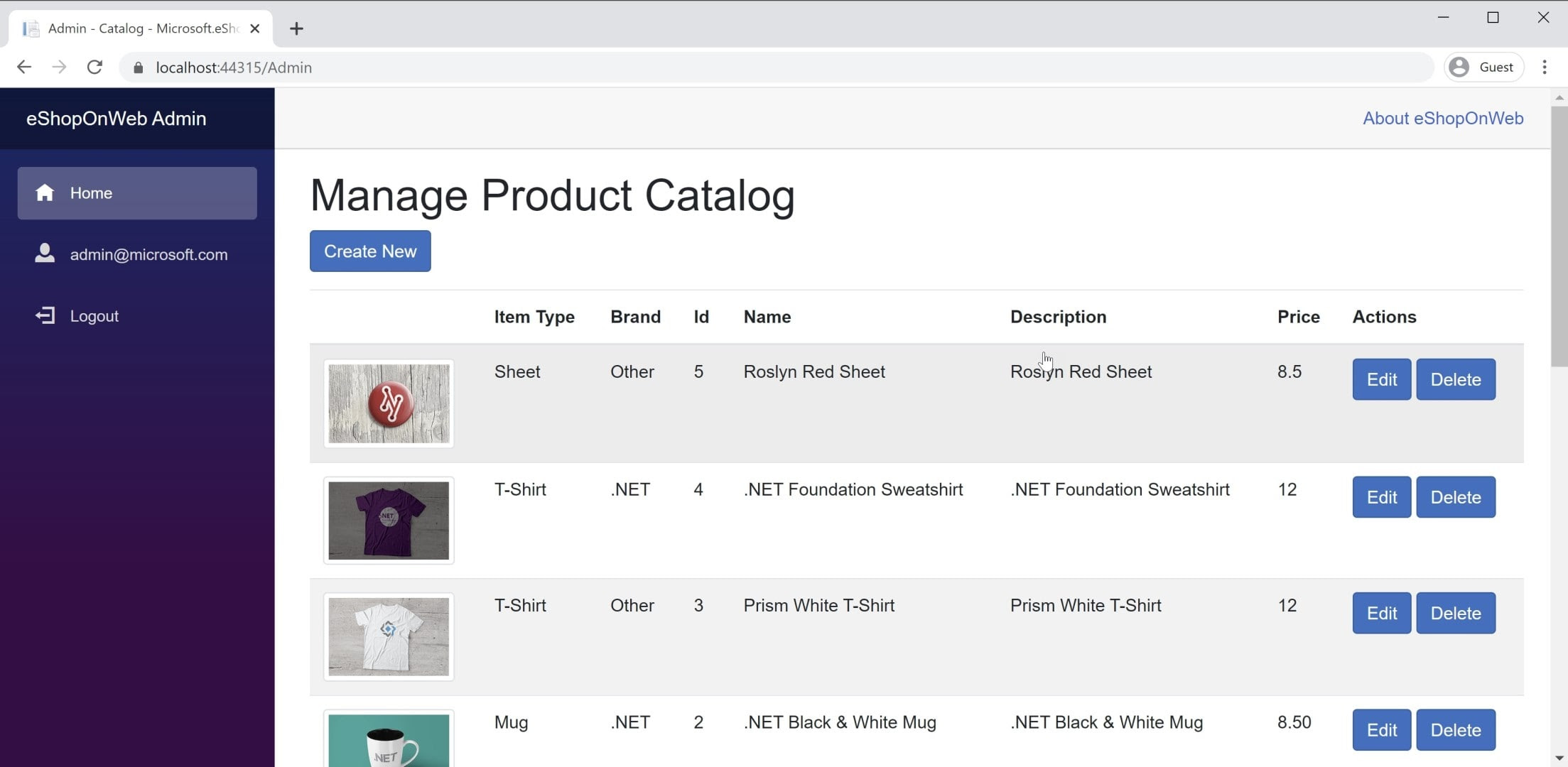
그림 8-3. eShopOnWeb 카탈로그 관리 스크린샷
Blazor
WebAssembly 앱 내의 웹 API에서 데이터를 가져오는 경우 모든 .NET 애플리케이션에서 사용하는 것처럼 HttpClient 인스턴스를 사용합니다. 포함된 기본 단계는 보낼 요청을 만들고(필요시 일반적으로 POST 또는 PUT 요청의 경우), 요청 자체를 기다리고, 상태 코드를 확인하며, 응답을 역직렬화하는 것입니다. 지정된 API 세트에 대한 많은 요청을 만들려는 경우 API를 캡슐화하고 HttpClient 기준 주소를 중앙에서 구성하는 것이 좋습니다. 이렇게 하면 환경 간에 해당 설정을 조정해야 하는 경우 한 곳에서만 변경 작업을 수행할 수 있습니다.
Program.Main에서 해당 서비스 지원을 추가해야 합니다.
builder.Services.AddScoped(sp => new HttpClient
{
BaseAddress = new Uri(builder.HostEnvironment.BaseAddress)
});
서비스에 안전하게 액세스해야 하는 경우 보안 토큰에 액세스하고 모든 요청에서 해당 토큰을 인증 헤더로 전달하도록 HttpClient를 구성해야 합니다.
_httpClient.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", token);
HttpClient가 HttpClient 수명을 사용하여 애플리케이션 서비스에 추가되지 않은 경우 Transient가 삽입된 모든 구성 요소에서 해당 작업을 수행할 수 있습니다. 애플리케이션의 HttpClient에 대한 모든 참조는 동일한 인스턴스를 참조하므로 한 구성 요소의 변경 내용은 전체 애플리케이션에 적용됩니다. 토큰을 지정하여 해당 인증 검사를 수행할 좋은 위치는 사이트의 주 탐색 같은 공유 구성 요소에 있습니다.
BlazorAdmin의 프로젝트에서 해당 접근 방식을 자세히 알아봅니다.
기존 JavaScript SPA를 통한 BlazorWebAssembly의 한 가지 이점은 DTO(데이터 전송 개체)의 복사본을 계속 동기화하지 않아도 된다는 것입니다. Blazor WebAssembly 프로젝트와 웹 API 프로젝트는 둘 다 공통 공유 프로젝트에서 동일한 DTO를 공유할 수 있습니다. 이렇게 하면 SPA 개발과 관련된 일부 충돌이 제거됩니다.
API 엔드포인트에서 데이터를 빠르게 가져오는 데는 기본 제공 도우미 메서드인 GetFromJsonAsync를 사용할 수 있습니다. POST, PUT 등을 위한 유사한 메서드가 있습니다. 다음은 HttpClientBlazor 앱에서 구성된 WebAssembly를 사용하여 API 엔드포인트에서 CatalogItem을 가져오는 방법을 보여 줍니다.
var item = await _httpClient.GetFromJsonAsync<CatalogItem>($"catalog-items/{id}");
필요한 데이터가 있으면 일반적으로 변경 내용을 로컬에서 추적합니다. 백 엔드 데이터 저장소를 업데이트하려는 경우 해당 목적을 위해 추가 웹 API를 호출합니다.
참조 – Blazor 데이터
- ASP.NET Core Blazorhttps://learn.microsoft.com/aspnet/core/blazor/call-web-api에서 웹 API 호출
GitHub에서 Microsoft와 공동 작업
이 콘텐츠의 원본은 GitHub에서 찾을 수 있으며, 여기서 문제와 끌어오기 요청을 만들고 검토할 수도 있습니다. 자세한 내용은 참여자 가이드를 참조하세요.
.NET