이 자습서에서는 .NET 콘솔 애플리케이션에서 ML.NET 사용하여 영화 추천을 빌드하는 방법을 보여줍니다. 이 단계에서는 C# 및 Visual Studio 2019를 사용합니다.
이 튜토리얼에서는 다음을 배우게 됩니다:
- 기계 학습 알고리즘 선택
- 데이터 준비 및 로드
- 모델 빌드 및 학습
- 모델 평가
- 모델 배포 및 사용
이 자습서의 소스 코드는 dotnet/samples 리포지토리에서 찾을 수 있습니다.
기계 학습 워크플로
당신은 다음 단계와 다른 모든 ML.NET 태스크에 대해서도 이러한 단계를 사용할 것입니다.
필수 조건
적절한 기계 학습 작업 선택
영화 목록을 추천하거나 관련 제품 목록을 추천하는 등 권장 사항 문제에 접근하는 방법에는 여러 가지가 있지만, 이 경우 사용자가 특정 영화에 제공할 등급(1-5)을 예측하고 정의된 임계값보다 높은 경우 해당 영화를 추천합니다(등급이 높을수록 특정 영화를 좋아할 가능성이 높음).
콘솔 애플리케이션 만들기
프로젝트 만들기
"MovieRecommender"라는 C# 콘솔 애플리케이션 을 만듭니다. 다음 단추를 클릭합니다.
사용할 프레임워크로 .NET 8을 선택합니다. 만들기 버튼을 클릭합니다.
프로젝트에 Data 라는 디렉터리를 만들어 데이터 집합을 저장합니다.
솔루션 탐색기에서 프로젝트를 마우스 오른쪽 단추로 클릭하고새 폴더>를 선택합니다. "데이터"를 입력하고 Enter 키를 선택합니다.
Microsoft.ML 및 Microsoft.ML.Recommender NuGet 패키지를 설치합니다.
비고
이 샘플에서는 달리 명시되지 않는 한 언급된 안정적인 최신 버전의 NuGet 패키지를 사용합니다.
솔루션 탐색기에서 프로젝트를 마우스 오른쪽 단추로 클릭하고 NuGet 패키지 관리를 선택합니다. 패키지 원본으로 "nuget.org"을 선택하고 , 찾아보기 탭을 선택하고, Microsoft.ML 검색하고, 목록에서 패키지를 선택하고, 설치를 선택합니다. 변경 내용 미리 보기 대화 상자에서 확인단추를 선택한 다음, 나열된 패키지의 사용 조건에 동의하는 경우 라이선스 승인 대화 상자에서 동의 단추를 선택합니다. Microsoft.ML.Recommender에 대해 다음 단계를 반복합니다.
using파일의 맨 위에 다음 지시문을 추가합니다.using Microsoft.ML; using Microsoft.ML.Trainers; using MovieRecommendation;
데이터 다운로드
두 데이터 세트를 다운로드하고 이전에 만든 데이터 폴더에 저장합니다.
recommendation-ratings-train.csv마우스 오른쪽 단추 로 클릭하고 "링크(또는 대상) 다른 이름으로 저장..."을 선택합니다.
recommendation-ratings-test.csv 파일을 마우스 오른쪽 버튼으로 클릭하고 "링크(또는 대상) 다른 이름으로 저장..."을 선택합니다.
*.csv 파일을 데이터 폴더에 저장하거나 다른 곳에 저장한 후 *.csv 파일을 데이터 폴더로 이동해야 합니다.
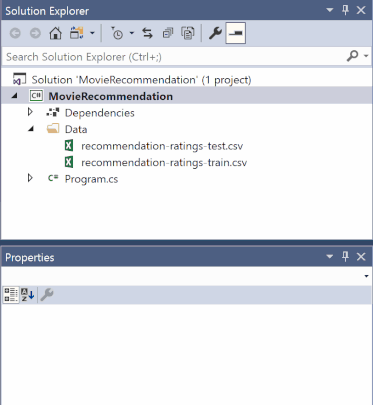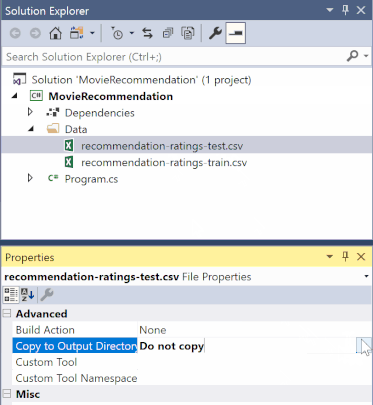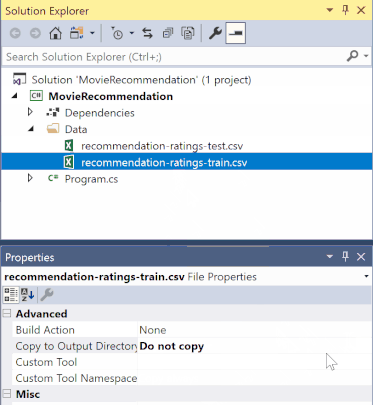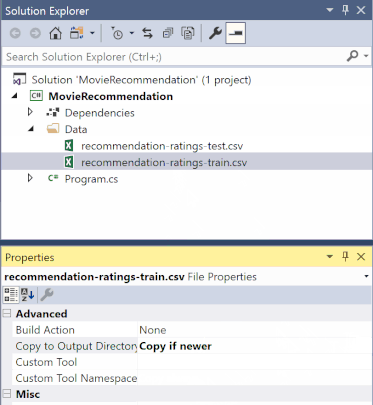
솔루션 탐색기에서 *.csv 파일을 각각 마우스 오른쪽 단추로 클릭하고 속성을 선택합니다. 고급 탭에서 출력 디렉터리에 복사 설정을 새 버전인 경우에만 복사로 변경합니다.
데이터 로드
ML.NET 프로세스의 첫 번째 단계는 모델 학습 및 테스트 데이터를 준비하고 로드하는 것입니다.
권장 사항 등급 데이터는 데이터 세트로 TrainTest 분할됩니다. 데이터는 Train 모델에 맞는 데 사용됩니다. 데이터는 Test 학습된 모델을 사용하여 예측을 수행하고 모델 성능을 평가하는 데 사용됩니다. 80/20을 데이터로 Train 분할하는 것이 일반적입니다 Test .
다음은 *.csv 파일의 데이터 미리 보기입니다.
*.csv 파일에는 4개의 열이 있습니다.
userIdmovieIdratingtimestamp
기계 학습에서 예측을 만드는 데 사용되는 열을 기능이라고 하며 반환된 예측이 있는 열을 레이블이라고 합니다.
영화 평가를 예측하려고 하므로 평가 열은 Label입니다. 나머지 세 열은 userIdmovieIdtimestamp 모두 Features 를 예측Label하는 데 사용됩니다.
| 기능 | 라벨 |
|---|---|
userId |
rating |
movieId |
|
timestamp |
예측Features하는 데 사용되는 항목을 결정하는 Label 것은 사용자에게 달려 있습니다.
순열 기능 중요도와 같은 메서드를 사용하여 최상의 Features항목을 선택할 수도 있습니다.
이 경우 타임스탬프가 사용자가 지정된 영화를 평가하는 방식에 실제로 영향을 주지 않으므로 더 정확한 예측을 수행하는 데 기여하지 않으므로 열을 timestamp 제거해야 합니다Feature.
| 기능 | 라벨 |
|---|---|
userId |
rating |
movieId |
다음으로 입력 클래스에 대한 데이터 구조를 정의해야 합니다.
프로젝트에 새 클래스를 추가합니다.
솔루션 탐색기에서 프로젝트를 마우스 오른쪽 단추로 클릭한 다음 새 항목 추가>를 선택합니다.
새 항목 추가 대화 상자에서 클래스를 선택하고 이름 필드를 MovieRatingData.cs 변경합니다. 그런 후 추가를 선택합니다.
MovieRatingData.cs 파일이 코드 편집기에서 열립니다.
using 맨 위에 다음 지시문을 추가합니다.
using Microsoft.ML.Data;
기존 클래스 정의를 제거하고 MovieRating 다음 코드를 추가하여 호출 되는 클래스를 만듭니다.
public class MovieRating
{
[LoadColumn(0)]
public float userId;
[LoadColumn(1)]
public float movieId;
[LoadColumn(2)]
public float Label;
}
MovieRating 은 입력 데이터 클래스를 지정합니다.
LoadColumn 특성은 데이터 세트에서 로드할 열(열 인덱스 기준)을 지정합니다.
userId 및 movieId 열은 Features입니다 (모델에 제공할 입력으로, Label을 예측하기 위해 사용됩니다), 그리고 등급 열은 예측할 Label입니다 (모델의 출력).
MovieRatingData.cs 클래스 MovieRatingPrediction다음에 다음 코드를 추가하여 예측 결과를 나타내는 다른 클래스를 MovieRating 만듭니다.
public class MovieRatingPrediction
{
public float Label;
public float Score;
}
Program.cs 다음 코드로 바꿉 Console.WriteLine("Hello World!") 다.
MLContext mlContext = new MLContext();
MLContext 클래스는 모든 ML.NET 작업의 시작점이며 초기화 mlContext 하면 모델 생성 워크플로 개체 간에 공유할 수 있는 새 ML.NET 환경이 만들어집니다. 개념적으로 DBContext Entity Framework와 유사합니다.
파일 맨 아래에 다음 메서드를 만듭니다 LoadData().
(IDataView training, IDataView test) LoadData(MLContext mlContext)
{
}
비고
이 메서드는 다음 단계에서 return 문을 추가할 때까지 오류를 제공합니다.
데이터 경로 변수를 초기화하고, *.csv 파일에서 데이터를 로드하십시오. 그런 다음, Train 및 Test 데이터를 IDataView 개체로 반환하려면 LoadData()에 아래 코드를 다음 줄로 추가하십시오.
var trainingDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-train.csv");
var testDataPath = Path.Combine(Environment.CurrentDirectory, "Data", "recommendation-ratings-test.csv");
IDataView trainingDataView = mlContext.Data.LoadFromTextFile<MovieRating>(trainingDataPath, hasHeader: true, separatorChar: ',');
IDataView testDataView = mlContext.Data.LoadFromTextFile<MovieRating>(testDataPath, hasHeader: true, separatorChar: ',');
return (trainingDataView, testDataView);
ML.NET 데이터는 IDataView 인터페이스로 표시됩니다.
IDataView 는 테이블 형식 데이터(숫자 및 텍스트)를 유연하고 효율적으로 설명하는 방법입니다. 데이터는 텍스트 파일에서 로드되거나 실시간으로(예: SQL 데이터베이스 또는 로그 파일) IDataView 개체로 로드됩니다.
LoadFromTextFile()은 데이터 스키마를 정의하고 파일에서 읽습니다. 데이터 경로 변수를 가져와서 .를 IDataView반환합니다. 이 경우 사용자 Test 와 Train 파일의 경로를 제공하고 텍스트 파일 머리글(열 이름을 제대로 사용할 수 있도록)과 쉼표 문자 데이터 구분 기호(기본 구분 기호는 탭)를 모두 나타냅니다.
다음 코드를 추가하여 메서드를 호출 LoadData() 하고 데이터와 Train 메서드를 Test 반환합니다.
(IDataView trainingDataView, IDataView testDataView) = LoadData(mlContext);
모델 빌드 및 학습
BuildAndTrainModel() 다음 코드를 사용하여 메서드 바로 다음에 LoadData() 메서드를 만듭니다.
ITransformer BuildAndTrainModel(MLContext mlContext, IDataView trainingDataView)
{
}
비고
이 메서드는 다음 단계에서 return 문을 추가할 때까지 오류를 제공합니다.
다음 코드를 추가하여 데이터 변환을 정의합니다 BuildAndTrainModel().
IEstimator<ITransformer> estimator = mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "userIdEncoded", inputColumnName: "userId")
.Append(mlContext.Transforms.Conversion.MapValueToKey(outputColumnName: "movieIdEncoded", inputColumnName: "movieId"));
실제 userId 값이 아닌 사용자 및 movieId 영화 제목을 나타내기 때문에 MapValueToKey() 메서드를 사용하여 각각 userIdmovieId 을 숫자 키 형식 Feature 열(권장 알고리즘에서 허용하는 형식)으로 변환하고 새 데이터 세트 열로 추가합니다.
| userId | movieId | 라벨 | 사용자 ID 인코딩됨 | movieIdEncoded |
|---|---|---|---|---|
| 1 | 1 | 4 | userKey1 | movieKey1 |
| 1 | 3 | 4 | userKey1 | movieKey2 |
| 1 | 6 | 4 | userKey1 | movieKey3 |
기계 학습 알고리즘을 선택하고 다음 코드를 다음 코드 줄로 추가하여 데이터 변환 정의에 BuildAndTrainModel()추가합니다.
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
var trainerEstimator = estimator.Append(mlContext.Recommendation().Trainers.MatrixFactorization(options));
MatrixFactorizationTrainer는 권장 사항 학습 알고리즘입니다. 행렬 팩터리화 는 사용자가 과거에 제품을 평가한 방법에 대한 데이터가 있는 경우 권장 사항에 대한 일반적인 접근 방식이며, 이 자습서의 데이터 세트에 대한 경우입니다. 다른 데이터를 사용할 수 있는 경우에 대한 다른 권장 알고리즘이 있습니다(자세한 내용은 아래 의 기타 권장 알고리즘 섹션 참조).
이 경우 Matrix Factorization 알고리즘은 "공동 작업 필터링"이라는 메서드를 사용합니다. 이 메서드는 사용자 1이 특정 문제에 대해 사용자 2와 동일한 의견을 가지고 있는 경우 사용자 1이 다른 문제에 대해 사용자 2와 같은 방식으로 느낄 가능성이 더 높다고 가정합니다.
예를 들어 사용자 1과 사용자 2가 영화를 비슷하게 평가하는 경우 사용자 2는 사용자 1이 보고 높은 평가를 받은 영화를 즐길 가능성이 더 높습니다.
Incredibles 2 (2018) |
The Avengers (2012) |
Guardians of the Galaxy (2014) |
|
|---|---|---|---|
| 사용자 1 | 영화를 보고 좋아했습니다. | 영화를 보고 좋아했습니다. | 영화를 보고 좋아했습니다. |
| 사용자 2 | 영화를 보고 좋아했습니다. | 영화를 보고 좋아했습니다. | 시청하지 않음 - 영화 추천 |
트레이너에는 Matrix Factorization 아래 알고리즘 하이퍼 매개 변수 섹션에서 자세히 읽을 수 있는 몇 가지 옵션이 있습니다.
다음을 메서드의 Train 다음 코드 BuildAndTrainModel() 줄로 추가하여 모델에 데이터를 맞추고 학습된 모델을 반환합니다.
Console.WriteLine("=============== Training the model ===============");
ITransformer model = trainerEstimator.Fit(trainingDataView);
return model;
Fit() 메서드는 제공된 학습 데이터 세트를 사용하여 모델을 학습시킵니다. 기술적으로는 데이터를 변환하고 학습을 적용하여 정의를 실행하고 Estimator 학습된 모델(예: )을 Transformer반환합니다.
ML.NET 모델 학습 워크플로에 대한 자세한 내용은 ML.NET 무엇이며 어떻게 작동하는지를 참조하세요.
당신의 BuildAndTrainModel() 메서드를 호출하고 학습된 모델을 반환하기 위해 LoadData() 메서드를 호출한 다음 줄에 다음 코드를 추가합니다.
ITransformer model = BuildAndTrainModel(mlContext, trainingDataView);
모델 평가
모델을 학습한 후에는 테스트 데이터를 사용하여 모델의 성능을 평가합니다.
EvaluateModel() 다음 코드를 사용하여 메서드 바로 다음에 BuildAndTrainModel() 메서드를 만듭니다.
void EvaluateModel(MLContext mlContext, IDataView testDataView, ITransformer model)
{
}
Test 다음 코드를 추가하여 데이터를 변환합니다EvaluateModel().
Console.WriteLine("=============== Evaluating the model ===============");
var prediction = model.Transform(testDataView);
Transform() 메서드는 테스트 데이터 세트의 제공된 여러 입력 행을 예측합니다.
메서드의 다음 코드 EvaluateModel() 줄로 다음을 추가하여 모델을 평가합니다.
var metrics = mlContext.Regression.Evaluate(prediction, labelColumnName: "Label", scoreColumnName: "Score");
예측 집합이 있으면 Evaluate() 메서드는 예측 값을 테스트 데이터 세트의 실제 Labels 값과 비교하고 모델의 성능에 대한 메트릭을 반환하는 모델을 평가합니다.
다음을 메서드의 다음 코드 줄로 추가하여 평가 메트릭을 콘솔에 EvaluateModel() 인쇄합니다.
Console.WriteLine("Root Mean Squared Error : " + metrics.RootMeanSquaredError.ToString());
Console.WriteLine("RSquared: " + metrics.RSquared.ToString());
메서드를 호출할 메서드에 대한 호출 BuildAndTrainModel() 아래에 다음 코드 줄로 다음을 추가합니다 EvaluateModel() .
EvaluateModel(mlContext, testDataView, model);
지금까지의 출력은 다음 텍스트와 유사해야 합니다.
=============== Training the model ===============
iter tr_rmse obj
0 1.5403 3.1262e+05
1 0.9221 1.6030e+05
2 0.8687 1.5046e+05
3 0.8416 1.4584e+05
4 0.8142 1.4209e+05
5 0.7849 1.3907e+05
6 0.7544 1.3594e+05
7 0.7266 1.3361e+05
8 0.6987 1.3110e+05
9 0.6751 1.2948e+05
10 0.6530 1.2766e+05
11 0.6350 1.2644e+05
12 0.6197 1.2541e+05
13 0.6067 1.2470e+05
14 0.5953 1.2382e+05
15 0.5871 1.2342e+05
16 0.5781 1.2279e+05
17 0.5713 1.2240e+05
18 0.5660 1.2230e+05
19 0.5592 1.2179e+05
=============== Evaluating the model ===============
Rms: 0.994051469730769
RSquared: 0.412556298844873
이 출력에는 20개의 반복이 있습니다. 각 반복에서 오류 측정값은 감소하고 0에 가까워지고 수렴됩니다.
root of mean squared error (RMS 또는 RMSE)는 모델 예측 값과 관찰된 테스트 데이터 세트 값 간의 차이를 측정하는 데 사용됩니다. 기술적으로 이는 오류 제곱의 평균의 제곱근입니다. 이 값이 낮을수록 모델이 더 좋습니다.
R Squared 는 데이터가 모델에 얼마나 잘 맞는지 나타냅니다. 0에서 1까지의 범위입니다. 값이 0이면 데이터가 임의이거나 모델에 맞지 않습니다. 값이 1이면 모델이 데이터와 정확히 일치합니다.
R Squared 점수가 가능한 1에 가까울 수 있습니다.
성공적인 모델을 빌드하는 것은 반복적인 프로세스입니다. 이 모델은 자습서에서 작은 데이터 세트를 사용하여 빠른 모델 학습을 제공하므로 초기 품질이 낮습니다. 모델 품질에 만족하지 않는 경우 더 큰 학습 데이터 세트를 제공하거나 각 알고리즘에 대해 서로 다른 하이퍼 매개 변수가 있는 다른 학습 알고리즘을 선택하여 이를 개선할 수 있습니다. 자세한 내용은 아래 모델 개선 섹션을 참조하세요.
모델 사용
이제 학습된 모델을 사용하여 새 데이터에 대한 예측을 수행할 수 있습니다.
UseModelForSinglePrediction() 다음 코드를 사용하여 메서드 바로 다음에 EvaluateModel() 메서드를 만듭니다.
void UseModelForSinglePrediction(MLContext mlContext, ITransformer model)
{
}
다음 PredictionEngine 코드를 추가하여 등급을 예측하는 데 UseModelForSinglePrediction()사용합니다.
Console.WriteLine("=============== Making a prediction ===============");
var predictionEngine = mlContext.Model.CreatePredictionEngine<MovieRating, MovieRatingPrediction>(model);
PredictionEngine은 단일 데이터 인스턴스에서 예측을 수행할 수 있는 편리한 API입니다.
PredictionEngine 가 스레드로부터 안전하지 않습니다. 단일 스레드 또는 프로토타입 환경에서 사용할 수 있습니다. 프로덕션 환경에서 성능 및 스레드 안전성 향상을 PredictionEnginePool 위해 애플리케이션 전체에서 사용할 개체를 ObjectPool 만드는 PredictionEngine 서비스를 사용합니다.
ASP.NET Core Web API에서 사용하는 PredictionEnginePool방법에 대한 이 가이드를 참조하세요.
비고
PredictionEnginePool 서비스 확장은 현재 미리 보기로 제공됩니다.
MovieRating라는 이름의 인스턴스를 만들고, testInput 메서드의 다음 코드 줄로 추가하여 UseModelForSinglePrediction()에 예측 엔진을 전달합니다.
var testInput = new MovieRating { userId = 6, movieId = 10 };
var movieRatingPrediction = predictionEngine.Predict(testInput);
Predict() 함수는 단일 데이터 열에 대해 예측을 합니다.
그런 다음, 예측 등급 또는 예상 등급을 사용하여 ScoremovieId 10이 있는 영화를 사용자 6에게 추천할지 여부를 결정할 수 있습니다. 높을수록 Score사용자가 특정 영화를 좋아할 가능성이 높아집니다. 이 경우 예측 등급 > 이 3.5인 영화를 추천한다고 가정해 보겠습니다.
결과를 인쇄하려면 메서드의 다음 코드 UseModelForSinglePrediction() 줄로 다음을 추가합니다.
if (Math.Round(movieRatingPrediction.Score, 1) > 3.5)
{
Console.WriteLine("Movie " + testInput.movieId + " is recommended for user " + testInput.userId);
}
else
{
Console.WriteLine("Movie " + testInput.movieId + " is not recommended for user " + testInput.userId);
}
메서드를 호출하여 메서드를 호출 EvaluateModel() 한 후 다음 코드를 다음 코드 줄로 추가합니다 UseModelForSinglePrediction() .
UseModelForSinglePrediction(mlContext, model);
이 메서드의 출력은 다음 텍스트와 유사해야 합니다.
=============== Making a prediction ===============
Movie 10 is recommended for user 6
모델 저장
모델을 사용하여 최종 사용자 애플리케이션에서 예측을 만들려면 먼저 모델을 저장해야 합니다.
SaveModel() 다음 코드를 사용하여 메서드 바로 다음에 UseModelForSinglePrediction() 메서드를 만듭니다.
void SaveModel(MLContext mlContext, DataViewSchema trainingDataViewSchema, ITransformer model)
{
}
메서드에 다음 코드를 SaveModel() 추가하여 학습된 모델을 저장합니다.
var modelPath = Path.Combine(Environment.CurrentDirectory, "Data", "MovieRecommenderModel.zip");
Console.WriteLine("=============== Saving the model to a file ===============");
mlContext.Model.Save(model, trainingDataViewSchema, modelPath);
이 메서드는 학습된 모델을 다른 .NET 애플리케이션에서 예측하는 데 사용할 수 있는 .zip 파일("데이터" 폴더)에 저장합니다.
메서드를 호출하여 메서드를 호출 UseModelForSinglePrediction() 한 후 다음 코드를 다음 코드 줄로 추가합니다 SaveModel() .
SaveModel(mlContext, trainingDataView.Schema, model);
저장된 모델 사용
학습된 모델을 저장한 후에는 다른 환경에서 모델을 사용할 수 있습니다. 앱에서 학습된 기계 학습 모델을 운영하는 방법을 알아보려면 학습된 모델 저장 및 로드 를 참조하세요.
Results
위의 단계를 수행한 후 콘솔 앱(Ctrl + F5)을 실행합니다. 위의 단일 예측의 결과는 다음과 유사해야 합니다. 경고 또는 메시지 처리가 표시될 수 있지만 명확성을 위해 다음 결과에서 이러한 메시지가 제거되었습니다.
=============== Training the model ===============
iter tr_rmse obj
0 1.5382 3.1213e+05
1 0.9223 1.6051e+05
2 0.8691 1.5050e+05
3 0.8413 1.4576e+05
4 0.8145 1.4208e+05
5 0.7848 1.3895e+05
6 0.7552 1.3613e+05
7 0.7259 1.3357e+05
8 0.6987 1.3121e+05
9 0.6747 1.2949e+05
10 0.6533 1.2766e+05
11 0.6353 1.2636e+05
12 0.6209 1.2561e+05
13 0.6072 1.2462e+05
14 0.5965 1.2394e+05
15 0.5868 1.2352e+05
16 0.5782 1.2279e+05
17 0.5713 1.2227e+05
18 0.5637 1.2190e+05
19 0.5604 1.2178e+05
=============== Evaluating the model ===============
Rms: 0.977175077487166
RSquared: 0.43233349213192
=============== Making a prediction ===============
Movie 10 is recommended for user 6
=============== Saving the model to a file ===============
축하합니다! 이제 영화를 추천하기 위한 기계 학습 모델을 성공적으로 빌드했습니다. 이 자습서의 소스 코드는 dotnet/samples 리포지토리에서 찾을 수 있습니다.
모델 개선
보다 정확한 예측을 얻을 수 있도록 모델의 성능을 향상시킬 수 있는 여러 가지 방법이 있습니다.
데이터
각 사용자 및 영화 ID에 대한 충분한 샘플이 있는 학습 데이터를 더 추가하면 권장 사항 모델의 품질을 개선하는 데 도움이 될 수 있습니다.
교차 유효성 검사는 데이터를 하위 집합으로 임의로 분할하고(이 자습서에서와 같이 데이터 세트에서 테스트 데이터를 추출하는 대신) 일부 그룹을 학습 데이터로 사용하고 일부 그룹을 테스트 데이터로 사용하는 모델을 평가하는 기술입니다. 이 메서드는 모델 품질 측면에서 학습 테스트 분할을 능가합니다.
기능
이 자습서에서는 데이터 세트에서 제공하는 세 Features 가지(user id및movie idrating)만 사용합니다.
이는 좋은 시작이지만 실제로는 데이터 세트에 포함된 경우 다른 특성 또는 Features (예: 나이, 성별, 지리적 위치 등)를 추가할 수 있습니다. 관련성 Features 을 높이면 권장 사항 모델의 성능을 향상시키는 데 도움이 될 수 있습니다.
기계 학습 작업에 가장 적합한 Features을 잘 모르는 경우, ML.NET에서 제공하는 특징 기여도 계산(FCC) 및 순열 특징 중요도를 사용하여 가장 영향력 있는 Features을 발견할 수 있습니다.
알고리즘 하이퍼 매개 변수
ML.NET 좋은 기본 학습 알고리즘을 제공하지만 알고리즘의 하이퍼 매개 변수를 변경하여 성능을 더욱 세밀하게 조정할 수 있습니다.
예를 Matrix Factorization들어 NumberOfIterations 및 ApproximationRank 과 같은 하이퍼 매개 변수를 실험하여 더 나은 결과를 제공하는지 확인할 수 있습니다.
예를 들어 이 자습서에서 알고리즘 옵션은 다음과 같습니다.
var options = new MatrixFactorizationTrainer.Options
{
MatrixColumnIndexColumnName = "userIdEncoded",
MatrixRowIndexColumnName = "movieIdEncoded",
LabelColumnName = "Label",
NumberOfIterations = 20,
ApproximationRank = 100
};
기타 권장 사항 알고리즘
공동 작업 필터링을 사용하는 행렬 팩터리화 알고리즘은 영화 권장 사항을 수행하기 위한 한 가지 방법일 뿐입니다. 대부분의 경우 등급 데이터를 사용할 수 없으며 사용자의 영화 기록만 사용할 수 있습니다. 다른 경우에는 사용자의 평가 데이터뿐만 아니라 더 많은 정보가 있을 수 있습니다.
| 알고리즘 | Scenario | Sample |
|---|---|---|
| 하나의 클래스 행렬 팩터리화 | userId 및 movieId만 있는 경우 이 옵션을 사용합니다. 이 권장 스타일은 공동 구매 시나리오 또는 자주 함께 구매하는 제품을 기반으로 하며, 이는 고객에게 자신의 구매 주문 기록에 따라 제품 세트를 추천한다는 것을 의미합니다. | >사용해 보기 |
| 필드 인식 팩터리화 컴퓨터 | userId, productId 및 등급(예: 제품 설명 또는 제품 가격)을 초과하는 기능이 더 많은 경우 이를 사용하여 권장 사항을 만들 수 있습니다. 이 메서드는 공동 작업 필터링 방법도 사용합니다. | >사용해 보기 |
새 사용자 시나리오
공동 작업 필터링의 일반적인 문제 중 하나는 추론을 그릴 이전 데이터가 없는 새 사용자가 있는 콜드 시작 문제입니다. 이 문제는 종종 새 사용자에게 프로필을 만들고, 예를 들어 과거에 본 영화를 평가하도록 요청하여 해결됩니다. 이 방법은 사용자에게 약간의 부담을 주지만 등급 기록이 없는 새 사용자에게 몇 가지 시작 데이터를 제공합니다.
리소스
이 자습서에서 사용되는 데이터는 MovieLens 데이터 세트에서 파생됩니다.
다음 단계
이 자습서에서는 다음 방법을 알아보았습니다.
- 기계 학습 알고리즘 선택
- 데이터 준비 및 로드
- 모델 빌드 및 학습
- 모델 평가
- 모델 배포 및 사용
자세한 내용을 보려면 다음 자습서로 진행하세요.
GitHub에서 Microsoft와 공동 작업
이 콘텐츠의 원본은 GitHub에서 찾을 수 있으며, 여기서 문제와 끌어오기 요청을 만들고 검토할 수도 있습니다. 자세한 내용은 참여자 가이드를 참조하세요.
.NET