집합 작업(C#)
LINQ의 집합 작업은 동일하거나 별도의 컬렉션 내에 동등한 요소가 있는지 여부에 따라 결과 집합을 생성하는 쿼리 작업을 나타냅니다.
| 메서드 이름 | 설명 | C# 쿼리 식 구문 | 자세한 정보 |
|---|---|---|---|
Distinct 또는 DistinctBy |
컬렉션에서 중복 값을 제거합니다. | 해당 없음. | Enumerable.Distinct Enumerable.DistinctBy Queryable.Distinct Queryable.DistinctBy |
Except 또는 ExceptBy |
두 번째 컬렉션에 표시되지 않는 한 컬렉션의 요소를 의미하는 차집합을 반환합니다. | 해당 없음. | Enumerable.Except Enumerable.ExceptBy Queryable.Except Queryable.ExceptBy |
Intersect 또는 IntersectBy |
두 컬렉션에 각각 표시되는 요소를 의미하는 교집합을 반환합니다. | 해당 없음. | Enumerable.Intersect Enumerable.IntersectBy Queryable.Intersect Queryable.IntersectBy |
Union 또는 UnionBy |
두 컬렉션 중 하나에 표시되는 고유한 요소를 의미하는 합집합을 반환합니다. | 해당 없음. | Enumerable.Union Enumerable.UnionBy Queryable.Union Queryable.UnionBy |
Distinct 및 DistinctBy
다음 예제에서는 문자열 시퀀스에 대한 Enumerable.Distinct 메서드의 동작을 보여 줍니다. 반환된 시퀀스에는 입력 시퀀스의 고유한 요소가 포함됩니다.
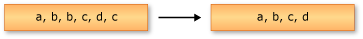
string[] words = ["the", "quick", "brown", "fox", "jumped", "over", "the", "lazy", "dog"];
IEnumerable<string> query = from word in words.Distinct()
select word;
foreach (var str in query)
{
Console.WriteLine(str);
}
/* This code produces the following output:
*
* the
* quick
* brown
* fox
* jumped
* over
* lazy
* dog
*/
DistinctBy는 Distinct에 대한 대체 방법으로, keySelector를 사용합니다. keySelector는 원본 형식의 비교 판별자로 사용됩니다. 다음 코드에서 단어는 Length에 따라 구별되고 각 길이의 첫 번째 단어가 표시됩니다.
string[] words = ["the", "quick", "brown", "fox", "jumped", "over", "the", "lazy", "dog"];
foreach (string word in words.DistinctBy(p => p.Length))
{
Console.WriteLine(word);
}
// This code produces the following output:
// the
// quick
// jumped
// over
Except 및 ExceptBy
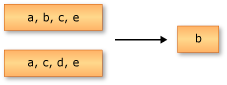
다음 예제에서는 Enumerable.Except의 동작을 보여줍니다. 반환된 시퀀스에는 두 번째 입력 시퀀스에 없는 첫 번째 입력 시퀀스의 요소만 포함됩니다.
이 문서의 다음 예제에서는 이 영역에 대한 공통 데이터 원본을 사용합니다.
public enum GradeLevel
{
FirstYear = 1,
SecondYear,
ThirdYear,
FourthYear
};
public class Student
{
public required string FirstName { get; init; }
public required string LastName { get; init; }
public required int ID { get; init; }
public required GradeLevel Year { get; init; }
public required List<int> Scores { get; init; }
public required int DepartmentID { get; init; }
}
public class Teacher
{
public required string First { get; init; }
public required string Last { get; init; }
public required int ID { get; init; }
public required string City { get; init; }
}
public class Department
{
public required string Name { get; init; }
public int ID { get; init; }
public required int TeacherID { get; init; }
}
각 Student에는 학년 수준, 기본 부서 및 일련의 점수가 있습니다. Teacher에는 교사가 수업을 진행하는 캠퍼스를 식별하는 City 속성도 있습니다. Department에는 이름이 있고 부서장 역할을 하는 Teacher에 대한 참조가 있습니다.
string[] words1 = ["the", "quick", "brown", "fox"];
string[] words2 = ["jumped", "over", "the", "lazy", "dog"];
IEnumerable<string> query = from word in words1.Except(words2)
select word;
foreach (var str in query)
{
Console.WriteLine(str);
}
/* This code produces the following output:
*
* quick
* brown
* fox
*/
ExceptBy 메서드는 이종 형식의 두 시퀀스와 keySelector를 사용하는 Except에 대한 대체 접근 방식입니다. keySelector은(는) 첫 번째 컬렉션의 형식과 동일한 형식입니다. 제외할 다음 Teacher 배열 및 교사 ID를 고려합니다. 두 번째 컬렉션에 없는 교사를 첫 번째 컬렉션에서 찾으려면 교사의 ID를 두 번째 컬렉션에 투영할 수 있습니다.
int[] teachersToExclude =
[
901, // English
965, // Mathematics
932, // Engineering
945, // Economics
987, // Physics
901 // Chemistry
];
foreach (Teacher teacher in
teachers.ExceptBy(
teachersToExclude, teacher => teacher.ID))
{
Console.WriteLine($"{teacher.First} {teacher.Last}");
}
위의 C# 코드에서:
teachers배열은teachersToExclude배열에 없는 교사로만 필터링됩니다.teachersToExclude배열에는 모든 부서장의ID값이 포함됩니다.ExceptBy을(를) 호출하면 콘솔에 기록되는 새로운 값 집합이 생성됩니다.
새 값 집합은 첫 번째 컬렉션의 형식인 Teacher 형식입니다. teachersToExclude 배열에 해당 ID 값이 없는 teachers 배열의 각 teacher이(가) 콘솔에 기록됩니다.
Intersect 및 IntersectBy
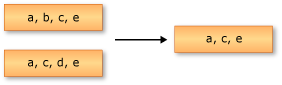
다음 예제에서는 Enumerable.Intersect의 동작을 보여줍니다. 반환된 시퀀스에는 입력 시퀀스 둘 다에 공통적으로 있는 요소가 포함됩니다.
string[] words1 = ["the", "quick", "brown", "fox"];
string[] words2 = ["jumped", "over", "the", "lazy", "dog"];
IEnumerable<string> query = from word in words1.Intersect(words2)
select word;
foreach (var str in query)
{
Console.WriteLine(str);
}
/* This code produces the following output:
*
* the
*/
IntersectBy 메서드는 이종 형식의 두 시퀀스와 keySelector를 사용하는 Intersect에 대한 대체 접근 방식입니다. keySelector는 두 번째 컬렉션 형식의 비교 판별자로 사용됩니다. 다음 학생 및 교사 배열을 고려합니다. 쿼리는 각 시퀀스의 항목을 이름별로 일치시켜 교사는 아닌 학생을 찾습니다.
foreach (Student person in
students.IntersectBy(
teachers.Select(t => (t.First, t.Last)), s => (s.FirstName, s.LastName)))
{
Console.WriteLine($"{person.FirstName} {person.LastName}");
}
위의 C# 코드에서:
- 쿼리는 이름과 비교하여
Teacher과(와)Student의 교차를 생성합니다. - 두 배열 모두에서 찾은 사람만 결과 시퀀스에 나타납니다.
- 결과
Student인스턴스는 콘솔에 기록됩니다.
Union 및 UnionBy
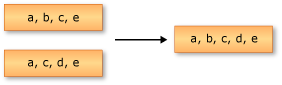
다음 예제에서는 두 개의 문자열 시퀀스에 대한 합집합을 보여줍니다. 반환된 시퀀스에는 두 입력 시퀀스의 고유한 요소가 모두 포함됩니다.
string[] words1 = ["the", "quick", "brown", "fox"];
string[] words2 = ["jumped", "over", "the", "lazy", "dog"];
IEnumerable<string> query = from word in words1.Union(words2)
select word;
foreach (var str in query)
{
Console.WriteLine(str);
}
/* This code produces the following output:
*
* the
* quick
* brown
* fox
* jumped
* over
* lazy
* dog
*/
UnionBy 메서드는 동일한 형식의 두 시퀀스와 keySelector를 사용하는 Union에 대한 대체 접근 방식입니다. keySelector는 원본 형식의 비교 판별자로 사용됩니다. 다음 쿼리는 학생 또는 교사인 모든 사람의 목록을 생성합니다. 교사이기도 한 학생은 합집합에 한 번만 추가됩니다.
foreach (var person in
students.Select(s => (s.FirstName, s.LastName)).UnionBy(
teachers.Select(t => (FirstName: t.First, LastName: t.Last)), s => (s.FirstName, s.LastName)))
{
Console.WriteLine($"{person.FirstName} {person.LastName}");
}
위의 C# 코드에서:
teachers및students배열은 해당 이름을 키 선택기로 사용하여 함께 짜여집니다.- 결과 이름은 콘솔에 기록됩니다.
참고 항목
.NET
피드백
출시 예정: 2024년 내내 콘텐츠에 대한 피드백 메커니즘으로 GitHub 문제를 단계적으로 폐지하고 이를 새로운 피드백 시스템으로 바꿀 예정입니다. 자세한 내용은 다음을 참조하세요. https://aka.ms/ContentUserFeedback
다음에 대한 사용자 의견 제출 및 보기